

En esta función mensual recurrente, filtramos artículos de investigación recientes que aparecen en el servidor de preimpresión arXiv.org para temas atractivos relacionados con la inteligencia artificial, el aprendizaje automático y el aprendizaje profundo, de disciplinas que incluyen estadística, matemáticas e informática, y le brindamos un útil «mejor de ”lista durante el último mes. Investigadores de todo el mundo contribuyen a este repositorio como antesala del proceso de revisión por pares para su publicación en revistas tradicionales. arXiv contiene un verdadero tesoro de métodos de aprendizaje estadístico que puede usar algún día en la solución de problemas de ciencia de datos. Los artículos que se enumeran a continuación representan una pequeña fracción de todos los artículos que aparecen en el servidor de preimpresión. Se enumeran sin ningún orden en particular con un enlace a cada documento junto con una breve descripción general. Se proporcionan enlaces a repositorios de GitHub cuando están disponibles. Los artículos especialmente relevantes están marcados con un icono de «pulgar hacia arriba». Tenga en cuenta que estos son trabajos de investigación académica, generalmente dirigidos a estudiantes graduados, postdoctorados y profesionales experimentados. Por lo general, contienen un alto grado de matemáticas, así que prepárate. ¡Disfrutar!
Sobre las oportunidades y los riesgos de los modelos de cimientos

La IA está experimentando un cambio de paradigma con el surgimiento de modelos (por ejemplo, BERT, DALL-E, GPT-3) que se entrenan en datos amplios a escala y se adaptan a una amplia gama de tareas posteriores. Estos modelos se pueden considerar como modelos fundamentales para subrayar su carácter críticamente central pero incompleto. Este documento proporciona una descripción completa de las oportunidades y los riesgos de los modelos de base, que van desde sus capacidades (por ejemplo, lenguaje, visión, robótica, razonamiento, interacción humana) y principios técnicos (por ejemplo, arquitecturas de modelos, procedimientos de capacitación, datos, sistemas, seguridad , evaluación, teoría) a sus aplicaciones (por ejemplo, derecho, salud, educación) e impacto social (por ejemplo, inequidad, mal uso, impacto económico y ambiental, consideraciones legales y éticas). Aunque los modelos básicos se basan en el aprendizaje profundo estándar y el aprendizaje por transferencia, su escala da como resultado nuevas capacidades emergentes y su efectividad en tantas tareas incentiva la homogeneización. La homogeneización proporciona un poderoso apalancamiento, pero exige precaución, ya que los defectos del modelo de base son heredados por todos los modelos adaptados posteriores. A pesar del inminente despliegue generalizado de modelos de base, actualmente carecemos de una comprensión clara de cómo funcionan, cuándo fallan y de qué son capaces debido a sus propiedades emergentes. Para abordar estas preguntas, gran parte de la investigación crítica sobre modelos de cimientos requerirá una profunda colaboración interdisciplinaria acorde con su naturaleza fundamentalmente sociotécnica.
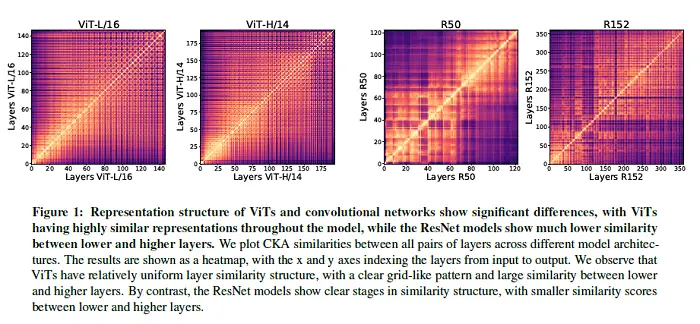
¿Los transformadores de visión se ven como redes neuronales convolucionales?
Las redes neuronales convolucionales (CNN) han sido hasta ahora el modelo de facto para los datos visuales. Trabajos recientes han demostrado que los modelos Transformer (Vision) (ViT) pueden lograr un rendimiento comparable o incluso superior en las tareas de clasificación de imágenes. Esto plantea una pregunta central: ¿cómo están resolviendo los transformadores de visión estas tareas? ¿Están actuando como redes convolucionales o están aprendiendo representaciones visuales completamente diferentes? Al analizar la estructura de representación interna de ViT y CNN en puntos de referencia de clasificación de imágenes, se han encontrado diferencias notables entre las dos arquitecturas, como que ViT tiene representaciones más uniformes en todas las capas. Este artículo explora cómo surgen estas diferencias, encontrando roles cruciales que juega la auto-atención, que permite la agregación temprana de información global, y conexiones residuales de ViT, que propagan fuertemente las características de las capas inferiores a las superiores. El artículo estudia las ramificaciones de la localización espacial, demostrando que los ViT conservan con éxito la información espacial de entrada, con efectos notables de diferentes métodos de clasificación. Finalmente, el artículo estudia el efecto de la escala del conjunto de datos (previo al entrenamiento) sobre las características intermedias y el aprendizaje de transferencia, y concluye con una discusión sobre las conexiones con nuevas arquitecturas como MLP-Mixer.
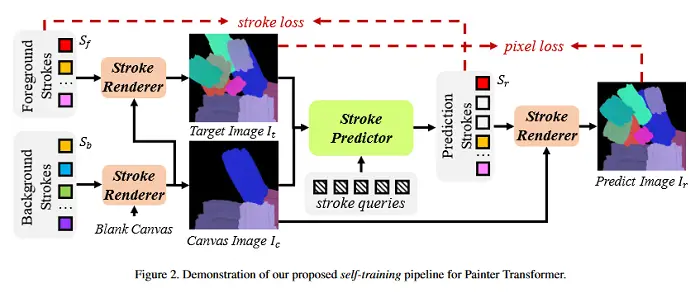
Transformador de pintura: pintura neural de avance con predicción de trazos
La pintura neuronal se refiere al procedimiento de producir una serie de trazos para una imagen dada y recrearla de manera no fotorrealista utilizando redes neuronales. Si bien los agentes basados en el aprendizaje por refuerzo (RL) pueden generar una secuencia de trazos paso a paso para esta tarea, no es fácil entrenar a un agente RL estable. Por otro lado, los métodos de optimización de trazos buscan un conjunto de parámetros de trazos de forma iterativa en un gran espacio de búsqueda; tan baja eficiencia limita significativamente su prevalencia y practicidad. A diferencia de los métodos anteriores, este artículo formula la tarea como un problema de predicción de conjuntos y propone un marco novedoso basado en Transformer, denominado Paint Transformer, para predecir los parámetros de un conjunto de trazos con una red de avance. De esta forma, el modelo puede generar un conjunto de trazos en paralelo y obtener la pintura final de tamaño 512 * 512 casi en tiempo real. Más importante aún, dado que no hay un conjunto de datos disponible para entrenar al Paint Transformer, la investigación diseña un proceso de autoaprendizaje para que pueda entrenarse sin ningún conjunto de datos estándar y al mismo tiempo lograr una excelente capacidad de generalización. Los experimentos demuestran que nuestro método logra un mejor rendimiento de pintura que los anteriores con costos de capacitación e inferencia más baratos. El repositorio de GitHub asociado con este documento se puede encontrar AQUÍ.
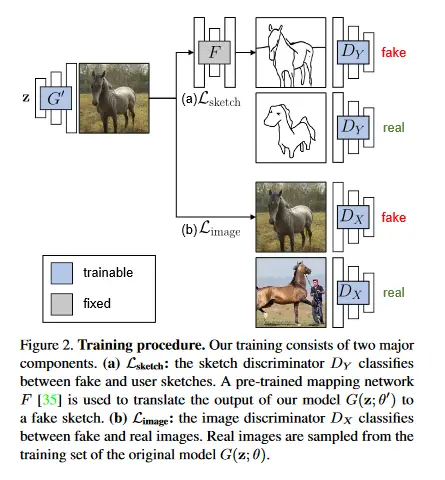
Dibuje su propio GAN
¿Puede un usuario crear un modelo generativo profundo esbozando un solo ejemplo? Tradicionalmente, la creación de un modelo GAN ha requerido la recopilación de un conjunto de datos a gran escala de ejemplos y conocimiento especializado en aprendizaje profundo. Por el contrario, dibujar es posiblemente la forma más universalmente accesible de transmitir un concepto visual. Este documento presenta un método, GAN Sketching, para reescribir GAN con uno o más bocetos, para facilitar la formación de GAN a los usuarios novatos. En particular, los pesos de un modelo GAN original se cambian de acuerdo con los bocetos del usuario. Se recomienda que la salida del modelo coincida con los bocetos del usuario a través de una pérdida de confrontación entre dominios. Además, se exploran diferentes métodos de regularización para preservar la diversidad y la calidad de imagen del modelo original. Los experimentos han demostrado que este método puede moldear las GAN para que coincidan con las formas y poses especificadas por los bocetos mientras se mantiene el realismo y la diversidad. El repositorio de GitHub asociado con este documento se puede encontrar AQUÍ.
¡Luces, CAMARA, ACCION! Un marco para mejorar la precisión de la PNL sobre los documentos OCR
La digitalización de documentos es esencial para la transformación digital de nuestras sociedades, pero un paso crucial en el proceso, el reconocimiento óptico de caracteres (OCR), aún no es perfecto. Incluso los sistemas comerciales de OCR pueden producir resultados cuestionables dependiendo de la fidelidad de los documentos escaneados. Este documento demuestra un marco eficaz para mitigar los errores de OCR para cualquier tarea de NLP posterior, utilizando el Reconocimiento de entidad con nombre (NER) como ejemplo. En primer lugar, se aborda el problema de la escasez de datos para el entrenamiento de modelos mediante la construcción de una tubería de síntesis de documentos, generando datos realistas pero degradados con etiquetas NER. La caída de precisión de NER se estima en varios niveles de degradación y muestra que un modelo de restauración de texto, entrenado en los datos degradados, cierra significativamente las brechas de precisión de NER causadas por errores de OCR, incluso en un conjunto de datos fuera del dominio. Para beneficio de la comunidad, la canalización de síntesis de documentos está disponible como un proyecto de código abierto. El repositorio de GitHub asociado con este documento se puede encontrar AQUÍ.
Una introducción elemental a la geometría de la información.
Esta encuesta describe las estructuras geométricas diferenciales fundamentales de las variedades de información, establece el teorema fundamental de la geometría de la información e ilustra algunos casos de uso de estas variedades de información en las ciencias de la información. La exposición es autónoma al introducir de manera concisa los conceptos necesarios de geometría diferencial, pero se omiten las pruebas por brevedad.
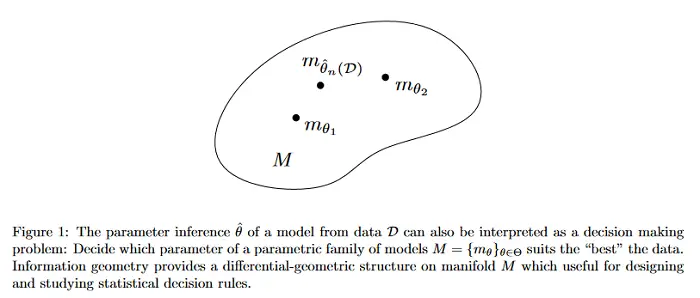
Detección de propaganda interpretable en artículos de noticias
Los usuarios en línea de hoy están expuestos a artículos de noticias y publicaciones en los medios engañosos y propagandísticos a diario. Para contrarrestar esto, se han diseñado una serie de enfoques con el objetivo de lograr un consumo de noticias y medios en línea más saludable y seguro. Los sistemas automáticos pueden ayudar a los humanos a detectar dicho contenido; sin embargo, un impedimento importante para su amplia adopción es que, además de ser precisas, las decisiones de dichos sistemas también deben ser interpretables para que los usuarios puedan confiar en ellas y adoptarlas ampliamente. Dado que el contenido engañoso y propagandístico influye en los lectores mediante el uso de una serie de técnicas de engaño, este artículo propone detectar y mostrar el uso de tales técnicas como una forma de ofrecer interpretabilidad.

Hombre versus máquina: AutoML y el papel de los expertos humanos en la detección de phishing
El aprendizaje automático (ML) se ha desarrollado rápidamente en los últimos años y se ha utilizado con éxito para una amplia gama de tareas, incluida la detección de phishing. Sin embargo, construir un sistema de detección eficaz basado en ML no es una tarea trivial y requiere científicos de datos con conocimiento del dominio relevante. Los marcos de aprendizaje automático automatizado (AutoML) han recibido mucha atención en los últimos años, lo que ha permitido a los expertos que no son de aprendizaje automático construir un modelo de aprendizaje automático. Esto lleva a la intrigante pregunta de si AutoML puede superar los resultados obtenidos por los científicos de datos humanos. Este documento compara el rendimiento de seis marcos de AutoML conocidos y de última generación en diez conjuntos de datos de phishing diferentes para ver si los modelos basados en AutoML pueden superar a los modelos de aprendizaje automático elaborados manualmente. Los resultados indican que los modelos basados en AutoML pueden superar a los modelos de aprendizaje automático desarrollados manualmente en tareas de clasificación complejas, específicamente en conjuntos de datos donde las características no son muy discriminatorias y conjuntos de datos con clases superpuestas o grados relativamente altos de no linealidad.
Reconocimiento facial 3D: una encuesta
El reconocimiento facial es uno de los temas de investigación más estudiados en la comunidad. En los últimos años, la investigación sobre el reconocimiento facial se ha desplazado hacia el uso de superficies faciales en 3D, ya que la información geométrica en 3D puede representar más características discriminatorias. Esta encuesta se centra en revisar las técnicas de reconocimiento facial en 3D desarrolladas en los últimos diez años, que generalmente se clasifican en métodos convencionales y métodos de aprendizaje profundo. Las técnicas categorizadas se evalúan mediante descripciones detalladas de las obras representativas. Las ventajas y desventajas de las técnicas se resumen en términos de precisión, complejidad y robustez para enfrentar la variación (expresión, pose y oclusiones, etc.). La principal contribución de esta encuesta es que cubre de manera integral tanto los métodos convencionales como los métodos de aprendizaje profundo en el reconocimiento facial 3D. Además, se proporciona una revisión de las bases de datos de rostros 3D disponibles, junto con la discusión de los desafíos y direcciones de la investigación futura.
Comprender la generalización de Adam en el aprendizaje de redes neuronales con una regularización adecuada
Los métodos de gradiente adaptativo como Adam han ganado una popularidad cada vez mayor en la optimización del aprendizaje profundo. Sin embargo, se ha observado que, en comparación con el descenso de gradiente (estocástico), Adam puede converger a una solución diferente con un error de prueba significativamente peor en muchas aplicaciones de aprendizaje profundo, como la clasificación de imágenes, incluso con una regularización ajustada. Este artículo proporciona una explicación teórica de este fenómeno: se muestra que en el entorno no convexo de aprendizaje de redes neuronales convolucionales de dos capas sobreparamizadas a partir de la misma inicialización aleatoria, para una clase de distribuciones de datos (inspiradas en datos de imágenes), Adam y el descenso de gradiente (GD) puede converger a diferentes soluciones globales del objetivo de entrenamiento con errores de generalización demostrablemente diferentes, incluso con la regularización del descenso de peso. Por el contrario, se muestra que si el objetivo de entrenamiento es convexo y se emplea la regularización de la disminución del peso, cualquier algoritmo de optimización, incluidos Adam y GD, convergerá en la misma solución si el entrenamiento es exitoso. Esto sugiere que el rendimiento de generalización inferior de Adam está fundamentalmente ligado al panorama no convexo de la optimización del aprendizaje profundo.

Suscríbase al boletín gratuito insideBIGDATA.
Únase a nosotros en Twitter: @ InsideBigData1 – https://twitter.com/InsideBigData1