

En esta función mensual recurrente, filtramos artículos de investigación recientes que aparecen en el servidor de preimpresión arXiv.org por temas atractivos relacionados con la inteligencia artificial, el aprendizaje automático y el aprendizaje profundo, de disciplinas que incluyen estadística, matemáticas y ciencias de la computación, y le brindamos un «mejor de ”lista durante el último mes. Investigadores de todo el mundo contribuyen a este repositorio como antesala del proceso de revisión por pares para su publicación en revistas tradicionales. arXiv contiene un verdadero tesoro de métodos de aprendizaje estadístico que puede usar algún día en la solución de problemas de ciencia de datos. Los artículos que se enumeran a continuación representan una pequeña fracción de todos los artículos que aparecen en el servidor de preimpresión. Se enumeran sin ningún orden en particular con un enlace a cada documento junto con una breve descripción general. Se proporcionan enlaces a repositorios de GitHub cuando están disponibles. Los artículos especialmente relevantes están marcados con un icono de «pulgar hacia arriba». Tenga en cuenta que estos son trabajos de investigación académica, generalmente dirigidos a estudiantes graduados, postdoctorados y profesionales experimentados. Por lo general, contienen un alto grado de matemáticas, así que prepárate. ¡Disfrutar!
Comprender y evitar las fallas de la IA: una guía práctica
A medida que las tecnologías de IA aumentan en capacidad y ubicuidad, los accidentes de IA se vuelven más comunes. Basado en la teoría de accidentes normales, la teoría de alta confiabilidad y la teoría de sistemas abiertos, este documento crea un marco para comprender los riesgos asociados con las aplicaciones de IA. Además, los investigadores también utilizan los principios de seguridad de la IA para cuantificar los riesgos únicos de una mayor inteligencia y cualidades humanas en la IA. Juntos, estos dos campos ofrecen una imagen más completa de los riesgos de la IA contemporánea. Al centrarse en las propiedades del sistema cerca de accidentes en lugar de buscar la causa raíz de los accidentes, el documento identifica dónde se debe prestar atención a la seguridad de los sistemas de inteligencia artificial de la generación actual.
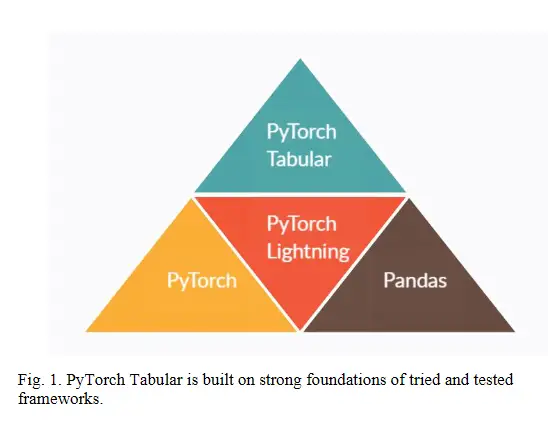
PyTorch Tabular: un marco para el aprendizaje profundo con datos tabulares

A pesar de mostrar una efectividad irrazonable en modalidades como Texto e Imagen, el Aprendizaje Profundo siempre se ha quedado rezagado en el aumento de gradiente en los datos tabulares, tanto en popularidad como en rendimiento. Pero recientemente se han creado modelos más nuevos específicamente para datos tabulares, lo que está empujando la barra de rendimiento. Pero la popularidad sigue siendo un desafío porque no existe una biblioteca fácil y lista para usar como Sci-Kit Learn para el aprendizaje profundo. PyTorch Tabular es una nueva biblioteca de aprendizaje profundo que hace que trabajar con el aprendizaje profundo y los datos tabulares sea fácil y rápido. Es una biblioteca construida sobre PyTorch y PyTorch Lightning y funciona directamente en marcos de datos de pandas. Muchos modelos SOTA como NODE y TabNet ya están integrados e implementados en la biblioteca con una API unificada. PyTorch Tabular está diseñado para ser fácilmente extensible para los investigadores, simple para los profesionales y robusto en implementaciones industriales.
Red generativa de adversarios: algunas perspectivas analíticas
Desde su debut, las redes generativas de confrontación (GAN) han atraído una enorme cantidad de atención. En los últimos años, se han desarrollado diferentes variaciones de modelos de GAN y se han adaptado a diferentes aplicaciones en la práctica. Mientras tanto, se han detectado e investigado algunos problemas relacionados con el desempeño y la formación de los GAN desde diversas perspectivas teóricas. Este documento comenzará con una introducción de las GAN desde una perspectiva analítica, luego avanzará en el entrenamiento de las GAN a través de aproximaciones SDE y finalmente discutirá algunas aplicaciones de las GAN en el cálculo de MFG de alta dimensión, así como en el abordaje de problemas financieros matemáticos.

Explorando el aprendizaje profundo bayesiano para la necesidad urgente de intervención del instructor en los foros MOOC
Los cursos masivos abiertos en línea (MOOC) se han convertido en una opción popular para el aprendizaje electrónico gracias a su gran flexibilidad. Sin embargo, debido a la gran cantidad de estudiantes y sus diversos orígenes, es agotador ofrecer asistencia en tiempo real. Los estudiantes pueden publicar sus sentimientos de confusión y lucha en los respectivos foros MOOC, pero con el gran volumen de publicaciones y la alta carga de trabajo para los instructores MOOC, es poco probable que los instructores puedan identificar a todos los estudiantes que requieren intervención. Este problema se ha estudiado recientemente como un problema de procesamiento del lenguaje natural (PNL) y se sabe que es un desafío debido al desequilibrio de los datos y la naturaleza compleja de la tarea. En este artículo, exploramos por primera vez el aprendizaje profundo bayesiano en publicaciones de texto basadas en el alumno con dos métodos: Abandono de Montecarlo e inferencia variacional, como una nueva solución para evaluar la necesidad de intervenciones del instructor para la publicación de un alumno. Este artículo compara modelos basados en métodos propuestos con modelos probabilísticos con sus modelos no bayesianos de línea base en circunstancias similares, para diferentes casos de aplicación de la predicción. Los resultados sugieren que el aprendizaje profundo bayesiano ofrece una medida de incertidumbre crítica que no es proporcionada por las redes neuronales tradicionales. Esto agrega más explicabilidad, confianza y robustez a la IA, que es crucial en las aplicaciones basadas en la educación.
Kit de herramientas de explicabilidad de TrustyAI
La inteligencia artificial (IA) se está volviendo cada vez más popular y se puede encontrar en lugares de trabajo y hogares de todo el mundo. Sin embargo, ¿cómo garantizamos la confianza en estos sistemas? Los cambios en la regulación, como el GDPR, significan que los usuarios tienen derecho a comprender cómo se han procesado y guardado sus datos. Por lo tanto, si, por ejemplo, se le niega un préstamo, tiene derecho a preguntar por qué. Esto puede resultar difícil si el método para resolverlo utiliza técnicas de aprendizaje automático de «caja negra», como las redes neuronales. TrustyAI es una nueva iniciativa que busca soluciones de inteligencia artificial explicable (XAI) para abordar la confiabilidad en ML, así como los paisajes de servicios de decisión. Este documento analiza cómo TrustyAI puede respaldar la confianza en los servicios de decisión y los modelos predictivos. Investigamos técnicas como LIME, SHAP y contrafactuales, comparando tanto las técnicas LIME como las contrafactuales con implementaciones existentes.
Una breve encuesta de modelos de lenguaje previamente entrenados para la IA conversacional-A NewAge en PNL
La construcción de un sistema de diálogo que pueda comunicarse de forma natural con los humanos es un problema desafiante pero interesante de la computación basada en agentes. El rápido crecimiento en esta área generalmente se ve obstaculizado por el antiguo problema de la escasez de datos, ya que se espera que estos sistemas aprendan sintaxis, gramática, toma de decisiones y razonamiento a partir de cantidades insuficientes de conjuntos de datos específicos de tareas. Los modelos de lenguaje pre-entrenados recientemente introducidos tienen el potencial de abordar el problema de la escasez de datos y brindan ventajas considerables al generar incrustaciones de palabras contextualizadas. Estos modelos se consideran contrapartes de ImageNet en PNL y han demostrado capturar diferentes facetas del lenguaje, como las relaciones jerárquicas, la dependencia a largo plazo y el sentimiento. Este breve artículo de encuesta analiza el progreso reciente realizado en el campo de los modelos lingüísticos previamente entrenados.
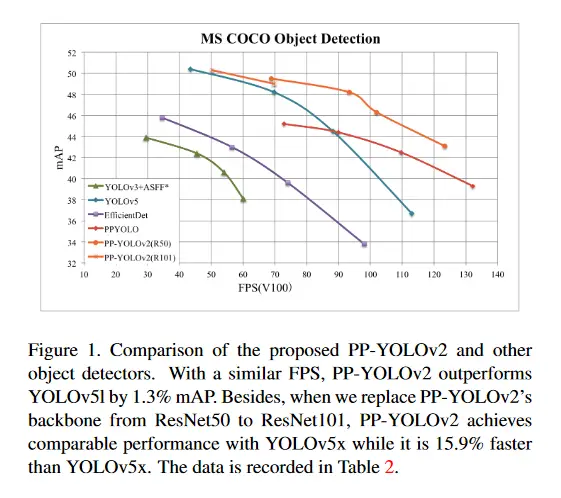
PP-YOLOv2: un detector de objetos práctico
Ser efectivo y eficiente es esencial para un uso práctico de un detector de objetos. Para satisfacer estas dos inquietudes, este documento evalúa de manera integral una colección de mejoras existentes para mejorar el desempeño de PP-YOLO mientras casi mantiene el tiempo de inferir sin cambios. El documento analiza una colección de refinamientos y evalúa empíricamente su impacto en el rendimiento del modelo final a través del estudio de ablación incremental. También se discutirán las cosas que se probaron que no funcionaron. El código fuente asociado con este documento se puede encontrar AQUÍ.
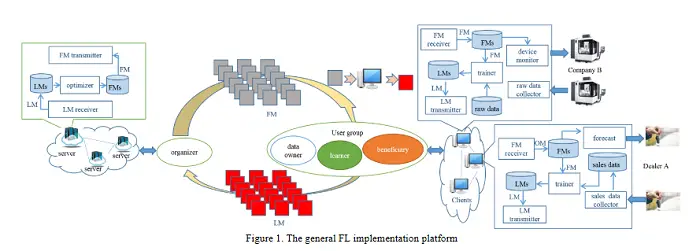
Una encuesta sobre el aprendizaje federado y sus aplicaciones para acelerar el Internet de las cosas industrial
El aprendizaje federado (FL) lleva la inteligencia colaborativa a las industrias sin datos de capacitación centralizados para acelerar el proceso de la Industria 4.0 en el nivel de la informática de punta. FL resuelve el dilema en el que las empresas desean hacer uso de la inteligencia de datos con preocupaciones de seguridad. Para acelerar el Internet de las cosas industrial con el mayor apalancamiento de FL, los logros existentes en FL se desarrollan a partir de tres aspectos: 1) definir terminologías y elaborar un marco general de FL para acomodar varios escenarios; 2) discutir el estado del arte de FL en investigaciones fundamentales que incluyen partición de datos, preservación de la privacidad, optimización de modelos, transporte de modelos locales, personalización, mecanismo de motivación, herramientas de plataforma y puntos de referencia; 3) discutir los impactos de FL desde la perspectiva económica. Para atraer más atención de la academia y la práctica industrial, en este documento se presenta un paradigma de fabricación transformado por FL, y también se proponen las direcciones de investigación futuras de FL y las posibles aplicaciones inmediatas en el dominio de la Industria 4.0.
Suscríbase al boletín gratuito insideBIGDATA.
Únase a nosotros en Twitter: @ InsideBigData1 – https://twitter.com/InsideBigData1