
Muchas tareas costosas de computación para el aprendizaje de la máquina pueden hacerse en paralelo dividiendo el trabajo entre múltiples núcleos de CPU…lo que se conoce como procesamiento multinúcleo.
Las tareas comunes de aprendizaje de máquinas que pueden hacerse en paralelo incluyen modelos de entrenamiento como conjuntos de árboles de decisión, evaluación de modelos utilizando procedimientos de remuestreo como la validación cruzada de pliegues k, y ajuste de hiperparámetros de modelos, como la cuadrícula y la búsqueda aleatoria.
El uso de múltiples núcleos para tareas comunes de aprendizaje de máquinas puede disminuir drásticamente el tiempo de ejecución como factor del número de núcleos disponibles en su sistema. Una computadora portátil y de escritorio común puede tener 2, 4 u 8 núcleos. Los sistemas de servidores más grandes pueden tener 32, 64 o más núcleos disponibles, lo que permite que las tareas de aprendizaje automático que llevan horas se completen en minutos.
En este tutorial, descubrirá cómo configurar Scikit-learn para el aprendizaje de máquinas multinúcleo.
Después de completar este tutorial, lo sabrás:
- Cómo entrenar modelos de aprendizaje de máquinas usando múltiples núcleos.
- Cómo hacer la evaluación de los modelos de aprendizaje de las máquinas en paralelo.
- Cómo usar múltiples núcleos para afinar los hiperparámetros del modelo de aprendizaje de la máquina.
Empecemos.

Aprendizaje de máquinas multinúcleo en Python con Scikit-Learn
Foto de ER Bauer, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en cinco partes; son:
- Multi-Core Scikit-Learn
- Entrenamiento de modelos multinúcleo
- Evaluación del modelo multi-núcleo
- Sintonización de Hiperparámetros Multi-núcleos
- Recomendaciones
Multi-Core Scikit-Learn
El aprendizaje por máquina puede ser costoso desde el punto de vista computacional.
Hay tres centros principales de este costo computacional; ellos son:
- Modelos de aprendizaje de máquinas de entrenamiento.
- Evaluando los modelos de aprendizaje de las máquinas.
- Modelos de aprendizaje de máquinas de afinación de hiperparámetros.
Peor aún, estas preocupaciones se agravan.
Por ejemplo, la evaluación de los modelos de aprendizaje de la máquina mediante una técnica de remuestreo como la validación cruzada de pliegues k requiere que el proceso de capacitación se repita varias veces.
- La evaluación requiere un entrenamiento repetido
La puesta a punto de los hiperparámetros del modelo lo complica aún más, ya que requiere que se repita el procedimiento de evaluación para cada combinación de hiperparámetros probados.
- La afinación requiere una evaluación repetida
La mayoría, si no todas, las computadoras modernas tienen CPU de múltiples núcleos. Esto incluye su estación de trabajo, su portátil, así como servidores más grandes.
Puede configurar sus modelos de aprendizaje de máquinas para aprovechar múltiples núcleos de su ordenador, acelerando drásticamente las operaciones de cálculo costosas.
La biblioteca de aprendizaje de máquinas en Python de scikit-learn proporciona esta capacidad a través del argumento n_jobs en tareas clave de aprendizaje de máquinas, como el entrenamiento de modelos, la evaluación de modelos y el ajuste de hiperparámetros.
Este argumento de configuración permite especificar el número de núcleos a utilizar para la tarea. El valor por defecto es None, que utilizará un solo núcleo. También se puede especificar un número de núcleos como un número entero, como 1 o 2. Finalmente, puede especificar -1, en cuyo caso la tarea utilizará todos los núcleos disponibles en su sistema.
- n_jobs: Especificar el número de núcleos a utilizar para las tareas de aprendizaje de la máquina clave.
Los valores comunes son:
- n_jobs=Ninguno: Usa un solo núcleo o el predeterminado configurado por tu biblioteca del backend.
- n_jobs=4: Utilice el número especificado de núcleos, en este caso 4.
- n_jobs=-1: Usar todos los núcleos disponibles.
¿Qué es un núcleo?
Una CPU puede tener múltiples núcleos físicos de CPU, que es esencialmente como tener múltiples CPU. Cada núcleo también puede tener hiperhilo, una tecnología que en muchas circunstancias permite duplicar el número de núcleos.
Por ejemplo, mi estación de trabajo tiene cuatro núcleos físicos, que se duplican a ocho núcleos debido a la hiperhiladura. Por lo tanto, puedo experimentar con 1-8 núcleos o especificar -1 para usar todos los núcleos de mi estación de trabajo.
Ahora que estamos familiarizados con la capacidad de la biblioteca de aprendizaje de ciencias para soportar el procesamiento paralelo de múltiples núcleos para el aprendizaje de las máquinas, vamos a trabajar con algunos ejemplos.
Obtendrá diferentes tiempos para todos los ejemplos de este tutorial; comparta sus resultados en los comentarios. Es posible que también tenga que cambiar el número de núcleos para que coincida con el número de núcleos de su sistema.
Nota: Sí, estoy al tanto de la API de Timeit, pero elegí en contra de ella para este tutorial. No estamos haciendo un perfil de los ejemplos de código en sí, sino que quiero que se centren en cómo y cuándo utilizar las capacidades multi-núcleo de scikit-learn y que ofrezcan beneficios reales. Quería que los ejemplos de código fueran limpios y fáciles de leer, incluso para los principiantes. Lo establecí como una extensión para actualizar todos los ejemplos para usar la API de timeit y obtener tiempos más precisos. Comparte tus resultados en los comentarios.
Entrenamiento de modelos multinúcleo
Muchos algoritmos de aprendizaje de máquinas soportan el entrenamiento multi-núcleo a través de un argumento n_jobs cuando se define el modelo.
Esto afecta no sólo a la formación del modelo, sino también a su uso para hacer predicciones.
Un ejemplo popular es el conjunto de árboles de decisión, como los árboles de decisión en bolsas, el bosque aleatorio y el aumento de gradientes.
En esta sección exploraremos la aceleración del entrenamiento de un modelo de RandomForestClassifier usando múltiples núcleos. Usaremos una tarea de clasificación sintética para nuestros experimentos.
En este caso, definiremos un modelo de bosque aleatorio con 500 árboles y utilizaremos un único núcleo para entrenar el modelo.
|
... # Definir el modelo modelo = RandomForestClassifier(n_estimadores=500, n_jobs=1) |
Podemos grabar la hora antes y después de la llamada al tren() usando la función tiempo() función. Podemos entonces restar la hora de inicio de la hora de fin y reportar el tiempo de ejecución en el número de segundos.
El ejemplo completo de evaluación del tiempo de ejecución de la capacitación de un modelo forestal aleatorio con un solo núcleo se enumera a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Ejemplo de cronometrar el entrenamiento de un modelo forestal aleatorio en un núcleo de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.conjunto importación RandomForestClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) # Definir el modelo modelo = RandomForestClassifier(n_estimadores=500, n_jobs=1) # Registrar la hora actual iniciar = tiempo() # Encaja con el modelo modelo.encajar(X, y) # Registrar la hora actual fin = tiempo() # Informe de tiempo de ejecución resultado = fin – iniciar imprimir(«%.3f segundos % resultado) |
La ejecución del ejemplo informa del tiempo que se tarda en entrenar el modelo con un solo núcleo.
En este caso, podemos ver que tarda unos 10 segundos.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
Ahora podemos cambiar el ejemplo para usar todos los núcleos físicos del sistema, en este caso, cuatro.
|
... # Definir el modelo modelo = RandomForestClassifier(n_estimadores=500, n_jobs=4) |
El ejemplo completo de entrenamiento con múltiples núcleos del modelo con cuatro núcleos se enumera a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Ejemplo de cronometraje del entrenamiento de un modelo forestal aleatorio en 4 núcleos de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.conjunto importación RandomForestClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) # Definir el modelo modelo = RandomForestClassifier(n_estimadores=500, n_jobs=4) # Registrar la hora actual iniciar = tiempo() # Encaja con el modelo modelo.encajar(X, y) # Registrar la hora actual fin = tiempo() # Informe de tiempo de ejecución resultado = fin – iniciar imprimir(«%.3f segundos % resultado) |
La ejecución del ejemplo informa del tiempo que se tarda en entrenar el modelo con un solo núcleo.
En este caso, podemos ver que la velocidad de ejecución se redujo a la mitad a unos 3.151 segundos.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
Ahora podemos cambiar el número de núcleos a ocho para tener en cuenta el hiper-hilo soportado por los cuatro núcleos físicos.
|
... # Definir el modelo modelo = RandomForestClassifier(n_estimadores=500, n_jobs=8) |
Podemos lograr el mismo efecto fijando n_jobs a -1 para utilizar automáticamente todos los núcleos; por ejemplo:
|
... # Definir el modelo modelo = RandomForestClassifier(n_estimadores=500, n_jobs=–1) |
Nos limitaremos a especificar manualmente el número de núcleos por ahora.
El ejemplo completo de entrenamiento con múltiples núcleos del modelo con ocho núcleos se enumera a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Ejemplo de cronometraje del entrenamiento de un modelo forestal aleatorio en 8 núcleos de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.conjunto importación RandomForestClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) # Definir el modelo modelo = RandomForestClassifier(n_estimadores=500, n_jobs=8) # Registrar la hora actual iniciar = tiempo() # Encaja con el modelo modelo.encajar(X, y) # Registrar la hora actual fin = tiempo() # Informe de tiempo de ejecución resultado = fin – iniciar imprimir(«%.3f segundos % resultado) |
La ejecución del ejemplo informa del tiempo que se tarda en entrenar el modelo con un solo núcleo.
En este caso, podemos ver que obtuvimos otra caída en la velocidad de ejecución de alrededor de 3.151 a alrededor de 2.521 utilizando todos los núcleos.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
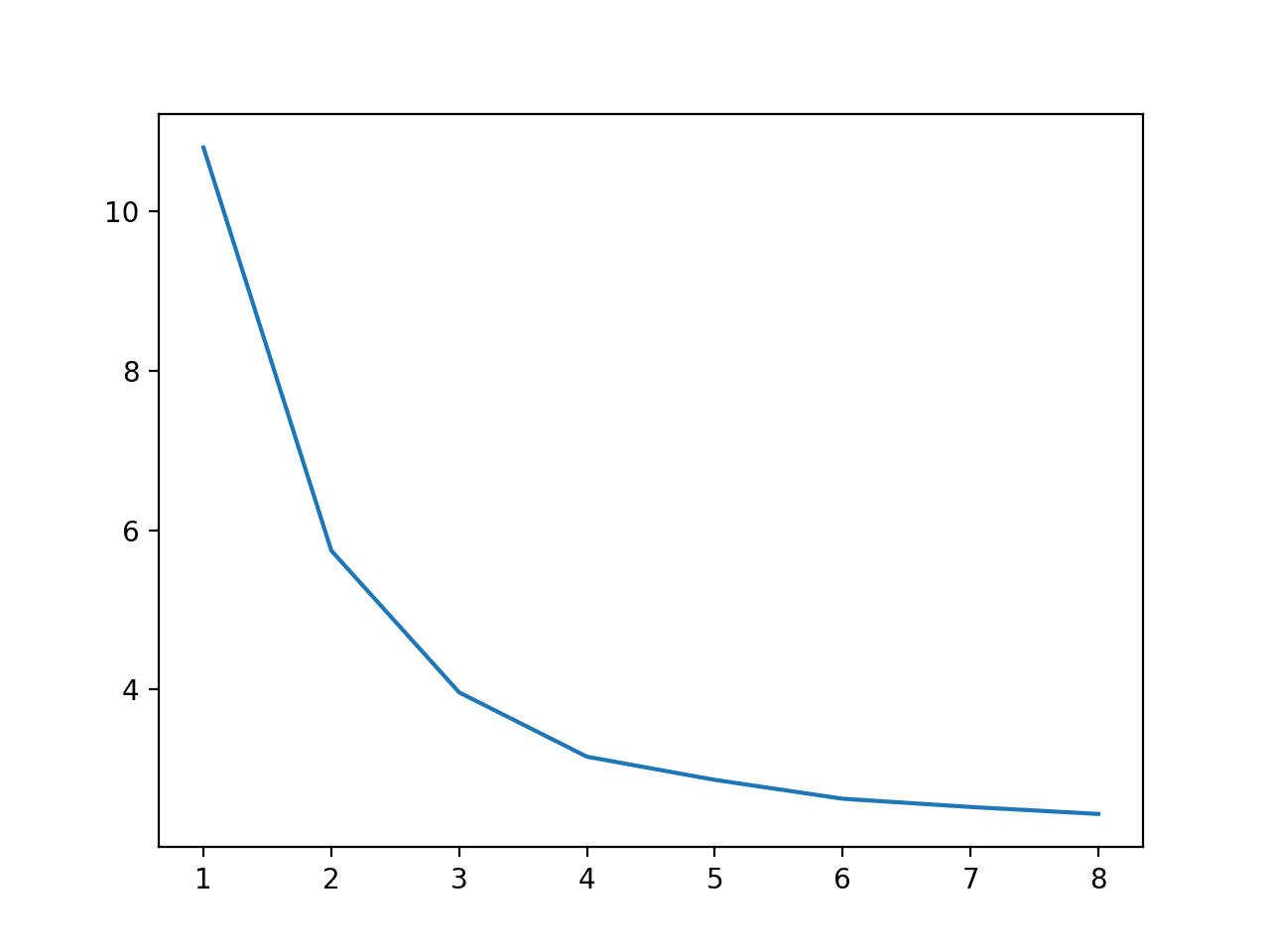
Podemos hacer más concreta la relación entre el número de núcleos utilizados durante el entrenamiento y la velocidad de ejecución, comparando todos los valores entre uno y ocho y trazando el resultado.
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Ejemplo de comparación del número de núcleos utilizados durante el entrenamiento con la velocidad de ejecución de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.conjunto importación RandomForestClassifier de matplotlib importación pyplot # Definir el conjunto de datos X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) resultados = lista() # Comparar el tiempo para el número de núcleos n_cores = [[1, 2, 3, 4, 5, 6, 7, 8] para n en n_cores: # capturar la hora actual iniciar = tiempo() # Definir el modelo modelo = RandomForestClassifier(n_estimadores=500, n_jobs=n) # Encaja con el modelo modelo.encajar(X, y) # capturar la hora actual fin = tiempo() # Almacena el tiempo de ejecución resultado = fin – iniciar imprimir(‘>cores=%d: %.3f segundos’ % (n, resultado)) resultados.anexar(resultado) pyplot.parcela(n_cores, resultados) pyplot.mostrar() |
El ejemplo primero reporta la velocidad de ejecución para cada número de núcleos utilizados durante el entrenamiento.
Podemos ver una disminución constante de la velocidad de ejecución de uno a ocho núcleos, aunque los beneficios dramáticos se detienen después de cuatro núcleos físicos.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
|
>cores=1: 10.798 segundos >cores=2: 5.743 segundos >cores=3: 3.964 segundos >cores=4: 3.158 segundos >cores=5: 2.868 segundos >cores=6: 2.631 segundos >cores=7: 2.528 segundos >cores=8: 2.440 segundos |
También se crea una trama para mostrar la relación entre el número de núcleos utilizados durante el entrenamiento y la velocidad de ejecución, mostrando que seguimos viendo un beneficio hasta ocho núcleos.
Trazado de la línea del número de núcleos utilizados durante el entrenamiento vs. la velocidad de ejecución
Ahora que estamos familiarizados con el beneficio de la formación de los modelos de aprendizaje de máquinas, veamos la evaluación de los modelos de múltiples núcleos.
Evaluación del modelo multi-núcleo
El estándar de oro para la evaluación del modelo es la validación cruzada del pliegue k.
Se trata de un procedimiento de remuestreo que requiere que el modelo sea entrenado y evaluado k veces en diferentes subconjuntos divididos del conjunto de datos. El resultado es una estimación del rendimiento de un modelo al hacer predicciones sobre datos no utilizados durante el entrenamiento que pueden utilizarse para comparar y seleccionar un buen o mejor modelo para un conjunto de datos.
Además, también es una buena práctica repetir este proceso de evaluación varias veces, lo que se denomina validación cruzada repetida k.
El procedimiento de evaluación puede configurarse para utilizar múltiples núcleos, en los que cada modelo de capacitación y evaluación se realiza en un núcleo separado. Esto puede hacerse configurando el n_jobs en la llamada a la función cross_val_score(); por ejemplo:
Podemos explorar el efecto de los múltiples núcleos en la evaluación del modelo.
Primero, evaluemos el modelo usando un solo núcleo.
|
... # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=1) |
Evaluaremos el modelo de bosque aleatorio y utilizaremos un único núcleo en la formación del modelo (por ahora).
|
... # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=1) |
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# Ejemplo de evaluación de un modelo usando un solo núcleo de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.conjunto importación RandomForestClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=1) # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Registrar la hora actual iniciar = tiempo() # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=1) # Registrar la hora actual fin = tiempo() # Informe de tiempo de ejecución resultado = fin – iniciar imprimir(«%.3f segundos % resultado) |
Al ejecutar el ejemplo se evalúa el modelo utilizando una validación cruzada de 10 veces con tres repeticiones.
En este caso, vemos que la evaluación del modelo tomó unos 6.412 segundos.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
Podemos actualizar el ejemplo para usar los ocho núcleos del sistema y esperar una gran aceleración.
|
... # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=8) |
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# Ejemplo de evaluación de un modelo usando 8 núcleos de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.conjunto importación RandomForestClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=1) # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Registrar la hora actual iniciar = tiempo() # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=8) # Registrar la hora actual fin = tiempo() # Informe de tiempo de ejecución resultado = fin – iniciar imprimir(«%.3f segundos % resultado) |
Ejecutando el ejemplo se evalúa el modelo usando múltiples núcleos.
En este caso, podemos ver que el tiempo de ejecución cayó de 6,412 segundos a unos 2,371 segundos, dando una bienvenida aceleración.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
Como hicimos en la sección anterior, podemos cronometrar la velocidad de ejecución para cada número de núcleos de uno a ocho para tener una idea de la relación.
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# Comparar la velocidad de ejecución para la evaluación del modelo vs. el número de núcleos de cpu de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.conjunto importación RandomForestClassifier de matplotlib importación pyplot # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) resultados = lista() # Comparar el tiempo para el número de núcleos n_cores = [[1, 2, 3, 4, 5, 6, 7, 8] para n en n_cores: # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=1) # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Registrar la hora actual iniciar = tiempo() # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=n) # Registrar la hora actual fin = tiempo() # Almacena el tiempo de ejecución resultado = fin – iniciar imprimir(‘>cores=%d: %.3f segundos’ % (n, resultado)) resultados.anexar(resultado) pyplot.parcela(n_cores, resultados) pyplot.mostrar() |
Ejecutando el ejemplo primero se reporta el tiempo de ejecución en segundos para cada número de núcleos para evaluar el modelo.
Podemos ver que no hay una mejora dramática por encima de cuatro núcleos físicos.
También podemos ver una diferencia aquí cuando se entrena con ocho núcleos del experimento anterior. En este caso, evaluar el rendimiento llevó 1.492 segundos mientras que el caso aislado llevó unos 2.371 segundos.
Esto pone de relieve la limitación de la metodología de evaluación que estamos utilizando, en la que informamos sobre el rendimiento de una sola ejecución en lugar de repetidas ejecuciones. Se requiere cierto tiempo de aceleración para cargar las clases en la memoria y realizar cualquier optimización de JIT.
Independientemente de la precisión de nuestro endeble perfil, vemos la familiar aceleración de la evaluación del modelo con el aumento de los núcleos utilizados durante el proceso.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
|
>cores=1: 6.339 segundos >cores=2: 3.765 segundos >cores=3: 2.404 segundos >cores=4: 1.826 segundos >cores=5: 1.806 segundos >cores=6: 1.686 segundos >cores=7: 1.587 segundos >cores=8: 1.492 segundos |
También se crea una gráfica de la relación entre el número de núcleos y la velocidad de ejecución.
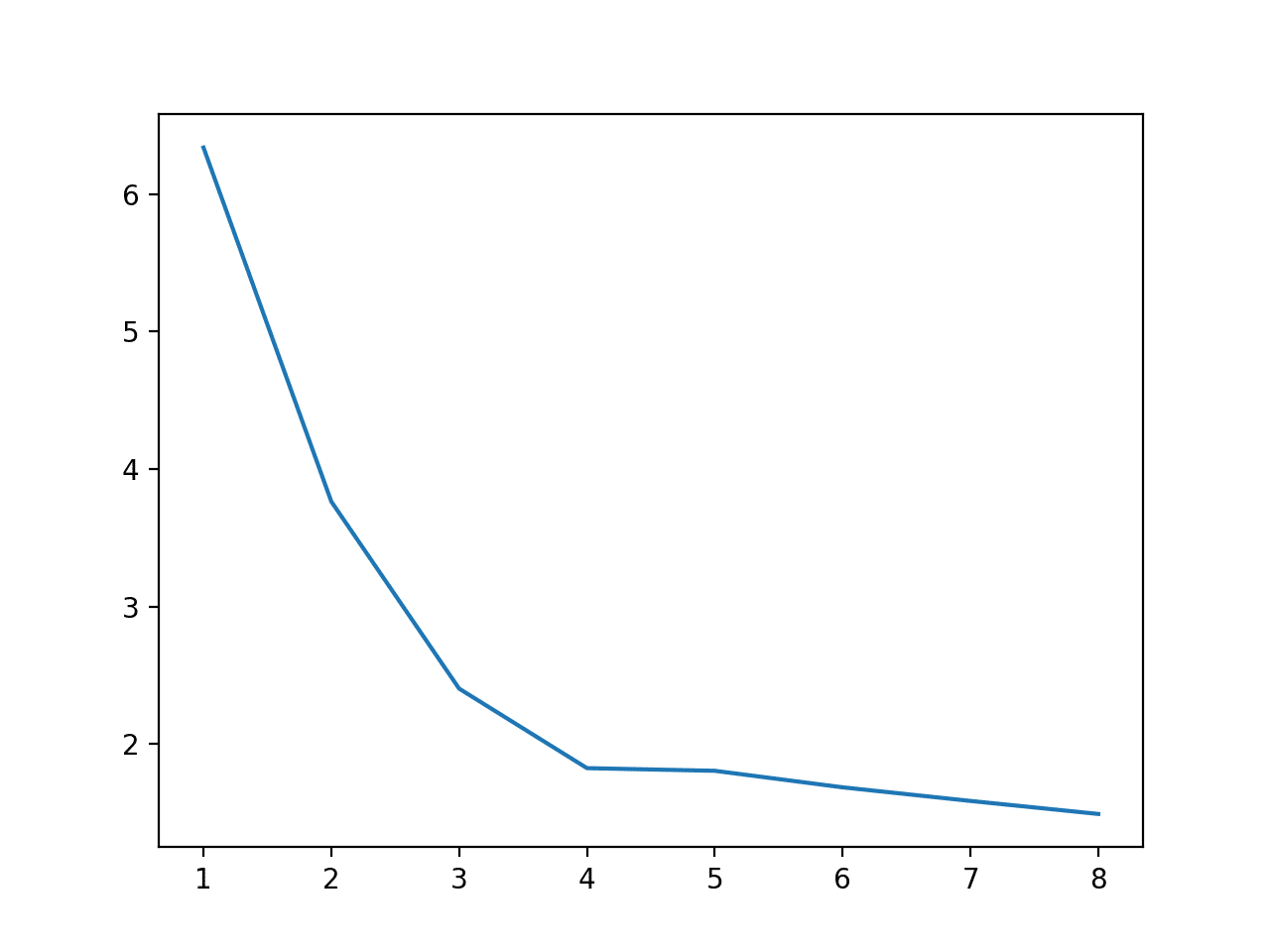
Gráfico de líneas del número de núcleos utilizados durante la evaluación frente a la velocidad de ejecución
También podemos hacer el proceso de entrenamiento del modelo en paralelo durante el procedimiento de evaluación del modelo.
Aunque esto es posible, ¿deberíamos?
Para explorar esta cuestión, consideremos primero el caso en el que el entrenamiento con modelos utiliza todos los núcleos y la evaluación de modelos utiliza un único núcleo.
|
... # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=8) ... # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=1) |
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# Ejemplo de uso de múltiples núcleos para el entrenamiento de modelos pero no para la evaluación de modelos de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.conjunto importación RandomForestClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=8) # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Registrar la hora actual iniciar = tiempo() # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=1) # Registrar la hora actual fin = tiempo() # Informe de tiempo de ejecución resultado = fin – iniciar imprimir(«%.3f segundos % resultado) |
Al ejecutar el ejemplo se evalúa el modelo utilizando un solo núcleo, pero cada modelo entrenado utiliza un solo núcleo.
En este caso, podemos ver que la evaluación del modelo toma más de 10 segundos, mucho más que los 1 o 2 segundos cuando usamos un solo núcleo para el entrenamiento y todos los núcleos para la evaluación paralela del modelo.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
¿Y si dividimos el número de núcleos entre los procedimientos de entrenamiento y evaluación?
|
... # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=4) ... # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=4) |
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# Ejemplo de uso de múltiples núcleos para la capacitación y evaluación de modelos de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.conjunto importación RandomForestClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=8) # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=4) # Registrar la hora actual iniciar = tiempo() # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=4) # Registrar la hora actual fin = tiempo() # Informe de tiempo de ejecución resultado = fin – iniciar imprimir(«%.3f segundos % resultado) |
Al ejecutar el ejemplo se evalúa el modelo utilizando cuatro núcleos, y cada modelo se entrena utilizando cuatro núcleos diferentes.
Podemos ver una mejora con respecto al entrenamiento con todos los núcleos y la evaluación con un solo núcleo, pero al menos para este modelo en este conjunto de datos, es más eficiente utilizar todos los núcleos para la evaluación del modelo y un solo núcleo para el entrenamiento del modelo.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
Sintonización de Hiperparámetros Multi-núcleos
Es común afinar los hiperparámetros de un modelo de aprendizaje de máquina usando una búsqueda en cuadrícula o una búsqueda aleatoria.
La biblioteca de aprendizaje de ciencias proporciona estas capacidades a través de las clases GridSearchCV y RandomizedSearchCV respectivamente.
Ambos procedimientos de búsqueda pueden hacerse en paralelo estableciendo el n_jobs asignando cada configuración de hiperparámetros a un núcleo para su evaluación.
El modelo de evaluación en sí mismo también puede ser multi-núcleo, como vimos en la sección anterior, y el modelo de capacitación para una evaluación determinada también puede ser de capacitación como vimos en la segunda anterior. Por lo tanto, la pila de procesos potencialmente multi-núcleo está empezando a ser difícil de configurar.
En esta implementación específica, podemos hacer el modelo de entrenamiento en paralelo, pero no tenemos control sobre cómo cada modelo hiperparamétrico y cómo cada evaluación de modelo se hace multi-núcleo. La documentación no está clara en el momento de escribir este documento, pero supongo que cada evaluación de modelo que utiliza una configuración de hiperparámetro de un solo núcleo se divide en trabajos.
Exploremos los beneficios de realizar la sintonización de hiperparámetros modelo usando múltiples núcleos.
Primero, evaluemos una cuadrícula de diferentes configuraciones del algoritmo de bosque aleatorio usando un solo núcleo.
|
... # Definir la búsqueda de la cuadrícula busca en = GridSearchCV(modelo, cuadrícula, n_jobs=1, cv=cv) |
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Ejemplo de sintonía de hiperparámetros modelo con un solo núcleo de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.conjunto importación RandomForestClassifier de sklearn.model_selection importación GridSearchCV # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=1) # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Definir la cuadrícula cuadrícula = dict() cuadrícula[[‘max_features’ (características máximas)] = [[1, 2, 3, 4, 5] # Definir la búsqueda de la cuadrícula busca en = GridSearchCV(modelo, cuadrícula, n_jobs=1, cv=cv) # Registrar la hora actual iniciar = tiempo() # realizar la búsqueda busca en.encajar(X, y) # Registrar la hora actual fin = tiempo() # Informe de tiempo de ejecución resultado = fin – iniciar imprimir(«%.3f segundos % resultado) |
Ejecutando el ejemplo se prueban diferentes valores de la max_features configuración para el bosque aleatorio, donde cada configuración se evalúa usando una validación cruzada repetida de k.
En este caso, la búsqueda en la cuadrícula de un solo núcleo tarda unos 28.838 segundos.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
Ahora podemos configurar la búsqueda en la cuadrícula para usar todos los núcleos disponibles en el sistema, en este caso, ocho núcleos.
|
... # Definir la búsqueda de la cuadrícula busca en = GridSearchCV(modelo, cuadrícula, n_jobs=8, cv=cv) |
Entonces podemos evaluar cuánto tiempo tarda en ejecutarse esta búsqueda de cuadrículas multinúcleo. El ejemplo completo se muestra a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Ejemplo de sintonía de hiperparámetros de modelo con 8 núcleos de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.conjunto importación RandomForestClassifier de sklearn.model_selection importación GridSearchCV # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=1) # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Definir la cuadrícula cuadrícula = dict() cuadrícula[[‘max_features’ (características máximas)] = [[1, 2, 3, 4, 5] # Definir la búsqueda de la cuadrícula busca en = GridSearchCV(modelo, cuadrícula, n_jobs=8, cv=cv) # Registrar la hora actual iniciar = tiempo() # realizar la búsqueda busca en.encajar(X, y) # Registrar la hora actual fin = tiempo() # Informe de tiempo de ejecución resultado = fin – iniciar imprimir(«%.3f segundos % resultado) |
Ejecutar el ejemplo reporta el tiempo de ejecución para la búsqueda de la cuadrícula.
En este caso, vemos que un factor de aproximadamente cuatro acelera de unos 28.838 segundos a unos 7.418 segundos.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
Intuitivamente, esperaríamos que hacer la búsqueda de la cuadrícula de múltiples núcleos sea el foco y no el modelo de entrenamiento.
Sin embargo, podemos dividir el número de núcleos entre el entrenamiento del modelo y la búsqueda de la cuadrícula para ver si ofrece un beneficio para este modelo en este conjunto de datos.
|
... # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=4) ... # Definir la búsqueda de la cuadrícula busca en = GridSearchCV(modelo, cuadrícula, n_jobs=4, cv=cv) |
El ejemplo completo de entrenamiento de modelos multinúcleo y ajuste de hiperparámetros multinúcleo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Ejemplo de entrenamiento de modelos multinúcleo y ajuste de hiperparámetros de tiempo importación tiempo de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.conjunto importación RandomForestClassifier de sklearn.model_selection importación GridSearchCV # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=3) # Definir el modelo modelo = RandomForestClassifier(n_estimadores=100, n_jobs=4) # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Definir la cuadrícula cuadrícula = dict() cuadrícula[[‘max_features’ (características máximas)] = [[1, 2, 3, 4, 5] # Definir la búsqueda de la cuadrícula busca en = GridSearchCV(modelo, cuadrícula, n_jobs=4, cv=cv) # Registrar la hora actual iniciar = tiempo() # realizar la búsqueda busca en.encajar(X, y) # Registrar la hora actual fin = tiempo() # Informe de tiempo de ejecución resultado = fin – iniciar imprimir(«%.3f segundos % resultado) |
En este caso, vemos una disminución de la velocidad de ejecución en comparación con un solo caso de núcleo, pero no tanto beneficio como asignar todos los núcleos al proceso de búsqueda en la cuadrícula.
¿Cuánto tiempo le lleva a su sistema? Comparta sus resultados en los comentarios que aparecen a continuación.
Recomendaciones
En esta sección se enumeran algunas recomendaciones generales cuando se utilizan varios núcleos para el aprendizaje de la máquina.
- Confirme el número de núcleos disponibles en su sistema.
- Considere la posibilidad de usar una instancia de AWS EC2 con muchos núcleos para obtener una aceleración inmediata.
- Revise la documentación de la API para ver si el/los modelo/s que está utilizando soportan el entrenamiento de múltiples núcleos.
- Confirmar que el entrenamiento multi-núcleo ofrece un beneficio medible en su sistema.
- Cuando se utiliza la validación cruzada de pliegue k, probablemente sea mejor asignar núcleos al procedimiento de remuestreo y dejar el entrenamiento del modelo en un solo núcleo.
- Cuando se utiliza la sintonización del hiperparámetro, probablemente sea mejor hacer la búsqueda con varios núcleos y dejar el modelo de entrenamiento y evaluación con un solo núcleo.
¿Tiene alguna recomendación propia?
Más lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar en él.
Tutoriales relacionados
APIs
Artículos
Resumen
En este tutorial, descubriste cómo configurar scikit-learn para el aprendizaje de máquinas multinúcleo.
Específicamente, aprendiste:
- Cómo entrenar modelos de aprendizaje de máquinas usando múltiples núcleos.
- Cómo hacer la evaluación de los modelos de aprendizaje de las máquinas en paralelo.
- Cómo usar múltiples núcleos para afinar los hiperparámetros del modelo de aprendizaje de la máquina.
¿Tiene alguna pregunta?
Haga sus preguntas en los comentarios de abajo y haré lo posible por responder.
Descubre el aprendizaje rápido de la máquina en Python!

Desarrolle sus propios modelos en minutos
…con sólo unas pocas líneas de código de aprendizaje científico…
Aprende cómo en mi nuevo Ebook:
Dominio de la máquina de aprendizaje con la pitón
Cubre Tutoriales de auto-estudio y proyectos integrales como:
Cargando datos, visualización, modelado, tuningy mucho más…
Finalmente traer el aprendizaje automático a
Sus propios proyectos
Sáltese los académicos. Sólo los resultados.
Ver lo que hay dentro