

Con la enorme cantidad de datos que se generan cada día, se hace importante entender la complejidad del Big Data. Si estás planeando entrar en el mundo del Big Data, deberías estar familiarizado con los términos de Big Data. Estos términos te ayudarán a sumergirte en el mundo del Big Data. Así que, empecemos con el término Big Data en sí mismo –
Una definición precisa de «Big Data» es bastante difícil de concretar, ya que los profesionales de los negocios, proyectos, practicantes y vendedores lo toman de una manera diferente. Así que, en términos generales, el Big Data es:
- conjuntos de datos amplios/grandes (por conjunto de datos amplios se entiende un conjunto de datos demasiado grande para almacenarlo o procesarlo en una sola computadora) y
- la clasificación de las tecnologías y estrategias informáticas que se utilizan para conferir grandes conjuntos de datos.
Big Data es un amplio espectro y hay mucho que aprender. Aquí están los términos de Big Data, con los que deberías estar familiarizado.
Términos de Big Data: El Glosario de Big Data
Cada campo tiene su propia terminología y por lo tanto, hay un número de términos de Big Data que hay que conocer al comenzar una carrera en Big Data. Una vez que te familiarices con estos términos y definiciones de Big Data, estarás preparado para aprenderlos en detalle. En este artículo, vamos a definir los términos de Big Data que debes saber para comenzar una carrera en Big Data.
A
1. Algoritmo
En informática y matemáticas, un algoritmo es una especificación categórica y efectiva de cómo resolver un problema complejo y cómo realizar un análisis de datos. Consiste en múltiples pasos para aplicar operaciones sobre los datos con el fin de resolver un problema particular.
2. (AI) Inteligencia artificial
El popular término Big Data, Inteligencia Artificial es la inteligencia demostrada por las máquinas. La IA es el desarrollo de sistemas informáticos para realizar tareas que normalmente tienen inteligencia humana como el reconocimiento de voz, la percepción visual, la toma de decisiones y los traductores de idiomas, etc.
3. (AIDC) Identificación automática y captura de datos
La identificación automática y la captura de datos (AIDC) es el gran término de datos que se refiere a un método de identificación y recolección automática de objetos de datos a través de un algoritmo de computación y su posterior almacenamiento en la computadora. Por ejemplo, la identificación por radiofrecuencia, los códigos de barras, la biometría, el reconocimiento óptico de caracteres y las bandas magnéticas incluyen algoritmos para la identificación de los objetos de datos capturados.
4. Avro
Avro es un marco de serialización de datos y una llamada de procedimiento remoto desarrollado para el proyecto de Hadoop. Utiliza JSON para definir protocolos y tipos de datos y luego serializa los datos en forma binaria. Avro proporciona ambos:
- Formato de serialización para datos persistentes.
- Formato de cable para la comunicación entre los nodos Hadoop y de los programas de clientes a los servicios Hadoop.
B
5. Behavioral Analytics
La analítica del comportamiento es un avance reciente en la analítica de negocios que presenta nuevos conocimientos sobre el comportamiento de los clientes en plataformas de comercio electrónico, aplicaciones web/móviles, juegos en línea, etc. Permite a los vendedores hacer ofertas adecuadas a los clientes adecuados en el momento adecuado.
6. Business Intelligence
La Inteligencia Empresarial es un conjunto de herramientas y metodologías que pueden analizar, manejar y entregar información relevante para el negocio. Incluye herramientas de reporte/consulta y un panel de control como los que se encuentran en los análisis. Las tecnologías de BI proveen vistas previas, actuales y futuras de las operaciones del negocio.
7. Big Data Scientist
Big Data Scientist es una persona que puede tomar puntos de datos estructurados y no estructurados y utilizar sus formidables habilidades en estadística, matemáticas y programación para organizarlos. Aplica todo su poder analítico (comprensión contextual, conocimiento de la industria y comprensión de los supuestos existentes) para descubrir las soluciones ocultas para el desarrollo de los negocios.
8. Biometrics
La biometría es la tecnología de James Bondish unida a la analítica para identificar a las personas por uno o más rasgos físicos. Por ejemplo, la tecnología biométrica se utiliza en el reconocimiento facial, el reconocimiento de huellas dactilares, el reconocimiento del iris, etc.
C
9. Cascading
La cascada es la capa para la abstracción de software que proporciona el mayor nivel de abstracción para Apache Hadoop y Apache Flink. Es un marco de trabajo de código abierto que está disponible bajo la licencia de Apache. Se utiliza para permitir a los desarrolladores realizar el procesamiento de datos complejos de forma fácil y rápida en lenguajes basados en JVM como Java, Clojure, Scala, Rubi, etc.
10. Call Detail Record (CDR) Analysis
El CDR contiene metadatos, es decir, datos sobre los datos que una empresa de telecomunicaciones recoge sobre las llamadas telefónicas, como la duración y la hora de la llamada. El análisis del CDR proporciona a las empresas los detalles exactos sobre cuándo, dónde y cómo se realizan las llamadas con fines de facturación y presentación de informes. Los metadatos del CDR dan información sobre
- Cuando se hacen las llamadas (fecha y hora)
- Cuánto tiempo duró la llamada (en minutos)
- Quién llamó a quién (Número de contacto de la fuente y el destino)
- Tipo de llamada (entrante, saliente o gratuita)
- Cuánto cuesta la llamada (en base a la tarifa por minuto)
11. Cassandra
Cassandra es un sistema de gestión de bases de datos NoSQL de código abierto y distribuido. Está diseñado para gestionar una gran cantidad de datos distribuidos en servidores de productos básicos, ya que proporciona una alta disponibilidad de servicios sin punto de fallo. Fue desarrollado inicialmente por Facebook y luego estructurado en forma de valor clave bajo la fundación Apache.
12. Cell Phone Data
Los datos de los teléfonos móviles han surgido como una de las grandes fuentes de datos, ya que generan una enorme cantidad de datos y gran parte de ellos están disponibles para su uso con aplicaciones analíticas.
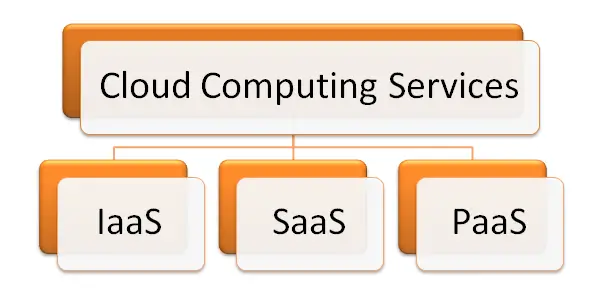
13. Cloud Computing
La computación en la nube es uno de los grandes términos de datos más conocidos. Es un nuevo paradigma de sistema de computación que ofrece la visualización de los recursos de computación para ejecutar sobre el servidor remoto estándar para el almacenamiento de datos y proporciona IaaS, PaaS y SaaS. La computación en nube proporciona recursos de TI como infraestructura, software, plataforma, base de datos, almacenamiento y así sucesivamente como servicios. Escalamiento flexible, rápida elasticidad, puesta en común de recursos, autoservicio bajo demanda son algunos de sus servicios.
14. Cluster Analysis
El análisis de clusters es el gran término de datos relacionado con el proceso de agrupación de objetos similares entre sí en el grupo común (cluster). Se hace para entender las similitudes y diferencias entre ellos. Es la importante tarea de la minería de datos exploratoria, y las estrategias comunes para analizar los datos estadísticos en varios campos como el análisis de imágenes, el reconocimiento de patrones, el aprendizaje automático, los gráficos por ordenador, la compresión de datos y así sucesivamente.
15. Chukwa
Apache Chukwa es un sistema de código abierto de recogida de registros a gran escala para la supervisión de grandes sistemas distribuidos. Es uno de los grandes términos comunes de datos relacionados con el Hadoop. Está construido sobre el Sistema de Archivos Distribuidos Hadoop (HDFS) y el marco de trabajo Map/Reduce. Hereda la robustez y escalabilidad de Hadoop. Chukwa contiene una poderosa y flexible base de datos de herramientas para monitorear, mostrar y analizar los resultados, de manera que los datos recolectados puedan ser utilizados de la mejor manera posible.
16. Columnar Database / Column-Oriented Database
Una base de datos que almacena los datos columna por columna en lugar de la fila se conoce como la base de datos orientada a la columna.
17. Comparative Analytic-oriented Database
El análisis comparativo es un tipo especial de tecnología de minería de datos que compara grandes conjuntos de datos, procesos múltiples u otros objetos utilizando estrategias estadísticas como el filtrado, el análisis de árboles de decisión, el análisis de patrones, etc.
18. Complex Event Processing (CEP)
El procesamiento de eventos complejos (CEP) es el proceso de analizar e identificar datos y luego combinarlos para inferir eventos que puedan sugerir soluciones a las complejas circunstancias. La principal tarea del CEP es identificar/rastrear eventos significativos y reaccionar ante ellos lo antes posible.
D
19. Data Analyst
El analista de datos se encarga de reunir, procesar y realizar el análisis estadístico de los datos. El analista de datos descubre las formas en que estos datos pueden ser utilizados para ayudar a la organización a tomar mejores decisiones de negocios. Es uno de los grandes términos de datos que definen una gran carrera de datos. El analista de datos trabaja con los usuarios finales de la empresa para definir los tipos de informe analítico que se requieren en los negocios.
20. Data Aggregation
La agregación de datos se refiere a la reunión de datos de múltiples fuentes para reunir todos los datos en un ateneo común a los efectos de la presentación de informes y/o el análisis.
El conocimiento de uno de los lenguajes de programación de alto nivel es necesario para construir una carrera en Big Data. Veamos cuáles son los 3 principales lenguajes de programación de Big Data para ti!
21. Dashboard
Es una representación gráfica del análisis realizado por los algoritmos. Este informe gráfico muestra alertas de diferentes colores para mostrar el estado de la actividad. Una luz verde es para las operaciones normales, una luz amarilla muestra que hay algún impacto debido a la operación y una luz roja significa que la operación ha sido detenida. Esta alerta con diferentes luces ayuda a seguir el estado de las operaciones y a conocer los detalles siempre que sea necesario.
22. Data Scientist
Data Scientist es también un gran término de datos que define una gran carrera de datos. Un científico de datos es un profesional de la ciencia de los datos. Es competente en matemáticas, estadística, informática y/o visualización de datos que establece modelos de datos y algoritmos para problemas complejos para resolverlos.
23. Data Architecture and Design
En la industria de la tecnología de la información, la arquitectura de los datos consiste en modelos, políticas, normas o reglas que controlan qué datos se agregan y cómo se organizan, almacenan, integran y utilizan en los sistemas de datos. Tiene tres fases
- Representación conceptual de las entidades comerciales
- La representación lógica de las relaciones entre entidades comerciales
- La construcción física del sistema de apoyo funcional
24. Database administrator (DBA)
DBA es el gran término de datos relacionado con una función que incluye la planificación de la capacidad, la configuración, el diseño de la base de datos, la supervisión del rendimiento, la migración, la solución de problemas, la seguridad, las copias de seguridad y la recuperación de datos. DBA es responsable de mantener y apoyar la rectitud del contenido y la estructura de una base de datos.
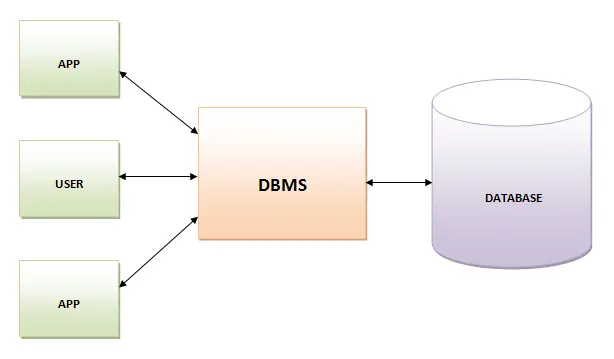
25. Database Management System (DBMS)
El Sistema de Gestión de Bases de Datos es un programa informático que recoge datos y proporciona acceso a ellos de forma organizada. Crea y administra la base de datos. El DBMS proporciona a los programadores y usuarios un proceso bien organizado para crear, actualizar, recuperar y gestionar los datos.
26. Data Model and Data Modelling
El modelo de datos es una fase inicial del diseño de una base de datos y suele consistir en atributos, tipos de entidades, reglas de integridad, relaciones y definiciones de objetos.
El modelado de datos es el proceso de creación de un modelo de datos para un sistema de información mediante el uso de ciertas técnicas formales. El modelado de datos se utiliza para definir y analizar los requisitos de datos para apoyar los procesos empresariales.
27. Data Cleansing
La limpieza de datos es un proceso de revisión de los datos para eliminar ortografías incorrectas, entradas duplicadas, agregar datos faltantes y proporcionar consistencia. Es necesario, ya que los datos incorrectos pueden llevar a un mal análisis y a conclusiones erróneas.
28. Document Management
La gestión de documentos, a menudo denominada Sistema de gestión de documentos es un software que se utiliza para rastrear, almacenar y gestionar documentos electrónicos y una imagen electrónica del papel a través de un escáner. Es uno de los términos básicos de Big Data que debes conocer para comenzar una carrera de Big Data.
29. Data Visualization
La visualización de datos es la presentación de datos en un formato gráfico o pictórico diseñado con el propósito de comunicar información o derivar un significado. Valida a los usuarios/decisores para ver la analítica visualmente de manera que puedan comprender los nuevos conceptos. Estos datos ayudan –
- para derivar la comprensión y el significado de los datos
- en la comunicación de datos e información de manera más eficaz
30. Data Warehouse
El almacén de datos es un sistema de almacenamiento de datos con fines de análisis y presentación de informes. Se cree que es el principal componente de la inteligencia comercial. Los datos almacenados en el almacén se cargan desde el sistema operativo como ventas o marketing.
31. Drill
El drill es un motor de consulta SQL de código abierto, distribuido y de baja latencia para Hadoop. Está construido para datos semi-estructurados o anidados y puede manejar esquemas fijos. El simulacro es similar en algunos aspectos al Dremel de Google y es manejado por Apache.
E
32. Extract, Transform, and Load (ETL)
ETL es la forma corta de tres funciones de base de datos: extraer, transformar y cargar. Estas tres funciones se combinan en una herramienta para colocarlas de una a otra base de datos.
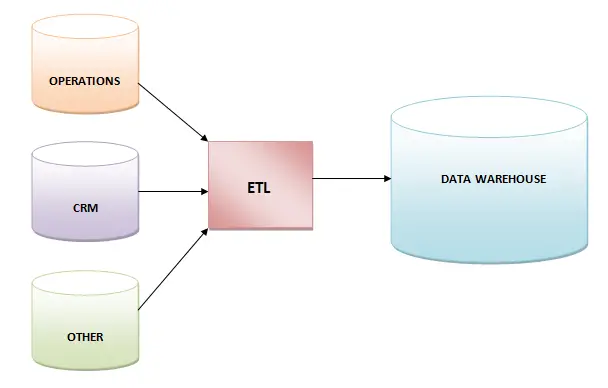
- Extract
Es el proceso de lectura de datos de una base de datos.
- Transform
Es el proceso de conversión de los datos extraídos en la forma deseada para que puedan ser puestos en otra base de datos.
- Load
Es el proceso de escribir datos en la base de datos de objetivos
F
33. Fuzzy Logic
La lógica difusa es una aproximación a la computación basada en grados de verdad en lugar del habitual álgebra booleana de verdadero/falso (1 o 0).
34. Flume
Flume se define como un servicio fiable, distribuido y disponible para agregar, recoger y transferir una gran cantidad de datos en el HDFS. Es robusto por naturaleza. La arquitectura del canal es de naturaleza flexible, basada en el flujo de datos.
G
35. Graph Database
Una base de datos de gráficos es un grupo/colección de bordes y nodos. Un nodo tipifica una entidad, es decir, una empresa o un individuo, mientras que un borde tipifica una relación o conexión entre nodos.
Debes recordar la declaración dada por los expertos en bases de datos de gráficos –
«Si puedes hacer una pizarra, puedes hacer un gráfico.»
36. Grid Computing
La computación en cuadrícula es un conjunto de recursos informáticos para realizar funciones de computación utilizando recursos de varios dominios o múltiples sistemas distribuidos para alcanzar un objetivo específico. Una grilla está diseñada para resolver grandes problemas para mantener la flexibilidad del proceso. La computación Grid se utiliza a menudo en la investigación científica/mercadeo, análisis estructural, servicios web como infraestructuras de back-office o banca ATM, etc.
37. Gamification
La gamificación se refiere a los principios utilizados en el diseño del juego para mejorar la participación de los clientes en negocios no relacionados con el juego. Diferentes empresas utilizan diferentes principios de juego para mejorar el interés en un servicio o producto o simplemente podemos decir que la gamificación se utiliza para profundizar la relación de su cliente con la marca.
H
38. Hadoop User Experience (HUE)
Hadoop User Experience (HUE) es una interfaz de código abierto que facilita el uso de Apache Hadoop. Es una aplicación basada en la web. Tiene un diseñador de trabajos para MapReduce, un navegador de archivos para HDFS, una aplicación Oozie para hacer flujos de trabajo y coordinadores, un Impala, un shell, una interfaz de usuario de Hive, y un grupo de APIs de Hadoop.
39. High-Performance Analytical Application (HANA)
La Aplicación Analítica de Alto Rendimiento es un esquema de software/hardware para transacciones de gran volumen y una plataforma de computación en memoria de análisis de datos en tiempo real del SAP.
40. HAMA
Hama es básicamente un marco de computación distribuido para el análisis de grandes datos basado en estrategias de Paralelo Sincrónico Masivo para cálculos avanzados y complejos como gráficos, algoritmos de red y matrices. Es un proyecto de alto nivel de la Fundación de Software Apache.
41. Hadoop Distributed File System (HDFS)
El Sistema de Archivo Distribuido Hadoop (HDFS) es la capa primaria de almacenamiento de datos utilizada por las aplicaciones Hadoop. Emplea la arquitectura DataNode y NameNode para implementar un sistema de archivos distribuido y basado en Java que proporciona un acceso de alto rendimiento a los datos con clusters Hadoop altamente escalables. Está diseñado para ser altamente tolerante a los fallos.
42. HBase
Apache HBase es la base de datos Hadoop que es una fuente abierta, escalable, versionada, distribuida y un gran almacén de datos. Algunas características de HBase son
- Escalabilidad modular y lineal.
- APIs Java fáciles de usar.
- Compartir tablas configurables y automáticas.
- Carcasa extensible de la JIRB.
43. Hive
Hive es un proyecto de software de código abierto de almacenamiento de datos basado en Hadoop para proporcionar resumen, análisis y consulta de datos. Los usuarios pueden escribir consultas en un lenguaje similar al SQL conocido como HiveQL. Hadoop es un marco de trabajo que maneja grandes conjuntos de datos en el entorno informático distribuido.
I
44. Impala
Impala es un motor de consulta SQL de código abierto MPP (procesamiento masivo en paralelo) que se utiliza en el clúster de computadoras para ejecutar Apache Hadoop. Impala proporciona una estrategia de base de datos paralela a Hadoop para que el usuario pueda aplicar consultas SQL de baja latencia a los datos que se almacenan en Apache HBase y HDFS sin ninguna transformación de datos.
K
45. Key Value Stores / Key Value Databases
El almacén de valores clave o base de datos de valores clave es un paradigma de almacenamiento de datos que se esquematiza para almacenar, gestionar y recuperar una estructura de datos. Los registros se almacenan en un tipo de datos de un lenguaje de programación con un atributo clave que identifica el registro de forma única. Por eso no se requiere un modelo de datos fijo.
L
46. Load balancing
El equilibrio de la carga es una herramienta que distribuye la cantidad de trabajo entre dos o más computadoras a través de una red de computadoras, de manera que el trabajo se completa en poco tiempo, ya que todos los usuarios desean ser atendidos más rápidamente. Es la razón principal de la agrupación de servidores informáticos y puede aplicarse con software o hardware o con la combinación de ambos.
47. Linked Data
Los datos vinculados se refieren a la recopilación de conjuntos de datos interconectados que pueden compartirse o publicarse en la web y colaborar con las máquinas y los usuarios. Está altamente estructurado, a diferencia del Big Data. Se utiliza en la construcción de la Web Semántica en la que una gran cantidad de datos están disponibles en el formato estándar de la web.
48. Location Analytics
El análisis de localización es el proceso de obtener información del componente geográfico o de la localización de los datos de negocio. Es el efecto visual del análisis e interpretación de la información que se presenta en los datos y permite al usuario conectar la información relacionada con la ubicación con el conjunto de datos.
49. Log File
Un archivo de registro es el tipo especial de archivo que permite a los usuarios llevar un registro de los eventos ocurridos o del sistema operativo o de la conversación entre los usuarios o de cualquier software en funcionamiento.
M
50. Metadata
Los metadatos son datos sobre datos. Son datos administrativos, descriptivos y estructurales que identifican los bienes.
51. MongoDB
MongoDB es un programa de base de datos de código abierto y orientado a documentos NoSQL. Utiliza documentos JSON para guardar estructuras de datos con un esquema ágil conocido como formato MongoDB BSON. Integra los datos en las aplicaciones de forma muy rápida y fácil.
52. Multi-Dimensional Database (MDB)
Una base de datos multidimensional (MDB) es un tipo de base de datos que está optimizada para las aplicaciones de OLAP (Online Analytical Processing) y el almacenamiento de datos. La MDB puede crearse fácilmente utilizando la entrada de una base de datos relacional. MDB es la capacidad de procesar los datos de la base de datos de manera que los resultados puedan desarrollarse rápidamente.
53. Multi-Value Database
La Base de Datos Multi-Valor es una especie de base de datos multidimensional y NoSQL que es capaz de comprender datos tridimensionales. Estas bases de datos son suficientes para manipular directamente cadenas XML y HTML.
Algunos ejemplos de bases de datos comerciales de valores múltiples son OpenQM, Rocket D3 Database Management System, jBASE, Intersystem Cache, OpenInsight, y InfinityDB.
54. Machine-Generated Data
Los datos generados por las máquinas son la información generada por las máquinas (computadora, aplicación, proceso u otro mecanismo inhumano). Los datos generados por máquinas se conocen como datos amorfos ya que los humanos raramente pueden modificar/cambiar estos datos.
55. Machine Learning
El aprendizaje automático es un campo de la informática que utiliza estrategias estadísticas para proporcionar la facilidad de «aprender» con los datos de la computadora. El aprendizaje automático se utiliza para explotar las oportunidades ocultas en el big data.
56. MapReduce
MapReduce es una técnica de procesamiento para procesar grandes conjuntos de datos con el algoritmo distribuido en paralelo en el cúmulo. Los trabajos de MapReduce son de dos tipos. La función «Map» se utiliza para dividir la consulta en múltiples partes y luego procesar los datos a nivel de nodos. La función «Reducir» recoge el resultado de la función «Mapa» y luego encuentra la respuesta a la consulta. La función «MapReduce» se utiliza para manejar grandes datos cuando se combina con el HDFS. Este acoplamiento de HDFS y MapReduce se denomina Hadoop.
57. Mahout
Apache Mahout es una biblioteca de minería de datos de código abierto. Utiliza algoritmos de minería de datos para pruebas de regresión, realización, agrupación, modelado estadístico, y luego los implementa utilizando el modelo MapReduce.
N
58. Network Analysis
El análisis de redes es la aplicación de la teoría de gráficos/tablas que se utiliza para categorizar, comprender y ver las relaciones entre los nodos en términos de red. Es una forma efectiva de analizar las conexiones y comprobar sus capacidades en cualquier campo como la predicción, el análisis de marketing, y el cuidado de la salud, etc.
59. NewSQL
NewSQL es una clase de sistema moderno de gestión de bases de datos relacionales que proporciona el mismo rendimiento escalable que los sistemas NoSQL para cargas de trabajo de lectura/escritura de OLTP. Es un sistema de base de datos bien definido que es fácil de aprender.
60. NoSQL
Ampliamente conocido como «No sólo SQL», es un sistema para la gestión de bases de datos. Este sistema de gestión de bases de datos es independiente del sistema de gestión de bases de datos relacionales. Una base de datos NoSQL no está construida sobre tablas, y no utiliza SQL para la manipulación de datos.
O
61. Object Databases
La base de datos que almacena datos en forma de objetos se conoce como la base de datos de objetos. Estos objetos se utilizan de la misma manera que los objetos utilizados en OOP. Una base de datos de objetos es diferente de las bases de datos gráficas y relacionales. Estas bases de datos proporcionan un lenguaje de consulta la mayoría de las veces que ayuda a encontrar el objeto con una declaración.
62. Object-based Image Analysis
Es el análisis de imágenes basadas en objetos que se realiza con datos tomados por píxeles relacionados seleccionados, conocidos como objetos de imagen o simplemente objetos. Es diferente del análisis digital que se realiza con datos de píxeles individuales.
63. Online Analytical Processing (OLAP)
Es el proceso por el cual el análisis de los datos multidimensionales se realiza utilizando tres operadores: drill-down, consolidación y slice and dice.
- El drill down es la capacidad que se proporciona a los usuarios para ver los detalles subyacentes
- La consolidación es el conjunto de los datos disponibles
- Slice and Dice es la capacidad que se ofrece a los usuarios para seleccionar subconjuntos y verlos desde diversos contextos
64. Online transactional processing (OLTP)
Es el término de big data utilizado para el proceso que proporciona a los usuarios un acceso al gran conjunto de datos transaccionales. Se hace de tal manera que los usuarios puedan obtener un significado de los datos a los que se accede.
65. Open Data Center Alliance (ODCA)
OCDA es la combinación de organizaciones de IT en todo el mundo. El objetivo principal de este consorcio es aumentar el movimiento de la computación en nube.
66. Operational Data Store (ODS)
Se define como un lugar para recoger y almacenar datos recuperados de diversas fuentes. Permite a los usuarios realizar muchas operaciones adicionales con los datos antes de que se envíen para su presentación al almacén de datos.
67. Oozie
Es el término de big data que se utiliza para un sistema de procesamiento que permite a los usuarios definir un conjunto de trabajos. Estos trabajos están escritos en diferentes idiomas como Pig, MapReduce y Hive. Oozie permite a los usuarios vincular esos trabajos entre sí.
P
68. Parallel Data Analysis
El proceso de descomponer un problema analítico en pequeñas particiones y luego ejecutar los algoritmos de análisis en cada una de las particiones simultáneamente se conoce como análisis paralelo de datos. Este tipo de análisis de datos puede ejecutarse en los diferentes sistemas o en el mismo sistema.
69. Parallel Method Invocation (PMI)
Es el sistema que permite al código del programa llamar o invocar múltiples métodos/funciones simultáneamente al mismo tiempo.
70. Parallel Processing
Es la capacidad de un sistema para realizar la ejecución de múltiples tareas simultáneamente.
71. Parallel Query
Una consulta paralela puede definirse como una consulta que puede ejecutarse en múltiples hilos del sistema para mejorar el rendimiento.
72. Pattern Recognition
Un proceso para clasificar o etiquetar el patrón identificado en el proceso de aprendizaje de la máquina se conoce como reconocimiento de patrones.
73. Pentaho
Pentaho, una organización de software, proporciona productos de código abierto de Inteligencia de Negocios que se conocen como Pentaho Business Analytics. Pentaho ofrece servicios OLAP, integración de datos, tableros, reportes, ETL y capacidades de minería de datos.
74. Petabyte
La unidad de medida de los datos equivale a 1.024 terabytes o 1 millón de gigabytes se conoce como petabyte.
Q
75. Query
Una consulta es un método para obtener algún tipo de información con el fin de obtener una respuesta a la pregunta.
76. Query Analysis
El proceso para realizar el análisis de la consulta de búsqueda se llama análisis de consulta. El análisis de la consulta se hace para optimizar la consulta para obtener los mejores resultados posibles.
R
77. R
Es un lenguaje de programación y un entorno para los gráficos y la computación estadística. Es un lenguaje muy extensible que proporciona una serie de técnicas gráficas y estadísticas como el modelado no lineal y lineal, el análisis de series temporales, las pruebas estadísticas clásicas, la agrupación, la clasificación, etc.
78. Re-identification
La reidentificación de los datos es un proceso que hace coincidir los datos anónimos con los datos o información auxiliar disponible. Esta práctica es útil para averiguar a quién pertenecen estos datos.
79. Real-time Data
Los datos que pueden ser creados, almacenados, procesados, analizados y visualizados instantáneamente, es decir, en milisegundos, se conocen como datos en tiempo real.
80. Reference Data
Es el gran término de datos que define los datos utilizados para describir un objeto junto con sus propiedades. El objeto descrito por los datos de referencia puede ser de naturaleza virtual o física.
81. Recommendation Engine
Es un algoritmo que realiza el análisis de varias acciones y compras realizadas por un cliente en un sitio web de comercio electrónico. Los datos analizados se utilizan para recomendar al cliente algunos productos complementarios.
82. Risk Analysis
Es un proceso o procedimiento para rastrear los riesgos de una acción, proyecto o decisión. El análisis de riesgos se realiza aplicando diferentes técnicas estadísticas a los conjuntos de datos.
83. Routing Analysis
Es un proceso o procedimiento para encontrar la ruta optimizada. Se hace con el uso de varias variables para el transporte para mejorar la eficiencia y reducir los costos del combustible.
S
84. SaaS
Es el gran término de datos que se usa para el Software como un Servicio (Software-as-a-Service). Permite a los vendedores alojar una aplicación y luego hacerla disponible en Internet. Los servicios SaaS son proporcionados en la nube por los proveedores de SaaS.
85. Semi-Structured Data
Los datos, no representados de la manera tradicional con la aplicación de los métodos regulares, se conocen como datos semiestructurados. Estos datos no están ni totalmente estructurados ni desestructurados, pero contienen algunas etiquetas, tablas de datos y elementos estructurales. Pocos ejemplos de datos semiestructurados son los documentos XML, los correos electrónicos, las tablas y los gráficos.
86. Server
El servidor es una computadora virtual o física que recibe solicitudes relacionadas con la aplicación de software y, por lo tanto, envía estas solicitudes a través de una red. Es el término común para Big Data que se utiliza casi en todas las grandes tecnologías de datos.
87. Spatial Analysis
El análisis de los datos espaciales, es decir, de los datos topológicos y geográficos, se conoce como análisis espacial. Este análisis ayuda a identificar y comprender todo lo relacionado con un área o posición en particular.
88. Structured Query Language (SQL)
SQL es un lenguaje de programación estándar que se utiliza para recuperar y gestionar datos en una base de datos relacional. Este lenguaje es muy útil para crear y consultar bases de datos relacionales.
89. Sqoop
Es una herramienta de conectividad que se usa para mover datos de almacenes de datos no Hadoop a almacenes de datos Hadoop. Esta herramienta instruye a Sqoop para recuperar datos de Teradata, Oracle o cualquier otra base de datos relacional y para especificar el destino del objetivo en Hadoop para mover los datos recuperados.
90. Storm
Apache Storm es un sistema de computación distribuido, de código abierto y en tiempo real que se utiliza para el procesamiento de datos. Es uno de los grandes términos de datos más conocidos, responsable de procesar datos no estructurados de manera fiable en tiempo real.
T
91. Text Analytics
El análisis de texto es básicamente el proceso de aplicación de técnicas lingüísticas, de aprendizaje automático y estadísticas sobre las fuentes basadas en el texto. El análisis de texto se utiliza para obtener una visión o significado de los datos del texto mediante la aplicación de estas técnicas.
92. Thrift
Se trata de un framework de software que se utiliza para el desarrollo de los servicios ascendentes de idiomas cruzados. Integra el motor de generación de código con la pila de software para desarrollar servicios que pueden funcionar sin problemas y de manera eficiente entre diferentes lenguajes de programación como Ruby, Java, PHP, C++, Python, C# y otros.
U
93. Unstructured Data
Los datos para los que no se puede definir la estructura se conocen como datos no estructurados. Se hace difícil procesar y gestionar los datos no estructurados. Los ejemplos comunes de datos no estructurados son el texto introducido en los mensajes de correo electrónico y las fuentes de datos con textos, imágenes y vídeos.
V
94. Value
Este término de big data define básicamente el valor de los datos disponibles. Los datos recopilados y almacenados pueden ser valiosos para las sociedades, los clientes y las organizaciones. Es uno de los términos importantes de Big Data ya que el Big Data están destinados a las grandes empresas y las empresas obtendrán algún valor, es decir, beneficios del Big Data.
95. Volume
Este término de big data está relacionado con la cantidad total disponible de los datos. Los datos pueden variar desde megabytes hasta brontobytes.
W
96. WebHDFS Apache Hadoop
WebHDFS es un protocolo de acceso a HDFS para hacer uso del mecanismo RESTful de la industria. Contiene bibliotecas nativas y por lo tanto permite tener un acceso del HDFS. Ayuda a los usuarios a conectarse al HDFS desde el exterior aprovechando el paralelismo del clúster Hadoop. También ofrece el acceso de los servicios web estratégicamente a todos los componentes del Hadoop.
97. Weather Data
Los datos de tendencias y patrones que ayudan a rastrear la atmósfera se conocen como datos meteorológicos. Estos datos consisten básicamente en números y factores. Ahora se dispone de datos en tiempo real que pueden ser utilizados por las organizaciones de una manera diferente. Por ejemplo, una empresa de logística utiliza los datos meteorológicos para optimizar el transporte de mercancías.
X
98. XML Databases
Las bases de datos que admiten el almacenamiento de datos en formato XML se conocen como base de datos XML. Estas bases de datos suelen estar conectadas con las bases de datos específicas de los documentos. Se puede exportar, serializar y consultar los datos de la base de datos XML.
Y
99. Yottabyte
Es un término de big data relacionado con la medición de datos. Un yottabyte equivale a 1000 zettabytes o los datos almacenados en 250 trillones de DVDs.
Z
100. ZooKeeper
Es un proyecto de software Apache y un subproyecto Hadoop que proporciona generación de nombres de código abierto para los sistemas distribuidos. También apoya la organización consolidada de los sistemas distribuidos de gran tamaño.
101. Zettabyte
Es el gran término de datos relacionado con la medición de datos. Un zettabyte es igual a 1.000 millones de terabytes o 1.000 exabytes.
En resumen
Big data no es sólo una palabra de moda, sino un término amplio que tiene mucho que aprender. Por lo tanto, hemos enlistado y descrito estos términos de Big Data que serán útiles en tu carrera de big data. Sin mencionar que es importante validar tus habilidades y conocimientos sobre Big Data para la brillante carrera. Y las certificaciones de Big Data están destinadas a demostrar tus grandes habilidades en datos a los empleadores.
Whizlabs, el pionero en el entrenamiento de certificaciones de Big Data, está dirigido a ayudarle a aprender y a certificarse en tecnologías de Big Data. Ya sea que usted sea un profesional de Hadoop o Spark, la capacitación en línea de Whizlabs para la certificación de Administrador de Hadoop (HDPCA), Desarrollador de Spark (HDPCD) y Administrador de CCA lo preparará para un futuro brillante!