

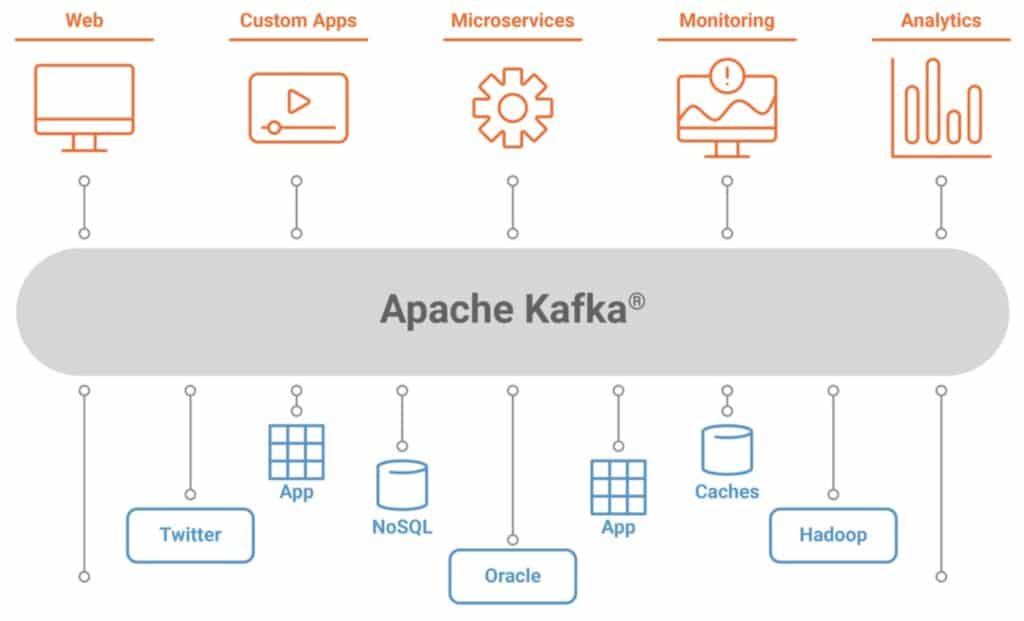
Kafka se está convirtiendo en una palabra cada vez más popular y común en estos días. Miles de empresas como Netflix, Airbnb, Microsoft, Target, etc., se basan en Apache Kafka. También encaja en la web, aplicaciones personalizadas, microservicios, análisis de monitoreo, Twitter, etc.
Sin embargo, ¿sabes realmente qué es Kafka? Kafka es una plataforma que fue desarrollada originalmente por el famoso sitio LinkedIn. En los últimos diez años, ha evolucionado para permitir al usuario almacenar grandes cantidades de datos, tener un bus de mensajes y realizar un procesamiento en tiempo real de los datos que pasan a través de él. En términos simples, Kafka es un registro de confirmación distribuido, escalable horizontalmente y tolerante a fallas. Ahora veamos todas estas palabras clave en detalle y aprendamos más sobre Apache Kafka.
¿Qué significa «distribuido»?
Un sistema que se diferencia en varias máquinas en ejecución que trabajan juntas para aparecer como un solo nodo para el usuario final se denomina sistema distribuido. Cuando decimos que Kafka es un sistema distribuido, nos referimos a que almacena, recibe y envía mensajes en un conjunto diverso de notas diferentes, a las que comúnmente se hace referencia como intermediarios.
¿Qué significa «escalable horizontalmente»?
Para comprender el significado de este término, los usuarios también deben conocer el significado de escalable verticalmente. Intentemos simplificar las cosas con la ayuda de un ejemplo. Si alguien tiene un servidor de base de datos tradicional que comienza a sobrecargarse, entonces se requiere escalado vertical o escalado hacia arriba. Esto significa que simplemente tenemos que agregar más recursos (CPU, RAM, SSD, etc.) a la máquina o dispositivo. Escalar hacia arriba tiene dos ventajas principales, a saber: no le permite escalar indefinidamente porque el hardware define ciertos límites. Además, no suele requerir tiempo de inactividad. Esto es algo que las grandes corporaciones no pueden permitirse.
Ahora entendamos el significado de «escalable horizontalmente». Implica resolver un problema similar lanzándole más máquinas. Tal adición elimina la necesidad de tiempo de inactividad. Además, no hay límites en la cantidad de máquinas que puede colocar en su clúster. Pero el problema es que no todos los sistemas tienen la capacidad de admitir la escalabilidad horizontal, ya que no están formateados para funcionar en un clúster.
¿Qué es tolerante a fallas?
Los sistemas no distribuidos tienen un solo punto de falla, a menudo abreviado como «SPoF». Si su único servidor de base de datos falla, puede causarle muchos problemas y molestias. Pero los sistemas distribuidos están formateados para lidiar con tales bloqueos y fallas de una manera configurable. Puede hacer que un clúster Kafka de 5 nodos continúe funcionando incluso si 2 nodos están inactivos o si fallan. Sin embargo, lo que debe recordarse es que cuanto más tolerante a fallas sea su sistema, menos rendimiento tendrá.
Definamos «registro de confirmación»
Esto también se conoce comúnmente como «registro de escritura anticipada» o «registro de transacciones». Un registro de confirmación es una estructura de datos ordenada y persistente que solo admite anexos. Esto simplemente significa que no puede cambiar ni eliminar ningún registro. Garantiza el pedido de los artículos y se lee de izquierda a derecha. Asegúrese de aprender también apache kafka.
¿Cómo actúa Kafka?
Kafka es una estructura de datos simple. En esto, las aplicaciones o los productores envían mensajes o registros a un corredor. Estos mensajes luego son procesados por otras aplicaciones, a las que comúnmente se hace referencia como consumidores. Estos registros se almacenan en lo que se denomina un «tema» y los consumidores deben suscribirse a este tema para recibir nuevos mensajes.
Si estos temas se vuelven enormes, se dividen en particiones más compactas para mejorar su rendimiento y escalabilidad. Kafka se asegura de que todos los registros presentes dentro de una partición estén ordenados en la secuencia en que ingresaron.
Un desplazamiento de un mensaje es la forma en que lo distingue. Puede ver esto como un índice de matriz normal, es decir, un número de secuencia que se incrementa para cada mensaje nuevo en una partición. Esta plataforma sigue el famoso principio del corredor tonto y el consumidor inteligente. Esto simplemente se refiere al hecho de que Kafka no realiza un seguimiento de los mensajes o registros que lee el consumidor y los elimina. En cambio, lo que hace es almacenarlos durante un período de tiempo determinado, como un día. Incluso puede hacer esto hasta que se cumpla algún límite de tamaño. Los consumidores sondean a Kafka en busca de nuevos mensajes y le dicen qué mensajes desean ver. Esto les da la oportunidad de aumentar o disminuir el desplazamiento en el que se encuentran. Por lo tanto, les permite reproducir y reprocesar eventos.
A lo que se debe prestar atención es que los consumidores son en realidad grupos de consumidores, que pueden contener uno o más procesos de consumo. Cada partición está vinculada a un solo proceso consumidor en un grupo para evitar que dos procesos lean el mismo mensaje dos veces.
Kafka almacena los metadatos en un dispositivo llamado Zookeeper.
¿Qué es el Zookeeper?
Puede definirse como un almacén de clave-valor distribuido. Se usa ampliamente para almacenar metadatos y manejar la mecánica de la agrupación en clústeres (como latidos, distribución de actualizaciones y configuraciones, etc.).