
Si bien la inteligencia artificial, el aprendizaje automático y el aprendizaje profundo son términos tecnológicos de tendencia que escuchamos en todas partes en estos días, existen importantes conceptos erróneos sobre lo que realmente significan estas palabras. Muchas empresas afirman incorporar algún tipo de inteligencia artificial (IA) en sus aplicaciones o servicios, pero ¿qué significa eso en la práctica?
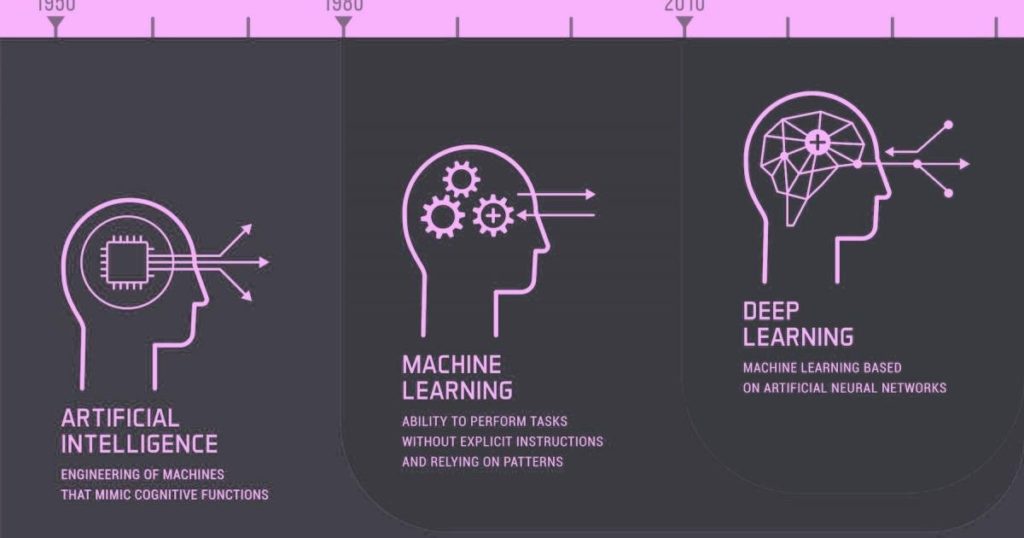
Inteligencia artificial
En términos generales, la IA describe cuando una máquina imita las funciones cognitivas que los humanos asocian con otras mentes humanas, como el aprendizaje y la resolución de problemas. En un nivel aún más elemental, la IA puede ser simplemente una regla programada que le dice a la máquina que se comporte de una manera específica en ciertas situaciones. En otras palabras, la inteligencia artificial no puede ser más que varias declaraciones if-else.
Una declaración if-else es una regla simple programada por un humano. Considere un robot que se mueve por una carretera. Una regla programada para ese robot podría ser:
if something_is_in_the_way is True:
stop_moving()
else:
continue_moving()Entonces, cuando hablamos de inteligencia artificial, vale la pena considerar dos subcampos más específicos de la IA: el aprendizaje automático y el aprendizaje profundo.
Aprendizaje automático frente a aprendizaje profundo
Ahora que comprendemos mejor lo que realmente significa la IA, podemos analizar más de cerca el aprendizaje automático y el aprendizaje profundo para establecer una distinción clara entre estos dos.
IA frente a aprendizaje automático frente a aprendizaje profundo
- Inteligencia artificial: un programa que puede sentir, razonar, actuar y adaptarse
- Aprendizaje automático: algoritmos cuyo rendimiento mejora a medida que se exponen a más datos a lo largo del tiempo.
- Aprendizaje profundo: subconjunto del aprendizaje automático en el que las redes neuronales de varias capas aprenden a partir de grandes cantidades de datos.
El aprendizaje automático no es una tecnología nueva
¿Qué es el aprendizaje automático? Podemos pensar en el aprendizaje automático como una serie de algoritmos que analizan datos, aprenden de ellos y toman decisiones informadas basadas en esos conocimientos adquiridos.
El aprendizaje automático puede conducir a una variedad de tareas automatizadas. Afecta prácticamente a todas las industrias, desde la búsqueda de malware de seguridad de TI hasta la previsión meteorológica y los corredores de bolsa que buscan operaciones óptimas. El aprendizaje automático requiere matemáticas complejas y mucha codificación para lograr las funciones y los resultados deseados. El aprendizaje automático también incorpora algoritmos clásicos para varios tipos de tareas, como la agrupación en clústeres, regresión o clasificación. Tenemos que entrenar estos algoritmos en grandes cantidades de datos. Cuantos más datos proporcione para su algoritmo, mejor será su modelo.
Cuando alguien dice que está trabajando con un algoritmo de aprendizaje automático, puede llegar a la esencia de su valor preguntando: ¿cuál es la función objetivo?
El aprendizaje automático es un campo relativamente antiguo e incorpora métodos y algoritmos que han existido durante decenas de años, algunos de ellos desde la década de 1960. Estos algoritmos clásicos incluyen el Clasificador Naïve Bayes y el Máquinas de vectores de soporte, los cuales se utilizan a menudo en la clasificación de datos. Además de la clasificación, también existen algoritmos de análisis de conglomerados como el K-medias y agrupación basada en árboles. Para reducir la dimensionalidad de los datos y obtener más información sobre su naturaleza, el aprendizaje automático utiliza métodos como el análisis de componentes principales y tSNE.
El componente de entrenamiento de un modelo de aprendizaje automático significa que el modelo intenta optimizar a lo largo de una determinada dimensión. En otras palabras, los modelos de aprendizaje automático intentan minimizar el error entre sus predicciones y los valores reales reales.
Para ello debemos definir una función de error (también llamada función de pérdida o función objetivo) porque el modelo tiene un objetivo. Este objetivo podría ser clasificar los datos en diferentes categorías (por ejemplo, imágenes de perros y gatos) o predecir la precio esperado de una acción en un futuro próximo. Cuando alguien dice que está trabajando con un algoritmo de aprendizaje automático, puede llegar a la esencia de su valor preguntando: ¿cuál es la función objetivo?
¿Cómo minimizamos el error?
Podemos comparar la predicción del modelo con el valor real del terreno y ajustar los parámetros del modelo para que la próxima vez el error entre estos dos valores sea menor. Este proceso se repite millones de veces hasta que los parámetros del modelo que determinan las predicciones son tan buenos que la diferencia entre las predicciones del modelo y las etiquetas de verdad del terreno es lo más pequeña posible.
En resumen, los modelos de aprendizaje automático son algoritmos de optimización. Si los ajusta correctamente, minimizan el error adivinando y adivinando y adivinando nuevamente.
Aprendizaje profundo: la próxima gran novedad
A diferencia del aprendizaje automático, el aprendizaje profundo es un subcampo joven de la inteligencia artificial basada en redes neuronales artificiales.
Dado que los algoritmos de aprendizaje profundo también requieren datos para aprender y resolver problemas, también podemos llamarlo un subcampo del aprendizaje automático. Los términos aprendizaje automático y aprendizaje profundo a menudo se tratan como sinónimos. Sin embargo, estos sistemas tienen diferentes capacidades.
El aprendizaje profundo utiliza una estructura de algoritmos de varias capas llamada red neuronal.
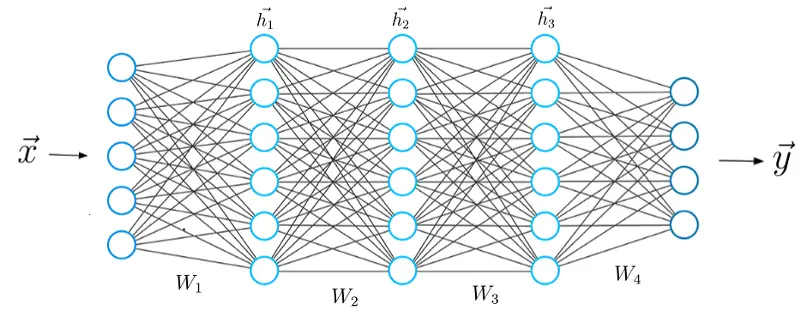
Las redes neuronales artificiales tienen capacidades únicas que permiten modelos de aprendizaje profundo para resolver tareas que los modelos de aprendizaje automático nunca podrían resolver.
Todos los avances recientes en inteligencia se deben al aprendizaje profundo. Sin el aprendizaje profundo no tendríamos coches autónomos, chatbots o asistentes personales como Alexa y Siri. Google Translate seguiría siendo primitivo y Netflix no tendría idea de qué películas o series de televisión sugerir.
Incluso podemos llegar a decir que la nueva revolución industrial está impulsada por redes neuronales artificiales y aprendizaje profundo. Este es el mejor y más cercano enfoque a la verdadera inteligencia artificial que tenemos hasta ahora porque el aprendizaje profundo tiene dos ventajas principales sobre el aprendizaje automático.
¿Por qué el aprendizaje profundo es mejor que el aprendizaje automático?
Sin extracción de características
La primera ventaja del aprendizaje profundo sobre el aprendizaje automático es la redundancia de la extracción de características.
Mucho antes de que usáramos el aprendizaje profundo, los métodos tradicionales de aprendizaje automático (árboles de decisión, SVM, clasificador Naïve Bayes y regresión logística) eran los más populares. Estos también se conocen como algoritmos planos. En este contexto, «plano» significa que estos algoritmos normalmente no se pueden aplicar directamente a datos sin procesar (como .csv, imágenes, texto, etc.). En su lugar, necesitamos un paso de preprocesamiento llamado extracción de características.
En la extracción de características, proporcionamos una representación abstracta de los datos sin procesar que los algoritmos clásicos de aprendizaje automático pueden usar para realizar una tarea (es decir, la clasificación de los datos en varias categorías o clases). La extracción de características suele ser bastante complicada y requiere un conocimiento detallado del dominio del problema. Este paso debe adaptarse, probarse y perfeccionarse en varias iteraciones para obtener resultados óptimos. Los modelos de aprendizaje profundo no necesitan extracción de características.
Cuando se trata de modelos de aprendizaje profundo, tenemos redes neuronales artificiales, que no requieren extracción de características. Las capas pueden aprender una representación implícita de los datos sin procesar por sí mismas.
Un modelo de aprendizaje profundo produce una representación abstracta y comprimida de los datos sin procesar en varias capas de una red neuronal artificial. Luego usamos una representación comprimida de los datos de entrada para producir el resultado. El resultado puede ser, por ejemplo, la clasificación de los datos de entrada en diferentes clases.
Durante el proceso de entrenamiento, la red neuronal optimiza este paso para obtener la mejor representación abstracta posible de los datos de entrada. Los modelos de aprendizaje profundo requieren poco o ningún esfuerzo manual para realizar y optimizar el proceso de extracción de características. En otras palabras, la extracción de características está integrada en el proceso que tiene lugar dentro de una red neuronal artificial sin intervención humana.
Si desea utilizar un modelo de aprendizaje automático para determinar si una imagen en particular muestra un automóvil o no, los humanos primero debemos identificar las características únicas de un automóvil (forma, tamaño, ventanas, ruedas, etc.), extraer estas características y déselos al algoritmo como datos de entrada. El algoritmo de aprendizaje automático luego realizaría una clasificación de la imagen. Es decir, en el aprendizaje automático, un programador debe intervenir directamente en el proceso de clasificación.
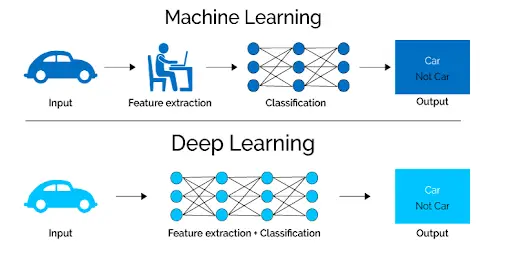
Esto se aplica a todas las demás tareas que realice con las redes neuronales. Entregue los datos sin procesar a la red neuronal y deje que el modelo haga el resto.
La era del Big Data
La otra gran ventaja del aprendizaje profundo, y una parte clave para comprender por qué se está volviendo tan popular, es que funciona con cantidades masivas de datos. La era de la tecnología de big data brindará una gran cantidad de oportunidades para nuevas innovaciones en el aprendizaje profundo.
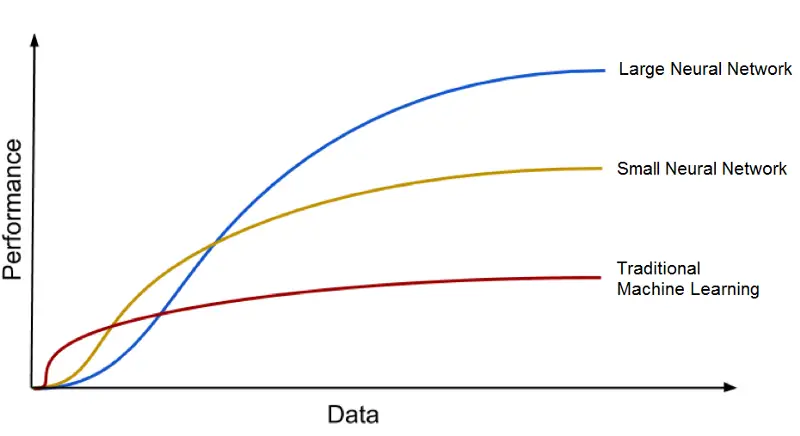
Los modelos de aprendizaje profundo tienden a aumentar su precisión con la creciente cantidad de datos de entrenamiento, mientras que los modelos tradicionales de aprendizaje automático como SVM y el clasificador Naïve Bayes dejan de mejorar después de un punto de saturación.
Los modelos de aprendizaje profundo escalan mejor con una mayor cantidad de datos. Parafraseando a Andrew Ng, el científico jefe del principal motor de búsqueda de China, Baidu, cofundador de Coursera y uno de los líderes del Google Brain Project, si un algoritmo de aprendizaje profundo es un motor cohete, los datos son el combustible.
Este artículo se publicó originalmente en Towards Data Science.