
El Biblioteca XGBoost proporciona una eficiente implementación de refuerzo de gradientes que puede ser configurado para entrenar conjuntos forestales aleatorios.
Bosque al azar es un algoritmo más simple que el aumento de gradiente. La biblioteca XGBoost permite entrenar los modelos de forma que se reproduzcan y aprovechen las eficiencias de cálculo implementadas en la biblioteca para entrenar modelos forestales aleatorios.
En este tutorial, descubrirás cómo utilizar la biblioteca XGBoost para desarrollar conjuntos forestales aleatorios.
Después de completar este tutorial, lo sabrás:
- XGBoost proporciona una eficiente implementación de refuerzo de gradientes que puede ser configurado para entrenar conjuntos forestales aleatorios.
- Cómo utilizar el API de XGBoost para entrenar y evaluar modelos de conjuntos forestales aleatorios para la clasificación y la regresión.
- Cómo afinar los hiperparámetros del modelo de conjunto forestal aleatorio XGBoost.
Empecemos.

Cómo desarrollar conjuntos forestales aleatorios con XGBoost
Foto de Jan Mosimann, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en cinco partes; son:
- Bosque aleatorio con XGBoost
- XGBoost API para Random Forest
- XGBoost Bosque aleatorio para la clasificación
- XGBoost Bosque aleatorio para la regresión
- XGBoost Hiperparámetros forestales aleatorios
Bosque aleatorio con XGBoost
XGBoost es una biblioteca de código abierto que proporciona una implementación eficiente del algoritmo de conjunto de aumento de gradiente, conocido como Extreme Gradient Boosting o XGBoost para abreviar.
Como tal, XGBoost se refiere al proyecto, la biblioteca y el propio algoritmo.
El aumento de gradiente es un algoritmo de primera elección para la clasificación y la regresión de los proyectos de modelado predictivo porque a menudo logra el mejor rendimiento. El problema con el aumento de gradiente es que a menudo es muy lento para entrenar un modelo, y el problema se exaspera por los grandes conjuntos de datos.
XGBoost aborda los problemas de velocidad del aumento de gradiente introduciendo una serie de técnicas que aceleran drásticamente el entrenamiento del modelo y a menudo dan como resultado un mejor rendimiento general del modelo.
Puedes aprender más sobre XGBoost en este tutorial:
Además de soportar el aumento de gradientes, el algoritmo central XGBoost también puede ser configurado para soportar otros tipos de algoritmos de conjunto de árboles, como el de bosque aleatorio.
El bosque aleatorio es un conjunto de algoritmos de árboles de decisión.
Cada árbol de decisión se ajusta a una muestra de la base de datos de entrenamiento. Se trata de una muestra del conjunto de datos de capacitación en la que se puede seleccionar más de una vez un determinado ejemplo (filas), lo que se denomina muestreo con sustitución.
Es importante considerar un subconjunto aleatorio de las variables de entrada (columnas) en cada punto de división del árbol. Esto asegura que cada árbol añadido al conjunto sea hábil, pero diferente de forma aleatoria. El número de características consideradas en cada punto de división es a menudo un pequeño subconjunto. Por ejemplo, en los problemas de clasificación, una heurística común consiste en seleccionar el número de rasgos igual a la raíz cuadrada del número total de rasgos, por ejemplo, 4 si un conjunto de datos tiene 20 variables de entrada.
Puedes aprender más sobre el algoritmo de conjunto de bosque aleatorio en el tutorial:
El principal beneficio de usar la biblioteca XGBoost para entrenar a conjuntos forestales aleatorios es la velocidad. Se espera que su uso sea significativamente más rápido que el de otras implementaciones, como la implementación nativa de aprendizaje científico.
Ahora que sabemos que XGBoost ofrece soporte para el conjunto de bosque aleatorio, veamos el API específico.
XGBoost API para Random Forest
El primer paso es instalar la biblioteca XGBoost.
Recomiendo usar el administrador de paquetes pip usando el siguiente comando desde la línea de comandos:
Una vez instalado, podemos cargar la biblioteca e imprimir la versión en un script Python para confirmar que se instaló correctamente.
|
# Verificar la versión de xgboost importación xgboost # Versión de la pantalla imprimir(xgboost.La versión…) |
Ejecutando el guión se cargará la biblioteca XGBoost e imprimirá el número de versión de la biblioteca.
Su número de versión debería ser el mismo o más alto.
La biblioteca XGBoost proporciona dos clases de envoltorio que permiten que la implementación de bosque aleatorio proporcionada por la biblioteca se utilice con la biblioteca de aprendizaje de la máquina de ciencias.
Son las clases XGBRFClassifier y XGBRFRegressor para la clasificación y la regresión respectivamente.
|
... # Definir el modelo modelo = Clasificador XGBRFC() |
El número de árboles utilizados en el conjunto se puede establecer a través de la «n_estimadores«y, típicamente, esto se incrementa hasta que el modelo no observa ninguna mejora en el rendimiento. A menudo se utilizan cientos o miles de árboles.
|
... # Definir el modelo modelo = Clasificador XGBRFC(n_estimadores=100) |
XGBoost no tiene soporte para dibujar una muestra de bootstrap para cada árbol de decisión. Esto es una limitación de la biblioteca.
En cambio, una submuestra del conjunto de datos de entrenamiento, sin reemplazo, puede ser especificada a través de la «submuestra» como un porcentaje entre 0.0 y 1.0 (100 por ciento de las filas en el conjunto de datos de entrenamiento). Se recomiendan valores de 0,8 ó 0,9 para asegurar que el conjunto de datos sea lo suficientemente grande para entrenar a un modelo hábil pero lo suficientemente diferente para introducir cierta diversidad en el conjunto.
|
... # Definir el modelo modelo = Clasificador XGBRFC(n_estimadores=100, submuestra=0.9) |
El número de características utilizadas en cada punto de división cuando se entrena un modelo puede especificarse mediante el «colsample_bynode«y toma un porcentaje del número de columnas del conjunto de datos de 0,0 a 1,0 (100 por ciento de las filas de entrada en el conjunto de datos de entrenamiento).
Si tuviéramos 20 variables de entrada en nuestro conjunto de datos de entrenamiento y la heurística para los problemas de clasificación es la raíz cuadrada del número de características, entonces esto podría establecerse en sqrt(20) / 20, o alrededor de 4 / 20 o 0,2.
|
... # Definir el modelo modelo = Clasificador XGBRFC(n_estimadores=100, submuestra=0.9, colsample_bynode=0.2) |
Puedes aprender más acerca de cómo configurar la biblioteca XGBoost para conjuntos forestales aleatorios aquí:
Ahora que estamos familiarizados con el uso del API de XGBoost para definir conjuntos forestales aleatorios, veamos algunos ejemplos trabajados.
XGBoost Bosque aleatorio para la clasificación
En esta sección, veremos el desarrollo de un conjunto de bosque aleatorio XGBoost para un problema de clasificación.
Primero, podemos usar la función make_classification() para crear un problema de clasificación binaria sintética con 1.000 ejemplos y 20 características de entrada.
El ejemplo completo figura a continuación.
|
# Conjunto de datos de clasificación de pruebas de sklearn.conjuntos de datos importación hacer_clasificación # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # resumir el conjunto de datos imprimir(X.forma, y.forma) |
Ejecutando el ejemplo se crea el conjunto de datos y se resume la forma de los componentes de entrada y salida.
A continuación, podemos evaluar un algoritmo de bosque aleatorio XGBoost en este conjunto de datos.
Evaluaremos el modelo utilizando la validación cruzada estratificada k-pliegue, con tres repeticiones y 10 pliegues. Informaremos la media y la desviación estándar de la precisión del modelo en todas las repeticiones y pliegues.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Evaluar el algoritmo de bosque aleatorio xgboost para la clasificación de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de xgboost importación Clasificador XGBRFC # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Definir el modelo modelo = Clasificador XGBRFC(n_estimadores=100, submuestra=0.9, colsample_bynode=0.2) # Definir el procedimiento de evaluación del modelo cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Evaluar el modelo y recoger las puntuaciones n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) # Informe de rendimiento imprimir(«Precisión media: %.3f (%.3f) % (significa(n_puntuaciones), std(n_puntuaciones))) |
La ejecución del ejemplo informa de la precisión de la media y la desviación estándar del modelo.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el conjunto de bosque aleatorio XGBoost logró una precisión de clasificación de alrededor del 89,1 por ciento.
|
Precisión media: 0,891 (0,036) |
También podemos usar el modelo de bosque aleatorio XGBoost como modelo final y hacer predicciones para la clasificación.
Primero, el conjunto de bosque aleatorio XGBoost se ajusta a todos los datos disponibles, luego el predecir() se puede llamar a la función para hacer predicciones sobre nuevos datos.
El siguiente ejemplo lo demuestra en nuestro conjunto de datos de clasificación binaria.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Hacer predicciones usando el bosque aleatorio xgboost para la clasificación de numpy importación asarray de sklearn.conjuntos de datos importación make_classification de xgboost importación Clasificador XGBRFC # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Definir el modelo modelo = Clasificador XGBRFC(n_estimadores=100, submuestra=0.9, colsample_bynode=0.2) # Encajar el modelo en todo el conjunto de datos modelo.encajar(X, y) # definir una fila de datos fila = [[0.2929949,–4.21223056,–1.288332,–2.17849815,–0.64527665,2.58097719,0.28422388,–7.1827928,–1.91211104,2.73729512,0.81395695,3.96973717,–2.66939799,3.34692332,4.19791821,0.99990998,–0.30201875,–4.43170633,–2.82646737,0.44916808] fila = asarray([[fila]) # hacer una predicción yhat = modelo.predecir(fila) # resumir la predicción imprimir(Clase prevista: %d’. % yhat[[0]) |
La ejecución del ejemplo se ajusta al modelo de conjunto de bosque aleatorio XGBoost en todo el conjunto de datos y luego se utiliza para hacer una predicción en una nueva fila de datos, como podríamos hacer al utilizar el modelo en una aplicación.
Ahora que estamos familiarizados con el uso del bosque aleatorio para la clasificación, veamos el API para la regresión.
XGBoost Bosque aleatorio para la regresión
En esta sección, veremos el desarrollo de un conjunto de bosque aleatorio XGBoost para un problema de regresión.
Primero, podemos usar la función make_regression() para crear un problema de regresión sintética con 1.000 ejemplos y 20 características de entrada.
El ejemplo completo figura a continuación.
|
# conjunto de datos de regresión de pruebas de sklearn.conjuntos de datos importación hacer_regresión # Definir el conjunto de datos X, y = make_regression(n_muestras=1000, n_funciones=20, n_informativo=15, ruido=0.1, estado_aleatorio=7) # resumir el conjunto de datos imprimir(X.forma, y.forma) |
Ejecutando el ejemplo se crea el conjunto de datos y se resume la forma de los componentes de entrada y salida.
A continuación, podemos evaluar un conjunto de bosque aleatorio XGBoost en este conjunto de datos.
Como hicimos con la última sección, evaluaremos el modelo usando la validación cruzada repetida k-pliegue, con tres repeticiones y 10 pliegues.
Informaremos del error medio absoluto (MAE) del modelo en todas las repeticiones y pliegues. La biblioteca de aprendizaje de ciencias hace que el MAE sea negativo, de modo que se maximiza en lugar de minimizarse. Esto significa que los MAE negativos más grandes son mejores y un modelo perfecto tiene un MAE de 0.
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Evaluar el conjunto de bosques aleatorios de xgboost para la regresión de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_regression de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepetidoKFold de xgboost importación XGBRFRegressor # Definir el conjunto de datos X, y = make_regression(n_muestras=1000, n_funciones=20, n_informativo=15, ruido=0.1, estado_aleatorio=7) # Definir el modelo modelo = XGBRFRegressor(n_estimadores=100, submuestra=0.9, colsample_bynode=0.2) # Definir el procedimiento de evaluación del modelo cv = RepetidoKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Evaluar el modelo y recoger las puntuaciones n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=‘neg_mean_absolute_error’, cv=cv, n_jobs=–1) # Informe de rendimiento imprimir(MAE: %.3f (%.3f)’. % (significa(n_puntuaciones), std(n_puntuaciones))) |
Ejecutando el ejemplo se informa de la media y la desviación estándar MAE del modelo.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el conjunto de bosque aleatorio con hiperparámetros por defecto alcanza un MAE de alrededor de 108.
También podemos usar el conjunto de bosque aleatorio XGBoost como modelo final y hacer predicciones para la regresión.
Primero, el conjunto de bosque aleatorio se ajusta a todos los datos disponibles, luego se puede llamar a la función predict() para hacer predicciones sobre nuevos datos.
El siguiente ejemplo lo demuestra en nuestro conjunto de datos de regresión.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# gradiente xgboost bosque aleatorio para hacer predicciones de regresión de numpy importación asarray de sklearn.conjuntos de datos importación make_regression de xgboost importación XGBRFRegressor # Definir el conjunto de datos X, y = make_regression(n_muestras=1000, n_funciones=20, n_informativo=15, ruido=0.1, estado_aleatorio=7) # Definir el modelo modelo = XGBRFRegressor(n_estimadores=100, submuestra=0.9, colsample_bynode=0.2) # Encajar el modelo en todo el conjunto de datos modelo.encajar(X, y) # definir una sola fila de datos fila = [[0.20543991,–0.97049844,–0.81403429,–0.23842689,–0.60704084,–0.48541492,0.53113006,2.01834338,–0.90745243,–1.85859731,–1.02334791,–0.6877744,0.60984819,–0.70630121,–1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,–0.11154792] fila = asarray([[fila]) # hacer una predicción yhat = modelo.predecir(fila) # resumir la predicción imprimir(«Predicción: %d % yhat[[0]) |
La ejecución del ejemplo se ajusta al modelo de conjunto de bosque aleatorio XGBoost en todo el conjunto de datos y luego se utiliza para hacer una predicción en una nueva fila de datos, como podríamos hacer al utilizar el modelo en una aplicación.
Ahora que estamos familiarizados con el desarrollo y evaluación de los conjuntos forestales aleatorios XGBoost, veamos cómo configurar el modelo.
XGBoost Hiperparámetros forestales aleatorios
En esta sección, examinaremos más de cerca algunos de los hiperparámetros que debería considerar para la sintonía del conjunto de bosque aleatorio y su efecto en el rendimiento del modelo.
Explorar el número de árboles
El número de árboles es otro hiperparámetro clave a configurar para el bosque aleatorio XGBoost.
Típicamente, el número de árboles se incrementa hasta que el rendimiento del modelo se estabiliza. La intuición podría sugerir que un mayor número de árboles llevaría a una sobrecarga, aunque no es así. Tanto el algoritmo de embolsado como el de bosque aleatorio parecen ser algo inmunes a la sobrecarga del conjunto de datos de entrenamiento dada la naturaleza estocástica del algoritmo de aprendizaje.
El número de árboles se puede establecer a través de la «n_estimadores«y por defecto a 100.
El siguiente ejemplo explora el efecto del número de árboles con valores entre 10 y 1.000.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# Explorar xgboost bosque aleatorio número de árboles efecto en el rendimiento de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de xgboost importación Clasificador XGBRFC de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() # Definir el número de árboles a considerar n_árboles = [[10, 50, 100, 500, 1000, 5000] para v en n_árboles: modelos[[str(v)] = Clasificador XGBRFC(n_estimadores=v, submuestra=0.9, colsample_bynode=0.2) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo, X, y): # Definir el procedimiento de evaluación del modelo cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Evaluar el modelo resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): # Evaluar el modelo y recoger los resultados resultados = evaluate_model(modelo, X, y) # Almacenar los resultados resultados.anexar(resultados) nombres.anexar(nombre) # resumir el rendimiento a lo largo del camino imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
Ejecutando el ejemplo primero se informa de la precisión media para cada número configurado de árboles.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el rendimiento aumenta y se mantiene plano después de unos 500 árboles. Las puntuaciones medias de precisión fluctúan entre 500, 1.000 y 5.000 árboles y esto puede ser un ruido estadístico.
|
>10 0.868 (0.030) >50 0.887 (0.034) >100 0.891 (0.036) >500 0.893 (0.033) >1000 0.895 (0.035) >5000 0.894 (0.036) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada número configurado de árboles.
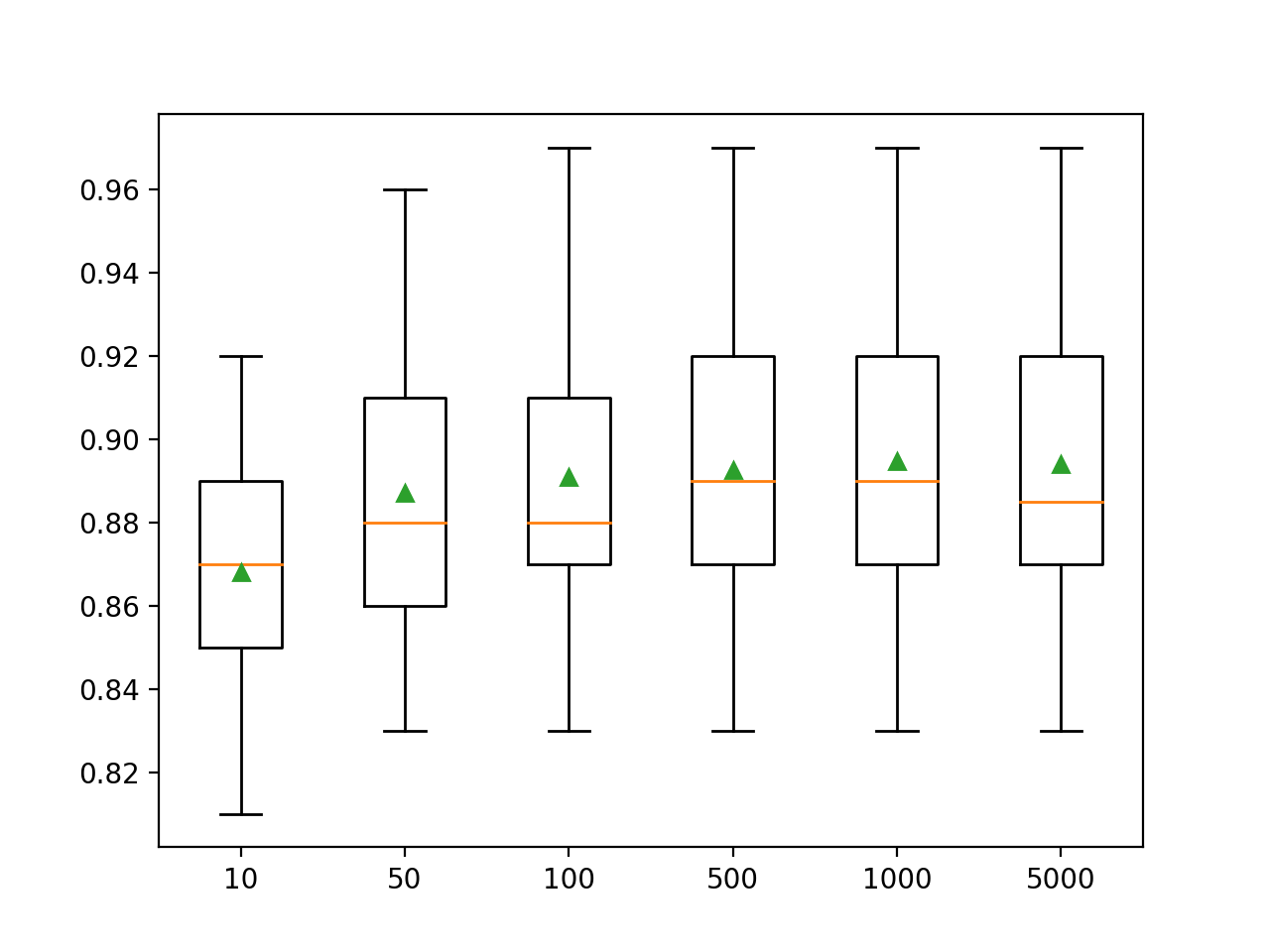
Recuadros del tamaño del conjunto de bosque aleatorio XGBoost vs. Precisión de la clasificación
Explorar el número de características
El número de características que se muestrean al azar para cada punto de división es quizás la característica más importante a configurar para el bosque aleatorio.
Se establece a través de la «colsample_bynode«que toma un porcentaje del número de características de entrada de 0 a 1.
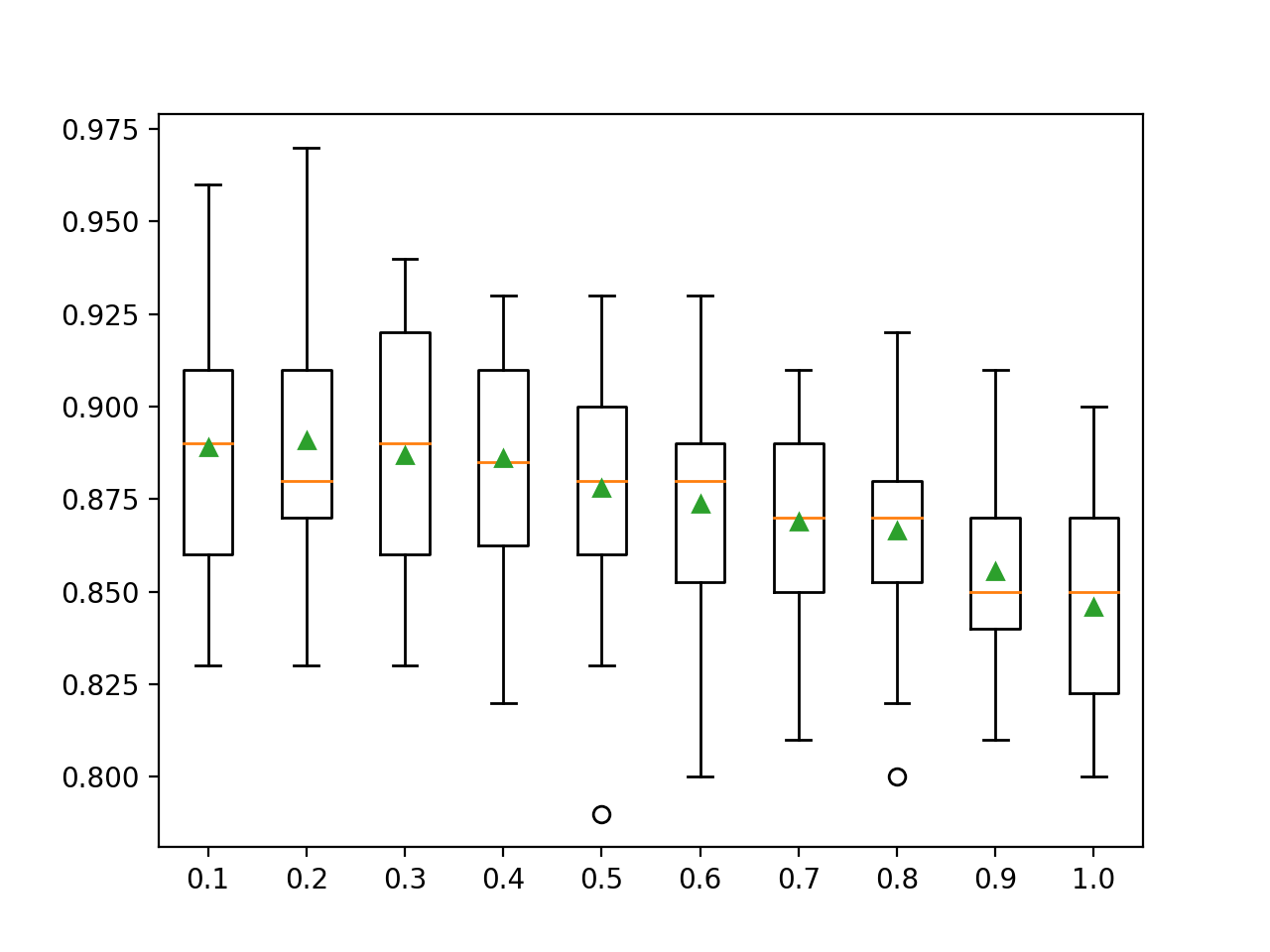
En el ejemplo que figura a continuación se explora el efecto del número de características seleccionadas al azar en cada punto de separación sobre la precisión del modelo. Probaremos valores de 0,0 a 1,0 con un incremento de 0,1, aunque esperaríamos que valores por debajo de 0,2 o 0,3 resultaran en un buen o mejor rendimiento dado que esto se traduce en aproximadamente la raíz cuadrada del número de características de entrada, que es una heurística común.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# Explorar el bosque aleatorio xgboost número de características efecto en el rendimiento de numpy importación significa de numpy importación std de numpy importación arange de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de xgboost importación Clasificador XGBRFC de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() para v en arange(0.1, 1.1, 0.1): clave = ‘%.1f’ % v modelos[[clave] = Clasificador XGBRFC(n_estimadores=100, submuestra=0.9, colsample_bynode=v) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo, X, y): # Definir el procedimiento de evaluación del modelo cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Evaluar el modelo resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): # Evaluar el modelo y recoger los resultados resultados = evaluate_model(modelo, X, y) # Almacenar los resultados resultados.anexar(resultados) nombres.anexar(nombre) # resumir el rendimiento a lo largo del camino imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
Ejecutando el ejemplo primero reporta la precisión media para cada tamaño de conjunto de características.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver una tendencia general de disminución del rendimiento medio de los modelos a medida que los miembros del conjunto utilizan más características de entrada.
Los resultados sugieren que el valor recomendado de 0,2 sería una buena elección en este caso.
|
>0.1 0.889 (0.032) >0.2 0.891 (0.036) >0.3 0.887 (0.032) >0.4 0.886 (0.030) >0.5 0.878 (0.033) >0.6 0.874 (0.031) >0.7 0.869 (0.027) >0.8 0.867 (0.027) >0.9 0.856 (0.023) >1.0 0.846 (0.027) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada tamaño de conjunto de características.
Podemos ver una tendencia en el rendimiento que disminuye con el número de características consideradas por los árboles de decisión.
Recuadro de XGBoost Random Forest Feature Size vs. Classification Accuracy
Más lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar en él.
Tutoriales
APIs
Resumen
En este tutorial, descubriste cómo usar la biblioteca XGBoost para desarrollar conjuntos forestales aleatorios.
Específicamente, aprendiste:
- XGBoost proporciona una eficiente implementación de refuerzo de gradientes que puede ser configurado para entrenar conjuntos forestales aleatorios.
- Cómo utilizar el API de XGBoost para entrenar y evaluar modelos de conjuntos forestales aleatorios para la clasificación y la regresión.
- Cómo afinar los hiperparámetros del modelo de conjunto forestal aleatorio XGBoost.
¿Tiene alguna pregunta?
Haga sus preguntas en los comentarios de abajo y haré lo posible por responder.