
Título: Marginación sólida de los efectos bariónicos para la inferencia cosmológica a nivel de campo
Autores: Francisco Villaescusa-Navarro, Shy Genel, Daniel Anglés-Alcázar, David N. Spergel, Yin Li, Benjamin Wandelt, Leander Thiele, Andrina Nicola, Jose Manuel Zorrilla Matilla, Helen Shao, Sultan Hassan, Desika Narayanan, Romeel Dave, Mark Vogelsberger
Institución del primer autor: Departamento de Ciencias Astrofísicas, Universidad de Princeton, Peyton Hall, Princeton NJ 08544, EE. UU.
Estado: Preimpresión en arXiv
En un momento u otro, estoy seguro de que todos nos hemos preguntado durante una conferencia: «¿Usaré esto alguna vez en la vida real?» Sin duda, esta es una pregunta que vale la pena considerar, pero a menudo se reemplaza por una pregunta más urgente: «¿Estará en la prueba?»
El artículo de hoy toma este diálogo interno clásico y agrega un giro: el estudiante no es una persona como tú o como yo, sino más bien un algoritmo de aprendizaje automático (una red neuronal convolucional [CNN]) entrenados en simulaciones cosmológicas. Los autores quieren permitir que la CNN estudie algunas simulaciones y luego le presente una pregunta de un tipo que nunca antes había visto en una prueba. Si la pregunta es correcta, esto es una indicación de robustez del modelo. ¡Desvelaremos por qué la robustez es algo que queremos en un modelo cosmológico en el bocado de hoy!
El cielo es el límite
¿Cuánta información cosmológica hay en el cielo? Si pudiéramos modelar todo el cielo a la vez, podríamos avanzar en esta cuestión. Esta es la idea detrás de la “inferencia a nivel de campo”: queremos tomar un mapa (2D) del cielo y compararlo directamente píxel por píxel con un modelo que asigna valores a estos píxeles. Este método potencialmente accede a más información física que las habituales «estadísticas de resumen» utilizadas en cosmología que se calculan a partir de mapas del cielo (es decir, el espectro de potencia o la función de correlación).
Una forma de generar un modelo para estos mapas es con simulaciones, pero ejecutar una simulación para cada elección de parámetros cosmológicos no es factible computacionalmente, especialmente para simulaciones que emplean física hidrodinámica detallada (como las del artículo de hoy). Una salida a este problema es introducir el concepto de “modelos sustitutos” que se aproximan a los modelos simulados (físicos) a una fracción del costo total después de que se entrenan. Un ejemplo de modelos sustitutos son las redes neuronales. Las redes neuronales se entrenan en un conjunto de simulaciones de entrada y se prueban en qué tan bien han aprendido el material presentándoles datos invisibles.
Al ser estudiantes de una sola vez, todos estamos muy familiarizados con esta idea. También estamos familiarizados con la idea de que las preguntas muy similares a las tareas que aparecen en el examen son fáciles en comparación con las preguntas sobre el material de una manera que no hemos visto antes. Pero si podemos responder al último tipo de pregunta, es una señal de que estamos en camino de dominar el material.
Esto corresponde aproximadamente a la idea de robusto Modelado: si se presenta una red neuronal con «datos de prueba» invisibles que se generan a partir de una simulación con una física general diferente, pero que codifica la misma física cosmológica, sería ideal que la red pudiera encontrar la respuesta correcta (la física cosmológica). en esta forma desconocida de hacer la pregunta.
La robustez es muy deseable en un modelo cosmológico porque los cosmólogos no están seguros de lo que sucede físicamente a pequeña escala, particularmente debido a los “efectos bariónicos” como la retroalimentación de las supernovas y los núcleos galácticos activos. Esta es exactamente la idea detrás del artículo de hoy, ¡pero para realizar esta capacitación se requieren muchas simulaciones!
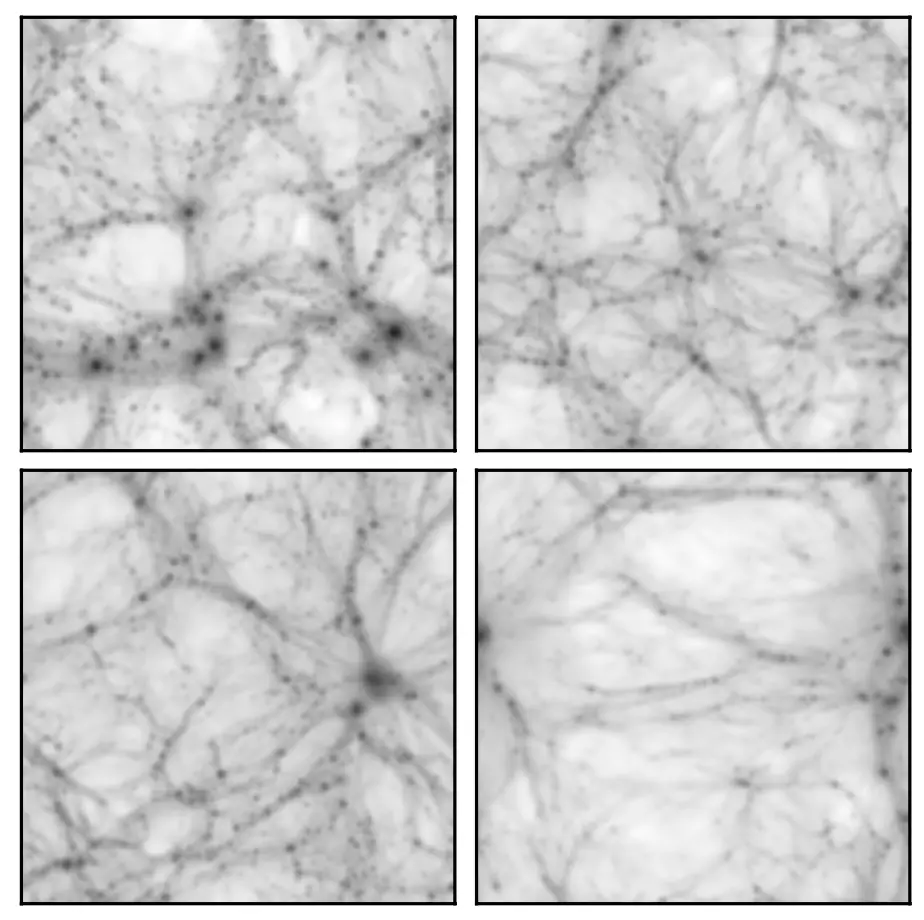
Figura 1: Mapas de masa total proyectada de dos submodelos de las simulaciones CAMELS: IllustrisTNG (arriba) y SIMBA (abajo). La longitud del lado de la caja es de 25 Mpc / h. Figura 1 del artículo de hoy.
Tiempo de estudio: ensillar algunos CAMELS
Los datos de entrenamiento y prueba utilizados en el artículo de hoy provienen del conjunto de simulaciones CAMELS: simulaciones cosmológicas que incluyen los efectos de los procesos hidrodinámicos y astrofísicos. En particular, las simulaciones CAMELS incluyen dos opciones de modelado astrofísico: utilizando el modelo de las simulaciones IllustrisTNG o el modelo de las simulaciones SIMBA. En particular, los autores generan 30.000 mapas 2D astronómicos de la masa total proyectada a partir de las simulaciones CAMELS para entrenar y probar el modelo de red neuronal (NN) (ver Figura 1). La forma en que los autores prueban la robustez es entrenar un modelo de red neuronal en mapas generados a partir de una clase de simulaciones (por ejemplo, IllustrisTNG) y luego probar el modelo tratando de inferir el valor de algunos parámetros cosmológicos de un mapa generado a partir del otro (por ejemplo, SIMBA). Los autores conocen la respuesta de antemano, por lo que la idea es que uno debe tener confianza en el modelo si obtiene la respuesta correcta en los mapas de simulación invisibles, es decir, el modelo es robusto.
La Figura 2 llega directamente a esta idea: aquí el modelo NN intenta aprender el parámetro cosmológico que describe la sobredensidad de la materia, Ωmetro. La figura muestra que con un pequeño porcentaje de dispersión, encuentran que este suele ser el caso. De particular interés son los puntos azul y verde, que son las pruebas «invisibles» destinadas a demostrar la solidez del modelo. La precisión de la simulación de prueba invisible es comparable a la precisión de la misma simulación, lo que parece indicar que el modelo está aprendiendo la física cosmológica común de una manera que es en su mayoría robusta a la elección del modelo astrofísico.
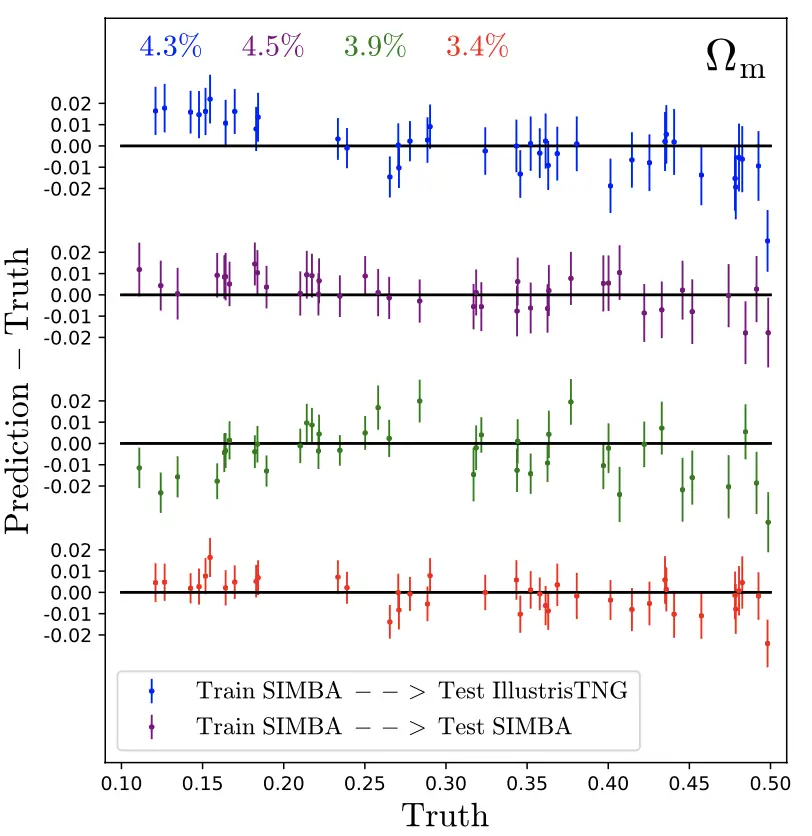
Figura 2: La diferencia en los valores reales y predichos por NN de los parámetros cosmológicos en el conjunto de prueba de mapas de masas simulados. El eje horizontal muestra diferentes valores del parámetro de sobredensidad de materia Ωmetro utilizado para la prueba. Los puntos azules muestran predicciones del modelo entrenado en SIMBA y probado en TNG (los puntos verdes muestran lo contrario), mientras que el rojo y el violeta muestran las predicciones del modelo cuando se prueban en mapas generados a partir de simulaciones con los mismos modelos astrofísicos subyacentes: rojo para TNG y morado para SIMBA. Adaptado de la Figura 2 del artículo de hoy.
Una lección del artículo de hoy es que el uso del aprendizaje automático para modelar directamente el mapa tiene el potencial de ser un método poderoso para restringir los parámetros cosmológicos de la estructura a gran escala. Fundamentalmente, los autores argumentan que la prueba realizada en el artículo demuestra que su modelo NN es robusto a los cambios en el modelado astrofísico. Si bien los mapas de masas proyectadas que se utilizan en el artículo de hoy no son realmente observables, el método que se describe aquí puede aplicarse a cantidades relacionadas en el contexto de observaciones de lentes débiles en el futuro.
Editado por: Graham Doskoch
Imagen destacada: equipo CAMELS
Sobre Jamie Sullivan
Soy un doctorado en astrofísica de tercer año. estudiante de UC Berkeley y parte del Berkeley Center for Cosmological Physics. Mi investigación actual se centra en medir y modelar estructuras a gran escala para restringir los parámetros cosmológicos. Completé mi licenciatura en UT Austin y soy originario del área de Washington DC.