

En este artículo mensual recurrente, filtramos los documentos de investigación recientes que aparecen en el servidor de preimpresión de arXiv.org en busca de temas convincentes relacionados con la IA, el aprendizaje de las máquinas y el aprendizaje profundo – de disciplinas como la estadística, las matemáticas y la informática – y le proporcionamos una útil lista de «lo mejor» del mes pasado. Investigadores de todo el mundo contribuyen a este repositorio como preludio al proceso de revisión por pares para su publicación en revistas tradicionales. arXiv contiene un verdadero tesoro de métodos de aprendizaje estadístico que usted podrá utilizar algún día en la solución de problemas de la ciencia de los datos. Los artículos que se enumeran a continuación representan una pequeña fracción de todos los artículos que aparecen en el servidor de preimpresión. Están listados sin un orden particular con un enlace a cada artículo junto con un breve resumen. Se proporcionan enlaces a los repositorios de GitHub cuando están disponibles. Los artículos especialmente relevantes están marcados con un icono de «pulgar hacia arriba». Considere que estos son artículos de investigación académica, típicamente dirigidos a estudiantes graduados, postdoctorados y profesionales experimentados. Generalmente contienen un alto grado de matemáticas, así que prepárense. ¡Disfruten!
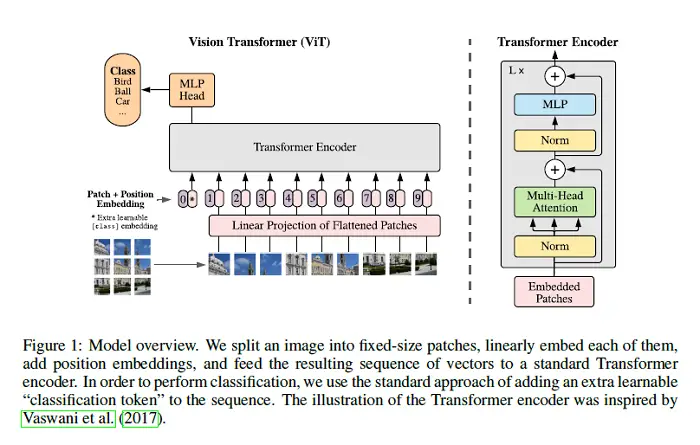
Una imagen vale 16×16 palabras: Transformadores para el reconocimiento de imágenes a escala

Aunque la arquitectura del Transformador se ha convertido en el estándar de facto para las tareas de procesamiento del lenguaje natural, sus aplicaciones a la visión por ordenador siguen siendo limitadas. En la visión, la atención se aplica conjuntamente con las redes convolucionales, o se utiliza para sustituir ciertos componentes de las redes convolucionales manteniendo su estructura general. En el presente documento se demuestra que esta dependencia de las redes convolucionales no es necesaria y que un transformador puro aplicado directamente a las secuencias de parches de imágenes puede funcionar muy bien en las tareas de clasificación de imágenes. Cuando se lo entrena previamente en grandes cantidades de datos y se lo transfiere a múltiples puntos de referencia de reconocimiento de imágenes de tamaño mediano o pequeño (ImageNet, CIFAR-100, VTAB, etc.), el transformador de visión (ViT) logra excelentes resultados en comparación con las redes convolucionales de última generación, al tiempo que requiere una cantidad sustancialmente menor de recursos computacionales para su entrenamiento. El código PyTorch asociado a este trabajo se puede encontrar AQUÍ.
mT5: Un transformador de texto a texto masivamente multilingüe y pre-entrenado
El reciente «Transformador de transferencia de texto a texto» (T5) aprovechó un formato y una escala unificados de texto a texto para lograr resultados de vanguardia en una amplia variedad de tareas de PNL en inglés. En este documento se presenta el mT5, una variante multilingüe del T5 que fue preformado en un nuevo conjunto de datos basado en Common Crawl que abarca 101 idiomas. También se describe el diseño y la modificación de la capacitación del mT5 y se demuestra su rendimiento de vanguardia en muchos puntos de referencia multilingües. Todos los códigos y modelos de puntos de control de TensorFlow utilizados en este trabajo están disponibles públicamente AQUÍ.
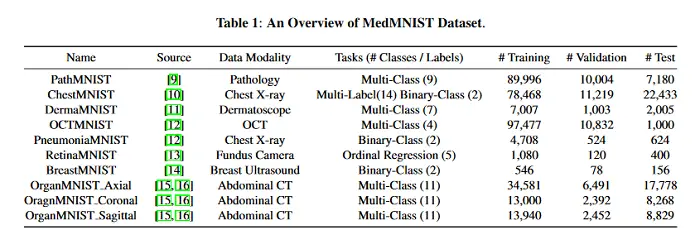
Decatlón de clasificación del MedMNIST: Una referencia AutoML ligera para el análisis de imágenes médicas
Este artículo presenta MedMNIST, una colección de 10 conjuntos de datos médicos abiertos preprocesados. El MedMNIST está estandarizado para realizar tareas de clasificación en imágenes livianas de 28×28, que no requieren conocimientos previos. Abarca las modalidades de datos primarios en el análisis de imágenes médicas, y es diverso en cuanto a la escala de datos (de 100 a 100.000) y las tareas (binario/multiclase, regresión ordinal y multi-etiqueta). El MedMNIST podría utilizarse con fines educativos, para la creación de prototipos rápidos, el aprendizaje de máquinas multimodales o el AutoML en el análisis de imágenes médicas. Además, el Decatlón de Clasificación del MedMNIST está diseñado para hacer una comparación de los algoritmos de AutoML en los 10 conjuntos de datos; en el documento se comparan varios métodos de base, incluidas herramientas de AutoML de código abierto o comerciales. Los conjuntos de datos, el código PyTorch de evaluación y los métodos de línea de base para el MedMNIST están a disposición del público AQUÍ.
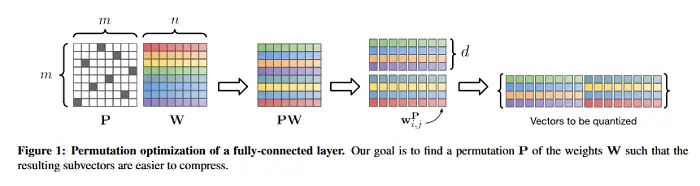
Permuta, cuantifica y afina: Compresión eficiente de las redes neuronales
La compresión de las grandes redes neuronales es un paso importante para su despliegue en plataformas computacionales con recursos limitados. En este contexto, la cuantificación de vectores es un marco atractivo que expresa múltiples parámetros utilizando un solo código, y recientemente ha logrado una compresión de redes de última generación en una serie de tareas de visión central y de procesamiento de lenguaje natural. La clave del éxito de la cuantificación vectorial es decidir qué grupos de parámetros deben comprimirse juntos. Los trabajos anteriores se han basado en heurísticos que agrupan la dimensión espacial de filtros convolucionales individuales, pero sigue sin abordarse una solución general. Esto es deseable para las convoluciones puntuales (que dominan las arquitecturas modernas), las capas lineales (que no tienen noción de la dimensión espacial) y las convoluciones (cuando se comprime más de un filtro con la misma palabra clave). En este documento se hace la observación de que los pesos de dos capas adyacentes pueden ser permutables mientras expresan la misma función. Se establece entonces una conexión con la teoría de la distorsión de la velocidad y se buscan permutaciones que den como resultado redes más fáciles de comprimir. Por último, se utiliza un algoritmo de cuantificación recocido para comprimir mejor la red y lograr una mayor precisión final. Los resultados se muestran en la clasificación de imágenes, la detección de objetos y la segmentación, reduciendo la brecha con el modelo sin comprimir en un 40 a 70% con respecto al estado actual de la técnica. El código PyTorch asociado a este trabajo está disponible AQUÍ.
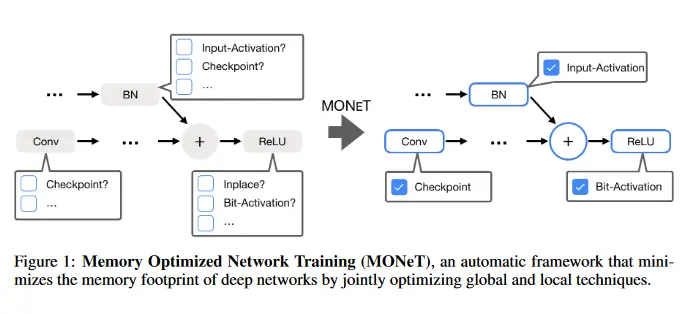
Optimización de la memoria para redes profundas
El aprendizaje profundo es lento, pero constante, golpeando un cuello de botella de la memoria. Mientras que el cálculo de tensores en las GPU de gama alta aumentó 32 veces en los últimos cinco años, la memoria total disponible sólo creció 2,5 veces. Esto impide a los investigadores explorar arquitecturas más grandes, ya que la formación de grandes redes requiere más memoria para almacenar salidas intermedias. Este documento presenta MONeT, un marco automático que minimiza tanto la huella de la memoria como la sobrecarga computacional de las redes profundas. MONeT optimiza conjuntamente el programa de control y la implementación de varios operadores. MONeT es capaz de superar todas las operaciones anteriores ajustadas manualmente, así como el control automático de los puntos de control. MONeT reduce el requerimiento de memoria total en 3 veces para varios modelos de PyTorch, con una sobrecarga de 9-16% en el cálculo. Por el mismo costo de cálculo, MONeT requiere 1,2-1,8 veces menos memoria que los actuales marcos de control automatizado de última generación. El código PyTorch asociado a este trabajo está disponible AQUÍ.
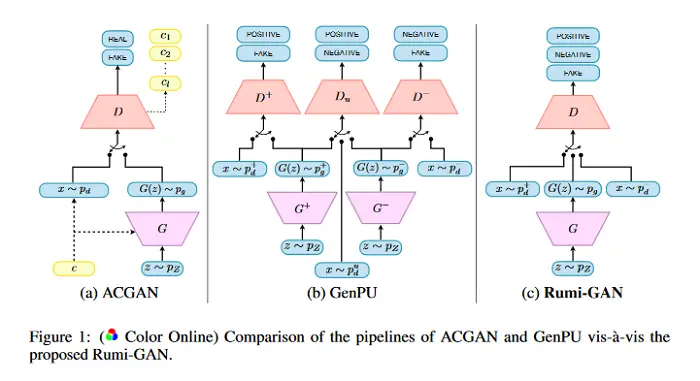
Enseñar a un GAN lo que no se debe aprender
Las redes de adversarios generativos (GAN) se concibieron originalmente como modelos generativos no supervisados que aprenden a seguir una distribución objetivo. Variantes como las GAN condicionales, las GAN de clasificación auxiliar (ACGAN) proyectan las GAN a marcos de aprendizaje supervisados y semisupervisados proporcionando datos etiquetados y utilizando discriminadores multiclase. Este trabajo aborda el problema de las GAN supervisadas desde una perspectiva diferente, motivada por la filosofía del famoso poeta persa Rumi que dijo: «El arte de saber es saber qué ignorar».
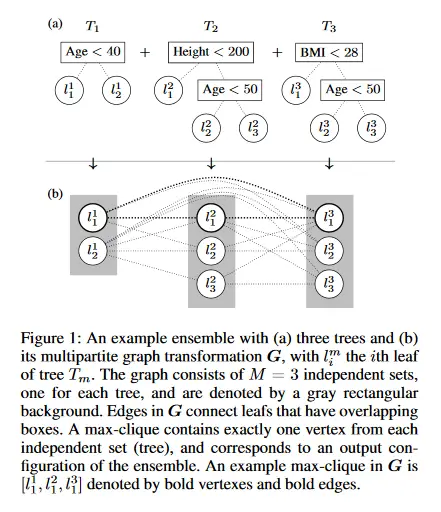
Verificación versátil de los conjuntos de árboles
Los modelos aprendidos con máquinas a menudo deben cumplir ciertos requisitos (por ejemplo, de equidad o legales). Esto ha estimulado el interés por elaborar enfoques que puedan verificar de manera demostrable si un modelo satisface ciertas propiedades. En este documento se presenta un algoritmo genérico denominado Veritas que permite abordar múltiples tareas de verificación diferentes para modelos de conjuntos de árboles como los bosques aleatorios (RF) y los árboles de decisión con gradiente de impulso (GBDT). Esta generalidad contrasta con los trabajos anteriores, que se han centrado exclusivamente en la generación de ejemplos de adversarios o en la comprobación de la robustez. Veritas formula la tarea de verificación como un problema genérico de optimización e introduce una novedosa representación del espacio de búsqueda. Veritas ofrece dos ventajas fundamentales. En primer lugar, proporciona en todo momento límites inferiores y superiores cuando el problema de optimización no puede resolverse con exactitud. Por el contrario, muchos métodos existentes se han centrado en soluciones exactas y, por lo tanto, están limitados por el hecho de que el problema de verificación sea NP-completo. En segundo lugar, Veritas produce soluciones completas (limitadas por debajo de lo óptimo) que pueden utilizarse para generar ejemplos concretos. Experimentalmente, se ha demostrado que Veritas supera el estado de la técnica anterior: a) generando soluciones exactas con mayor frecuencia, b) produciendo límites más estrechos cuando a) no es posible, y c) ofreciendo órdenes de magnitud de aceleración. Posteriormente, Veritas permite abordar más y mayores escenarios de verificación en el mundo real.
Suscríbete al boletín de noticias gratuito de InsideBIGDATA.