
Extreme Gradient Boosting (XGBoost) es una biblioteca de código abierto que proporciona una implementación eficiente y efectiva del algoritmo de aumento de gradiente.
Aunque antes de XGBoost ya existían otras implementaciones de código abierto del enfoque, el lanzamiento de XGBoost pareció liberar el poder de la técnica e hizo que la comunidad de aprendizaje de máquinas aplicadas tomara nota del aumento de gradientes de forma más general.
Poco después de su desarrollo y lanzamiento inicial, XGBoost se convirtió en el método de referencia y a menudo en el componente clave para ganar soluciones a los problemas de clasificación y regresión en las competiciones de aprendizaje de máquinas.
En este tutorial, descubrirá cómo desarrollar conjuntos de Refuerzo de Gradiente Extremo para la clasificación y la regresión.
Después de completar este tutorial, lo sabrás:
- Extreme Gradient Boosting es una eficiente implementación de código abierto del algoritmo de conjunto de aumento de gradiente estocástico.
- Cómo desarrollar conjuntos XGBoost para la clasificación y la regresión con la API de aprendizaje de ciencias.
- Cómo explorar el efecto de los hiperparámetros del modelo XGBoost en el rendimiento del modelo.
Empecemos.

Conjunto de Refuerzo de Gradiente Extremo (XGBoost) en Python
Foto de Andrés Nieto Porras, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en tres partes; son:
- Algoritmo de potenciación de gradiente extremo
- XGBoost Scikit-Learn API
- XGBoost Ensemble for Classification
- XGBoost Ensemble for Regression
- Hiperparámetros XGBoost
- Explorar el número de árboles
- Explorar la profundidad del árbol
- Explorar el ritmo de aprendizaje
- Explorar el número de muestras
- Explorar el número de características
Algoritmo de potenciación de gradiente extremo
El aumento de gradiente se refiere a una clase de algoritmos de aprendizaje de máquinas en conjunto que pueden utilizarse para la clasificación o la regresión de problemas de modelado predictivo.
Los conjuntos se construyen a partir de modelos de árboles de decisión. Los árboles se añaden uno a uno al conjunto y se ajustan para corregir los errores de predicción de los modelos anteriores. Este es un tipo de modelo de aprendizaje de máquinas de conjuntos al que se le llama «boosting».
Los modelos se ajustan usando cualquier función de pérdida diferenciable arbitraria y algoritmo de optimización de descenso de gradiente. Esto le da a la técnica su nombre, «aumento del gradiente…ya que el gradiente de pérdida se minimiza al ajustar el modelo, como una red neuronal.
Para más información sobre la mejora de los gradientes, vea el tutorial:
Extreme Gradient Boosting, o XGBoost para abreviar, es una eficiente implementación de código abierto del algoritmo de aumento de gradiente. Como tal, XGBoost es un algoritmo, un proyecto de código abierto, y una librería Python.
Fue desarrollado inicialmente por Tianqi Chen y fue descrito por Chen y Carlos Guestrin en su documento de 2016 titulado «XGBoost»: Un sistema escalable de potenciación de árboles».
Está diseñado para ser tanto eficiente desde el punto de vista informático (por ejemplo, rápido de ejecutar) como altamente eficaz, tal vez más eficaz que otras implementaciones de código abierto.
El nombre xgboost, sin embargo, en realidad se refiere al objetivo de ingeniería de empujar el límite de los recursos de cálculo para los algoritmos de árboles potenciados. Esa es la razón por la que mucha gente usa xgboost.
– Tianqi Chen, en respuesta a la pregunta «¿Cuál es la diferencia entre la R gbm (máquina de aumento de gradiente) y xgboost (aumento de gradiente extremo)?» en Quora
Las dos razones principales para usar XGBoost son la velocidad de ejecución y el rendimiento del modelo.
Generalmente, XGBoost es rápido cuando se compara con otras implementaciones de aumento de gradiente. Szilard Pafka realizó algunos puntos de referencia objetivos comparando el rendimiento del XGBoost con otras implementaciones de potenciación de gradientes y árboles de decisión embolsados. Escribió sus resultados en mayo de 2015 en la entrada del blog titulada «Benchmarking Random Forest Implementations».
Sus resultados mostraron que XGBoost era casi siempre más rápido que las otras implementaciones de referencia de R, Python Spark y H2O.
De su experimento, comentó:
También intenté con xgboost, una biblioteca popular para el impulso que es capaz de construir bosques al azar también. Es rápida, eficiente en la memoria y de alta precisión
– Benchmarking Random Forest Implementations, Szilard Pafka, 2015.
XGBoost domina los conjuntos de datos estructurados o tabulares sobre los problemas de clasificación y de modelización predictiva de la regresión. La evidencia es que es el algoritmo de referencia para los ganadores de las competiciones de la plataforma de ciencia de datos competitiva de Kaggle.
Entre las 29 soluciones ganadoras de desafíos 3 publicadas en el blog de Kaggle durante el 2015, 17 soluciones usaron XGBoost. […] El éxito del sistema también se vio en KDDCup 2015, donde XGBoost fue utilizado por todos los equipos ganadores del top-10.
– XGBoost: Un sistema de potenciación de árboles escalable, 2016.
Ahora que estamos familiarizados con lo que es el XGBoost y por qué es importante, vamos a ver más de cerca cómo podemos usarlo en nuestros proyectos de modelado predictivo.
XGBoost Scikit-Learn API
XGBoost puede instalarse como una biblioteca independiente y se puede desarrollar un modelo de XGBoost utilizando el API de scikit-learn.
El primer paso es instalar la biblioteca XGBoost si no está ya instalada. Esto se puede conseguir usando el gestor de paquetes pip python en la mayoría de las plataformas; por ejemplo:
Entonces puedes confirmar que la biblioteca XGBoost se instaló correctamente y puede ser utilizada ejecutando el siguiente script.
|
# Verificar la versión de xgboost importación xgboost imprimir(xgboost.La versión…) |
Ejecutando el script se imprimirá tu versión de la biblioteca XGBoost que tienes instalada.
Tu versión debería ser la misma o más alta. Si no, debes actualizar tu versión de la biblioteca XGBoost.
Es posible que tenga problemas con la última versión de la biblioteca. No es culpa suya.
A veces, la versión más reciente de la biblioteca impone requisitos adicionales o puede ser menos estable.
Si tiene errores al intentar ejecutar el script anterior, recomiendo bajar a la versión 1.0.1 (o inferior). Esto se puede lograr especificando la versión a instalar en el comando pip, de la siguiente manera:
|
sudo pip install xgboost==1.0.1 |
Si ves un mensaje de advertencia, puedes ignorarlo por ahora. Por ejemplo, a continuación se muestra un ejemplo de un mensaje de advertencia que puede ver y puede ignorar:
|
FutureWarning: las pruebas de pandas.util están desactualizadas. Utilice las funciones de la API pública en pandas.testing en su lugar. |
Si necesita instrucciones específicas para su entorno de desarrollo, consulte el tutorial:
La biblioteca XGBoost tiene su propia API personalizada, aunque utilizaremos el método a través de las clases de envoltorio de scikit-learn: XGBRegressor y XGBClassifier. Esto nos permitirá utilizar el conjunto completo de herramientas de la biblioteca de aprendizaje automático scikit-learn para preparar datos y evaluar modelos.
Ambos modelos operan de la misma manera y toman los mismos argumentos que influyen en la forma en que los árboles de decisión se crean y se añaden al conjunto.
La aleatoriedad se utiliza en la construcción del modelo. Esto significa que cada vez que el algoritmo se ejecute con los mismos datos, producirá un modelo ligeramente diferente.
Cuando se utilizan algoritmos de aprendizaje automático que tienen un algoritmo de aprendizaje estocástico, es una buena práctica evaluarlos promediando su rendimiento a través de múltiples ejecuciones o repeticiones de validación cruzada. Al ajustar un modelo final, puede ser conveniente aumentar el número de árboles hasta que se reduzca la varianza del modelo a través de evaluaciones repetidas, o ajustar múltiples modelos finales y promediar sus predicciones.
Echemos un vistazo a cómo desarrollar un conjunto XGBoost tanto para la clasificación como para la regresión.
XGBoost Ensemble for Classification
En esta sección, veremos el uso de XGBoost para un problema de clasificación.
Primero, podemos usar la función make_classification() para crear un problema de clasificación binaria sintética con 1.000 ejemplos y 20 características de entrada.
El ejemplo completo figura a continuación.
|
# Conjunto de datos de clasificación de pruebas de sklearn.conjuntos de datos importación hacer_clasificación # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # resumir el conjunto de datos imprimir(X.forma, y.forma) |
Ejecutando el ejemplo se crea el conjunto de datos y se resume la forma de los componentes de entrada y salida.
A continuación, podemos evaluar un modelo XGBoost en este conjunto de datos.
Evaluaremos el modelo utilizando la validación cruzada estratificada k-pliegue, con tres repeticiones y 10 pliegues. Informaremos la media y la desviación estándar de la precisión del modelo en todas las repeticiones y pliegues.
|
# Evaluar el algoritmo xgboost para la clasificación de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de xgboost importación XGBClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Definir el modelo modelo = XGBClassifier() # Evaluar el modelo cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) # Informe de rendimiento imprimir(«Precisión: %.3f (%.3f) % (significa(n_puntuaciones), std(n_puntuaciones))) |
La ejecución del ejemplo informa de la precisión de la media y la desviación estándar del modelo.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el conjunto XGBoost con hiperparámetros predeterminados logra una precisión de clasificación de alrededor del 92,5 por ciento en este conjunto de datos de prueba.
También podemos usar el modelo XGBoost como modelo final y hacer predicciones para la clasificación.
Primero, el conjunto XGBoost se ajusta a todos los datos disponibles, luego el predecir() se puede llamar a la función para hacer predicciones sobre nuevos datos. Es importante señalar que esta función espera que los datos se proporcionen siempre en forma de matriz NumPy con una fila por cada muestra de entrada.
El siguiente ejemplo lo demuestra en nuestro conjunto de datos de clasificación binaria.
|
# Hacer predicciones usando xgboost para la clasificación de numpy importación asarray de sklearn.conjuntos de datos importación make_classification de xgboost importación XGBClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Definir el modelo modelo = XGBClassifier() # Encajar el modelo en todo el conjunto de datos modelo.encajar(X, y) # hacer una sola predicción fila = [[0.2929949,–4.21223056,–1.288332,–2.17849815,–0.64527665,2.58097719,0.28422388,–7.1827928,–1.91211104,2.73729512,0.81395695,3.96973717,–2.66939799,3.34692332,4.19791821,0.99990998,–0.30201875,–4.43170633,–2.82646737,0.44916808] fila = asarray([[fila]) yhat = modelo.predecir(fila) imprimir(Clase prevista: %d’. % yhat[[0]) |
La ejecución del ejemplo se ajusta al modelo de conjunto XGBoost en todo el conjunto de datos y luego se utiliza para hacer una predicción en una nueva fila de datos, como podríamos hacer al utilizar el modelo en una aplicación.
Ahora que estamos familiarizados con el uso de XGBoost para la clasificación, veamos el API para la regresión.
XGBoost Ensemble for Regression
En esta sección, veremos el uso de XGBoost para un problema de regresión.
Primero, podemos usar la función make_regression() para crear un problema de regresión sintética con 1.000 ejemplos y 20 características de entrada.
El ejemplo completo figura a continuación.
|
# conjunto de datos de regresión de pruebas de sklearn.conjuntos de datos importación hacer_regresión # Definir el conjunto de datos X, y = make_regression(n_muestras=1000, n_funciones=20, n_informativo=15, ruido=0.1, estado_aleatorio=7) # resumir el conjunto de datos imprimir(X.forma, y.forma) |
Ejecutando el ejemplo se crea el conjunto de datos y se resume la forma de los componentes de entrada y salida.
A continuación, podemos evaluar un algoritmo XGBoost en este conjunto de datos.
Como hicimos con la última sección, evaluaremos el modelo usando la validación cruzada repetida k-pliegue, con tres repeticiones y 10 pliegues. Informaremos del error medio absoluto (MAE) del modelo en todas las repeticiones y pliegues. La biblioteca de aprendizaje de ciencias hace que el MAE sea negativo, de modo que se maximiza en lugar de minimizarse. Esto significa que los MAE negativos más grandes son mejores y un modelo perfecto tiene un MAE de 0.
El ejemplo completo figura a continuación.
|
# Evaluar el conjunto xgboost para la regresión de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_regression de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepetidoKFold de xgboost importación XGBRegressor # Definir el conjunto de datos X, y = make_regression(n_muestras=1000, n_funciones=20, n_informativo=15, ruido=0.1, estado_aleatorio=7) # Definir el modelo modelo = XGBRegressor() # Evaluar el modelo cv = RepetidoKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=‘neg_mean_absolute_error’, cv=cv, n_jobs=–1, error_score=«aumentar) # Informe de rendimiento imprimir(MAE: %.3f (%.3f)’. % (significa(n_puntuaciones), std(n_puntuaciones))) |
La ejecución del ejemplo informa de la precisión de la media y la desviación estándar del modelo.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el conjunto XGBoost con hiperparámetros por defecto alcanza un MAE de alrededor de 76.
También podemos usar el modelo XGBoost como modelo final y hacer predicciones para la regresión.
Primero, el conjunto XGBoost se ajusta a todos los datos disponibles, luego el predecir() se puede llamar a la función para hacer predicciones sobre nuevos datos. Al igual que con la clasificación, la fila única de datos debe representarse como una matriz bidimensional en formato de matriz NumPy.
El siguiente ejemplo lo demuestra en nuestro conjunto de datos de regresión.
|
# gradiente xgboost para hacer predicciones de regresión de numpy importación asarray de sklearn.conjuntos de datos importación make_regression de xgboost importación XGBRegressor # Definir el conjunto de datos X, y = make_regression(n_muestras=1000, n_funciones=20, n_informativo=15, ruido=0.1, estado_aleatorio=7) # Definir el modelo modelo = XGBRegressor() # Encajar el modelo en todo el conjunto de datos modelo.encajar(X, y) # hacer una sola predicción fila = [[0.20543991,–0.97049844,–0.81403429,–0.23842689,–0.60704084,–0.48541492,0.53113006,2.01834338,–0.90745243,–1.85859731,–1.02334791,–0.6877744,0.60984819,–0.70630121,–1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,–0.11154792] fila = asarray([[fila]) yhat = modelo.predecir(fila) imprimir(«Predicción: %d % yhat[[0]) |
La ejecución del ejemplo se ajusta al modelo de conjunto XGBoost en todo el conjunto de datos y luego se utiliza para hacer una predicción en una nueva fila de datos, como podríamos hacer al utilizar el modelo en una aplicación.
Ahora que estamos familiarizados con el uso del API de XGBoost Scikit-Learn para evaluar y utilizar los conjuntos de XGBoost, veamos la configuración del modelo.
Hiperparámetros XGBoost
En esta sección, examinaremos más de cerca algunos de los hiperparámetros que debería considerar para la afinación del conjunto Gradient Boosting y su efecto en el rendimiento del modelo.
Explorar el número de árboles
Un importante hiperparámetro para el algoritmo del conjunto XGBoost es el número de árboles de decisión utilizados en el conjunto.
Recordemos que los árboles de decisión se añaden al modelo de forma secuencial en un esfuerzo por corregir y mejorar las predicciones hechas por los árboles anteriores. Como tal, más árboles es a menudo mejor.
El número de árboles se puede establecer a través de la «n_estimadores«y por defecto a 100.
El siguiente ejemplo explora el efecto del número de árboles con valores entre 10 y 5.000.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# Explorar el número de árboles xgboost efecto en el rendimiento de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de xgboost importación XGBClassifier de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() árboles = [[10, 50, 100, 500, 1000, 5000] para n en árboles: modelos[[str(n)] = XGBClassifier(n_estimadores=n) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
La ejecución del ejemplo primero reporta la precisión media para cada número configurado de árboles de decisión.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el rendimiento mejora en este conjunto de datos hasta unos 500 árboles, después de lo cual el rendimiento parece nivelarse o disminuir.
|
>10 0.885 (0.029) >50 0.915 (0.029) >100 0.925 (0.028) >500 0.927 (0.028) >1000 0.926 (0.028) >5000 0.925 (0.027) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada número configurado de árboles.
Podemos ver la tendencia general de aumentar el rendimiento de los modelos y el tamaño de los conjuntos.
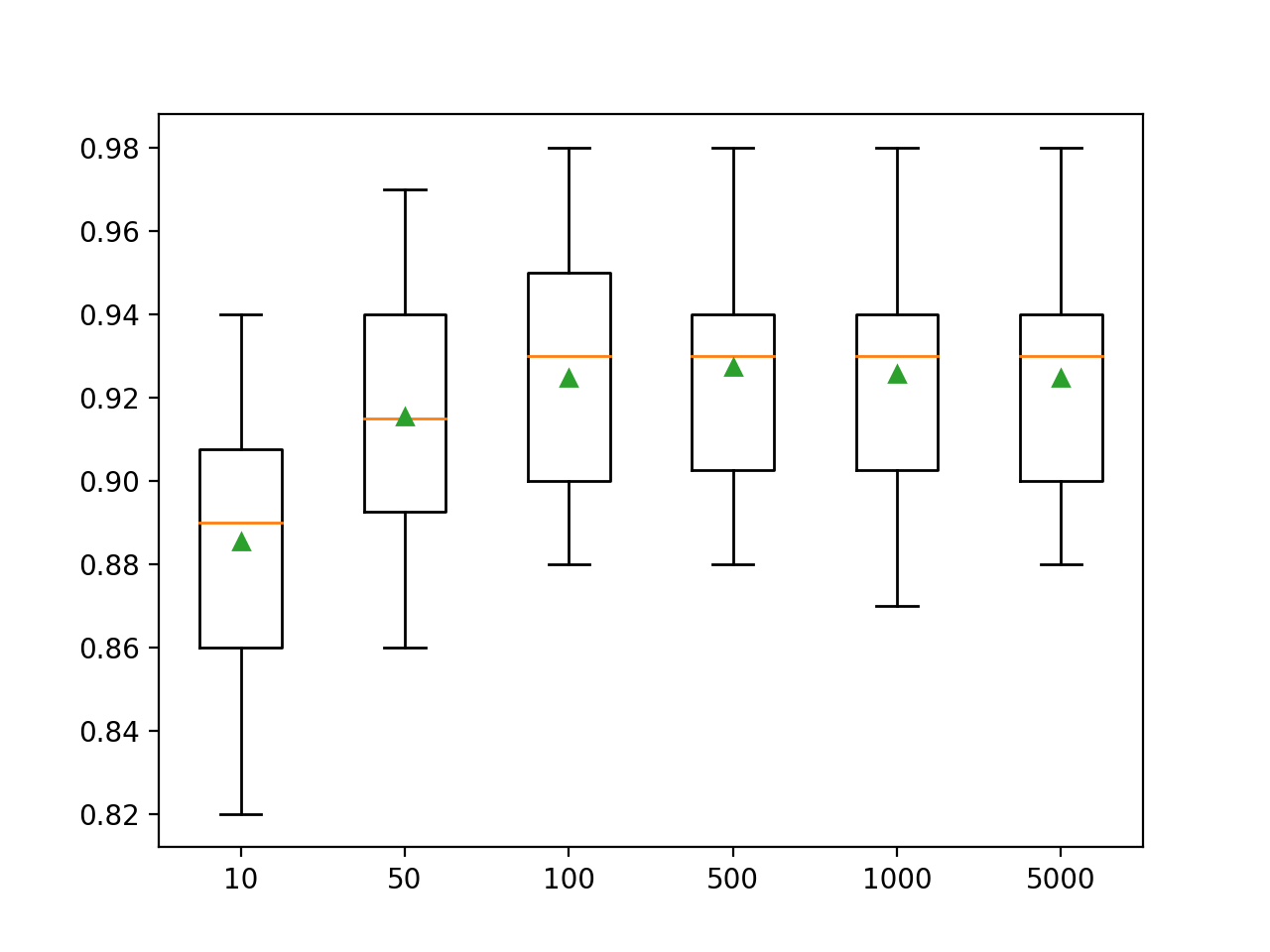
Cuadros del tamaño del conjunto XGBoost vs. Precisión de la clasificación
Explorar la profundidad del árbol
Variar la profundidad de cada árbol añadido al conjunto es otro importante hiperparámetro para aumentar el gradiente.
La profundidad del árbol controla cuán especializado está cada árbol en el conjunto de datos de entrenamiento: cuán general o excesivo puede ser. Se prefieren árboles que no sean demasiado superficiales y generales (como el AdaBoost) y no demasiado profundos y especializados (como la agregación de bootstrap).
La potenciación del gradiente generalmente funciona bien con árboles que tienen una profundidad modesta, encontrando un equilibrio entre la habilidad y la generalidad.
La profundidad del árbol se controla a través de la «max_depth«y por defecto a 6.
En el ejemplo que figura a continuación se exploran las profundidades de los árboles entre 1 y 10 y el efecto en el rendimiento del modelo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# Explorar el efecto de la profundidad del árbol xgboost en el rendimiento de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de xgboost importación XGBClassifier de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() para i en rango(1,11): modelos[[str(i)] = XGBClassifier(max_depth=i) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
Ejecutando el ejemplo primero se informa de la precisión media para cada profundidad de árbol configurada.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el rendimiento mejora con la profundidad de los árboles, tal vez asomándose a una profundidad de 3 a 8, después de lo cual los árboles más profundos y especializados dan como resultado un peor rendimiento.
|
>1 0.849 (0.028) >2 0.906 (0.032) >3 0.926 (0.027) >4 0.930 (0.027) >5 0.924 (0.031) >6 0.925 (0.028) >7 0.926 (0.030) >8 0.926 (0.029) >9 0.921 (0.032) >10 0.923 (0.035) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada profundidad de árbol configurada.
Podemos ver la tendencia general de aumentar el rendimiento del modelo con la profundidad del árbol hasta un punto, después del cual el rendimiento comienza a quedarse plano o a degradarse con los árboles demasiado especializados.
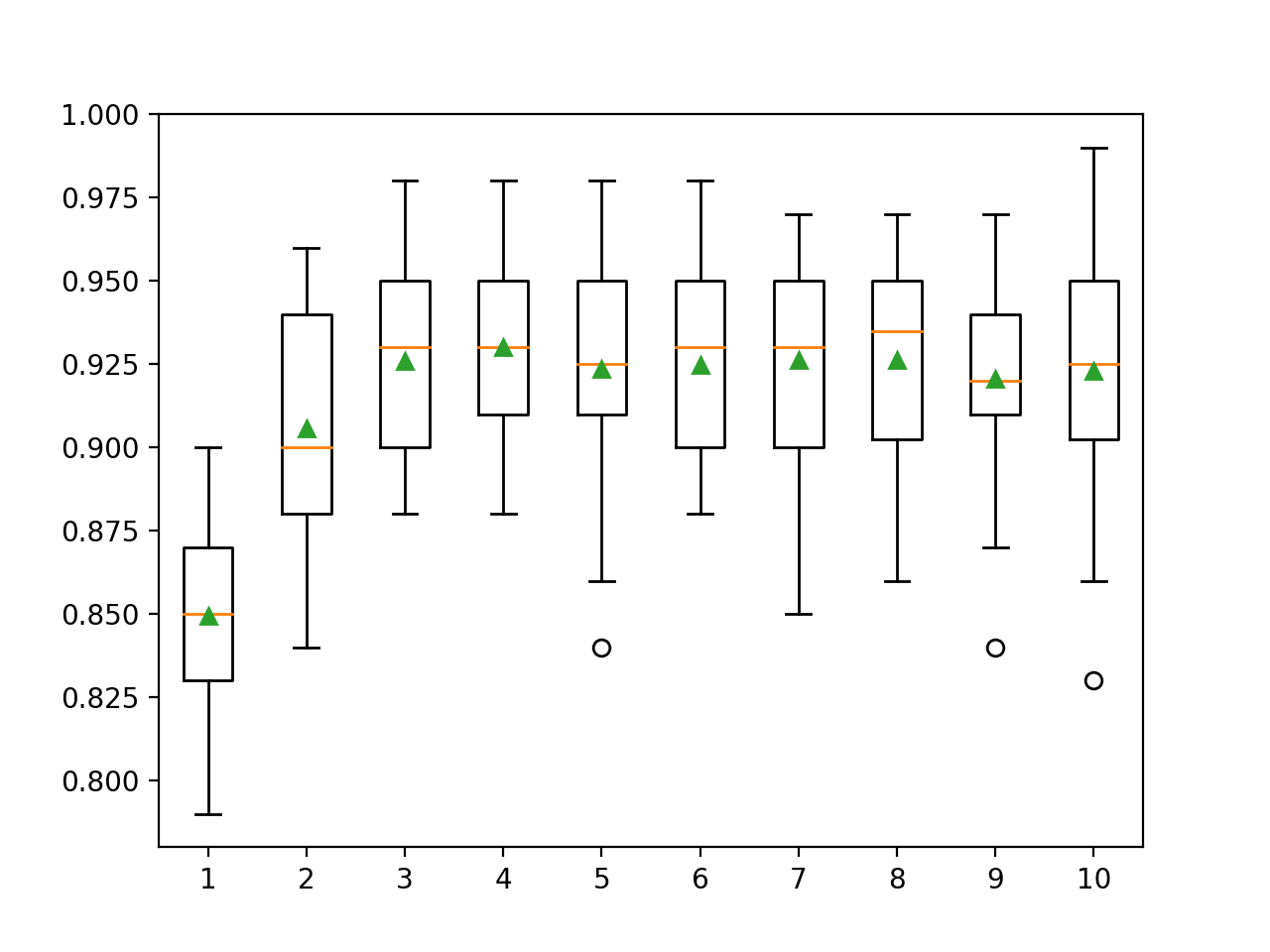
Recuadro de la profundidad de los árboles del conjunto XGBoost vs. Precisión de la clasificación
Explorar el ritmo de aprendizaje
La tasa de aprendizaje controla la cantidad de contribución que cada modelo tiene en la predicción del conjunto.
Las tasas más pequeñas pueden requerir más árboles de decisión en el conjunto.
El ritmo de aprendizaje puede ser controlado a través de la «eta«…y el valor por defecto es de 0,3.
El siguiente ejemplo explora la tasa de aprendizaje y compara el efecto de los valores entre 0,0001 y 1,0.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# Explorar el efecto de la tasa de aprendizaje xgboost en el rendimiento de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de xgboost importación XGBClassifier de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() tarifas = [[0.0001, 0.001, 0.01, 0.1, 1.0] para r en tarifas: clave = ‘%.4f’ % r modelos[[clave] = XGBClassifier(eta=r) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
Ejecutando el ejemplo primero se informa de la precisión media para cada tasa de aprendizaje configurada.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que una mayor tasa de aprendizaje resulta en un mejor rendimiento en este conjunto de datos. Esperábamos que añadir más árboles al conjunto para las tasas de aprendizaje más pequeñas elevaría aún más el rendimiento.
Esto pone de relieve el equilibrio entre el número de árboles (velocidad de entrenamiento) y la tasa de aprendizaje, por ejemplo, podemos ajustar un modelo más rápido utilizando menos árboles y una mayor tasa de aprendizaje.
|
>0.0001 0.804 (0.039) >0.0010 0.814 (0.037) >0.0100 0.867 (0.027) >0.1000 0.923 (0.030) >1.0000 0.913 (0.030) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada tasa de aprendizaje configurada.
Podemos ver la tendencia general de aumentar el rendimiento del modelo con el aumento de la tasa de aprendizaje de 0,1, tras lo cual el rendimiento se degrada.
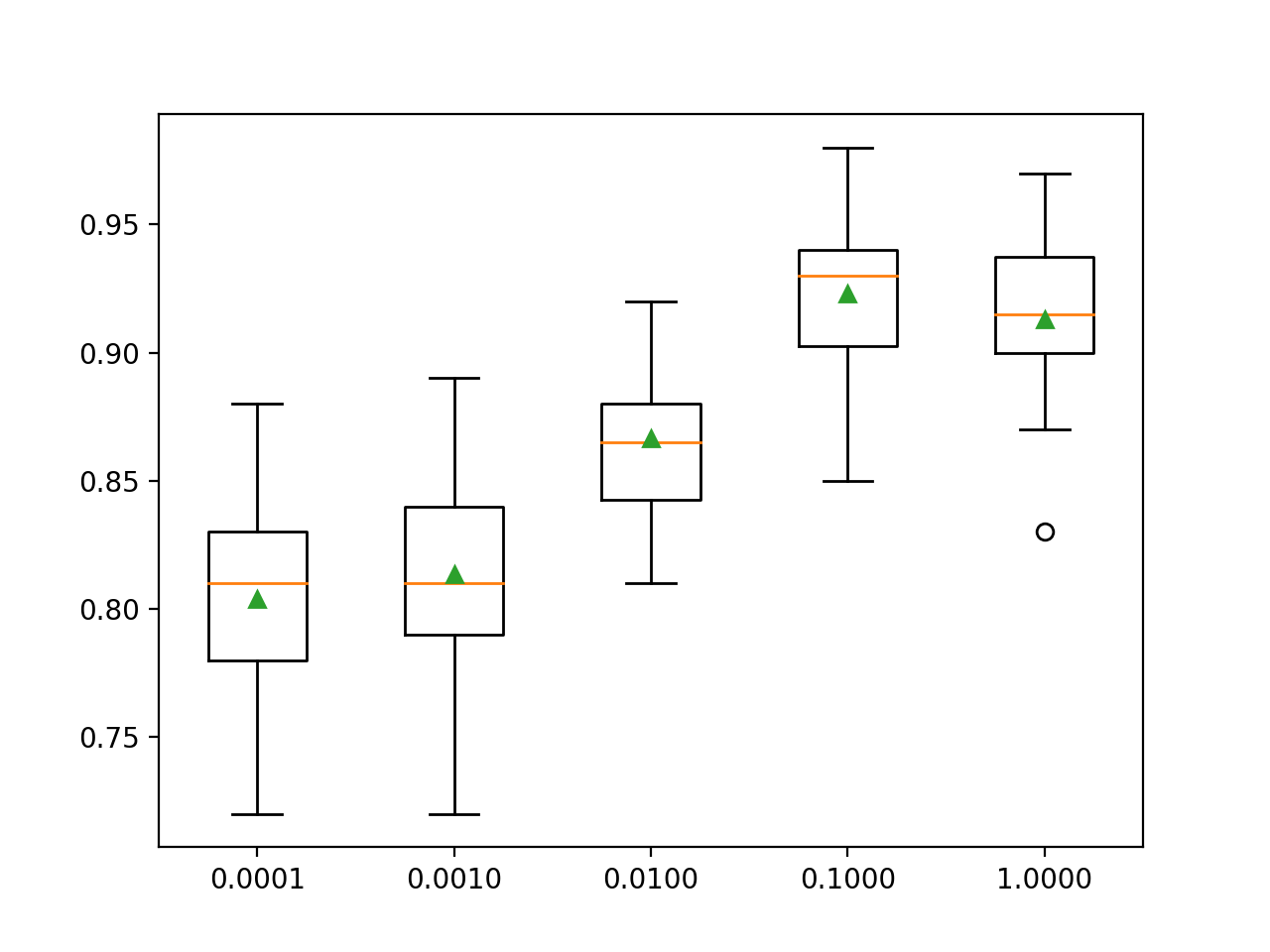
Cuadro de la tasa de aprendizaje XGBoost vs. Precisión de clasificación
Explorar el número de muestras
El número de muestras utilizadas para encajar en cada árbol puede variar. Esto significa que cada árbol se ajusta a un subconjunto seleccionado al azar del conjunto de datos de entrenamiento.
El uso de menos muestras introduce más varianza para cada árbol, aunque puede mejorar el rendimiento general del modelo.
El número de muestras utilizadas para ajustar cada árbol se especifica en el «submuestra«…y se puede ajustar a una fracción del tamaño del conjunto de datos de entrenamiento. Por defecto, está configurado en 1.0 para usar todo el conjunto de datos de entrenamiento.
El ejemplo que figura a continuación demuestra el efecto del tamaño de la muestra en el rendimiento del modelo con ratios que varían entre el 10 y el 100 por ciento en incrementos del 10 por ciento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# Explorar el efecto de la proporción de submuestras de xgboost en el rendimiento de numpy importación arange de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de xgboost importación XGBClassifier de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() para i en arange(0.1, 1.1, 0.1): clave = ‘%.1f’ % i modelos[[clave] = XGBClassifier(submuestra=i) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
Ejecutando el ejemplo primero se informa de la precisión media para cada tamaño de muestra configurado.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el rendimiento medio es probablemente mejor para un tamaño de muestra que cubra la mayor parte del conjunto de datos, como el 80 por ciento o más.
|
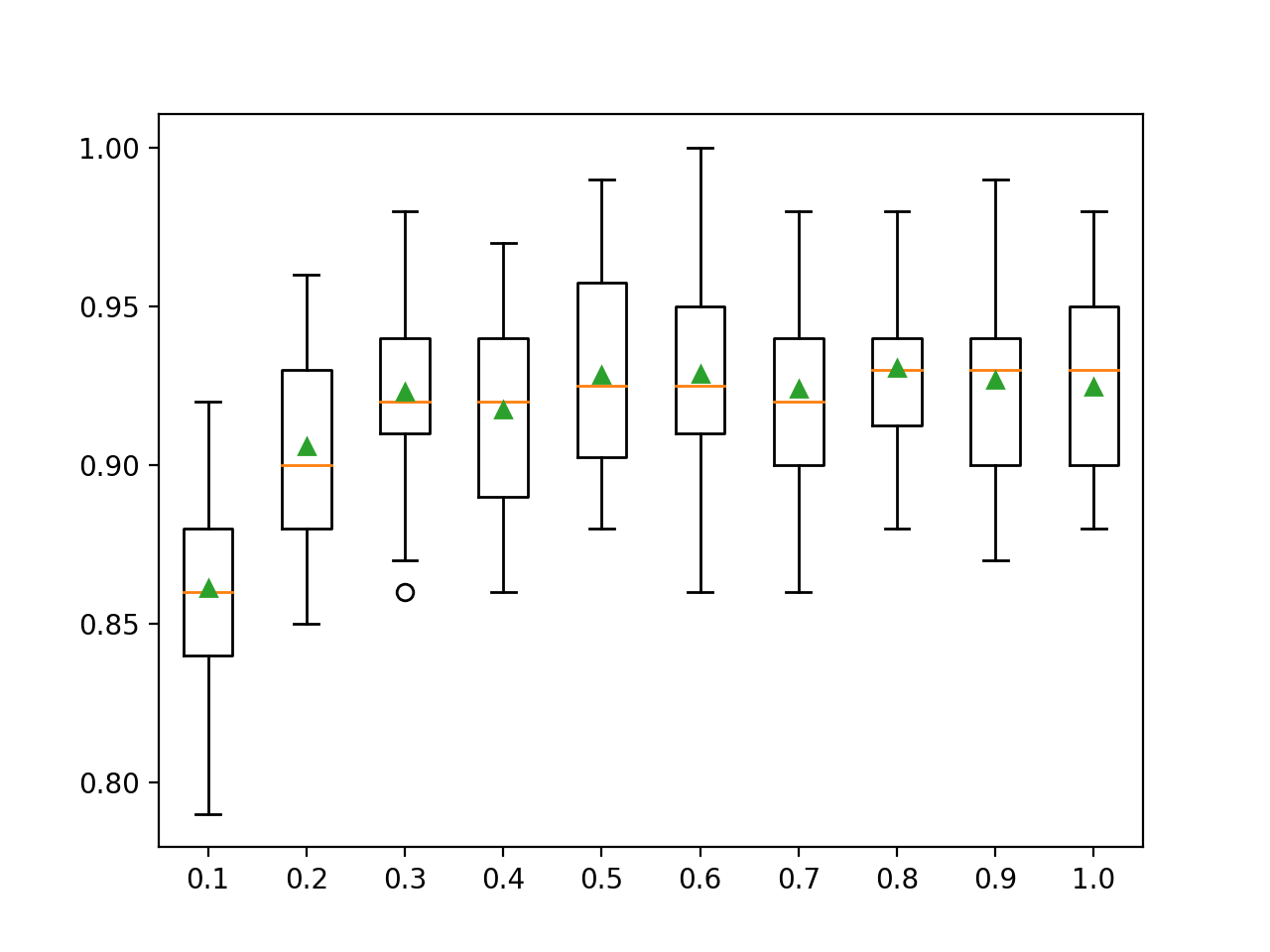
>0.1 0.876 (0.027) >0.2 0.912 (0.033) >0.3 0.917 (0.032) >0.4 0.925 (0.026) >0.5 0.928 (0.027) >0.6 0.926 (0.024) >0.7 0.925 (0.031) >0.8 0.928 (0.028) >0.9 0.928 (0.025) >1.0 0.925 (0.028) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada ratio de muestreo configurado.
Podemos ver la tendencia general de aumentar el rendimiento de los modelos, tal vez alcanzando un máximo de alrededor del 80 por ciento y manteniéndose algo nivelado.
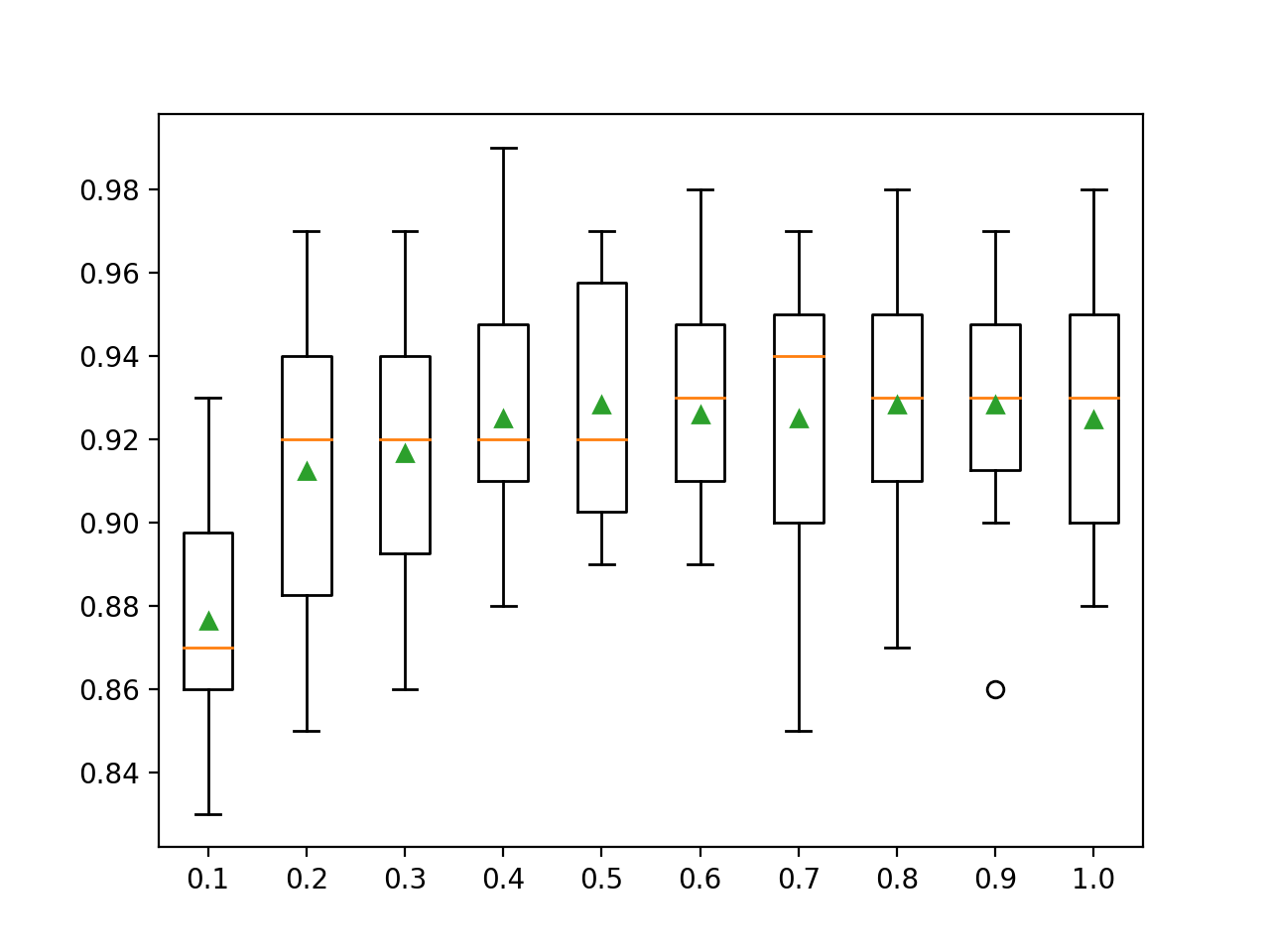
Cuadros de la relación de muestra del conjunto XGBoost vs. Precisión de la clasificación
Explorar el número de características
El número de características utilizadas para ajustarse a cada árbol de decisión puede variar.
Al igual que el cambio del número de muestras, el cambio del número de características introduce una varianza adicional en el modelo, que puede mejorar el rendimiento, aunque podría requerir un aumento del número de árboles.
El número de características utilizadas por cada árbol se toma como muestra aleatoria y se especifica por el «colsample_bytree» y se ajusta por defecto a todas las características del conjunto de datos de entrenamiento, por ejemplo, el 100 por ciento o un valor de 1,0. También se pueden muestrear columnas para cada división, y esto se controla mediante el argumento «colsample_bylevel«pero no miraremos este hiperparámetro de aquí.
En el ejemplo que figura a continuación se explora el efecto del número de características en el rendimiento del modelo con ratios que varían entre el 10 y el 100 por ciento en incrementos del 10 por ciento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# Explorar la proporción de columnas xgboost por árbol efecto en el rendimiento de numpy importación arange de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de xgboost importación XGBClassifier de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() para i en arange(0.1, 1.1, 0.1): clave = ‘%.1f’ % i modelos[[clave] = XGBClassifier(colsample_bytree=i) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
Ejecutando el ejemplo primero se informa de la precisión media para cada ratio de columnas configurado.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el rendimiento medio aumenta hasta aproximadamente la mitad del número de características (50 por ciento) y se mantiene algo nivelado después de eso. Es sorprendente que la eliminación de la mitad de las variables de entrada por árbol tenga tan poco efecto.
|
>0.1 0.861 (0.033) >0.2 0.906 (0.027) >0.3 0.923 (0.029) >0.4 0.917 (0.029) >0.5 0.928 (0.030) >0.6 0.929 (0.031) >0.7 0.924 (0.027) >0.8 0.931 (0.025) >0.9 0.927 (0.033) >1.0 0.925 (0.028) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada proporción de columna configurada.
Podemos ver la tendencia general de aumentar el rendimiento de los modelos tal vez alcanzando un máximo con una proporción del 60 por ciento y manteniéndose algo nivelada.
Cuadros de la relación entre la columna del conjunto XGBoost y la precisión de la clasificación
Más lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar en él.
Tutoriales
Documentos
Proyecto
APIs
Artículos
Resumen
En este tutorial, descubriste cómo desarrollar conjuntos de Refuerzo de Gradiente Extremo para la clasificación y la regresión.
Específicamente, aprendiste:
- Extreme Gradient Boosting es una eficiente implementación de código abierto del algoritmo de conjunto de aumento de gradiente estocástico.
- Cómo desarrollar conjuntos XGBoost para la clasificación y la regresión con la API de aprendizaje de ciencias.
- Cómo explorar el efecto de los hiperparámetros del modelo XGBoost en el rendimiento del modelo.
¿Tiene alguna pregunta?
Haga sus preguntas en los comentarios de abajo y haré lo posible por responder.
