

Aprendemos muchas lecciones de los hiperescaladores y centros de HPC del mundo, y una de ellas es que aquellos que controlan su propio software controlan sus propios destinos.
Y es precisamente por eso que todos los grandes hiperescaladores, que quieren vender servicios de IA o integrarlos en los servicios existentes para mantener sus productos frente a la feroz competencia, tienen sus propios modelos. Algunos, más de uno, ya pesar de todas las palabrería, son reacios a abrir los modelos básicos que han desarrollado en los últimos años. Para ser justos, se rumorea que Meta Platforms está considerando una variante comercial de su modelo básico LLaMA, del que hablamos en detalle en febrero.
Inflection AI, la puesta en marcha detrás del servicio de chatbot de «inteligencia personal» de Pi, ha recaudado $ 1.53 mil millones en capital de riesgo y terminará gastando una gran cantidad de ese dinero en capacidad de capacitación de IA para CoreWeave, un proveedor de cómputo en la nube de IA, y su socio, Nvidia. . El LLM Inflection-1 de cosecha propia de la compañía se entrenó en 3500 GPU Nvidia «Hopper» H100 como parte de sus recientes pruebas comparativas MLPerf, y creemos que se agregaron muchos miles de GPU Nvidia más para entrenar el modelo Inflection-1 completo.
Lo que sí sabemos es que Nvidia y CoreWeave están construyendo un clúster en la nube con 22 000 H100, que presumiblemente se usarán para crear y entrenar el LLM Inflection-2. Hemos calculado que los costos de hardware solo para esta máquina costarían alrededor de $ 1.35 mil millones, un poco más de lo que creemos que Microsoft está gastando para construir un grupo rumoreado con 25,000 GPU para entrenar lo que suponemos que es el modelo GPT-5. del socio OpenAI. (Comparamos estas máquinas con la supercomputadora «El Capitán» que Hewlett Packard Enterprise y AMD están construyendo recientemente para el Laboratorio Nacional Lawrence Livermore en términos de precio y varios tipos de rendimiento). Digamos que el gobierno de EE. UU. está haciendo un gran trato por sus sistemas de exaescala, y no creemos que las startups de IA o Microsoft puedan presumir de ello. La demanda es demasiado alta y la oferta es demasiado baja para que las GPU para entidades comerciales no paguen una prima considerable.
Después de una inmersión profunda en Inflection AI hace unas semanas, prometimos que regresaríamos y veríamos cómo su Inflection-1 LLM se compara con los otros modelos grandes que compiten por ser la base de las adiciones de IA generativa a aplicaciones grandes y pequeñas. – y aquí y allá y en todas partes. Queda por ver cómo se puede monetizar algo de esto, pero si los costos de capacitación e inferencia se reducen, como creemos que pueden hacerlo, es razonable suponer que la IA generativa se integrará en casi todo.
Hablemos sobre la escala y el alcance por un minuto, y específicamente sobre los recuentos de parámetros y tokens utilizados en la capacitación de los LLM. Estos dos juntos impulsan el uso de fracasos y el comportamiento cada vez más emergente de los modelos. Y al igual que antes durante la era del análisis de datos de la Web, parece que más datos superan a un mejor algoritmo, pero solo hasta cierto punto con el entrenamiento de IA porque después de cierto punto, los datos en Internet (o seleccionados de otro lugar) que se puede cortar en pedazos, ese es el token, y un token tiene aproximadamente cuatro caracteres de largo, es basura completa y absoluta y en realidad hace que un modelo se comporte peor, no mejor.
Los parámetros en una red neuronal son las ponderaciones de las conexiones entre las neuronas virtuales expresadas en código que son similares a los picos de voltaje reales para activar las neuronas en nuestros cerebros reales. El acto de entrenar es usar un conjunto de datos para crear estas activaciones y luego refinarlas propagando las respuestas correctas en el entrenamiento para que pueda mejorar. Con este método, primero usando conjuntos de datos etiquetados y luego sin requerirlos una vez que una cierta escala de datos y procesamiento fue posible, podemos enseñar a una red neuronal a dividir cualquier dato, como una imagen o un bloque de texto, en descriptivos. bits y luego volver a ensamblarlos de manera que «sepa» qué es esa imagen o texto. Cuantos más parámetros tenga, más rico será el baile de spiking en la red neuronal.
Entonces, los tokens te dicen cuánto sabes y los parámetros te dicen qué tan bien puedes pensar sobre lo que sabes. Los recuentos de parámetros más pequeños contra un conjunto más grande de tokens le brindan respuestas más rápidas pero más simples. Los recuentos de parámetros más grandes contra un conjunto más pequeño de tokens le brindan muy buenas respuestas sobre un número limitado de cosas. Lograr un equilibrio es la clave, y creemos que los investigadores de IA todavía están tratando de resolverlo.
Revisemos el parámetro y el recuento de tokens en algunos de los modelos:
- El modelo BERT de Google, a partir de 2018, vino con 110 millones (base) y 340 millones (grandes) recuentos de parámetros; el conjunto de datos de entrenamiento tenía 3300 millones de palabras, pero no sabemos el recuento de tokens. El tamaño de palabra promedio en inglés es de 4,7 caracteres y el tamaño promedio de token es de alrededor de cuatro caracteres, lo que pondría el recuento de tokens en alrededor de 4 mil millones de tokens.
- La variante Megatron MT-NLG de Nvidia del modelo BERT de Google pesó 530 mil millones de parámetros, pero solo se entrenó en 270 mil millones de tokens.
- El modelo Chinchilla de Google, que se ha utilizado para encontrar la mejor proporción de recuento de tokens y recuento de parámetros para cualquier cantidad de cómputo, alcanza un máximo de 70 000 millones de parámetros con un conjunto de entrenamiento de 1,4 billones de tokens. La regla general de Chinchilla, que se muestra en este documento, es de 20 tokens de texto por parámetro.
- Pathways Language Model (PaLM) de Google se lanzó en 2022, masticó 780 000 millones de tokens y alcanzó un máximo de 540 000 millones de parámetros. El modelo PaLM 2, que fue entrenado para más de cien idiomas, salió en mayo con 340 mil millones de parámetros como máximo y 3,6 billones de tokens en su conjunto de datos de entrenamiento. PaLM 2 es el que Google está integrando en más de 25 de sus servicios.
- Google Gemini, abreviatura de Generalized Multimodal Intelligence Network, se basa en las capacidades de resolución de problemas del modelo de juego DeepMind AlphaGo y será el próximo en la serie de modelos de IA generativa del gigante de los motores de búsqueda. Está dirigido directamente al GPT-4 de OpenAI, y no tenemos idea de qué conteo de parámetros o conteo de tokens tendrá. Es mucho más fácil aumentar el número de parámetros y los niveles de la red neuronal que el tamaño de los datos de entrenamiento, eso es seguro.
- El extremo superior de la tercera iteración del modelo de transformador preentrenado generativo (GPT-3) de OpenAI, cuyo nombre en código es «Davinci» y lanzado a principios de 2019 por OpenAI, fue entrenado en alrededor de 499 mil millones de tokens y alcanzó un máximo de 175 mil millones. parámetros El modelo se refinó en GPT-3.5 con nuevos algoritmos y medidas de seguridad.
- GPT-4 salió en marzo de este año, y los rumores dicen que tiene al menos 1 billón de parámetros y algunos han estimado que tiene alrededor de 1,76 billones de parámetros. Eso es un factor de 10X más parámetros. Si bien OpenAI no ha dicho cuántos datos ha masticado, consideramos que OpenAI alcanzará el rango de 3,6 billones como Google en más de cien idiomas y que el corpus en inglés no cambiará tanto, ni siquiera con la adición de dos más años de contenido de Internet. (GPT-4 se corta en septiembre de 2021). GPT-5 probablemente será el que OpenAI rompa en todos esos idiomas.
- El modelo LLaMA lanzado este año por Meta Platforms ha sido entrenado usando 6.700 millones, 13.000 millones, 32.000 millones y 65.200 millones de parámetros, con los dos modelos más pequeños utilizando 1 billón de tokens y los dos más grandes utilizando 1,4 billones de tokens.
Con eso como contexto, hablemos del modelo de base Inflection-1. En primer lugar, los detalles de la arquitectura en términos de número de parámetros y tokens de datos utilizados para el entrenamiento son secretos. Lo cual no es genial y se hace a propósito, como admite abiertamente el documento de rendimiento de Inflection-1 publicado por Inflection AI. Bueno, eso no es divertido. Pero si Inflection AI está prestando atención como lo está haciendo Meta Platforms, entonces el recuento de parámetros podría ser medio mientras que el recuento de tokens podría ser bastante alto. Sospechamos firmemente que está en algún lugar, lo adivinaste, 1,4 billones de tokens. Solo el cielo sabe dónde está el conteo de parámetros para Inflection-1.
Cuando Inflection AI habla de modelos generativos de IA, divide el mundo en dos campos. Aquellos que han implementado tanto o más cómputo de punto flotante como el modelo PaLM de Google y aquellos que no lo han hecho. Inflection AI se ubica en la última categoría, junto con GPT-3.5 y LLaMA, entre otros, y se desempeña casi tan bien como PaLM-2 y GPT-4 en muchas pruebas.
Ahora, hablemos de los datos. Así es como Inflection-1 se alineó con GPT-3.5 y LLaMA en una variedad de tareas:
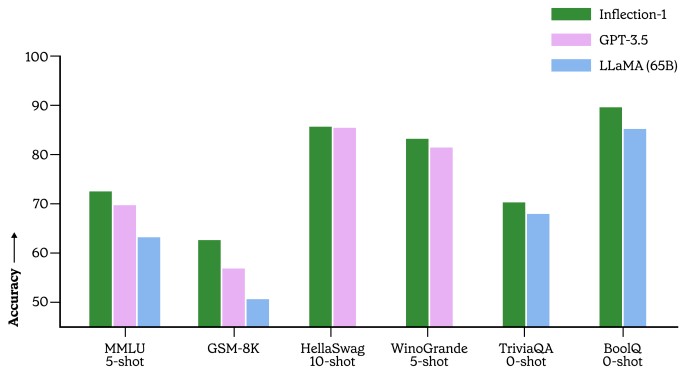
Si bien este gráfico es bonito y todo eso, lo que necesita saber son las configuraciones precisas de los clústeres que ejecutaron estas pruebas para determinar cuál ofrece el mejor rendimiento. con que precisión. Esto es algo que debemos considerar, al igual que lo haríamos con un procesador muy rápido pero defectuoso en un clúster HPC. Los sistemas de IA pueden equivocarse, y lo harán, ¿y a quién le importa si obtienen una respuesta incorrecta más rápido? Y, con suerte, no quemando mucho dinero haciéndolo. . . .
Lo que muestra este gráfico es si tiene problemas de color o no (los tenemos), pero también muestra que en una variedad de exámenes y tareas de preguntas y respuestas, Inflection 1 puede estar cara a cara con los 175 mil millones de GPT-3.5. parámetros y los 65 mil millones de modelos de parámetros de LLaMA.
Este artículo tiene muchas comparaciones, y no vamos a revisarlas todas, pero esta sobre la precisión del modelo en el conjunto de puntos de referencia para la realización de pruebas de Comprensión del lenguaje multitarea (MMLU) es interesante porque trae muchas de ellas. juntos:
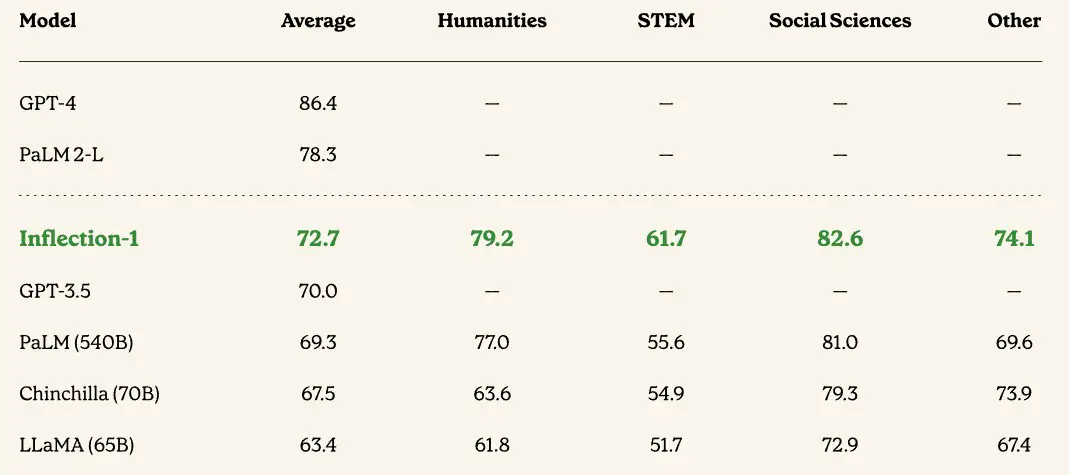
En todos los casos, Inflection-1 LLM funciona mejor que GPT-3.5, PaLM, Chinchilla y LLaMA, aunque tiene mucho camino por recorrer antes de que pueda alcanzar a PaLM 2-L y GPT-4. Si estos tres modelos principales se están entrenando esencialmente en el mismo conjunto de datos de 1,4 billones de tokens (que, por cierto, ninguno de ellos posee), entonces lo único que puede hacer Inflection AI es aumentar el recuento de parámetros y ajustar su modelo para ponerse al día con Microsoft. /OpenAI y Google. Esos parámetros adicionales consumen memoria y hacen que un modelo tarde más en entrenarse, y eso puede no valer la pena para el servicio Pi que ofrece Inflection AI.
Lo que podemos esperar es que el tamaño de los modelos generativos de IA no se base en la precisión en el sentido más puro, sino en una precisión que sea lo suficientemente buena para el servicio que se vende. Un amigo en línea de chatbot para los solitarios no necesita la misma precisión que una IA que realmente está tomando decisiones, o descargando cualquier responsabilidad de una decisión a los seres humanos que se apoyan en la IA para «ayudarlos» a tomar una decisión.

Presentando aspectos destacados, análisis e historias de la semana directamente de nosotros a su bandeja de entrada sin nada en el medio.
Suscríbase ahora