
Vea todas las sesiones bajo demanda de la Cumbre de Seguridad Inteligente aquí.
No hay cura para el Alzheimer. Pero, ¿y si pudiéramos encontrar una manera de detectarlo temprano? La pregunta intrigó a los científicos de Imagia, quienes luego utilizaron el aprendizaje automático automático de Google (AutoML) para reducir el tiempo de procesamiento de la prueba de 16 horas a una hora. PayPal experimentó beneficios similares. En 2018, con AutoML de H2O, PayPal aumentó la precisión de su modelo de detección de fraude en un 6 % y aceleró seis veces el proceso de desarrollo del modelo.
Historias de éxito como estas han inspirado a alrededor del 61 % de los responsables de la toma de decisiones en empresas que utilizan inteligencia artificial (IA) para adoptar AutoML. Su aceptación solo aumentará, ya que puede mitigar, en gran medida, los problemas causados por la falta de científicos de datos. Además, la capacidad de AutoML para mejorar la escalabilidad y aumentar la productividad seguramente atraerá a los clientes.
Pero, ¿significa esto que la adopción de AutoML se ha convertido en una obligación? Bueno, ese es un enigma al que se enfrentan la mayoría de las empresas en este momento, y examinar casos de la vida real podría ser una solución.
Como ingeniero de software sénior, he trabajado con varias empresas emergentes en las que la IA desempeñó un papel fundamental. He visto los pros y los contras y el impacto comercial. Pero antes de entrar en los casos de uso, primero establezcamos qué es AutoML, su estado actual y lo que puede y no puede hacer.
Evento
Cumbre de seguridad inteligente bajo demanda
Conozca el papel fundamental de la IA y el ML en la ciberseguridad y los estudios de casos específicos de la industria. Mira las sesiones a pedido hoy.
Mira aquí
¿Qué es AutoML?
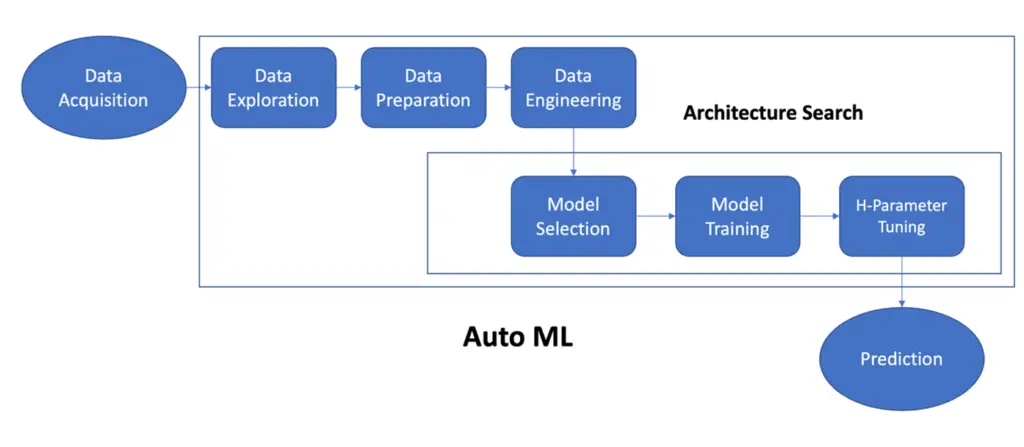
AutoML (aprendizaje automático automatizado) es la capacidad de un sistema para decidir automáticamente el modelo correcto y establecer parámetros para entregar el mejor modelo posible. Me centraré solo en las redes neuronales profundas en este artículo.
En las redes neuronales profundas, encontrar la arquitectura correcta siempre es un gran desafío. Por arquitectura, me refiero a los bloques de construcción básicos (por ejemplo, para el reconocimiento de imágenes, los bloques de construcción básicos serían una agrupación máxima de 3X3, una convolución de 3X1, etc.) y la interconexión entre ellos para múltiples capas ocultas.
La búsqueda de arquitectura neuronal (NAS) es una técnica para automatizar el diseño de redes neuronales profundas. Se utiliza para diseñar redes que están a la par o pueden superar las arquitecturas diseñadas a mano. Pero necesitamos capacitar a un gran número de redes candidatas como parte del proceso de búsqueda para encontrar la arquitectura adecuada, lo cual requiere mucho tiempo.
El estado actual de las plataformas disponibles
NAS juega un papel fundamental en la formación del marco AutoML para Amazon Web Services (AWS) y Google Cloud Platform (GCP). Pero AutoML aún se encuentra en la etapa inicial y estas plataformas están evolucionando. Hablemos de estos dos famosos marcos de AutoML.
AutoML de GCP
GCP AutoML tiene NAS y transferencia de aprendizaje en su núcleo. NAS busca la arquitectura óptima de un grupo de arquitecturas en función de los resultados de capacitación anteriores. Inicialmente, los algoritmos de aprendizaje por refuerzo se utilizaron para la búsqueda de arquitectura.
Sin embargo, estos algoritmos tienden a ser computacionalmente costosos debido al gran espacio de búsqueda. Recientemente, ha habido un cambio de paradigma hacia el desarrollo de métodos basados en gradientes que han mostrado resultados prometedores. Pero lo que sucede dentro de GCP AutoML aún no está tan claro y es más una solución de caja negra.
Piloto automático de AWS
El concepto principal de AWS Autopilot es proporcionar una solución AutoML configurable. Se exponen todos los detalles sobre el ciclo de aprendizaje automático, desde la transformación de datos hasta el entrenamiento de modelos y el ajuste de hiperparámetros. A diferencia de GCP AutoML, AWS Autopilot es una solución de caja blanca.
AWS Autopilot utiliza diferentes estrategias para canalizaciones de datos y ML (aprendizaje automático). Algunas de estas estrategias se basan en las declaraciones if-else sugeridas por expertos en dominios; otras estrategias dependen de elegir los hiperparámetros correctos (es decir, tasa de aprendizaje, parámetro de ajuste excesivo, tamaño de incrustación) para la canalización.
Qué puede hacer AutoML y qué no puede hacer
A veces, la gente dice que AutoML es el santo grial de AI/ML, una opinión que no comparto. Así que continuemos:
| Que puede hacer | Lo que no puede hacer | |
| Transformación de datos | Se encarga del preprocesamiento y transformación de datos. Identifica variables numéricas y categóricas y puede manejarlas. | Puede cometer errores, como identificar incorrectamente características numéricas en datos con baja cardinalidad como una característica categórica. No se pueden volcar los datos y asumir que funcionará sin contratiempos. |
| Extracción de características | Extrae características hasta cierto punto. | En los modelos dependientes del dominio, es necesaria la extracción de características. Dominar el conocimiento del dominio sigue siendo un problema. |
| Modelado y Tuning | Identifica los mejores hiperparámetros. Puede hacer una búsqueda de la mejor arquitectura. | AutoML no puede funcionar con una pequeña cantidad de datos, ya que existe una restricción de puntos de datos mínimos. Es excesivo para problemas simples en los que usamos regresión lineal o algunos modelos básicos. Es una tarea que requiere mucho tiempo y puede generar altos costos tanto para problemas simples como para problemas con una gran cantidad de datos. |
Permítanme compartir algunos conocimientos experimentales, con ejemplos de la vida real, para profundizar en dónde AutoML encajaba bien y dónde no funcionaba.
Caso de uso 1: medir el desempeño de un distribuidor en la industria automotriz
Tuvimos que generar una métrica para evaluar el desempeño de un distribuidor con gigabytes de datos históricos, como ventas anteriores, datos de censos, datos religiosos y datos geográficos. Utilizamos AutoML y obtuvimos un rendimiento comparable al humano.
Sin embargo, necesitábamos un científico de datos para realizar el preprocesamiento de datos, la ingeniería de funciones y la transformación. Le tomó mucho trabajo a AutoML descubrir cuáles eran los datos importantes en nuestras columnas de datos, ya que había miles de columnas. Incluso un experimento podría haber incurrido en enormes costos y desperdiciado un tiempo precioso.
Caso de uso 2: predicción de alquiler de propiedades
Tuvimos que desarrollar una herramienta para predecir el alquiler de la propiedad, pero AutoML no funcionó bien porque el mercado inmobiliario tiene mucha información localizada (por estado). De hecho, nuestros intentos fallaron con un modelo por región ya que no tenía suficientes datos (menos de 500 puntos de datos) para aprender arquitectura. Un tipo de modelo XGBoost simple con funciones reducidas funcionó bien en comparación con AutoML.
En los estados donde los datos eran lo suficientemente buenos para AutoML, a nuestro modelo de predicción le fue mejor que a la solución interna.
Caso de uso 3: predicción de rating de TV
En el caso de la predicción del rating televisivo, sucedió lo mismo. AutoML no pudo capturar el comportamiento basado en la franja horaria en múltiples canales. Por ejemplo, NICK es para niños; la mayoría de los niños ven programas por la tarde, y los adultos ven principalmente MTV y tienen una audiencia máxima por la noche. Este es solo un patrón simple, pero AutoML no pudo capturar múltiples patrones de múltiples categorías en un modelo.
¿AutoML realmente reemplazará a DS?
Desde mi experiencia en el campo, diría “No”. AutoML no puede reemplazar directamente a los científicos de datos. Pero puede ser una herramienta útil para los científicos de datos.
Dónde deberíamos estar usando AutoML
La probabilidad de que AutoML funcione bien sin ninguna interferencia humana es mayor en escenarios donde los problemas son familiares en la literatura. En casos como la detección de objetos para objetos genéricos o la clasificación de imágenes, puede usar AutoML, ya que ya están ajustados con una gran cantidad de datos. También puede ayudarlo a desarrollar pruebas de concepto rápidas, que pueden o no brindar un rendimiento razonable.
Dónde no deberíamos estar usando AutoML
A veces, necesitamos ingeniería de características simple con un modelo de regresión lineal simple para proyectos de ML del mundo real. AutoML podría incurrir en un mayor costo en esos casos, ya que no es compatible con la ingeniería de características. Internamente, utiliza una red neuronal profunda, lo que significa que hay algo de ingeniería de funciones, pero para eso, requerirá una gran cantidad de datos. Además, es caro si lo comparas con el enfoque básico. Y el rendimiento del modelo seleccionado por AutoML necesitará mejorar.
Los escenarios en los que el problema es muy específico del dominio y requiere algún conocimiento del dominio también pueden fallar con AutoML. Estos son los escenarios en los que deberíamos usar AutoML y aquellos en los que deberíamos evitarlo:
| AutoML | Modelo personalizado | |
| Seguridad y privacidad | Tiene un problema de seguridad porque tenemos que subir datos a la nube. | Esto es seguro. También podemos entrenar modelos personalizados en nuestras máquinas personales. |
| Problema específico del dominio | AutoML no funciona para problemas específicos. | Podemos entrenar el modelo para problemas específicos de dominio. |
| Restricción presupuestaria | AutoML es costoso en muchos casos como la regresión lineal. | Su presupuesto depende de los requerimientos. |
| Menos datos | AutoML tiene un requisito mínimo de datos. | Puede afectar el rendimiento, pero no existe tal restricción. |
| Hora de comprar | Usando AutoML podemos completar la tarea rápidamente. | Tenemos que configurar una canalización en este caso, lo que requiere mucho tiempo. |
| Problema estándar | En el caso de problemas estándar, AutoML puede completarse rápidamente. | Los modelos personalizados tardarán más en encontrar la arquitectura óptima. |
| Ingeniería de características | AutoML no puede ayudar con la ingeniería de características donde necesitamos conocimiento del dominio para crearlas. | Debemos trabajar por separado en la ingeniería de características; entonces podemos alimentar a AutoML. |
| Solución | Dará soluciones a partir de enfoques ya conocidos para problemas existentes. | Los científicos de datos pueden probar enfoques novedosos que serán muy específicos para la declaración del problema. |
Conclusión
AutoML no es inteligencia general artificial (AGI), lo que significa que no puede definir las declaraciones del problema y resolverlas automáticamente. Sin embargo, puede resolver problemas predefinidos si le damos datos y características relevantes.
El uso de AutoML implica un compromiso entre la generalización de un problema y el desempeño de un problema específico. Si AutoML está generalizando su solución, entonces debe comprometer el rendimiento de un problema específico (porque la arquitectura de AutoML no está ajustada para eso). Y la solución general no puede ayudar con problemas de dominio específico donde necesitamos un enfoque novedoso para resolverlos.
Alakh Sharma es científico de datos en Talentica Software.
Tomadores de decisiones de datos
¡Bienvenido a la comunidad VentureBeat!
DataDecisionMakers es donde los expertos, incluidos los técnicos que trabajan con datos, pueden compartir información e innovación relacionadas con los datos.
Si desea leer sobre ideas de vanguardia e información actualizada, mejores prácticas y el futuro de los datos y la tecnología de datos, únase a nosotros en DataDecisionMakers.
¡Incluso podría considerar contribuir con un artículo propio!
Leer más de DataDecisionMakers
