

En este post vamos a ver la evolución del esquema y los tipos de compatibilidad en Kafka con el registro de esquemas de Kafka. Con una buena comprensión de los tipos de compatibilidad podemos hacer con seguridad cambios en nuestros esquemas a lo largo del tiempo sin romper a nuestros productores o consumidores involuntariamente.
Conjunto de datos
Tenemos un capítulo dedicado a Kafka en nuestro curso de Desarrollo de Hadoop en el Mundo Real. En este capítulo, transmitimos datos de confirmación de asistencia en vivo de Meetup.com a Kafka escribiendo nuestra propia calidad de producción, lista para ser desplegada, productores y consumidores con la integración de Spring Kafka. Vamos a utilizar el mismo flujo de datos de RSVP de Meetup.com como fuente para explicar la evolución del esquema y los tipos de compatibilidad con el registro de esquemas de Kafka.
Caso de uso y configuración del proyecto
Digamos que Meetup.com decide usar a Kafka para distribuir las confirmaciones de asistencia. En este caso, el programa de producción será administrado por Meetup.com y si quiero consumir las RSVPs producidas por Meetup.com, tengo que conectarme al cluster de Kakfa y consumir las RSVPs. Para mí, como consumidor para consumir mensajes, lo primero que necesito saber es el esquema, es decir, la estructura del mensaje de confirmación de asistencia. Un esquema típico para los mensajes en Kafka se verá así.
{
"namespace": "com.hirw.kafkaschemaregistry.producer",
"type": "record",
"name": "Rsvp",
"fields": [
{
"name": "rsvp_id",
"type": "long"
},
{
"name": "group_name",
"type": "string"
},
{
"name": "event_id",
"type": "string"
},
{
"name": "event_name",
"type": "string"
},
{
"name": "member_id",
"type": "int"
},
{
"name": "member_name",
"type": "string"
}
]
}
El esquema enumera los campos del mensaje junto con los tipos de datos. Puedes imaginar que el esquema es un contrato entre el productor y el consumidor. Cuando el productor produce mensajes, utilizará este esquema para producir mensajes. Así que en este caso, cada mensaje de RSVP tendrá rsvp_id, group_name, event_id, event_name, member_id y member_name.
El productor es un proyecto de Spring Kafka, escribiendo mensajes Rsvp a Kafka usando el esquema anterior. Así que todos los mensajes enviados al tema de Kafka se escribirán usando el esquema anterior y se serializarán usando Avro. Asumimos que el código del productor es mantenido por meetup.com. Consumidor es también un proyecto de Kafka de primavera, consumiendo los mensajes que se escriben a Kafka. Consumer también utilizará el esquema anterior y deserializará los mensajes Rsvp utilizando Avro. Mantenemos el proyecto Consumer.
Problema
Meetup.com se puso en marcha con esta nueva forma de distribuir RSVPs, es decir, a través de Kafka. Tanto el productor como el consumidor están de acuerdo con el esquema y todo es genial. Es una tontería pensar que el esquema se quedaría así para siempre. Digamos que meetup.com no sintió el valor de proporcionar el campo member_id y lo elimina. ¿Qué crees que pasará – afectará a los consumidores?
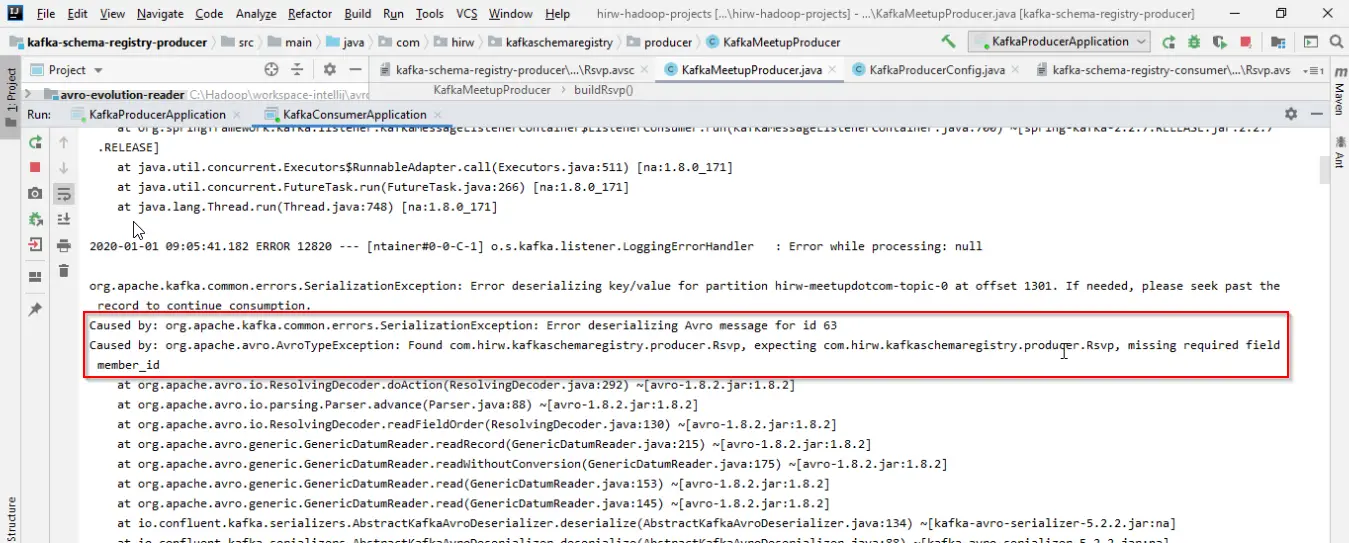
El campo member_id no tiene un valor por defecto y se considera una columna obligatoria por lo que este cambio afectará a los consumidores. Cuando un productor elimina un campo obligatorio, el consumidor verá un error como el siguiente –
Causado por: org.apache.kafka.errores.comunes.de.serializaciónExcepción: Error de deserialización del mensaje de Avro para el id 63
Causado por: org.apache.avro.AvroTypeExcepción: found com.hirw.kafkaschemaregistry.producer.Rsvp,
waiting com.hirw.kafkaschemaregistry.producer.Rsvp, missing required field member_id
Si los consumidores están pagando a los consumidores, se enojarán y esto será un error muy costoso. ¿Hay formas de evitar tales errores? Por suerte para nosotros, hay formas de evitar tales errores con el registro de esquemas de Kafka y los tipos de compatibilidad. El registro de esquemas de Kafka nos proporciona formas de comprobar nuestros cambios en el nuevo esquema propuesto y asegurarnos de que los cambios que estamos haciendo en el esquema son compatibles con los esquemas existentes. Los cambios que son permisibles y los que no lo son en nuestros esquemas dependen del tipo de compatibilidad que se defina en el nivel del tema.
Hay varios tipos de compatibilidad en Kafka. Ahora exploremos cada uno de ellos.
BACKWARD
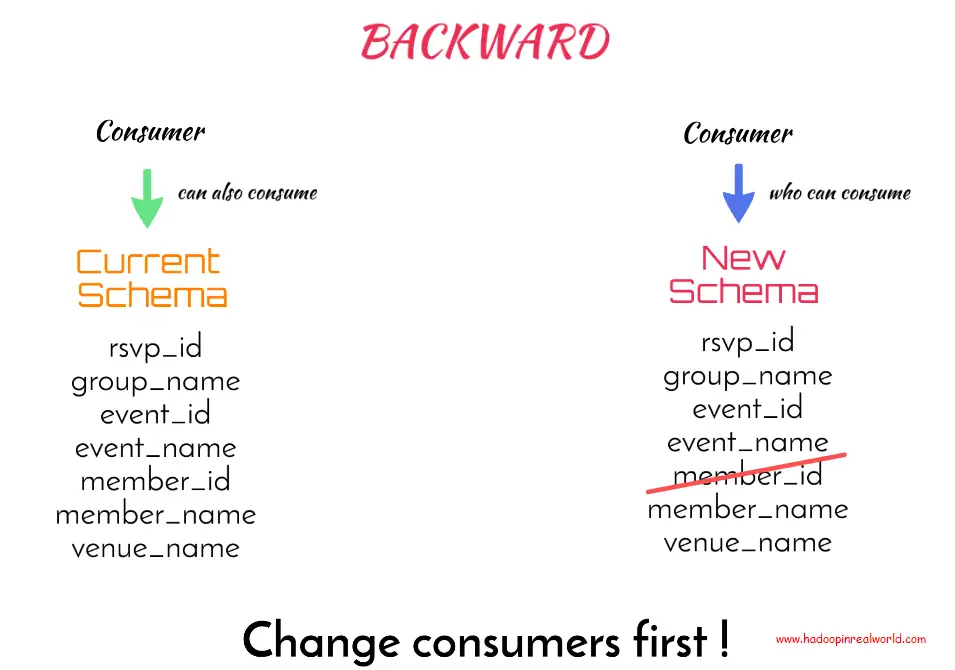
Se considera que un esquema es compatible con BACKWARD si un consumidor que puede consumir los datos producidos por el nuevo esquema también podrá consumir los datos producidos por el esquema actual.
El tipo de compatibilidad BACKWARD es el tipo de compatibilidad por defecto para el registro del esquema si no especificamos el tipo de compatibilidad explícitamente. Intentemos ahora entender qué pasó cuando eliminamos el campo member_id del nuevo esquema. ¿Es el nuevo esquema compatible con el sistema anterior?
En el nuevo esquema estamos eliminando el ID de miembro. Supongamos que un consumidor ya está consumiendo los datos producidos con el nuevo esquema – tenemos que preguntar si puede consumir los datos producidos con el antiguo esquema. La respuesta es sí. En el nuevo esquema el ID_miembro no está presente, así que si al consumidor se le presentan los datos con el ID_miembro, es decir, con el esquema actual, no tendrá problemas para leerlo porque los campos adicionales están bien. Así que podemos decir que el nuevo esquema es compatible con el anterior y el registro de esquemas de Kafka permitirá el nuevo esquema.
Pero desafortunadamente este cambio afectará a los clientes existentes como vimos en nuestra demostración. Así que en el modo de compatibilidad retroactiva, los consumidores deben cambiar primero para adaptarse al nuevo esquema. Es decir, tenemos que hacer el cambio de esquema en el consumidor primero antes de que podamos hacerlo en el productor.
Esto está bien si tienes el control sobre los consumidores o si los consumidores están impulsando los cambios en el esquema. En algunos casos, los consumidores no estarán contentos con hacer cambios por su parte, especialmente si son consumidores pagados. En tales casos, la compatibilidad retroactiva no es la mejor opción.
Si los consumidores se ven afectados por un cambio, ¿por qué el registro de esquemas permite el cambio en primer lugar?
Los tipos de compatibilidad no garantizan que todos los cambios sean transparentes para todos. Nos da una pauta y comprensión de qué cambios son permisibles y cuáles no para un determinado tipo de compatibilidad. Cuando los cambios son permisibles para un tipo compatible, con una buena comprensión de los tipos compatibles, estaremos en una mejor posición para entender quién será impactado para que podamos tomar medidas apropiadas.
En nuestra instancia actual, la eliminación de member_id en el nuevo esquema está permitida según el tipo de compatibilidad BACKWARD. Porque según la compatibilidad BACKWARD, un consumidor que pueda consumir RSVP sin el ID_de_miembro que está en el nuevo esquema, podrá consumir RSVP con el antiguo esquema que está con el ID_de_miembro. Por lo tanto, el cambio se permite según la compatibilidad BACKWARD, pero eso no significa que el cambio no sea perjudicial si no se maneja adecuadamente.
Cambios de esquema en el modo de compatibilidad BACKWARD, es mejor notificar a los consumidores primero antes de cambiar el esquema. En nuestro caso meetup.com debe notificar a los consumidores que el member_id será eliminado y dejar que los consumidores eliminen las referencias del member_id primero y luego cambiar el productor para eliminar el member_id. Esa es la forma más adecuada para manejar este cambio de esquema específico.
En el modo de compatibilidad con el pasado, ¿puedo añadir un campo sin valor predeterminado en el nuevo esquema?
Aquí estamos tratando de añadir un nuevo campo llamado respuesta, que es en realidad la respuesta del usuario de su RSVP y no tiene un valor por defecto. ¿Este cambio en el esquema es aceptable en el tipo de compatibilidad retroactiva? ¿Qué opina usted?
Veamos. Con el modo compatible con BACKWARD, un consumidor que es capaz de consumir los datos producidos por el nuevo esquema también podrá consumir los datos producidos por el esquema actual.
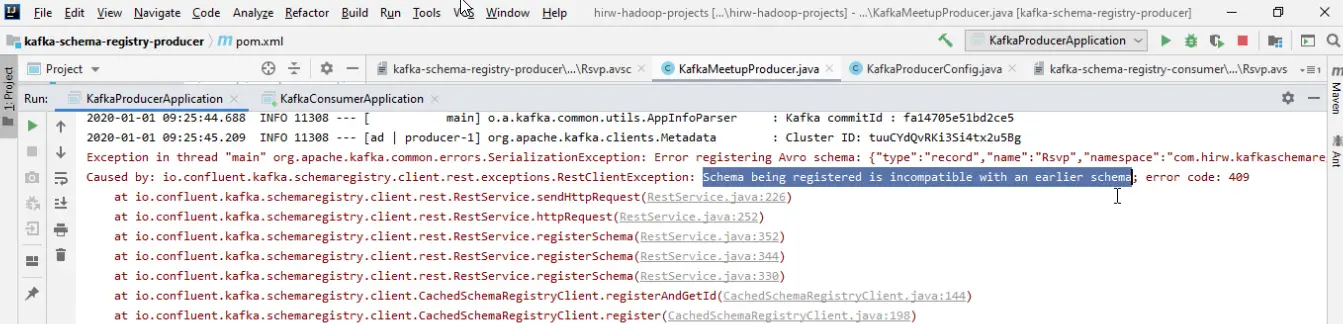
Así que supongamos que un consumidor ya está consumiendo datos con respuesta que no tiene un valor predeterminado, lo que significa que es un campo obligatorio. Ahora, ¿puede consumir los datos producidos con el esquema actual que no tiene una respuesta? La respuesta es NO, porque el consumidor esperará una respuesta en los datos, ya que es un campo obligatorio. Así que el cambio de esquema propuesto no es compatible con el pasado y el registro del esquema no permitirá este cambio en primer lugar.
El error es muy claro: «El esquema que se está registrando es incompatible con un esquema anterior».
Por lo tanto, si el esquema no es compatible con el tipo de compatibilidad del conjunto, el registro del esquema rechaza el cambio y esto es para salvaguardarnos de cambios no intencionados.
¿Y si cambiamos la respuesta de campo con un valor predeterminado? ¿Se considerará este cambio como compatible con el pasado?
Responde esto – «¿Puede un consumidor que ya está consumiendo datos con respuesta con un valor por defecto de digamos «Sin respuesta» consumir los datos producidos con el esquema actual que no tiene respuesta?»
La respuesta es SÍ porque los datos de consumo de los consumidores producidos con el nuevo esquema con respuesta sustituirán al valor por defecto cuando falte el campo de respuesta, que será el caso cuando los datos se produzcan con el esquema actual.
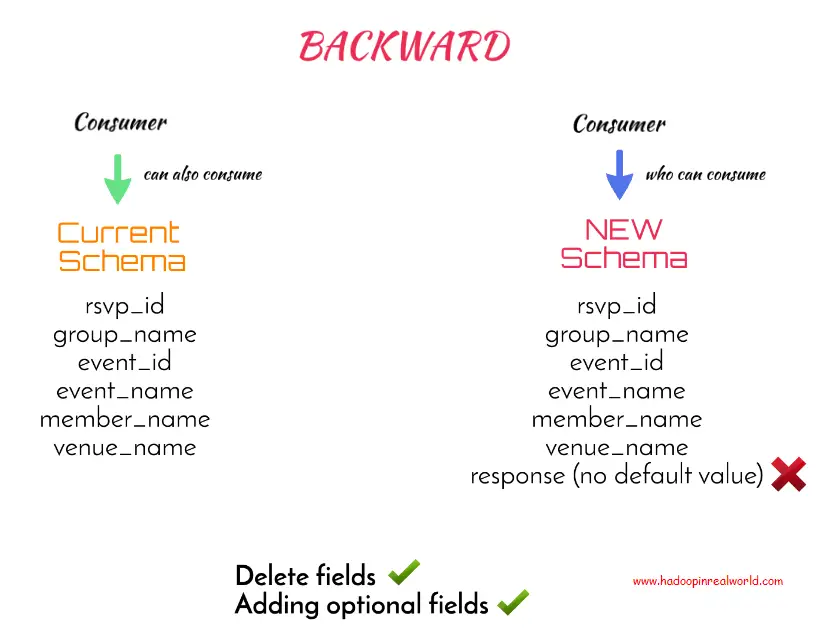
En resumen, la compatibilidad con BACKWARD permite borrar y añadir al esquema campos con valores por defecto. A diferencia de la adición de campos con valores por defecto, la eliminación de campos afectará a los consumidores, por lo que es mejor actualizar primero a los consumidores con el tipo de compatibilidad BACKWARD.
BACKWARD_TRANSITIVE
El tipo de compatibilidad BACKWARD comprueba la nueva versión con la versión actual, si necesita que esta comprobación se haga en todas las versiones registradas, entonces debe utilizar el tipo de compatibilidad BACKWARD_TRANSITIVE.

FORWARD
Muy bien, hasta ahora hemos visto los tipos de compatibilidad BACKWARD y BACKWARD_TRANSITIVE.
¿Pero qué pasa si no nos gustan los cambios de esquema que afectan a los consumidores actuales? Es decir, queremos evitar lo que pasó con nuestros consumidores cuando quitamos el ID de miembro del esquema. Cuando quitamos el ID de miembro, afectó a nuestros consumidores de forma abrupta. Si los consumidores son clientes de pago, se enojarían y sería un golpe para su reputación. Entonces, ¿cómo evitamos eso?
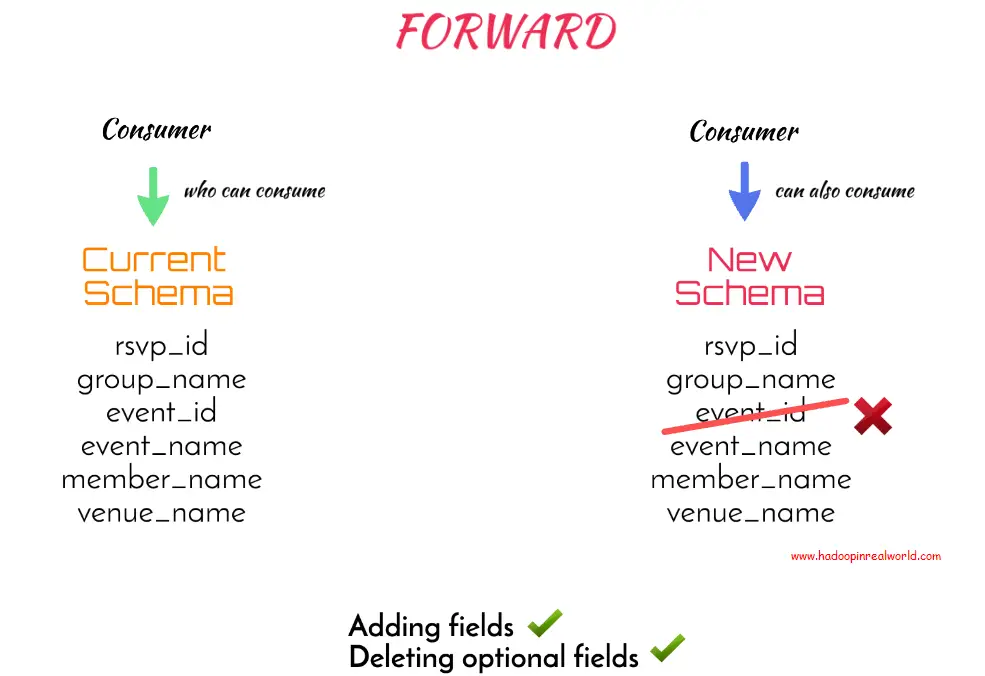
En lugar de usar el tipo de compatibilidad por defecto, BACKWARD, podemos usar el tipo de compatibilidad FORWARD. Un esquema se considera compatible con FORWARD si un consumidor que consume datos producidos por el esquema actual también podrá consumir datos producidos por el nuevo esquema.
Con esta regla, no podremos eliminar una columna sin un valor por defecto en nuestro nuevo esquema porque eso afectaría a los consumidores que consumen el esquema actual. Así que añadir campos está bien y eliminar los campos opcionales también está bien.
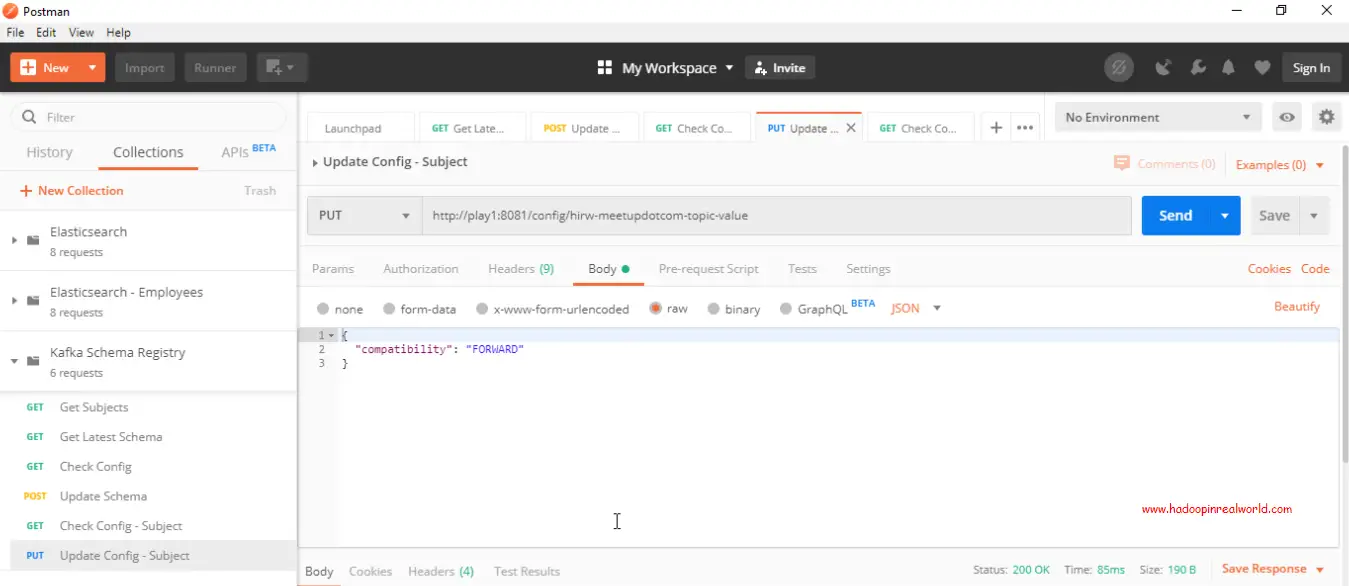
¿Cómo cambiar el tipo de compatibilidad de un tema?
Emitir una petición PUT en la configuración especificando el nombre del tema y en el cuerpo de la petición especificar la compatibilidad como FORWARD. Eso es todo. Emitamos la petición.
Ahora, cuando comprobemos la configuración del tema veremos que el tipo de compatibilidad está ahora establecido en FORWARD. Ahora que el tipo de compatibilidad del tema se ha cambiado a FORWARD, no se nos permite eliminar los campos obligatorios, es decir, las columnas sin valores por defecto. Vamos a confirmarlo. ¿Por qué no intentamos eliminar el campo event_id, que es un campo obligatorio.
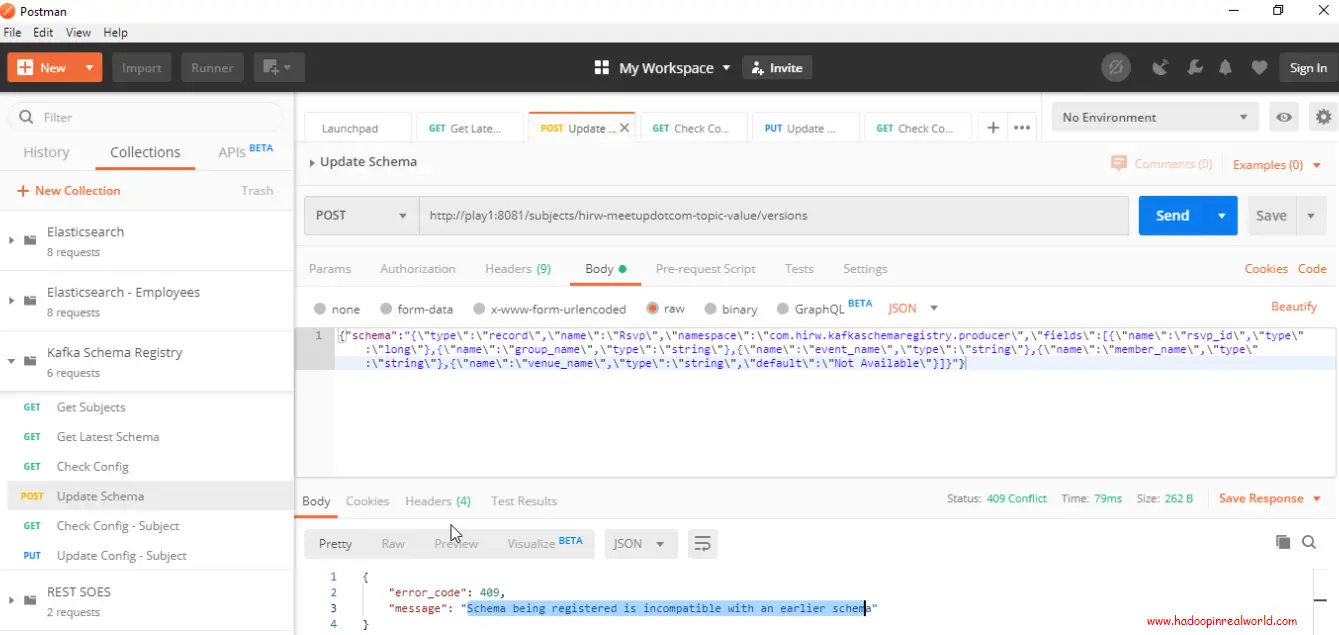
Actualicemos el esquema sobre el tema emitiendo un comando REST. Para actualizar el esquema emitiremos un POST con el cuerpo que contiene el nuevo esquema. Aquí en el esquema hemos eliminado el campo event_id.
«Esquema»: «Tipo de registro», «nombre», «Rsvp», «namespace», «com.hirw», «kafkaschemaregistry», «fields»:[{”name”:”rsvp_id”,”type”:”long”},{”name”:”group_name”,”type”:”string”},{”name”:”event_name”,”type”:”string”},{”name”:”member_name”,”type”:”string”},{”name”:”venue_name”,”type”:”string”,”default”:”Not Available”}]}”}
Ver con el tipo de compatibilidad establecido en FORWARD la actualización realmente falló. Habrías recibido la misma respuesta aunque hubieras hecho cambios en tu código, actualizando el esquema y pulsando los RSVPs. Con el tipo de compatibilidad FORWARD, puede garantizar que los consumidores que están consumiendo su esquema actual podrán consumir el nuevo esquema.
FORWARD_TRANSITIVE
FORWARD sólo comprueba el nuevo esquema con el esquema actual, si quieres comprobar todos los esquemas registrados necesitas cambiar el tipo de compatibilidad a, lo adivinaste – FORWARD_TRANSITIVE.

COMPLETO Y NINGUNO
Hay 3 tipos más de compatibilidad. Si quieres que tus esquemas sean compatibles tanto con el Adelante como con el Atrás, entonces puedes usar el Completo. Con el tipo de compatibilidad FULL se le permite añadir o eliminar sólo los campos opcionales, es decir, los campos con valores predeterminados. FULL comprueba su nuevo esquema con el esquema actual. Si desea que el nuevo esquema se verifique con todos los esquemas registrados, puede utilizar, de nuevo, lo adivinó, utilice FULL_TRANSITIVE. Los tipos de compatibilidad FULL y FULL_TRANSITIVE son más restrictivos en comparación con otros.
El último tipo de compatibilidad es NINGUNO. NINGUNO significa que todos los tipos de compatibilidad están desactivados. Esto significa que todos los cambios son posibles y esto es arriesgado y no se utiliza típicamente en la producción.