

Los humanos manipulan diariamente estructuras deformables en 2D como el tejido,
desde ponerse la ropa hasta hacer las camas. ¿Pueden los robots aprender a actuar de forma similar
tareas? Los enfoques exitosos pueden hacer avanzar aplicaciones tales como el vestirse
asistencia para el cuidado de ancianos, doblado de ropa, tapicería de tela, fabricación de camas,
fabricación, y otras tareas. Sin embargo, la manipulación de la tela es un desafío,
debido a la dificultad de modelar los estados y la dinámica del sistema, lo que significa que
cuando un robot manipula un tejido, es difícil predecir el resultado del tejido
estado o apariencia visual.
En esta entrada del blog, revisamos cuatro artículos recientes de dos laboratorios de investigación (Pieter
de Abbeel y Ken Goldberg) en Berkeley AI Research (BAIR) que
investigue la siguiente hipótesis: ¿es posible emplear la tecnología basada en el aprendizaje
enfoques del problema de la manipulación de los tejidos?
Demostramos resultados prometedores en apoyo de esta hipótesis mediante el uso de un
variedad de métodos basados en el aprendizaje con simuladores de tejido para entrenar la suavidad
(e incluso plegables) en la simulación. Luego realizamos la transferencia de la simulación a la realidad
para desplegar las políticas sobre los robots físicos. Ejemplos de las políticas aprendidas en
se muestran en los GIFs de arriba.
Mostramos que los métodos profundos sin modelo entrenados desde la exploración o desde
las demostraciones funcionan razonablemente bien para tareas específicas como el alisado, pero
no está claro cuán bien se generalizan a tareas relacionadas como el plegado. En el
Por otro lado, mostramos que los métodos basados en modelos profundos tienen más potencial para
generalización a una variedad de tareas, siempre que los modelos aprendidos sean
lo suficientemente preciso. En el resto de este post, resumimos los documentos,
enfatizando la técnicas y compensaciones en cada acercamiento.
Aprendizaje sin modelos ni demostraciones
En este documento presentamos un enfoque de aprendizaje de refuerzo profundo sin modelo
para suavizar la tela. Usamos un ambiente de control de DM con MuJoCo.
Enfatizamos dos innovaciones clave que nos ayudan a acelerar el entrenamiento: un factorizado
la política de escoger el lugar, junto con el aprendizaje de la política de lugar condicionada a
puntos de selección al azar, y luego elegir el punto de selección por el valor máximo. La cifra
a continuación se muestra una visualización.

A diferencia del aprendizaje directo de la política de «elegir y colocar» (a), nuestro método
aprende cada componente de un modelo factorizado de selección y colocación de forma independiente por
primero entrenando con una política de lugares con lugares elegidos al azar, y luego
aprendiendo la política de elección.
El entrenamiento conjunto de las políticas de «pick and place» puede resultar ineficiente
…aprender. Considere el escenario degenerado cuando la política de selección se derrumba en
un conjunto de puntos restrictivos subóptimo. Esto inhibiría la exploración de la
política de lugar ya que las recompensas vienen sólo después de que las acciones de escoger y colocar son
ejecutado. Para resolver este problema, nuestro método propone utilizar primero
Soft Actor Critic (SAC), un refuerzo profundo sin modelo de última generación
algoritmo de aprendizaje, para aprender una política de lugar condicionada a los puntos de recogida de la muestra
uniformemente de puntos de recogida válidos en la tela. Entonces, caracterizamos la púa
política seleccionando el punto con el valor más alto de la política aproximada de
estimador de valor aprendido al entrenar la política de lugar, por lo tanto Valor Máximo
en la sección de Colocación (MVP). Observamos que nuestro enfoque no está ligado al SAC, y puede funcionar
con cualquier algoritmo de aprendizaje fuera de la política.

Un ejemplo de experimentos de suavizado de telas de robots reales con diferentes tipos de arranque…
los estados y los colores de la tela. Cada fila muestra un episodio diferente de un estado de inicio
a la suavidad de la tela lograda. Observamos que el robot puede alcanzar el objetivo
de los estados iniciales complejos, y generaliza fuera de los datos de entrenamiento
distribución.
La figura de arriba muestra diferentes episodios en un robot real usando un
la política de «elegir y colocar» aprendida con nuestro método. La política está entrenada en
simulación, y luego transferido a un robot real usando la aleatorización de dominio en
la física de la tela, el color y la iluminación. Podemos ver que la política aprendida es capaz
para alisar con éxito la tela a partir de muchas complejidades diferentes de
estado, y para diferentes colores de tela.
Las ventajas del enfoque de aprendizaje de refuerzo sin modelos de este trabajo son
que todo el entrenamiento puede hacerse en simulación sin ninguna demostración, y
que el entrenamiento puede ser aplicado fácilmente usando algoritmos estándar y es
más rápido debido a la estructura de «recoger y colocar» que presentamos, que (como se discutió
antes) puede evitar el colapso del modo. La contrapartida es que entrena una política que
sólo puede hacer el alisado, y debe ser reentrenado para otras tareas. Además, el
las acciones pueden tener tirones relativamente cortos y pueden ser ineficientes cuando se trata de
a tareas de tela más difíciles como el plegado.
Aprendizaje sin modelos con demostraciones simuladas
- Daniel Seita, Aditya Ganapathi, Ryan Hoque, Minho Hwang, Edward Cen, Ajay Kumar Tanwani, Ashwin Balakrishna, Brijen Thananjeyan, Jeffrey Ichnowski, Nawid Jamali, Katsu Yamane, Soshi Iba, John Canny, Ken Goldberg.
Aprendizaje de imitación profunda del alisado de telas secuenciales de un supervisor algorítmico
arXiv 2019. Sitio web del proyecto con código.
Ahora presentamos un enfoque alternativo para suavizar las telas. Como el
papel anterior, usamos un método sin modelos y creamos un ambiente para la tela
manipulación usando un simulador. En lugar de MuJoCo, usamos un simulador hecho a medida
simulador que representa la tela como una cuadrícula de 25 dólares por 25 dólares de puntos. Hemos
open source este simulador para que otros investigadores lo utilicen.
En este proyecto, consideramos un plano de la tela como un cuadrado de fondo blanco de
del mismo tamaño que una tela totalmente lisa. La métrica de rendimiento es cobertura,
o cuánto del plano de fondo se cubre con la tela, que
anima al robot a cubrir un lugar específico. Terminamos un episodio si
el robot alcanza al menos un 92% de cobertura.
Una forma de suavizar la tela es tirar de las esquinas de la tela. Ya que esta política es
fácil de definir, codificamos un supervisor algorítmico en la simulación y realizamos
aprendizaje de imitación usando Dataset Aggregation (DAgger). Como se ha explicado brevemente
en una entrada anterior del blog de BAIR, DAgger es un algoritmo para corregir
cambio de covariable. Continuamente consulta a un supervisor agente para conseguir la corrección
acciones para los estados. Esto es normalmente un inconveniente para DAgger, pero no es un
problema en este caso, ya que tenemos un simulador con acceso total al estado
(es decir, la cuadrícula de 25 dólares por 25 puntos) y puede determinar la
una óptima acción de atracción de manera eficiente.
Además de usar imágenes en color, usamos profundidad imágenes, que proporcionan una
«escala de altura». En una entrada anterior del blog del BAIR, discutimos cómo la profundidad era
útil para varias tareas de robótica. Para obtener imágenes, utilizamos Blender, un
un juego de herramientas de gráficos por ordenador de código abierto.
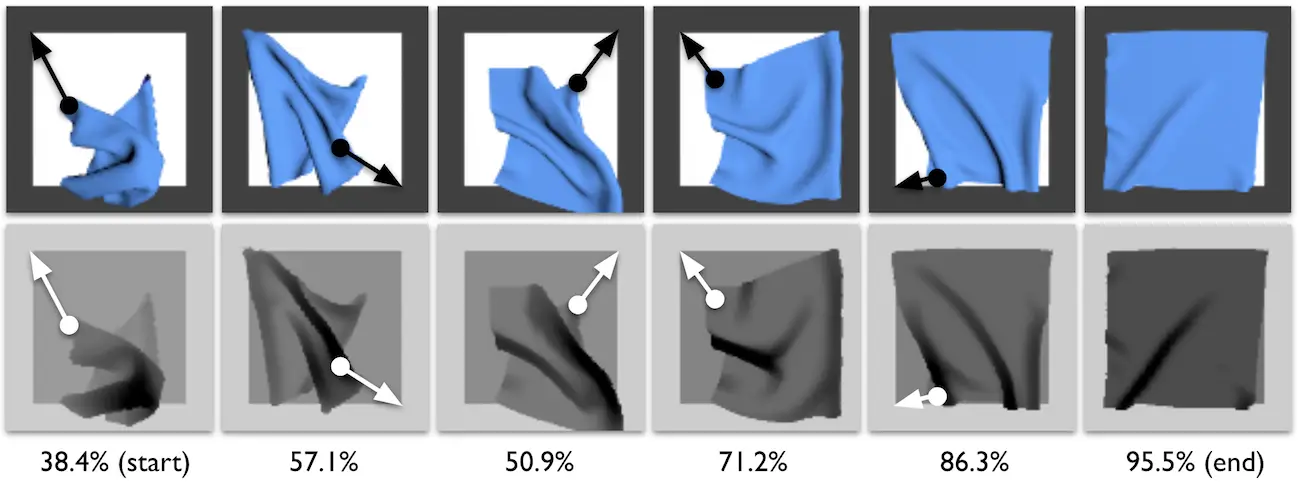
Un episodio de ejemplo de nuestra política simulada de supervisión de tirar de la esquina. Cada uno
La columna de imágenes muestra una acción, representada por las flechas blancas superpuestas.
Mientras que nosotros dominamos-aleatorizamos estas imágenes para el entrenamiento, para la visualización
en esta figura, dejamos las imágenes en su configuración «por defecto». El comienzo
estado, representado a la izquierda, está muy arrugado y sólo cubre el 38,4% del
plano de la tela. A través de una secuencia de cinco acciones de recogida y extracción, la política
finalmente obtiene una cobertura del 95,5%.
La figura de arriba visualiza la política del supervisor. El supervisor elige el
esquina de la tela para tirar en base a su distancia de un objetivo conocido en el
plano de fondo. A pesar de que las esquinas de la tela a veces están ocultas por una tapa
como en el segundo paso temporal, las acciones de recoger y tirar son eventualmente
…que pueda obtener suficiente cobertura.
Después de entrenar con DAgger en el dominio de datos aleatorios, transferimos la política
a un Robot Quirúrgico da Vinci sin ningún entrenamiento adicional. La figura
A continuación se presenta un ejemplo de un episodio de Da Vinci tirando y suavizando
…la tela.

Un ejemplo de episodio de siete acciones tomadas por una política entrenada sólo en simulacro
Imágenes RGB-D. La fila superior tiene capturas de pantalla del video del robot físico,
con flechas negras superpuestas para visualizar la acción. La segunda y tercera fila
muestran las imágenes de color y profundidad que se procesan como entrada para ser pasadas
a través de la política aprendida. A pesar del tejido inicial altamente arrugado, a lo largo de
con esquinas de tela ocultas, el da Vinci es capaz de ajustar la tela de
40,1% a 92,2% de cobertura.
Para resumir, aprendemos políticas de suavización de la tela usando el aprendizaje de imitación con
un supervisor que tiene acceso a la información del estado real de las telas. Nosotros
dominio aleatorizar los colores, el brillo y la orientación de la cámara en simulaciones
imágenes para transferir pólizas a un robot quirúrgico da Vinci físico. El
La ventaja del enfoque es que el robot puede suavizar eficientemente el tejido en
relativamente pocas acciones y no requiere un gran espacio de trabajo, ya que la formación
Los datos consisten en largos tirones restringidos en el espacio de trabajo. Además,
La implementación y depuración de DAgger es relativamente fácil comparada con la de los modelos libres.
métodos de aprendizaje de refuerzo como DAgger es similar al aprendizaje supervisado y
uno puede inspeccionar la salida del profesor. Las limitaciones principales son que
necesitan saber cómo aplicar la política del supervisor, lo que puede ser difícil
para las tareas más allá de la suavización, y que la política aprendida es una suavización
«especialista» que debe ser re-entrenado para otras tareas.
Planificación sobre los estados de imagen
- Ryan Hoque*, Daniel Seita*, Ashwin Balakrishna, Aditya Ganapathi, Ajay Kumar
Tanwani, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg.
VisuoSpatial Foresight para la manipulación de tejidos de múltiples pasos y tareas.
Robótica: Ciencia y Sistemas, 2020. Sitio web del proyecto con código.
Mientras que los dos enfoques anteriores nos dan un sólido rendimiento en el suavizado
tarea en los sistemas robóticos reales, las políticas aprendidas son «especialistas en suavizar»
y debe ser entrenado desde el principio para una nueva tarea, como el plegado de telas. En
En este documento, consideramos el problema más general de la condicionalidad de los objetivos
manipulación de la tela: dado un observación de imágenes con un solo objetivo de un deseado
estado de la tela, queremos una política que pueda llevar a cabo una secuencia de
acciones para pasar de una configuración inicial arbitraria a ese estado.
Para ello, desacoplamos el problema en el aprendizaje de un modelo de tejido
dinámica directamente de las observaciones de la imagen y luego reutilizando ese modelo de dinámica
para diferentes tareas de manipulación de tejidos. Para la primera, aplicamos la tecnología visual
El marco de previsión propuesto por nuestros colegas del BAIR, un modelo basado en
técnica de aprendizaje de refuerzo que entrena un modelo de predicción de vídeo para
predecir una secuencia de imágenes a partir de la observación de la imagen del estado actual como
así como una secuencia de acción. Con tal modelo, podemos predecir los resultados de
tomar varias secuencias de acción, y puede entonces utilizar técnicas de planificación como
el método de la entropía cruzada y el control predictivo del modelo para planificar acciones que
minimizar alguna función de costo. Usamos la distancia euclidiana a la imagen de la meta para
la función de costo en nuestros experimentos.
Generamos aproximadamente 100.000 imágenes de un completamente al azar política, ejecutada
completamente en la simulación. Usando el mismo simulador de tejido que en (Seita et al.,
2019), usamos la Predicción de Variación de Vídeo Estocástica (SV2P) como la
modelo de predicción de video. Aprovechamos tanto las modalidades RGB como las de profundidad, que
encontrar en nuestros experimentos para superar cualquier modalidad por sí sola, y por lo tanto llamar a la
algoritmo Previsión Visuoespacial (VSF).
Mientras que el trabajo previo sobre la Previsión Visual incluye algo de manipulación de tejidos
resultados, las tareas consideradas son típicamente de corto plazo y tienen un amplio rango
de los estados objetivos, como cubrir una cuchara con la pierna de un pantalón. En contraste, nos centramos
en tareas de mayor horizonte que requieren una secuencia de preciso puntos de elección. Ver
la imagen de abajo para las predicciones típicas de tiempo de prueba de la dinámica visual
modelo. Los datos son aleatorios en cuanto a color, ángulo de la cámara, brillo y
para facilitar la transferencia a un Robot Quirúrgico da Vinci.

Mostramos al suelo imágenes verdaderas como resultado de la manipulación de la tela, cada una emparejada
con las predicciones del modelo de predicción de video entrenado. Dado sólo un comienzo
imagen (no se muestra), junto con las siguientes cuatro acciones, el modelo de predicción de vídeo
debe predecir las próximas cuatro imágenes, que se muestran arriba.
Las predicciones son lo suficientemente precisas para que podamos planear hacia una variedad de objetivos
imágenes. De hecho, nuestra política resultante rivaliza con el rendimiento del alisado
especialistas…a pesar de que sólo se ven imágenes aleatorias en el entrenamiento.






Ejecutamos una secuencia de acciones de «pick and place» para manipular la tela hacia
alguna imagen de la meta. La fila superior tiene tres imágenes de meta diferentes: lisa, doblada,
y doblemente doblado, que tiene tres capas de tela apiladas en el centro en un
orden particular. En la fila inferior, mostramos los despliegues simulados (mostrados aquí como
de observaciones de imágenes en intervalos de tiempo) de nuestra política de VSF manipulando el tejido hacia
cada una de las imágenes de la meta. La parte inferior de la tela es de un tono más oscuro
(ligeramente más oscuro en la segunda y mucho más oscuro en la tercera columna), y el
las manchas de luz en la oscuridad se deben a las auto-colisiones en el simulador que
son difíciles de modelar.
La principal ventaja de este enfoque es que podemos entrenar a un solo neural
política de redes que se utilizará para una variedad de tareas, cada una de las cuales se establece
proporcionando una imagen objetivo de la configuración del tejido del objetivo. Por ejemplo, podemos
hacer tareas de plegado, para las cuales puede ser un reto codificar a mano un algoritmo
supervisor, a diferencia del caso de suavizar. Los principales inconvenientes son que
El entrenamiento de un modelo de predicción de video es difícil debido a la alta dimensión
naturaleza de las imágenes, y que típicamente requerimos más acciones que la imitación
agente de aprendizaje para completar las tareas de suavizado ya que los datos consisten en
acciones de menor magnitud.
Planificación sobre los estados latentes
En este documento, consideramos igualmente un método basado en modelos, pero en lugar de
entrenando un modelo de predicción de video para planear en el espacio de pixeles, nosotros en cambio plan en un
aprendió el espacio latente de dimensiones inferiores desde que aprendió un modelo de predicción de video
puede ser un desafío, ya que el modelo aprendido debe capturar cada detalle de la
el medio ambiente. Además, también es difícil aprender la dinámica adecuada de los píxeles
en los casos en que utilizamos la aleatorización de dominio cuadro por cuadro para transferir al
el mundo real.
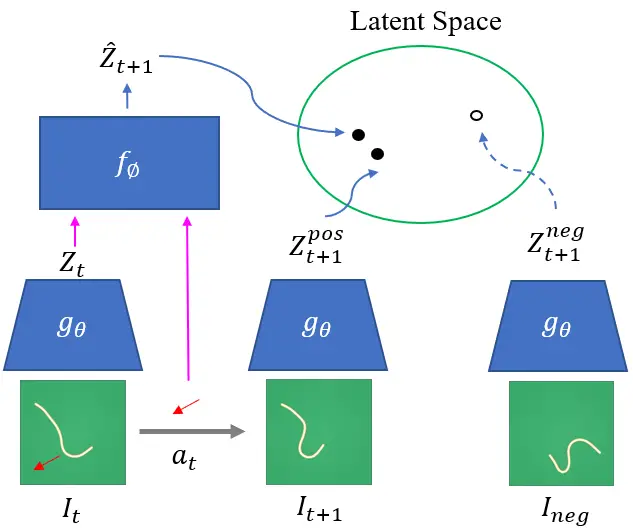
Una representación visual del marco de aprendizaje contrastivo. Dada la positiva
pares de estados actuales y observaciones negativas muestreadas al azar, aprendemos
un codificador y un modelo de avance tal que los próximos estados estimados se encuentran más cerca
que las observaciones negativas en el espacio latente.
Aprendemos conjuntamente un codificador y un modelo de avance latente usando contrastes
métodos de estimación. El codificador mapea las imágenes en bruto en una latente de menor dimensión
espacio. El modelo de avance latente tomará esta variable latente, junto con el
y producir una estimación del próximo estado.
Entrenamos nuestros modelos minimizando una variante del contraste de la InfoNCE
pérdida, lo que fomenta el aprendizaje latente que maximiza la información mutua
entre las huellas latentes codificadas y sus respectivas observaciones futuras. En la práctica,
este método de entrenamiento acercará las codificaciones latentes actuales y posteriores
(en $L_2$ de distancia), mientras que se hacen otras codificaciones latentes no próximas para ser
…más separados. Como resultado, somos capaces de usar el codificador aprendido y aprender
para predecir eficazmente el futuro, similar al modelo basado en imágenes
presentado en el documento anterior (Hoque et al., 2020), excepto que estamos
no predicen imágenes sino variables latentes, que son potencialmente más fáciles de
con el que trabajar.
En nuestros experimentos con telas, aplicamos acciones aleatorias para recoger 400.000 muestras en
un simulador de control de DM con aleatorización de dominio añadido en la física de la tela,
la iluminación, y el color de la tela. Usamos el codificador aprendido y el modelo de avance para
realizar el control predictivo del modelo (MPC) con una predicción de un paso para planificar hacia
una imagen de estado objetivo deseada. La siguiente figura muestra ejemplos de suavizado
telas de diferentes colores en un robot PR2 real. Tengan en cuenta que la misma tela azul es
usado como la imagen de la meta sin importar la tela real que se esté manipulando. Este
indica que las huellas latentes aprendidas han aprendido a ignorar las innecesarias
propiedades de la tela como el color cuando se realizan tareas de manipulación.
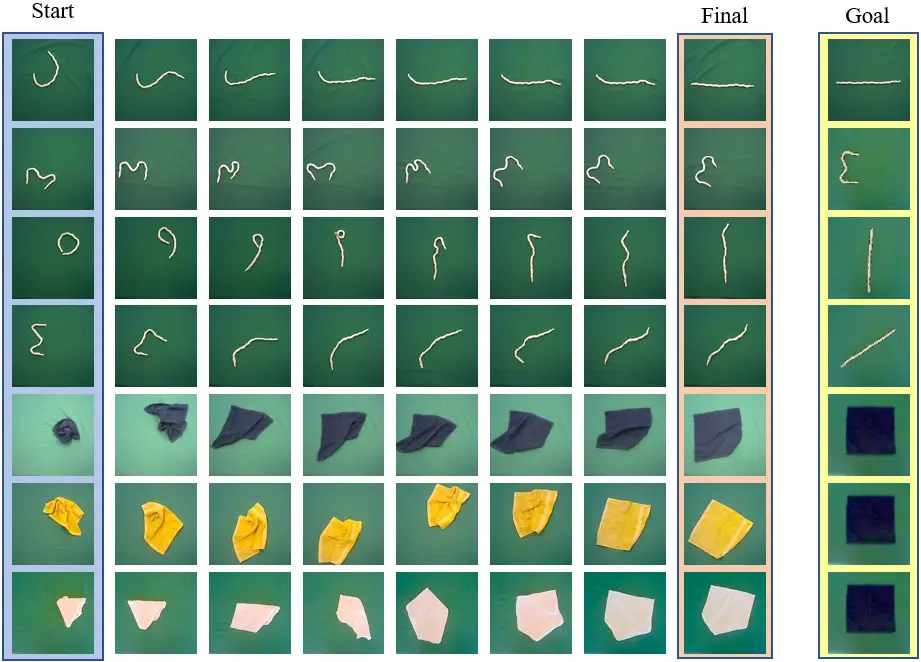
Varios episodios de manipulación de cuerda y tela con nuestro método, con
diferentes estados de inicio y meta. Tengan en cuenta que se utiliza la misma tela azul que la
estado de objetivo independientemente del color de la tela que se manipula
Similar a (Hoque et al., 2020), este método es capaz de resolver el objetivo de múltiples tareas
como se muestra en los episodios de ejemplo arriba ejecutados en un robot real. Usando
métodos contrastados para aprender un espacio latente, también conseguimos una mejor muestra
complejidad en el aprendizaje de los modelos en comparación con los modelos de predicción directa de vídeo,
porque estos últimos requieren más muestras para predecir imágenes de alta dimensión. En
Además, la planificación directamente en los espacios latentes es más fácil en comparación con la planificación
con un modelo visual. En nuestro trabajo, mostramos que usando un simple paso
el control predictivo del modelo para planificar en los espacios latentes funciona sustancialmente mejor
que la planificación en un solo paso con un modelo de avance visual aprendido, tal vez porque el
los latentes aprenden a ignorar aspectos irrelevantes de las imágenes. Aunque la planificación
permite la extensión de la tela y la manipulación de la orientación de la cuerda, nuestros modelos fallan
para realizar manipulación de largo plazo ya que los modelos se entrenan fuera de línea
acciones aleatorias.
Para recapitular, presentamos cuatro documentos relacionados que presentan diferentes enfoques
para la manipulación robótica de las telas. Dos utilizan enfoques sin modelo (uno con
de refuerzo y uno con aprendizaje de imitación) y dos utilizan modelos basados en
enfoques de aprendizaje de refuerzo (ya sea con imágenes o variables latentes).
Basándonos en lo que hemos cubierto en esta entrada del blog, consideremos las posibilidades de
…el trabajo futuro.
Una opción es combinar estos métodos, como se ha hecho en trabajos recientes o concurrentes.
Por ejemplo, (Matas y otros, 2018) utilizaron el aprendizaje de refuerzo sin modelos
con aprendizaje de imitación (a través de demostraciones) para tareas de manipulación de telas.
También es posible añadir otras herramientas de la robótica y la visión por ordenador
literatura, como estrategias de estimación del estado para permitir una mejor
planificación. Otro posible instrumento podría ser descriptores de objetos densos
que indican correspondencia entre píxeles en dos imágenes diferentes. Para
ejemplo, hemos demostrado la utilidad de los descriptores para una variedad de cuerdas
y tareas de manipulación de tejidos.
Técnicas como el aprendizaje por imitación, el aprendizaje de refuerzo,
auto-supervisión, previsión visual, detección de profundidad, descriptores de objetos densos,
y en particular el uso de simuladores, han sido herramientas útiles. Creemos que
continuará jugando un papel cada vez más importante en la manipulación de tejidos por parte de los robots, y
podría ser usado para tareas más complejas como envolver artículos o ajustar la tela
a los objetos 3D.
Reflexionando sobre nuestro trabajo, otra dirección a explorar podría ser el uso de estos
métodos para entrenar el agarre de seis grados de libertad. Restringimos nuestra configuración a
políticas planas de recolección y colocación, y notaron que los robots a menudo tenían
dificultad con los agarres de arriba hacia abajo cuando las esquinas de la tela no estaban claramente expuestas.
En estos casos, los agarres más flexibles pueden ser mejores para suavizar o doblar.
Por último, otra dirección para el trabajo futuro es abordar los desajustes que
observado entre el rendimiento simulado y el rendimiento físico de la política. Esto puede deberse a
imperfecciones en los simuladores de tejido, y podría ser posible utilizar datos
del robot físico para afinar los parámetros de los simuladores de tejido para
mejorar el rendimiento.