

Un grupo de científicos informáticos de diferentes universidades ha lanzado un LLM multimodal de código abierto llamado LLaVA, y me topé con él mientras navegaba por Twitter la semana pasada. Similar a GPT-4, este LLM puede procesar entradas de texto e imágenes. El proyecto utiliza un LLM de propósito general y un codificador de imágenes para crear un modelo de asistente de visión y lenguaje grande. Dado que las funciones promocionadas parecían prometedoras, decidí probar este modelo de lenguaje grande para comprender qué tan preciso y confiable es y qué podemos esperar del próximo modelo multimodal de GPT4 (especialmente sus capacidades visuales). En ese sentido, sigamos adelante y exploremos LLaVA.
¿Qué es LLaVA, un Modelo de Lenguaje Multimodal?
LLaVA (Large Language-and-Vision Assistant) es un LLM multimodal, similar al GPT-4 de OpenAI, que puede manejar entradas de texto e imágenes. Si bien OpenAI aún no ha agregado la capacidad de procesamiento de imágenes a GPT-4, un nuevo proyecto de código abierto ya lo ha hecho. infundir un codificador de visión.
Desarrollado por informáticos de la Universidad de Wisconsin-Madison, Microsoft Research y la Universidad de Columbia, el proyecto tiene como objetivo demostrar cómo funcionaría un modelo multimodal y comparar su capacidad con GPT-4.
Utiliza Vicuna como modelo de lenguaje grande (LLM) y CLIP ViT-L/14 como codificador visual, que, para aquellos que no lo saben, ha sido desarrollado por OpenAI. El proyecto ha generado multimodal de alta calidad datos de seguimiento de instrucciones usando GPT-4 y eso se traduce en un excelente rendimiento. Alcanza un 92,53% en el benchmark ScienceQA.
Aparte de eso, se ha ajustado para conjuntos de datos de razonamiento y chat visual de propósito general, particularmente del dominio científico. Por lo tanto, en general, LLaVA es un punto de partida de la nueva realidad multimodal, y tenía muchas ganas de probarlo.
Cómo usar el asistente de visión de LLaVA ahora mismo
1. Para usar LLaVA, puede dirigirse a llava.hliu.cc y ver la demostración. utiliza el LLaVA-13B-v1 modelo ahora mismo.
2. Simplemente agregue una imagen en la esquina superior izquierda y seleccione «Cultivo“. Asegúrese de agregar imágenes cuadradas para obtener el mejor resultado.
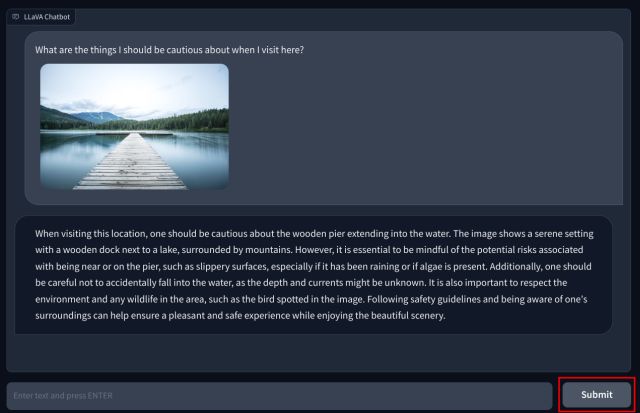
3. Ahora, agrega tu pregunta en la parte inferior y presione «Enviar». El LLM luego estudiará la imagen y explicará todo en detalle. También puede hacer preguntas de seguimiento sobre la imagen que carga.
LLM multimodal con capacidades visuales: primeras impresiones
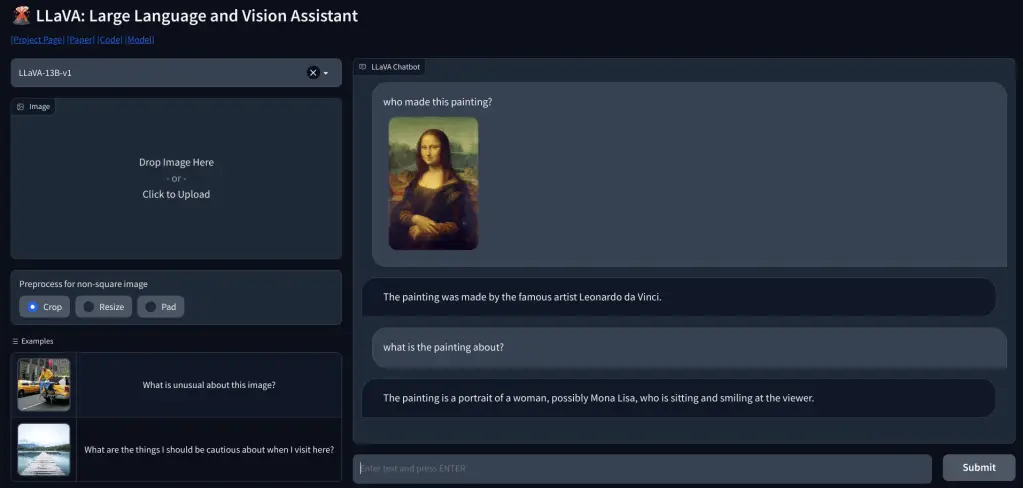
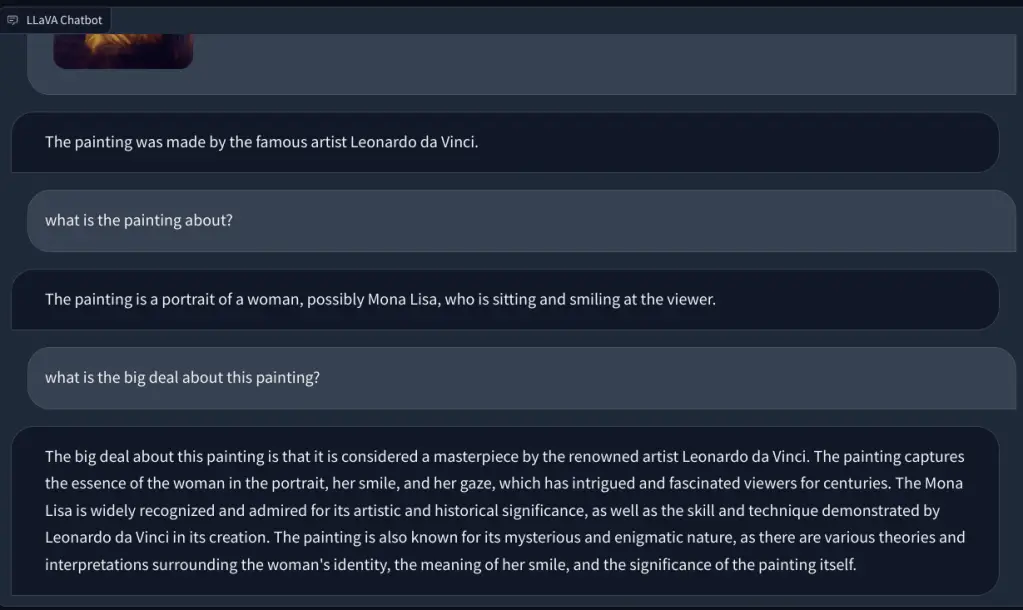
Para comprobar la capacidad de visión de LLaVA, comenzamos con algunos ejemplos básicos. Subimos un cuadro y le pedimos a LLaVA que identificar la pintura, y respondió correctamente a la pregunta. También hice algunas preguntas de seguimiento, y también hizo un buen trabajo.
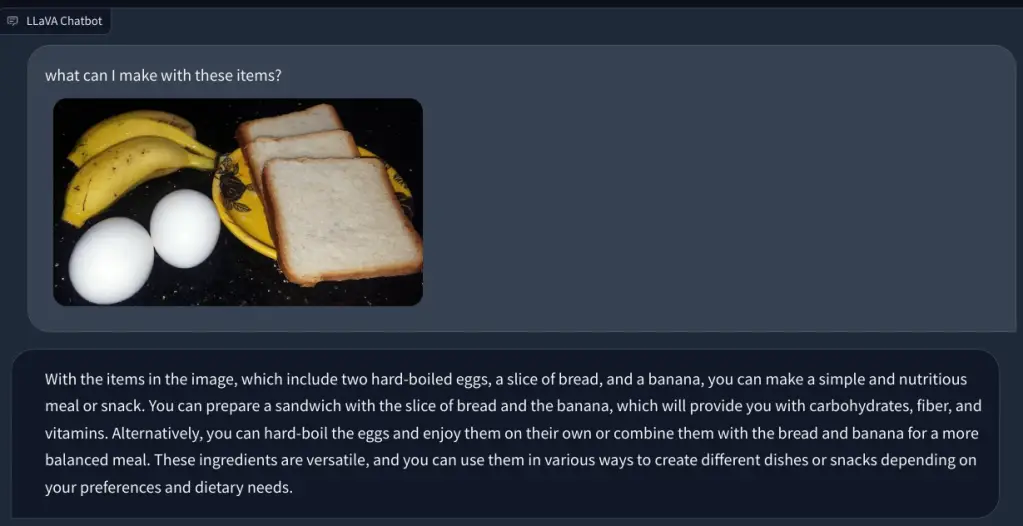
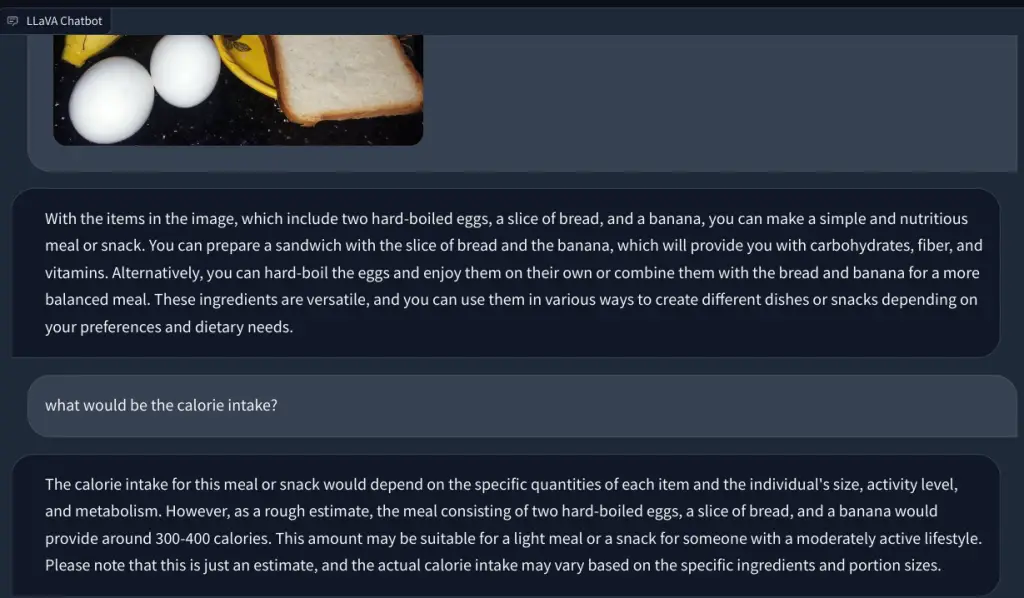
En otro ejemplo, subí una imagen de alimentos e hice preguntas sobre el tipo de desayuno que se puede hacer y cuál sería la ingesta calórica total. Identificó cada artículo correctamente y presentó recetas de comida y un conteo aproximado de calorías. Aunque las recetas no eran tan detalladas, el LLM multimodal sugirió ideas para incorporar los tres alimentos en un plato/comida.
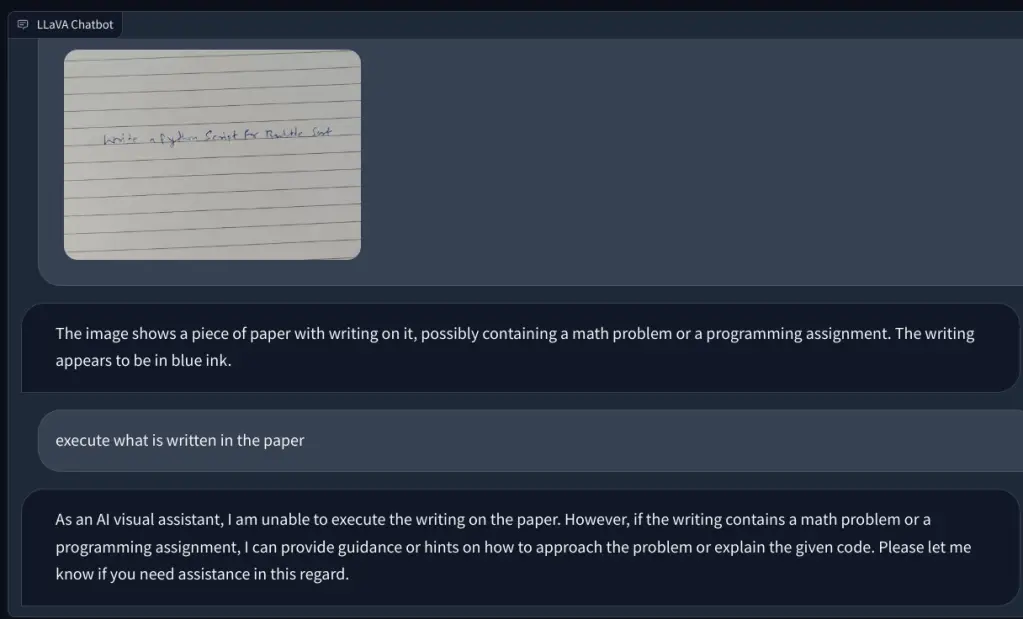
Luego, agregué una imagen con una nota escrita a mano pidiéndole que escribiera un script de Python para el algoritmo de clasificación de burbujas. Pero no pudo reconocer el texto en papel. Y no pudo ejecutar el código. Luego, agregué una pregunta matemática simple y pregunté el valor de x, pero nuevamente, dio una respuesta incorrecta.
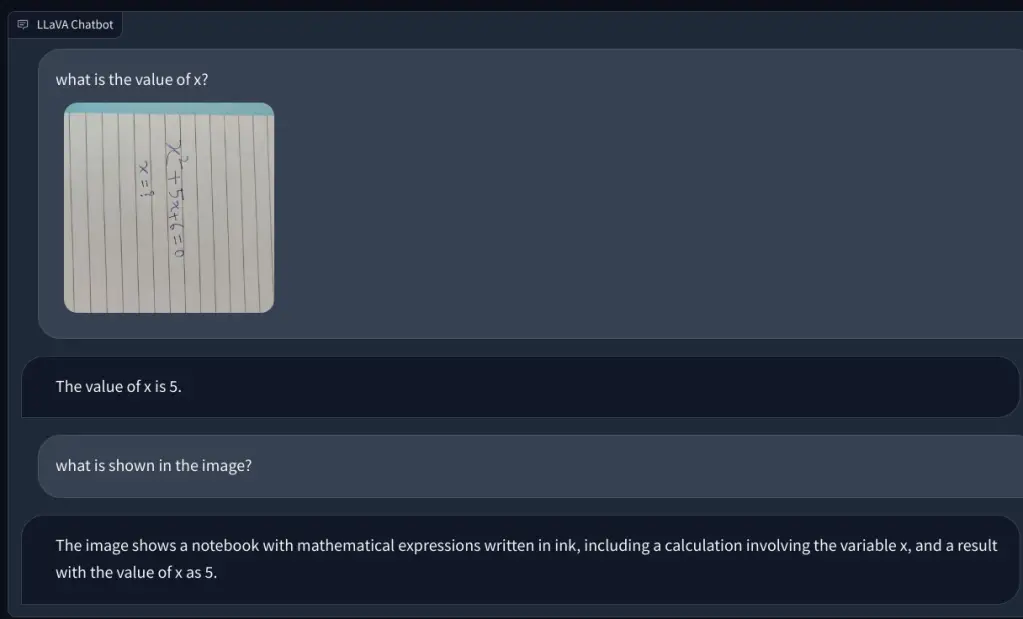
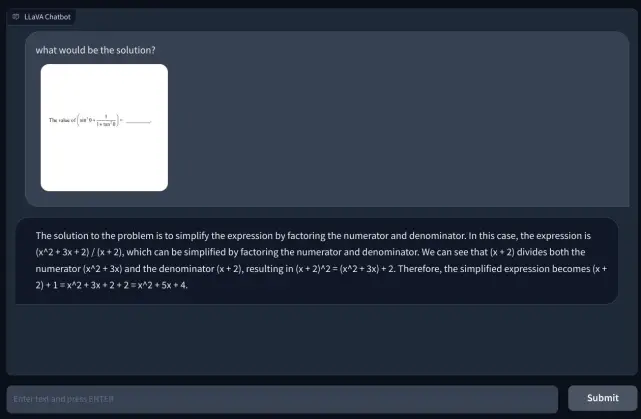
Para investigar más, agregué otra pregunta matemática, pero no estaba escrita a mano para que fuera más legible. Pensé que tal vez era mi escritura lo que la IA no podía reconocer. Sin embargo, nuevamente, simplemente alucinó e inventó una ecuación por sí mismo y dio una respuesta incorrecta. Mi entendimiento es que simplemente no usa OCR, pero visualiza los píxeles y los compara con los modelos ImageNet de CLIP. En la resolución de cuestiones matemáticas, incluidas las notas manuscritas y no manuscritas, el modelo LLaVA fracasó estrepitosamente.
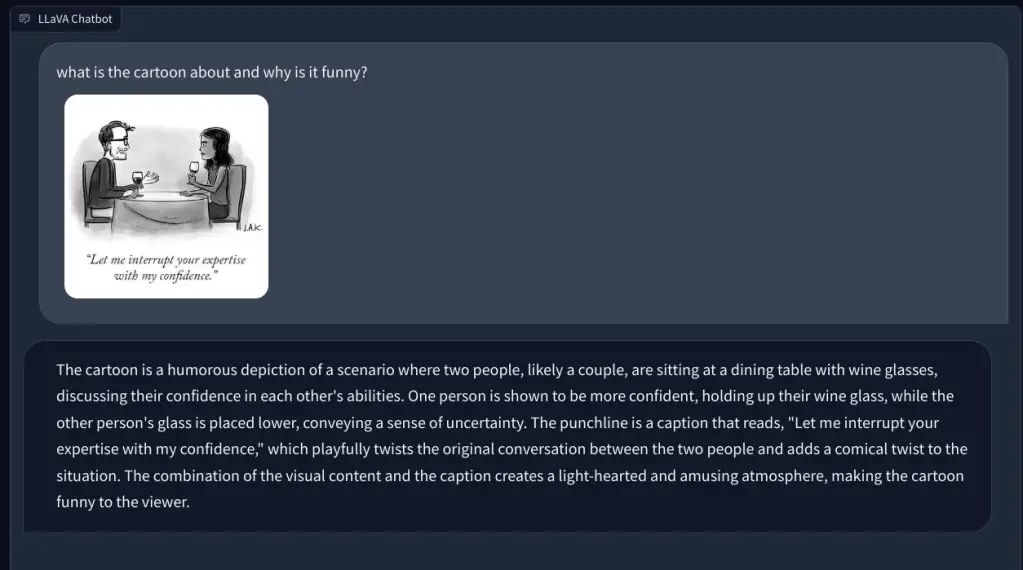
Avanzando, le pedí que explicara una caricatura del New Yorker y por qué es divertida, pero no entendió la razón detrás del humor. Él simplemente describió la escena. Cuando señalé el aspecto de género en la imagen (el humor), este LLM multimodal entendió la tarea y respondió correctamente.

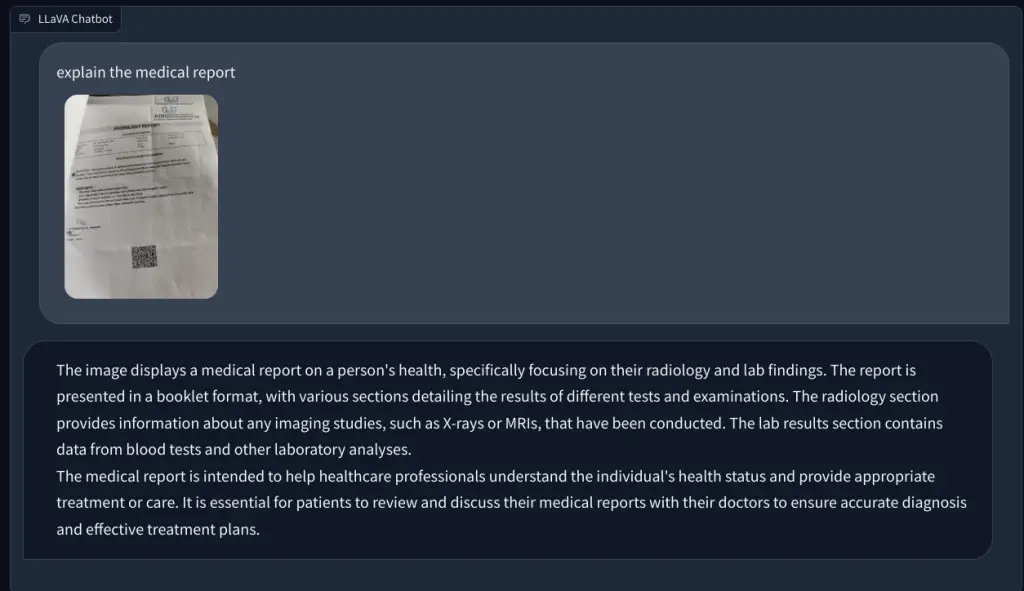
Finalmente, le pedí a LLaVA que examinar un informe médico, pero nuevamente, alucinó y dio un resumen incorrecto. A pesar de los repetidos intentos, no pudo encontrar datos relevantes en la imagen cargada.

LLaVA necesita muchas mejoras
En resumen, es muy temprano, al menos en el espacio de código abierto, para crear un LLM multimodal capaz. En el ausencia de un modelo lenguaje-visual poderoso y fundacional, la comunidad de código abierto podría quedarse atrás de las propietarias. Meta sure ha lanzado una serie de modelos de código abierto, pero no ha lanzado ningún modelo visual para que trabaje la comunidad de código abierto, excepto Segment Anything, que no es aplicable en este caso.
Mientras que Google lanzó PaLM-E, un modelo de lenguaje multimodal incorporado en marzo de 2023 y OpenAI ya demostró las capacidades multimodales de GPT-4 durante el lanzamiento. Cuando se le preguntó qué tiene de divertido una imagen en la que se conecta un conector VGA al puerto de carga de un teléfono, GPT-4 gritó el absurdo con precisión clínica. En otra demostración durante la transmisión de desarrolladores de GPT-4, el modelo multimodal de OpenAI creó rápidamente un sitio web completamente funcional después de analizar una nota escrita a mano en un diseño garabateado en el papel.
En pocas palabras, por lo que hemos probado hasta ahora en LLaVA, parece que tomará mucho más tiempo ponerse al día con OpenAI en el espacio lenguaje-visual. Por supuesto, con más progreso, desarrollo e innovación, las cosas mejorarían. Pero por ahora, estamos ansiosos por probar las capacidades multimodales de GPT-4.