


Crédito: Lisa Sheehan
Desde 2012, en el campo de la inteligencia artificial (IA) se han registrado notables progresos en una amplia gama de capacidades, entre ellas el reconocimiento de objetos, el juego, el reconocimiento del habla y la traducción automática.43 Gran parte de este progreso se ha logrado mediante modelos de aprendizaje profundo cada vez más grandes e intensivos en computación.aFigura 1, reproducida de Amodei et al..,2 …que los costos de entrenamiento aumentan con el tiempo para los modelos de aprendizaje profundo de última generación, comenzando con AlexNet en 2012…24 a Alfa Cero en 2017.45 El gráfico muestra un aumento general de 300.000x, con el costo de entrenamiento duplicándose cada pocos meses. Se puede observar una tendencia aún más aguda en los enfoques de incorporación de palabras de la PNL mirando a ELMo34 seguido por el BERT,8 openGPT-2,35 XLNet,56 Megatron-LM,42 T5,36 y GPT-3.4 Un papel importante47 ha estimado la huella de carbono de varios modelos de PNL y ha argumentado que esta tendencia es a la vez poco amistosa con el medio ambiente y prohibitivamente costosa, lo que aumenta los obstáculos a la participación en las investigaciones sobre PNL. Nos referimos a trabajos como La IA roja.
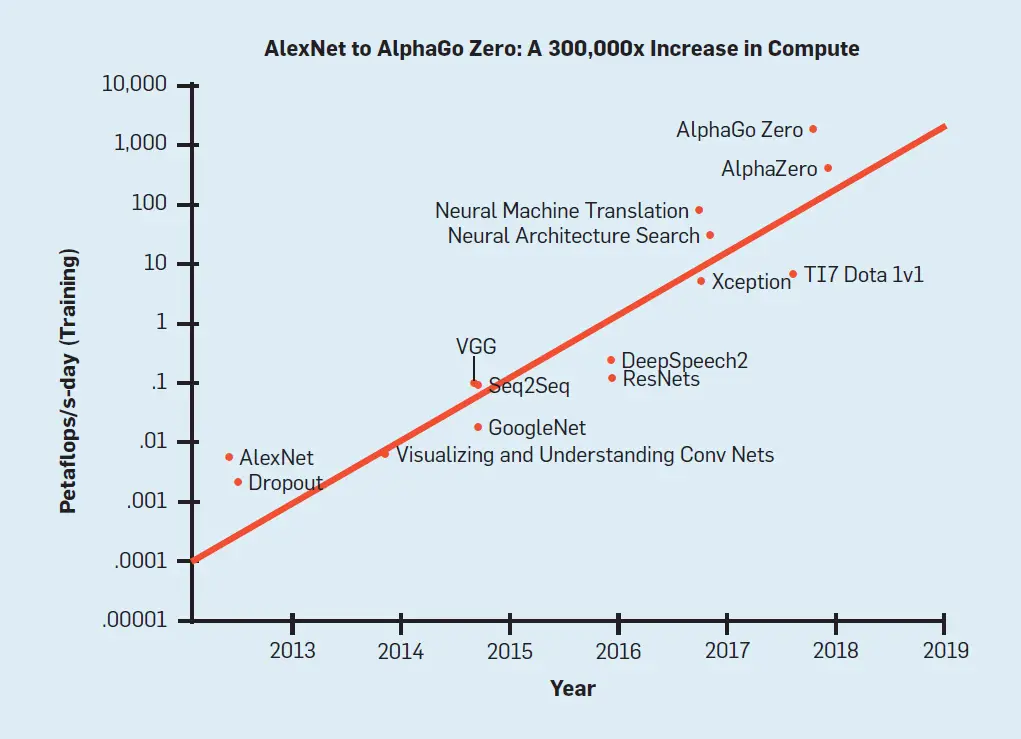
Figura 1. La cantidad de computación usada para entrenar modelos de aprendizaje profundo ha aumentado 300.000 veces en seis años. Figura tomada de Amodei et al.2
Volver al principio
Ideas clave

Esta tendencia está impulsada por el fuerte enfoque de la comunidad de la IA en la obtención de resultados «de última generación»,b como lo ejemplifica la popularidad de las tablas de clasificación,53,54 que suelen informar sobre la exactitud (u otras medidas similares) pero omiten toda mención de costo o eficiencia (véase, por ejemplo, leaderboards.allenai.org).c A pesar de los claros beneficios de mejorar la precisión del modelo, el enfoque en esta métrica única ignora el costo económico, ambiental y social de alcanzar los resultados reportados.
Abogamos por el aumento de la actividad de investigación en IA verde-Investigación de la IA que es más amigable con el medio ambiente e inclusiva. Hacemos hincapié en que La IA roja La investigación ha estado dando valiosas contribuciones científicas al campo, pero ha sido demasiado dominante. Queremos cambiar el equilibrio hacia la IA verde para asegurar que cualquier estudiante inspirado con una computadora portátil tenga la oportunidad de escribir trabajos de alta calidad que puedan ser aceptados en las principales conferencias de investigación. Específicamente, proponemos hacer de la eficiencia un criterio de evaluación más común para los trabajos de IA, junto con la precisión y las medidas relacionadas.
La investigación de la IA puede ser costosa desde el punto de vista informático de varias maneras, pero cada una de ellas ofrece oportunidades de mejoras eficientes; por ejemplo, los trabajos pueden trazar el rendimiento en función del tamaño del conjunto de la capacitación, lo que permite que en el futuro se pueda comparar el rendimiento incluso con presupuestos de capacitación reducidos. Informar sobre el precio computacional del desarrollo, la capacitación y la ejecución de los modelos es una clave IA verde práctica (véase la ecuación 1). Además de proporcionar transparencia, las etiquetas de los precios son puntos de referencia que otros investigadores podrían mejorar.
Nuestro análisis empírico en la figura 2 sugiere que la comunidad de investigación de la IA ha prestado relativamente poca atención a la eficiencia computacional. De hecho, como ilustra la Figura 1, el costo computacional de la investigación de alto presupuesto está aumentando exponencialmente, a un ritmo que excede por mucho la Ley de Moore.33La IA roja está en alza a pesar de los conocidos rendimientos decrecientes del aumento de los costos (por ejemplo, la figura 3).
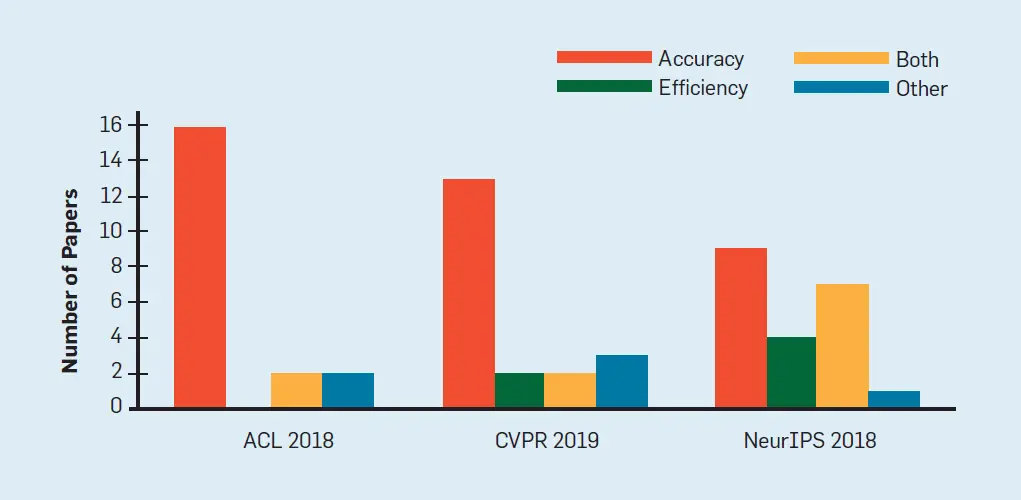
Figura 2. Los documentos de la IA tienden a apuntar a la precisión más que a la eficiencia. La figura muestra la proporción de trabajos que apuntan a la exactitud, la eficiencia, ambos u otros a partir de una muestra aleatoria de 60 trabajos de las principales conferencias de IA.
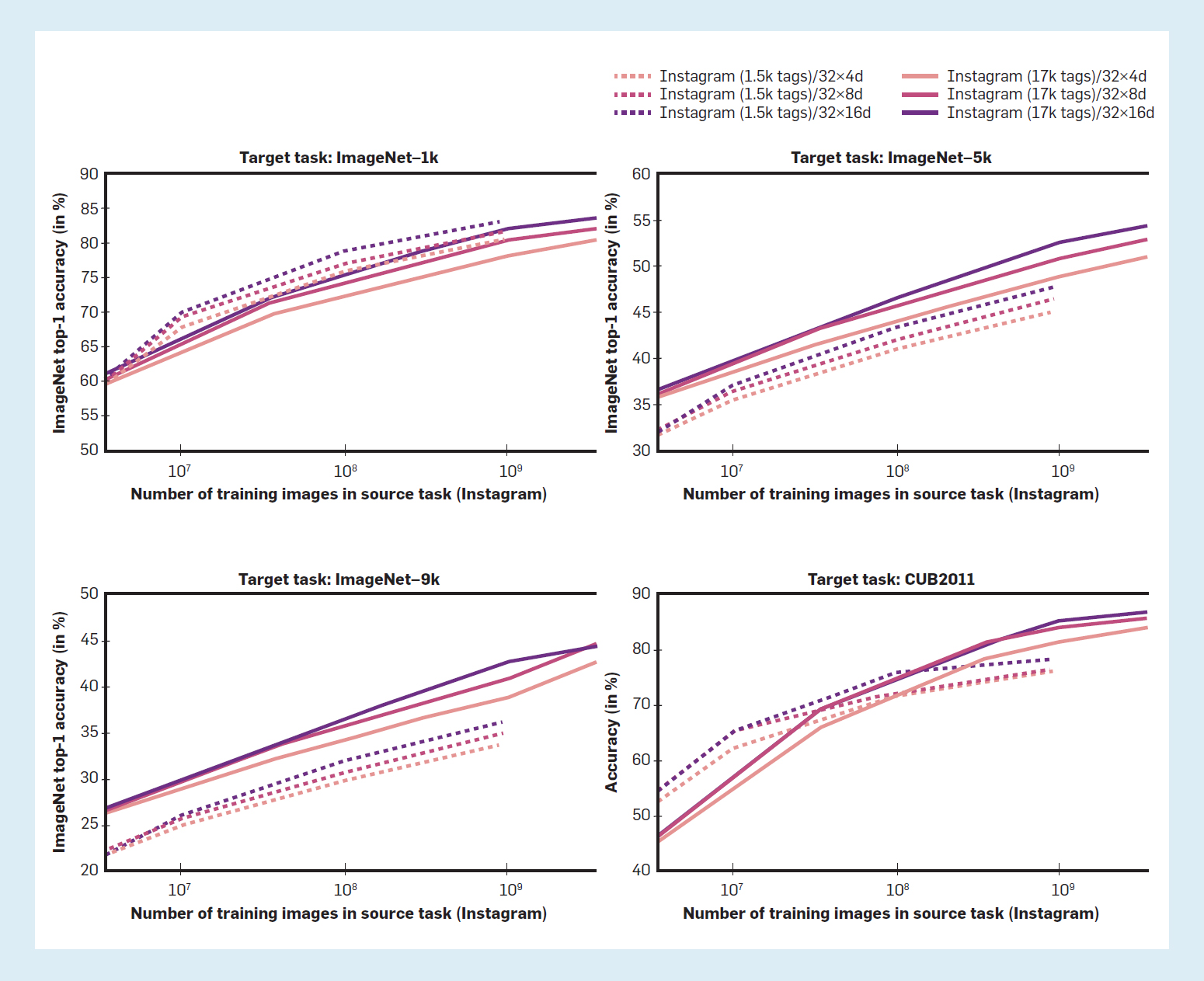
Figura 3. Disminución de los rendimientos de la formación en más datos: la precisión de la detección de objetos aumenta linealmente a medida que el número de ejemplos de formación aumenta exponencialmente.30
En este artículo se identifican los factores clave que contribuyen a La IA roja y aboga por la introducción de una métrica de eficiencia simple y fácil de calcular que podría ayudar a que algunas investigaciones de IA sean más ecológicas, más inclusivas y quizás más plausibles desde el punto de vista cognitivo. IA verde forma parte de un interés más amplio, de larga data, en la investigación científica respetuosa con el medio ambiente (por ejemplo, véase la Revista Química Verde). La informática, en particular, tiene una larga historia de investigación de la informática sostenible y de eficiencia energética (por ejemplo, véase la Revista Sustainable Computing: Informática y Sistemas).
En este artículo, analizamos las prácticas que mueven la investigación de aprendizaje profundo en el ámbito de La IA roja. Luego discutimos nuestras propuestas para IA verde y considerar el trabajo relacionado, y las direcciones para futuras investigaciones.
Volver al principio
La IA roja
La IA roja se refiere a la investigación de la IA que trata de mejorar la precisión (o las medidas relacionadas) mediante el uso de una enorme potencia de cálculo, sin tener en cuenta los resultados más sólidos que «compran» por su costo. Sin embargo, desde hace tiempo se entiende que la relación entre el rendimiento del modelo y la complejidad del mismo (medida como el número de parámetros o el tiempo de inferencia) es, en el mejor de los casos, logarítmica; para obtener una ganancia lineal en el rendimiento, se requiere un modelo exponencialmente mayor.20 Existen tendencias similares al aumentar la cantidad de datos de capacitación14,48 y el número de experimentos.9,10 En cada uno de estos casos, la disminución de los rendimientos se produce con un mayor costo de computación.
Esta sección analiza los factores que contribuyen a La IA roja y muestra cómo está resultando en retornos decrecientes a lo largo del tiempo (ver Figura 3). Observamos que La IA roja El trabajo es valioso, y de hecho, gran parte de él contribuye a lo que sabemos al empujar los límites de la IA. Nuestra exposición aquí tiene como objetivo resaltar las áreas donde el gasto computacional es alto, y presentar cada una de ellas como una oportunidad para desarrollar técnicas más eficientes.
Para demostrar la prevalencia de La IA roja…muestreamos al azar 60 trabajos de las principales conferencias de IA (ACL, NeurIPS y CVPR).d En cada documento se señaló si los autores afirman que su principal contribución es: a) una mejora de la precisión o alguna medida conexa, b) una mejora de la eficiencia, c) ambas, o d) otra. Como se muestra en la Figura 2, en todas las conferencias que consideramos, una gran mayoría de los trabajos se centran en la exactitud (90% de los trabajos de ACL, 80% de los trabajos de NeurIPS y 75% de los trabajos de CVPR). Además, para ambas conferencias empíricas de IA (ACL y CVPR) sólo una pequeña parte (10% y 20% respectivamente) argumentan un nuevo resultado de eficiencia.e Esto pone de relieve el enfoque de la comunidad de la IA en medidas de rendimiento como la precisión, a expensas de medidas de eficiencia como la velocidad o el tamaño del modelo. En este artículo, argumentamos que se debe dar un mayor peso a este último.
Para entender mejor las diferentes formas en que la investigación de la IA puede ser roja, considere un resultado de IA reportado en un documento científico. Este resultado caracteriza típicamente un modelo entrenado en un conjunto de datos de entrenamiento y evaluado en un conjunto de datos de prueba, y el proceso de desarrollo de ese modelo a menudo implica múltiples experimentos para afinar sus hiperparámetros. Así pues, consideramos tres dimensiones que captan gran parte del costo computacional de la obtención de ese resultado: el costo de ejecutar el modelo en un solo (E)xample (ya sea durante el entrenamiento o en el momento de la inferencia); el tamaño del entrenamiento (D)ataset, que controla el número de veces que se ejecuta el modelo durante el entrenamiento, y el número de (H) experimentos de parámetros, que controla cuántas veces se entrena el modelo durante su desarrollo. El costo total de producir un (R) el resultado del aprendizaje de la máquina aumenta linealmente con cada una de estas cantidades. Este costo puede estimarse de la siguiente manera:

La ecuación 1 es una simplificación (por ejemplo, diferentes asignaciones de hiperparámetros pueden dar lugar a diferentes costos de procesamiento de un solo ejemplo). También ignora otros factores como el número de épocas de entrenamiento o el aumento de los datos. No obstante, ilustra tres cantidades que son cada una un factor importante en el costo total de la generación de un resultado. A continuación, se considera cada cantidad por separado.
Procesamiento costoso de un ejemplo. Nos centramos en los modelos neuronales, donde es común que cada paso de entrenamiento requiera inferencia, por lo que discutimos el entrenamiento y el costo de la inferencia juntos como «procesamiento» de un ejemplo (aunque véase la discusión más adelante). En algunos trabajos se han utilizado modelos cada vez más grandes en términos de, por ejemplo, parámetros de modelos, y como resultado, en estos modelos, realizar la inferencia puede requerir mucho cálculo, y entrenamiento aún más. Por ejemplo, el BERT-large de Google8 contiene aproximadamente 350 millones de parámetros. El modelo openGPT2-XL de OpenAI35 contiene 1.500 millones de parámetros. AI2, nuestra organización local, ha liberado a Grover,57 que también contiene 1.500 millones de parámetros. NVIDIA lanzó Megatron-LM,42 que contiene más de 8.000 millones de parámetros. El T5-11B de Google36 contiene 11 mil millones de parámetros. Más recientemente, openAI lanzó openGPT-3,4 que contiene 175 mil millones de parámetros. En la comunidad de la visión por computadora se observa una tendencia similar (Figura 1).
Esos grandes modelos tienen altos costos de procesamiento de cada ejemplo, lo que conlleva grandes gastos de capacitación. BERT-large fue entrenado en 64 chips TPU durante cuatro días a un costo estimado de 7.000 dólares. Grover fue entrenado en 256 chips TPU durante dos semanas, con un costo estimado de 25.000 dólares. XLNet tenía una arquitectura similar a la de BERT-large, pero utilizaba una función objetiva más cara (además de un orden de magnitud más datos), y se entrenó en 512 chips TPU durante dos días y medio, con un costo estimado de más de 60.000 dólares.f Es imposible reproducir los mejores resultados de BERT-large o XLNet usando una sola GPU,g y los modelos como openGPT2 son demasiado grandes para ser utilizados en la producción.h Los modelos especializados pueden tener costes aún más extremos, como el AlphaGo, cuya mejor versión requirió 1.920 CPUs y 280 GPUs para jugar a un solo juego de Go,44 con un costo estimado para reproducir este experimento de 35.000.000 de dólares.i, j
Al examinar las variantes de un solo modelo (por ejemplo, BERT-pequeño y BERT-grande) vemos que los modelos más grandes pueden tener un rendimiento más fuerte, lo cual es una valiosa contribución científica. Sin embargo, esto implica que el costo financiero y ambiental de los modelos de IA cada vez más grandes no disminuirá pronto, ya que el ritmo de crecimiento del modelo excede con mucho el aumento resultante en el rendimiento del mismo.18 Como resultado, se van a necesitar cada vez más recursos para seguir mejorando los modelos de IA simplemente haciéndolos más grandes.
Por último, observamos que en algunos casos el precio de la tramitación de un ejemplo puede ser diferente en el tiempo de formación y de prueba. Por ejemplo, algunos métodos apuntan a una inferencia eficiente al aprender un modelo más pequeño basado en el modelo grande entrenado. Estos modelos a menudo no conducen a una capacitación más eficiente, ya que el costo de E sólo se reduce en el momento de la inferencia. Los modelos utilizados en la producción suelen tener costos computacionales dominados por la inferencia más que por la capacitación, pero en la investigación la capacitación suele ser mucho más frecuente, por lo que abogamos por el estudio de métodos para el procesamiento eficiente de un ejemplo tanto en la capacitación como en la inferencia.
Procesando muchos ejemplos. El aumento de la cantidad de datos de entrenamiento también ha contribuido a los progresos en el rendimiento de la IA. BERT-large tuvo un rendimiento superior en 2018 en muchas tareas de PNL después de entrenar en tres mil millones de piezas de palabras. XLNet superó a BERT después de entrenar con 32.000 millones de palabras, incluyendo parte del Common Crawl; openGPT-2-XL se entrenó con 40.000 millones de palabras; RoBERTa de FAIR28 fue entrenado con 160 GB de texto, aproximadamente 40 mil millones de piezas de palabras, requiriendo alrededor de 25.000 horas de GPU para entrenar. T5-11B36 fue entrenado en 1 billón de fichas, 300 veces más que el BERT-grande. En la visión por computador, los investigadores de Facebook30 preentrenó un modelo de clasificación de imágenes en 3.500 millones de imágenes de Instagram, tres órdenes de magnitud más grande que los conjuntos de datos de imágenes etiquetadas existentes como Open Images.k
El uso de datos masivos crea barreras para que muchos investigadores reproduzcan los resultados de estos modelos, y para entrenar sus propios modelos en la misma configuración (especialmente porque el entrenamiento para múltiples épocas es estándar). Por ejemplo, el Common Crawl de julio de 2019 contiene 242 TB de datos sin comprimir,l así que incluso el almacenamiento de los datos es caro. Finalmente, como en el caso del tamaño del modelo, depender de más datos para mejorar el rendimiento es notoriamente caro debido a los rendimientos decrecientes de añadir más datos.48 Por ejemplo, la figura 3, tomada de Mahajan et al..,30 muestra una relación logarítmica entre la precisión del reconocimiento de objetos de primera clase y el número de ejemplos de entrenamiento.
Un número masivo de experimentos. Algunos proyectos han volcado grandes cantidades de computación en la sintonización de hiperparámetros o en la búsqueda de arquitecturas neuronales, lo cual está fuera del alcance de la mayoría de los investigadores. Por ejemplo, los investigadores de Google59 entrenó a más de 12.800 redes neuronales en su búsqueda de arquitectura neuronal para mejorar el rendimiento en la detección de objetos y el modelado del lenguaje. Con una arquitectura fija, los investigadores de DeepMind31 evaluó 1.500 asignaciones de hiperparámetros para demostrar que un modelo de lenguaje LSTM17 puede alcanzar resultados de perplejidad de última generación. A pesar del valor de este resultado para demostrar que el rendimiento de un LSTM no se estabiliza después de sólo unas pocas pruebas de hiperparámetros, explorar plenamente el potencial de otros modelos competitivos para una comparación justa es prohibitivamente caro.
El valor de aumentar masivamente el número de experimentos no está tan bien estudiado como los dos primeros discutidos anteriormente. De hecho, el número de experimentos realizados durante la construcción del modelo a menudo no se reporta. No obstante, también aquí existen pruebas de una relación logarítmica.9,10
Discusión. El aumento de los costos de los experimentos de IA ofrece una motivación económica natural para desarrollar métodos de IA más eficientes. Podría darse el caso de que en un determinado momento los precios sean demasiado altos, lo que obligaría incluso a los investigadores con grandes presupuestos a desarrollar métodos más eficientes. Nuestro análisis en la figura 2 muestra que actualmente la mayor parte de los esfuerzos se siguen dedicando a la exactitud más que a la eficiencia. Al mismo tiempo, la tecnología de la IA ya es muy costosa de entrenar o ejecutar, lo que limita la capacidad de muchos investigadores para estudiarla, y de los profesionales para adoptarla. En combinación con el precio ambiental de la IA,47 creemos que se debe dedicar más esfuerzo a las soluciones eficientes de la IA.
Queremos reiterar que La IA roja es extremadamente valioso, y de hecho, gran parte de él contribuye a lo que sabemos acerca de empujar los límites de la IA. De hecho, hay un valor en empujar los límites del tamaño del modelo, el tamaño del conjunto de datos y el presupuesto de búsqueda de hiperparámetros.
Además, La IA roja puede brindar oportunidades para la labor futura de promoción de la eficiencia; por ejemplo, la evaluación de un modelo sobre cantidades variables de datos de capacitación brindará la oportunidad de que los futuros investigadores se basen en la labor sin necesidad de un presupuesto lo suficientemente grande para capacitarse en un conjunto de datos masivo. En la actualidad, a pesar de la enorme cantidad de recursos invertidos en los recientes modelos de IA, esa inversión sigue rindiendo frutos en términos de rendimiento en la fase posterior (aunque a un ritmo cada vez más bajo). Encontrar el punto de saturación (si es que existe) es una cuestión importante para el futuro de la IA. Además, La IA roja los costos pueden incluso a veces ser amortizados, porque un La IA roja El módulo de entrenamiento puede ser reutilizado por muchos proyectos de investigación como un componente incorporado, que no requiere de un reentrenamiento.
El objetivo de este artículo es doble: primero, queremos concienciar sobre el coste de La IA roja y alentar a los investigadores que utilizan esos métodos a que adopten medidas para permitir comparaciones más equitativas, como la notificación de las curvas de capacitación. En segundo lugar, queremos alentar a la comunidad de la IA a que reconozca el valor del trabajo de los investigadores que toman un camino diferente, optimizando la eficiencia en lugar de la precisión. A continuación, pasamos a discutir medidas concretas para que la IA sea más ecológica.
Volver al principio
IA verde
El término IA verde se refiere a la investigación de la IA que produce resultados novedosos teniendo en cuenta el costo computacional, fomentando una reducción de los recursos gastados. Mientras que La IA roja ha dado lugar a un rápido aumento de los costos computacionales (y por lo tanto del carbono), IA verde promueve enfoques que tienen compensaciones favorables de rendimiento/eficiencia. Si las medidas de eficiencia son ampliamente aceptadas como importantes métricas de evaluación para la investigación junto con la precisión, entonces los investigadores tendrán la opción de centrarse en la eficiencia de sus modelos con un impacto positivo tanto en la inclusividad como en el medio ambiente. En este documento, examinamos varias medidas de eficiencia que podrían notificarse y optimizarse, y defendemos una medida en particular, la FPO, que argumentamos que debería notificarse cuando se publiquen los resultados de la investigación de la IA.
Algunos proyectos han volcado grandes cantidades de computación en la sintonización de hiperparámetros o en la búsqueda de arquitecturas neuronales, lo cual está fuera del alcance de la mayoría de los investigadores.
Medidas de eficiencia. Para medir la eficiencia, sugerimos que se informe sobre la cantidad de trabajo necesaria para generar un resultado. Específicamente, la cantidad de trabajo requerida para entrenar un modelo, y si es aplicable, la cantidad agregada de trabajo requerida para todos los experimentos de ajuste de hiperparámetros. A medida que el costo de un experimento se descompone en el costo de un procesamiento de un solo ejemplo, el tamaño del conjunto de datos y el número de experimentos (Ecuación 1), la reducción de la cantidad de trabajo en cada uno de estos pasos dará como resultado una IA más verde.
Animamos a los profesionales de la IA a utilizar hardware eficiente para reducir los costos de energía, pero el dramático aumento en el costo computacional observado en los últimos años se debe principalmente al modelado y a las elecciones algorítmicas; nuestro enfoque está en cómo incorporar la eficiencia allí. Al informar sobre la cantidad de trabajo realizado por un modelo, queremos medir una cantidad que permita una comparación justa entre los diferentes modelos. Como resultado, esta medida debería ser idealmente estable a través de diferentes laboratorios, en diferentes momentos y utilizando diferentes equipos.
Emisión de carbono. La emisión de carbono es atractiva ya que es una cantidad que queremos minimizar directamente. No obstante, es difícil medir la cantidad exacta de carbono liberado por la capacitación o la ejecución de un modelo y, en consecuencia, generar un resultado de IA, ya que esta cantidad depende en gran medida de la infraestructura eléctrica local (aunque véanse los esfuerzos iniciales de Henderson et al.16 y Lacoste et al.25). Como resultado, no es comparable entre investigadores en diferentes lugares o incluso el mismo lugar en diferentes momentos.16
El uso de la electricidad. El uso de la electricidad está correlacionado con la emisión de carbono, siendo a la vez agnóstico en cuanto al tiempo y al lugar. Además, las GPU suelen informar de la cantidad de electricidad que cada uno de sus núcleos consume en cada punto temporal, lo que facilita la estimación de la cantidad total de electricidad consumida al generar un resultado de IA. No obstante, esta medida depende del hardware y, por lo tanto, no permite una comparación justa entre los diferentes modelos desarrollados en diferentes máquinas.
Elapsado en tiempo real. El tiempo total de funcionamiento para generar un resultado de IA es una medida natural de la eficiencia, ya que, en igualdad de condiciones, un modelo más rápido hace menos trabajo de cálculo. No obstante, esta medida está muy influida por factores como el hardware subyacente, otros trabajos que se ejecutan en la misma máquina y el número de núcleos utilizados. Estos factores dificultan la comparación entre los diferentes modelos, así como la disociación de las contribuciones de los modelos de las mejoras del hardware.
Número de parámetros. Otra medida común de la eficiencia es el número de parámetros (aprendibles o totales) utilizados por el modelo. Al igual que con el tiempo de ejecución, esta medida está correlacionada con la cantidad de trabajo. A diferencia de las otras medidas descritas anteriormente, no depende del hardware subyacente. Además, esta medida también se correlaciona en gran medida con la cantidad de memoria consumida por el modelo. No obstante, los diferentes algoritmos hacen un uso diferente de sus parámetros, por ejemplo, haciendo que el modelo sea más profundo frente a más amplio. Como resultado, los diferentes modelos con un número similar de parámetros a menudo realizan diferentes cantidades de trabajo.
FPO. Como medida concreta, sugerimos informar el número total de operaciones en coma flotante (FPO) necesarias para generar un resultado.m La FPO proporciona una estimación de la cantidad de trabajo realizado por un proceso computacional. Se calcula analíticamente definiendo el coste de dos operaciones básicas, ADD y MUL. Basándose en estas operaciones, el coste FPO de cualquier operación abstracta de aprendizaje automático (por ejemplo, una operación de tanh, una multiplicación de matriz, una operación de convolución o el modelo BERT) puede calcularse como una función recursiva de estas dos operaciones. La FPO se ha utilizado en el pasado para cuantificar la huella energética de un modelo,13,32,50,51 pero no es ampliamente adoptado en la IA. La FPO tiene varias propiedades atractivas. En primer lugar, calcula directamente la cantidad de trabajo realizado por la máquina en funcionamiento cuando se ejecuta una instancia específica de un modelo y, por tanto, está vinculada a la cantidad de energía consumida. En segundo lugar, la FPO es agnóstica al hardware en el que se ejecuta el modelo. Esto facilita las comparaciones justas entre los diferentes enfoques, a diferencia de las medidas descritas anteriormente. Tercero, la FPO a menudo se correlaciona con el tiempo de funcionamiento del modelo5 (aunque véase el análisis que figura a continuación). A diferencia del tiempo de ejecución asintótica, la FPO también considera la cantidad de trabajo realizado en cada paso de tiempo.
El término IA verde se refiere a la investigación de la IA que produce resultados novedosos teniendo en cuenta el costo computacional, fomentando una reducción de los recursos gastados.
Existen varios paquetes para computar la FPO en varias bibliotecas de redes neuronales,n aunque ninguno de ellos contiene todos los bloques de construcción necesarios para construir todos los modelos modernos de IA. Animamos a los constructores de bibliotecas de redes neuronales a implementar dicha funcionalidad directamente.
Discusión. Los enfoques eficientes de aprendizaje automático han recibido atención en la comunidad de investigadores, pero por lo general no están motivados por ser ecológicos. Por ejemplo, una cantidad significativa de trabajo en la comunidad de visión artificial ha abordado la inferencia eficiente,13,38,58 que es necesario para el procesamiento en tiempo real de imágenes para aplicaciones como la auto-conducción de coches,27,29,37 o para colocar modelos en dispositivos como los teléfonos móviles.18,40 La mayoría de estos enfoques sólo minimizan el costo de procesamiento de un solo ejemplo, mientras que ignoran las otras dos prácticas rojas discutidas perversamente.o Otros métodos para mejorar la eficiencia tienen por objeto desarrollar arquitecturas más eficientes, empezando por la adopción de unidades de procesamiento gráfico (GPU) a los algoritmos de IA, que fue la fuerza motriz de la profunda revolución del aprendizaje, hasta el desarrollo más reciente de hardware como las unidades de procesamiento tensorial (TPU)22).
Los ejemplos de aquí indican que el camino para hacer que la IA sea verde depende de cómo se use. Cuando se desarrolla un nuevo modelo, gran parte del proceso de investigación implica el entrenamiento de muchas variantes del modelo en un conjunto de entrenamiento y la realización de la inferencia en un conjunto de desarrollo pequeño. En un entorno de este tipo, unos procedimientos de capacitación más eficientes pueden conducir a mayores ahorros, mientras que en un entorno de producción una inferencia más eficiente puede ser más importante. Abogamos por una visión holística de los ahorros computacionales que no sacrifique en algunas áreas para hacer avances en otras.
La FPO tiene algunas limitaciones. Lo más importante es que el consumo de energía de un modelo no sólo se ve influido por la cantidad de trabajo, sino también por otros factores como la comunicación entre los diferentes componentes, que no es captada por la FPO. Como resultado, la FPO no siempre se correlaciona con otras medidas como el tiempo de ejecución21 y el consumo de energía.16 En segundo lugar, la OPF se centra en el número de operaciones realizadas por un modelo, ignorando otros posibles factores limitantes para los investigadores, como la memoria utilizada por el modelo, que a menudo puede dar lugar a costos energéticos y monetarios adicionales.29 Por último, la cantidad de trabajo realizado por un modelo depende en gran medida de la implementación del mismo, ya que dos implementaciones diferentes del mismo modelo podrían dar lugar a cantidades muy diferentes de trabajo de procesamiento. Debido a la atención que se presta a la contribución del modelo, la comunidad de la IA ha ignorado tradicionalmente la calidad o la eficiencia de la implementación de los modelos.p Sostenemos que ha llegado el momento de invertir esta norma, y que las implementaciones excepcionalmente buenas que conducen a modelos eficientes deben ser acreditadas por la comunidad de la IA.
El coste de la FPO de los modelos existentes. Para demostrar la importancia de informar sobre la cantidad de trabajo, presentamos los costos de la FPO para varios modelos existentes.qLa figura 4(a) muestra el número de parámetros y FPO de varios modelos de reconocimiento de objetos principales, así como su rendimiento en el conjunto de datos de ImageNet.7,r Se observan algunas tendencias. En primer lugar, como ya se ha dicho, los modelos se encarecen con el tiempo, pero el aumento de la FPO no conduce a ganancias de rendimiento similares. Por ejemplo, un aumento de casi el 35% en FPO entre ResNet y ResNext (segundo y tercer punto en el gráfico) resultó en una mejora de la precisión del 0,5% en el top-1. Se observan patrones similares cuando se considera el efecto de otros aumentos en el trabajo de modelos. En segundo lugar, el número de parámetros del modelo no cuenta toda la historia: AlexNet (primer punto del gráfico) tiene en realidad más parámetros que ResNet (segundo punto), pero dramáticamente menos FPO, y también una precisión mucho menor.
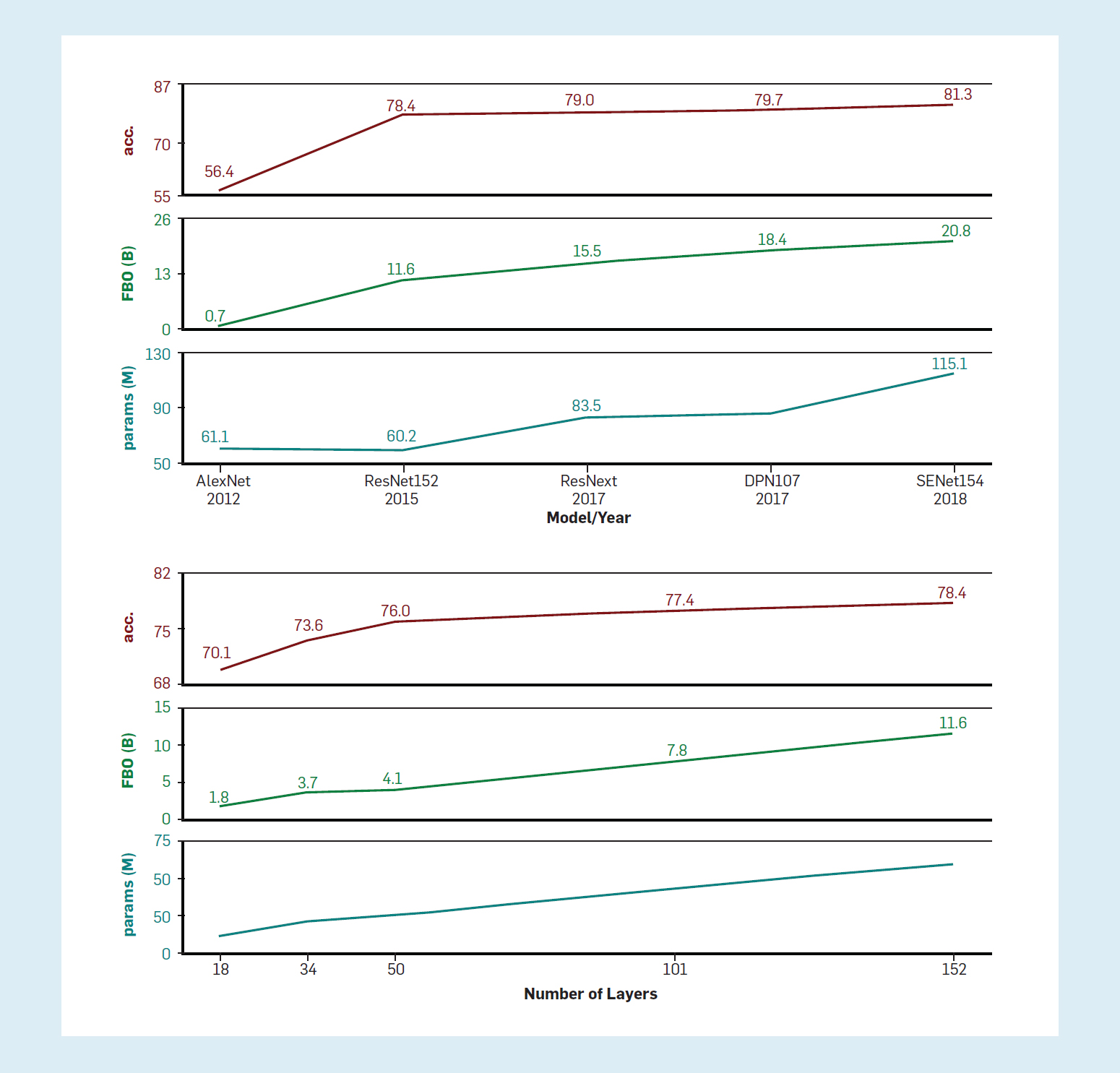
Figura 4. El aumento de la FPO lleva a una disminución del rendimiento de la detección de objetos con la máxima precisión. Gráficos (de abajo a arriba): parámetros del modelo (en millones), FPO (en miles de millones), precisión top-1 en ImageNet. 4(a). Principales modelos de reconocimiento de objetos: AlexNet,24 ResNet,15 ResNext,55 DPN107,6 SENet154.19 4(b): Comparación de los diferentes tamaños (medidos por el número de capas) del modelo ResNet.15
La figura 4(b) muestra el mismo análisis para un modelo de reconocimiento de un solo objeto, ResNet,15 mientras se comparan diferentes versiones del modelo con diferentes números de capas. Esto crea una comparación controlada entre los diferentes modelos, ya que son idénticos en arquitectura, excepto por su tamaño (y en consecuencia, su coste de FPO). Una vez más, notamos la misma tendencia: el gran aumento del coste de la FPO no se traduce en un gran aumento del rendimiento.
Otras formas de promover IA verde. Hay muchas maneras de fomentar la investigación más ecológica. Además de reportar el costo de la FPO para cada término en la Ecuación 1, animamos a los investigadores a reportar las curvas de presupuesto/rendimiento cuando sea posible. Por ejemplo, las curvas de formación proporcionan oportunidades para que los futuros investigadores comparen en un rango de diferentes presupuestos y la realización de experimentos con diferentes tamaños de modelos proporciona una valiosa información sobre cómo el tamaño del modelo impacta en el rendimiento. En un documento reciente9 observamos que la afirmación sobre qué modelo funciona mejor depende del presupuesto computacional disponible durante el desarrollo del modelo. Introdujimos un método para calcular el mejor rendimiento de validación esperado de un modelo en función del presupuesto dado. Sostenemos que la presentación de informes sobre esta curva permitirá a los usuarios tomar decisiones más sabias sobre su selección de modelos y destacar la estabilidad de los diferentes enfoques.
Abogamos además por hacer de la eficiencia una contribución oficial en las principales conferencias de la IA, aconsejando a los examinadores que reconozcan y valoren las contribuciones que no mejoran estrictamente el estado de la técnica, pero que tienen otros beneficios como la eficiencia. Por último, observamos que la tendencia de publicar modelos preformados es un éxito ecológico, y quisiéramos alentar a las organizaciones a que sigan publicando sus modelos para ahorrar a otros los costos de su readiestramiento.
Volver al principio
Trabajos relacionados
Trabajos recientes han analizado las emisiones de carbono de los modelos de PNL de profundidad de entrenamiento47 y llegó a la conclusión de que los experimentos costosos desde el punto de vista computacional pueden tener un gran impacto ambiental y económico. Con los experimentos modernos que utilizan presupuestos tan grandes, muchos investigadores (especialmente los del mundo académico) carecen de los recursos necesarios para trabajar en muchas áreas de alto perfil; el aumento del valor de los enfoques computacionalmente eficientes permitirá las contribuciones de investigación de grupos más diversos. Hacemos hincapié en que las conclusiones de Stubell et al.47 son el resultado de tendencias a largo plazo, y no están aisladas dentro de la PNL, sino que son válidas para todo el aprendizaje de las máquinas.
Si bien algunas empresas compensan el uso de electricidad comprando créditos de carbono, no está claro que la compra de créditos sea tan eficaz como el uso de menos energía. Además, la compra de créditos de carbono es voluntaria; la nube de Googles y Microsoft Azuret compran créditos de carbono para compensar su energía gastada, pero la AWS de Amazonu (la mayor plataforma de computación en la nubev) sólo cubría el 50% de su consumo de energía con energía renovable.
El impulso para mejorar el rendimiento de la tecnología punta ha centrado la atención de la comunidad investigadora en informar sobre el mejor resultado individual después de realizar muchos experimentos para el desarrollo de modelos y el ajuste de hiperparámetros. El no reportar completamente estos experimentos impide que los futuros investigadores entiendan cuánto esfuerzo se requiere para reproducir un resultado o extenderlo.9
Nos centramos en mejorar la eficiencia en la comunidad de aprendizaje de la máquina, pero el aprendizaje de la máquina también puede utilizarse como una herramienta de trabajo en áreas como el cambio climático. Por ejemplo, el aprendizaje automático se ha utilizado para reducir las emisiones de las plantas de cemento1 y el seguimiento de los resultados de la conservación de los animales,12 y se predice que será útil para la gestión de los incendios forestales.39 Sin duda, estas son aplicaciones importantes del aprendizaje por máquina; reconocemos que son ortogonales al contenido de este artículo.
Volver al principio
Conclusión
La visión de IA verde plantea muchas direcciones de investigación emocionantes que ayudan a superar los desafíos de La IA roja. El progreso encontrará formas más eficientes de asignar un presupuesto determinado para mejorar el rendimiento, o para reducir los gastos de computación con una reducción mínima del rendimiento. Además, parece que IA verde podría estar moviéndonos en una dirección más cognitiva, ya que el cerebro es muy eficiente.
Es importante reiterar que vemos IA verde como una opción valiosa, no un mandato exclusivo, por supuesto, tanto IA verde y La IA roja tienen contribuciones que hacer. Nuestros objetivos son aumentar La IA roja con ideas ecológicas, como el uso de métodos de capacitación más eficientes y la presentación de curvas de capacitación; y para aumentar la prevalencia de IA verde destacando sus beneficios, abogando por una medida estándar de eficiencia. Aquí, señalamos algunas direcciones importantes de la investigación verde, y destacamos algunas preguntas abiertas.
La investigación sobre la construcción de modelos eficientes en el espacio o en el tiempo suele estar motivada por la adaptación de un modelo a un dispositivo pequeño (como un teléfono) o lo suficientemente rápido como para procesar ejemplos en tiempo real, como el subtitulado de imágenes para los ciegos (como se ha comentado anteriormente). En este caso, abogamos por un enfoque mucho más amplio que promueva la eficiencia para todas las partes del ciclo de desarrollo de la IA.
La eficiencia de los datos ha recibido una atención significativa a lo largo de los años.23,41,49 La investigación moderna sobre la visión y la PNL a menudo implica primero el preentrenamiento de un modelo sobre grandes datos «brutos» (no anotados) y luego su ajuste a una tarea de interés a través de un aprendizaje supervisado. Un buen resultado en esta área a menudo implica lograr un rendimiento similar al de una línea de base con menos ejemplos de entrenamiento o menos pasos de gradiente. En la labor más reciente se ha abordado la cuestión del ajuste de los datos,34 pero la eficiencia del entrenamiento previo también es importante. En cualquier caso, una técnica sencilla para mejorar en esta área es simplemente informar sobre el rendimiento con diferentes cantidades de datos de entrenamiento. Por ejemplo, informar sobre el rendimiento de los modelos de incrustación contextual entrenados en 10 millones, 100 millones, 1.000 millones y 10.000 millones de fichas facilitaría un desarrollo más rápido de nuevos modelos, ya que pueden compararse primero con los tamaños de datos más pequeños.
La investigación aquí es de valor no sólo para hacer menos costosa la capacitación, sino porque en áreas como los idiomas de bajos recursos o los dominios históricos es extremadamente difícil generar más datos, por lo que para progresar debemos hacer un uso más eficiente de lo que está disponible.
Por último, el número total de experimentos realizados para obtener un resultado final a menudo no se informa ni se discute lo suficiente.9 Los pocos casos que los investigadores tienen de informes completos de la búsqueda de hiperparámetros, evaluaciones de arquitectura, y ablaciones que fueron a un resultado experimental reportado ha sorprendido a la comunidad.47 Aunque existen muchos algoritmos de optimización de hiperparámetros, que pueden reducir los gastos de computación necesarios para alcanzar un determinado nivel de rendimiento,3,11 simples mejoras aquí pueden tener un gran impacto. Por ejemplo, dejar de entrenar antes de tiempo a los modelos que tienen un rendimiento claramente inferior puede suponer un gran ahorro.26
Reconocimiento. Esta investigación se llevó a cabo en el Instituto Allen para la IA.

Figura. Vea a los autores discutir este trabajo en la exclusiva Comunicaciones video. https://cacm.acm.org/videos/green-ai
Volver al principio
Referencias
1. Acharyya, P., Rosario, S.D., Flor, F., Joshi, R., Li, D., Linares, R, y Zhang, H. Piloto automático de plantas de cemento para la reducción del consumo de combustible y las emisiones. En Actas del taller del ICML sobre el cambio climático, 2019.
2. Amodei, D. y Hernandez, D. AI y computación, 2018. Publicación en el blog.
3. Bergstra, J.S., Bardenet, R., Bengio, Y. y Kégl, B. Algoritmos para la optimización de hiperparámetros. En Procedimientos de NeurIPS, 2011.
4. Brown, T.B. y otros. Los modelos de lenguaje son aprendices de poca monta, 2020; arXiv:2005.14165.
5. Canziani, A., Paszke, A. y Culurciello, E. Un análisis de los modelos de redes neuronales profundas para aplicaciones prácticas. En Actas del ISCAS, 2017.
6. Chen, Y., Li, J., Xiao, H., Jin, X., Yan, S. y Feng, J. Redes de doble vía. En Procedimientos de NeurIPS, 2017.
7. Deng, J., Dong, W., Socher, R., Li, L-J, Li, K. y Fei-Fei, L. ImageNet: Una base de datos de imágenes jerárquica a gran escala. En Actas de la CVPR, 2009.
8. Devlin, J., Chang, M.W., Lee, K., y Toutanova, K. BERT: Entrenamiento previo de transformadores bidireccionales profundos para la comprensión del lenguaje. En Las actas de la NAACL, 2019.
9. Dodge, J., Gururangan, S., Card, D., Schwartz, R. y Smith, N.A. Muestra tu trabajo: Mejoramiento de los informes de los resultados experimentales. En Actas del EMNLP, 2019.
10. Dodge, J., Ilharco, G., Schwartz, R., Farhadi, A., Hajishirzi, H. y Smith, N.A. Perfeccionamiento de modelos lingüísticos preentrenados: Inicializaciones de peso, órdenes de datos y paradas tempranas, 2020; arXiv:2002.06305.
11. Dodge, J., Jamieson, K. y Smith, N.A. Optimización de hiperparámetros en bucle abierto y procesos de puntos determinantes. En Procedimientos de AutoML, 2017.
12. Duhart, C., Dublon, G., Mayton, B., Davenport, G. y Paradiso, J.A. Aprendizaje profundo para la conservación de la vida silvestre y los esfuerzos de restauración. En Actas del taller del ICML sobre el cambio climático, 2019.
13. Gordon, A., Eban, E., Nachum, O., Chen, B., Wu, H., Yang, T-J, y Choi, E. MorphNet: Aprendizaje rápido y sencillo de la estructura de recursos restringidos de las redes profundas. En Actas de la CVPR, 2018.
14. Halevy, A., Norvig, P. y Pereira, F. La irracional eficacia de los datos. IEEE Sistemas Inteligentes 24 (2009), 8–12.
15. He, K., Zhang, X., Ren, S. y Sun, J. Aprendizaje residual profundo para el reconocimiento de imágenes. En Actas de la CVPR, 2016.
16. Henderson, P., Hu, J., Romoff, J., Brunskill, E., Jurafsky, D. y Pineau, J. Towards the systematic reporting of the energy and carbon footprints of machine learning, 2020; arXiv:2002.05651.
17. Hochreiter, S. y Schmidhuber, J. Memoria a corto plazo. Cómputo neuronal 9, 8 (1997), 1735–1780.
18. Howard, A.G. y otros. MobileNets: Efficient convolutional neural networks for mobile vision applications, 2017; arXiv:1704.04861.
19. Hu, J., Shen, L. y Sun, G. Redes de apretón y excitación. En Actas de la CVPR, 2018.
20. Huang, J. y otros. Velocidad y precisión para los modernos detectores de objetos convolucionales. En Actas de la CVPR, 2017.
21. Jeon, Y. y Kim, J. Construyendo una red rápida a través de la deconstrucción de la convolución. En Procedimientos de NeurIPS, 2018.
22. Jouppi, N.P. y otros. Análisis del rendimiento en el centro de datos de una unidad de procesamiento de tensores. En Actas de la ISCA 11 (2017), fecha de publicación: junio de 2020.
23. Kamthe, S. y Deisenroth, M.P. Aprendizaje de refuerzo de datos con control predictivo de modelos probabilísticos. En Actas de AISTATS, 2018.
24. Krizhevsky, A., Sutskever, I. y Hinton, G.E. Clasificación de Imagenet con redes neuronales convolucionales profundas. En Procedimientos de NeurIPS, 2012.
25. Lacoste, A., Luccioni, A., Schmidt, V. y Dandres, T. Cuantificación de las emisiones de carbono del aprendizaje automático. En Actas del taller de la IA sobre el cambio climático, 2019.
26. Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A. y Talwalkar, A. Hyperband: Evaluación de la configuración basada en bandidos para la optimización de hiperparámetros. En Actas de la ICLR, 2017.
27. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S. Fu, C-Y y Berg, A.C. SSD: Detector multi-caja de un solo disparo. En Actas del ECCV, 2016.
28. Liu, Y. y otros. RoBERTa: Un enfoque de pre-entrenamiento del BERT robustamente optimizado, 2019; arXiv:1907.11692.
29. Ma, N., Zhang, X., Zheng, H.T y Sun, J. ShuffleNet V2: Directrices prácticas para el diseño eficiente de la arquitectura CNN. En Actas del ECCV, 2018.
30. Mahajan, D. y otros. Explorando los límites del preentrenamiento débilmente supervisado, 2018; arXiv:1805.00932.
31. Melis, G., Dyer, C. y Blunsom, P. Sobre el estado del arte de la evaluación en modelos de lenguaje neural. En Actas del EMNLP, 2018.
32. Molchanov, P., Tyree, S., Karras, T., Aila, T. y Kautz, J. Podando las redes neuronales convolucionales para la inferencia de recursos eficientes. En Actas de la ICLR, 2017.
33. Moore, G.E. Embutiendo más componentes en los circuitos integrados, 1965.
34. Peters, M., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K. y Zettlemoyer, L. Representaciones de palabras profundamente contextualizadas. En Las actas de la NAACL, 2018.
35. Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. y Sutskever, I. Los modelos de lenguaje son aprendices no supervisados de múltiples tareas… Blog de OpenAI, 2019.
36. Raffel, C. y otros. Explorando los límites del aprendizaje por transferencia con un transformador unificado de texto a texto, 2019; arXiv:1910.10683.
37. Rastegari, M., Ordóñez, V., Redmon, J. y Farhadi, A. Xnornet: Clasificación de Imagenet usando redes neuronales convolucionales binarias. En Actas del ECCV, 2016.
38. Redmon, J., Divvala, S., Girshick, R. y Farhadi, A. Sólo miras una vez: Detección de objetos unificada y en tiempo real. En Actas de la CVPR, 2016.
39. Rolnick, D. y otros. Tackling climate change with machine learning, 2019; arXiv:1905.12616.
40. Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. y Chen, L.C. MobileNetV2: Residuos invertidos y cuellos de botella lineales. En Actas de la CVPR, 2018.
41. Schwartz, R., Thomson, S. y Smith, N.A. SoPa: Uniendo CNN, RNN y máquinas de estado finito ponderado. En Procedimientos de ACL, 2018.
42. Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., Catanzaro, B. Megatron-LM: Entrenamiento de modelos de lenguaje paramétrico multimillonario usando el paralelismo del modelo de la GPU, 2019; arXiv:1909.08053.
43. Shoham, Y. y otros. The AI index 2018 annual report. Comité Directivo del Índice de Inteligencia Artificial, Iniciativa de Inteligencia Artificial centrada en el ser humano, Universidad de Stanford; http://cdn.aiindex.org/2018/AI%20Index%202018%20Annual%20Report.pdf.
44. Silver, D. y otros. Dominando el juego de Go con redes neurales profundas y búsqueda de árboles. Naturaleza 529, 7587 (2016) 484.
45. Silver, D. y otros. Dominando el ajedrez y el shogi por auto-juego con un algoritmo de aprendizaje de refuerzo general, 2017; arXiv:1712.01815.
46. Silver, D. y otros. Dominando el juego de Go sin conocimiento humano. Naturaleza 550, 7676 (2017), 354.
47. Strubell, E., Ganesh, A. y McCallum, A. Consideraciones energéticas y de política para el aprendizaje profundo en PNL. En Procedimientos de ACL, 2019.
48. Sun, C., Shrivastava, A., Singh, S. y Gupta, A. Revisando la eficacia irracional de los datos en la era del aprendizaje profundo. En Proceedings of ICCV, 2017.
49. Tsang, I., Kwok, J.T. y Cheung, P.M. Máquinas de vectores de núcleo: Entrenamiento rápido de SVM en conjuntos de datos muy grandes. JMLR 6 (abril de 2005), 363-392.
50. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gómez, A.N., Kaiser, L. y Polosukhin, I. La atención es todo lo que necesitas. En Procedimientos de NeurIPS, 2017.
51. Veniat, T. y Denoyer, L. Arquitecturas profundas eficientes en tiempo y memoria con super redes presupuestadas. En Actas de la CVPR, 2018.
52. Walsman, A., Bisk, Y., Gabriel, S., Misra, D., Artzi, Y., Choi, Y. y Fox, D. Fusión temprana para la visión robótica dirigida por objetivos. En Actas del IROS, 2019.
53. Wang, A. Pruksachatkun, Y., Nangia, N., Singh, A., Michael, J., Hill, F., Levy, O. y Bowman, S.R. SuperGLUE: A stickier benchmark for general-purpose language understanding systems, 2019; arXiv:1905.00537.
54. Wang, A., Singh, A., Michael, J., Hill, F., Levy, O. y Bowman, S.R. GLUE: Una plataforma de referencia y análisis multitarea para la comprensión del lenguaje natural. En Actas de la ICLR, 2019.
55. Xie, S., Girshick, R., Dollar, P., Tu, Z. y He, K. Transformaciones residuales agregadas para redes neuronales profundas. En Actas de la CVPR, 2017.
56. Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R. y Le, Q.V. XLNet: Preentrenamiento autorregresivo generalizado para la comprensión del lenguaje, 2019; arXiv:1906.08237.
57. Zellers, R., Holtzman, A., Rashkin, H., Bisk, Y., Farhadi, A., Roesner, F. y Choi, Y. Defendiendo contra las falsas noticias neuronales, 2019; arXiv:1905.12616.
58. Zhang, X., Zhou, X., Lin, M. y Sun, J. ShuffleNet: Una red neuronal convolucional extremadamente eficiente para dispositivos móviles. En Actas de la CVPR, 2018.
59. Zoph, B. y Le, Q.V. Búsqueda de arquitectura neuronal con aprendizaje de refuerzo. En Actas de la ICLR, 2017.
Volver al principio
Volver al principio
Notas a pie de página
a. Para ser breves, nos referimos a la IA a lo largo de este artículo, pero nos centramos en la investigación de la IA que se basa en métodos de aprendizaje profundo.
b. Significa, en la práctica, que la precisión de un sistema en algún punto de referencia es mayor que la precisión de cualquier sistema notificado anteriormente.
c. Algunas tablas de clasificación se centran en la eficiencia (https://dawn.cs.stanford.edu/benchmark/).
d. https://acl2018.org; https://nips.cc/Conferences/2018; y http://cvpr2019.thecvf.com.
e. Curiosamente, muchos documentos de NeurIPS incluían tasas de convergencia o límites de arrepentimiento que describen el rendimiento en función de ejemplos o iteraciones, apuntando así a la eficiencia (55%). Esto indica una mayor conciencia de la importancia de este concepto, al menos en los análisis teóricos.
f. https://syncedreview.com/2019/06/27/the-staggering-cost-of-training-sota-aimodels/
g. Véase https://github.com/google-research/bert y https://github.com/zihangdai/xlnet.
h. https://towardsdatascience.com/too-big-to-deploy-how-gpt-2-is-breakingproduction-63ab29f0897c
i. https://www.yuzeh.com/data/agz-cost.html
j. Las versiones recientes de AlphaGo son mucho más eficientes.46
k. https://opensource.google.com/projects/open-images-dataset
l. http://commoncrawl.org/2019/07/
m. Las operaciones en coma flotante se denominan a menudo FLOP(s), aunque este término no se define de manera única.13 Para evitar confusiones, utilizamos el término FPO.
n. Por ejemplo, https://github.com/Swall0w/torchstat; https://github.com/Lyken17/pytorch-OpCounter
o. De hecho, la creación de modelos más pequeños a menudo resulta en un tiempo de funcionamiento más largo, por lo que la mitigación de las diferentes tendencias podría estar en desacuerdo.52
p. Consideramos que este enfoque exclusivo en la predicción final es otro síntoma de La IA roja.
q. Estas cifras representan la FPO por inferencia, es decir, el trabajo necesario para procesar un solo ejemplo.
r. Números tomados de https://github.com/sovrasov/flops-counter.pytorch.
s. https://cloud.google.com/sustainability/
t. https://www.microsoft.com/en-us/environment/carbon
u. https://aws.amazon.com/about-aws/sustainability/
v. https://tinyurl.com/y2kob969
Los derechos de autor pertenecen a los autores/propietarios.
Este trabajo está licenciado bajo una licencia Creative Commons Attribution International 4.0 License.
La Biblioteca Digital es publicada por la Asociación de Maquinaria de Computación. Derechos de autor © 2020 ACM, Inc.
No se han encontrado entradas