

En este artículo mensual recurrente, filtramos los documentos de investigación recientes que aparecen en el servidor de preimpresión de arXiv.org en busca de temas convincentes relacionados con la IA, el aprendizaje de las máquinas y el aprendizaje profundo – de disciplinas como la estadística, las matemáticas y la informática – y le proporcionamos una útil lista de «lo mejor» del mes pasado. Investigadores de todo el mundo contribuyen a este repositorio como preludio al proceso de revisión por pares para su publicación en revistas tradicionales. arXiv contiene un verdadero tesoro de métodos de aprendizaje estadístico que usted podrá utilizar algún día en la solución de problemas de la ciencia de los datos. Los artículos que se enumeran a continuación representan una pequeña fracción de todos los artículos que aparecen en el servidor de preimpresión. Están listados sin un orden particular con un enlace a cada artículo junto con un breve resumen. Se proporcionan enlaces a los repositorios de GitHub cuando están disponibles. Los artículos especialmente relevantes están marcados con un icono de «pulgar hacia arriba». Considere que estos son artículos de investigación académica, típicamente dirigidos a estudiantes graduados, postdoctorados y profesionales experimentados. Generalmente contienen un alto grado de matemáticas, así que prepárense. ¡Disfruten!
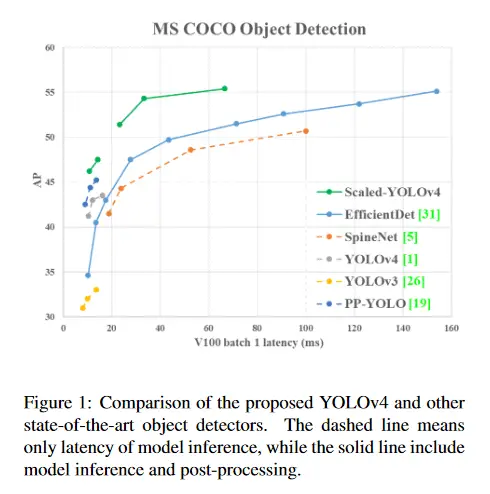
Scaled-YOLOv4: Red Parcial de Escala Transversal
Este documento muestra que la red neural de detección de objetos YOLOv4, basada en el enfoque CSP, se escala tanto hacia arriba como hacia abajo y es aplicable a redes pequeñas y grandes manteniendo una velocidad y precisión óptimas. Se propone un enfoque de escalamiento de la red que modifica no sólo la profundidad, el ancho y la resolución, sino también la estructura de la red. El modelo YOLOv4-grande logra resultados de última generación: 55,4% AP (73,3% AP50) para el conjunto de datos de MS COCO a una velocidad de 15 FPS en el Tesla V100, mientras que con el aumento del tiempo de prueba, YOLOv4-large logra un 55,8% AP (73,2 AP50). Hasta donde sabemos, esta es actualmente la mayor precisión en el conjunto de datos COCO entre cualquier trabajo publicado. El modelo YOLOv4-tiny alcanza un 22,0% AP (42,0% AP50) a una velocidad de 443 FPS en el RTX 2080Ti, mientras que usando el TensorRT, tamaño de lote = 4 y precisión FP16 el YOLOv4-tiny alcanza 1774 FPS. El código asociado a este documento se puede encontrar AQUÍ.
DeepMind Lab2D
Este artículo presenta DeepMind Lab2D, un simulador de entorno escalable para la investigación de la inteligencia artificial que facilita la experimentación dirigida por el investigador con el diseño del entorno. DeepMind Lab2D fue construido teniendo en cuenta las necesidades específicas de los investigadores del aprendizaje de refuerzo profundo de múltiples agentes, pero también puede ser útil más allá de ese subcampo en particular. El código asociado a este trabajo se puede encontrar AQUÍ.
CompressAI: una biblioteca de PyTorch y una plataforma de evaluación para la investigación de la compresión de extremo a extremo
En este documento se presenta CompressAI, una plataforma que proporciona operaciones personalizadas, capas, modelos y herramientas para investigar, desarrollar y evaluar códecs de compresión de imagen y vídeo de extremo a extremo. En particular, CompressAI incluye modelos y herramientas de evaluación previamente capacitados para comparar los métodos aprendidos con los códecs tradicionales. Así pues, se han reimplantado en PyTorch múltiples modelos de la compresión de extremo a extremo aprendida y se han entrenado desde cero. El documento también informa de los resultados de la comparación objetiva utilizando la métrica PSNR y MS-SSIM frente a la velocidad de bits, utilizando el conjunto de datos de imágenes Kodak como conjunto de pruebas. Aunque este marco implementa actualmente modelos para la compresión de imágenes fijas, se pretende ampliarlo pronto al dominio de la compresión de vídeo.

Modelo de transformador de dos etapas para COVID-19 Detección de noticias falsas y comprobación de hechos
El rápido avance de la tecnología en la comunicación en línea a través de las plataformas de medios sociales ha dado lugar a un prolífico aumento de la difusión de información errónea y noticias falsas. Las noticias falsas son especialmente frecuentes en la actual pandemia COVID-19, lo que hace que la gente crea en afirmaciones e historias falsas y potencialmente dañinas. Detectar rápidamente las noticias falsas puede aliviar la propagación del pánico, el caos y los posibles peligros para la salud. En este documento se describe el desarrollo de una tubería automatizada en dos etapas para la detección de noticias falsas de COVID-19 utilizando modelos de aprendizaje automático de última generación para el procesamiento del lenguaje natural. El primer modelo aprovecha un novedoso algoritmo de comprobación de hechos que recupera los hechos más relevantes relativos a las afirmaciones de los usuarios sobre determinadas afirmaciones de COVID-19. El segundo modelo verifica el nivel de verdad de la afirmación calculando la relación textual entre la afirmación y los hechos reales recuperados de un conjunto de datos de COVID-19 curados manualmente. El conjunto de datos se basa en una fuente de conocimiento disponible públicamente que consiste en más de 5.000 afirmaciones falsas y explicaciones verificadas de COVID-19, un subconjunto de las cuales fue anotado internamente y validado de forma cruzada para entrenar y evaluar nuestros modelos. Se desarrollan una serie de modelos basados en características clásicas de texto a modelos más contextuales basados en Transformadores y se observa que un modelo pipeline basado en BERT y ALBERT para las dos etapas respectivamente da los mejores resultados.

Analizando el proceso de revisión de la Conferencia de Aprendizaje Automático
En los últimos años, las conferencias sobre aprendizaje automático han aumentado drásticamente el número de participantes, así como la variedad de perspectivas. Es probable que los miembros de la comunidad de aprendizaje automático escuchen por casualidad acusaciones que van desde la aleatoriedad de las decisiones de aceptación hasta el sesgo institucional. En el presente documento se analiza críticamente el proceso de examen mediante un estudio exhaustivo de los documentos presentados al ICLR entre 2017 y 2020. El documento cuantifica la reproducibilidad/aleatoriedad en las puntuaciones de la revisión y las decisiones de aceptación, y examina si las puntuaciones se correlacionan con el impacto del documento. Los resultados sugieren un fuerte sesgo institucional en las decisiones de aceptación/rechazo, incluso después de controlar la calidad del papel. Además, se encuentran pruebas de una brecha de género, ya que las autoras femeninas reciben puntuaciones más bajas, tasas de aceptación más bajas y menos citaciones por papel que sus homólogos masculinos. El documento concluye con recomendaciones para los futuros organizadores de la conferencia.
Cuando el aprendizaje automático se une a la privacidad: Una encuesta y una perspectiva

Los nuevos métodos de aprendizaje automático (por ejemplo, el aprendizaje profundo) se han convertido en una fuerte fuerza motriz para revolucionar una amplia gama de industrias, como la atención sanitaria inteligente, la tecnología financiera y los sistemas de vigilancia. Mientras tanto, la privacidad ha surgido como una gran preocupación en esta era de inteligencia artificial basada en el aprendizaje automático. Es importante señalar que el problema de la preservación de la privacidad en el contexto del aprendizaje automático es muy diferente del de la protección tradicional de la privacidad de los datos, ya que el aprendizaje automático puede actuar tanto como amigo como enemigo. Actualmente, la labor de preservación de la privacidad y el aprendizaje automático (ML) se encuentra todavía en una etapa inicial, ya que la mayoría de las soluciones existentes sólo se centran en los problemas de privacidad durante el proceso de aprendizaje automático. Por lo tanto, se requiere un estudio exhaustivo sobre los problemas de preservación de la privacidad y el aprendizaje automático. En el presente documento se examina el estado actual de las cuestiones de privacidad y las soluciones para el aprendizaje automático. El estudio abarca tres categorías de interacciones entre la privacidad y el aprendizaje automático: i) aprendizaje automático privado, ii) protección de la privacidad con ayuda del aprendizaje automático y iii) ataque a la privacidad basado en el aprendizaje automático y los correspondientes esquemas de protección. Se examinan los progresos actuales de la investigación en cada categoría y se identifican los principales problemas. Por último, sobre la base de un análisis a fondo de la esfera de la privacidad y el aprendizaje automático, en el documento se señalan las orientaciones futuras de la investigación en este ámbito.
Sobre la convergencia del aprendizaje de refuerzo
En este trabajo se considera el problema del aprendizaje de refuerzo para los sistemas dinámicos estocásticos no lineales. Se muestra que en el escenario de RL, hay una inherente «Maldición de la Varianza» además de la infame «Maldición de la Dimensionalidad» de Bellman, en particular, se muestra que la varianza en la solución crece factorialmente-exponencialmente en el orden de la aproximación. Una consecuencia fundamental es que esto impide la búsqueda de cualquier otra cosa que no sean soluciones de retroalimentación «locales» en RL, con el fin de controlar el crecimiento explosivo de la varianza, y así, asegurar la exactitud. Se demuestra además que el control óptimo determinístico tiene una estructura de perturbación, en el sentido de que los términos de orden superior no afectan al cálculo de los términos de orden inferior, que pueden utilizarse en RL para obtener soluciones locales precisas.

Suscríbete al boletín de noticias gratuito de InsideBIGDATA.
Únete a nosotros en Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1