
¿Considerando la posibilidad de construir una gran aplicación de flujo de datos? Has venido al lugar correcto. Este es un post completo sobre la arquitectura y orquestación de grandes tuberías de flujo de datos a escala industrial. Con una plétora de herramientas a su alrededor, puede rápidamente desconocer el número de herramientas y los posibles casos de uso y encajar en la arquitectura general. Personalmente he estado en una posición en la que he sentido que cada herramienta era igualmente eficiente, al menos eso es lo que sientes cuando lees su propia documentación. Al leer este post deberías ser capaz de entender los diversos componentes involucrados en la construcción de una tubería de flujo eficiente y deberías ser capaz de mapear las herramientas al componente de la arquitectura al que pertenece y evaluarlas con otras herramientas competitivas disponibles en el mercado.
Si estás buscando un ejemplo del mundo real, mira nuestro curso de desarrollo de chispas en el mundo real. Tenemos un proyecto de punta a punta Transmitiendo datos de Meetup.com con Kafka y Spark Streaming
¿Por qué Streaming?
Las empresas quieren obtener información lo más rápido posible y no quieren esperar un día, como antes, para hacer un informe para entender lo que pasó hasta ayer. Requieren un enfoque más proactivo que pueda ayudar a actuar de inmediato cuando algo significativo sucede y también para evitar que el sistema tenga algún fallo/tiempo de inactividad antes de que ocurra. Imagine que está comprando algún producto de un comercio electrónico y que ha llegado al punto de hacer el pago y algo sucedió que causó que el pago no se llevara a cabo con éxito. En ese mismo momento, usted está teniendo un segundo pensamiento acerca de si comprar el producto ahora o más tarde. Supongamos que si el negocio recibe un informe de este suceso al día siguiente, no les servirá de mucho ya que el cliente ya lo habrá comprado en algún lugar o se habrá decidido en contra. Aquí es donde entran en juego los acontecimientos y las percepciones en tiempo real. Si se tratara de un informe en tiempo real, el equipo habría llamado al cliente y realizado la compra ofreciéndole algunos descuentos, lo que a su vez habría hecho cambiar de opinión al cliente.
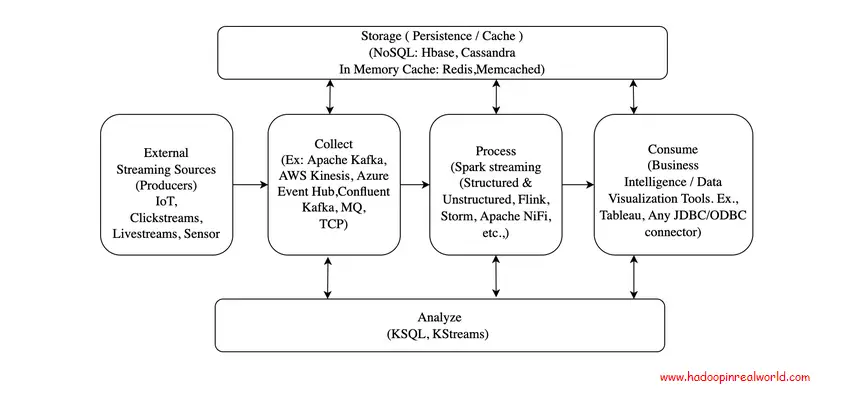
Arquitectura
Fuentes externas
Las fuentes externas son los productores de los eventos. Los eventos son hechos que han ocurrido. Los eventos son inmutables y cualquier cambio en el evento sería otro evento que se enviará después de este evento.
Algunos ejemplos de acontecimientos podrían ser:
- Transacciones como ATM/POS – que ocurrieron en un momento específico.
- Los cambios en las preferencias de alerta de los clientes se pueden capturar en tiempo real y luego, en consecuencia, se envían alertas o notificaciones.
- Las alertas y el seguimiento del correo se pueden hacer en tiempo real y las notificaciones se pueden enviar al cliente.
Recopila
La recolección es el primer y principal proceso en cualquier arquitectura de streaming. Los datos se recogen en la plataforma de streaming mediante el método llamado ingestión. Las colas se utilizan principalmente como un medio para recoger eventos.
Tecnologías
Hay pocas opciones de tecnología para elegir cuando recogemos datos. Aquí están las más destacadas.
Kafka
Kafka es una plataforma distribuida de código abierto de orquestación de eventos resistente que se utiliza ampliamente para capturar eventos en tiempo real. Kafka funciona con un patrón editor-suscriptor en el que los sistemas de origen pueden publicar eventos sobre el tema de Kafka a un ritmo constante y cualquier número de suscriptores puede suscribirse al tema en Kafka y procesar esos eventos. Desvincula tanto a los productores (editores) como a los suscriptores (consumidores), lo que permitirá que ambos actúen de forma independiente.
Colas de mensajes (MQ)
Los MQs son principalmente colas JMS que se usan para enviar eventos. La plataforma de streaming requeriría que un oyente se conectara al servidor MQ y sacara los mensajes. El establecimiento de un modo de transporte con sockets TCP es otro medio para enviar eventos. Este tipo de transporte de eventos es bastante común para las transacciones POS de los cajeros automáticos.
Kinesis del Amazonas
Amazon Kinesis es una oferta de streaming de eventos desde la nube de Amazon Web Services. Conceptualmente, tanto kafka como kinesis tienen muchas similitudes. Entre bastidores, la infraestructura es administrada por AWS y por lo tanto es altamente escalable y fiable para las fuentes que requieren interfaces de streaming de alto rendimiento como IoT, etc. AWS también ha lanzado recientemente AWS Managed Kafka para las empresas que quieran seguir con kafka pero en la nube.
El centro de eventos de Azure
El centro de eventos Azure es una gran plataforma de transmisión de datos y servicio de ingestión de eventos que ofrece Microsoft Azure. Azure Event Hub (AEH) puede recibir y procesar millones de eventos por segundo y tiene conexiones ricas en otros componentes de la infraestructura Azure. Los centros de eventos son componentes de la Plataforma como servicio (PAAS) totalmente administrados que sólo requieren una configuración menor y gastos de administración por parte de los clientes. Las industrias utilizan los centros de eventos para ingerir y procesar datos de transmisión si tienen Microsoft Azure.
Cosas a tener en cuenta
Implica una conexión de sistema a sistema. La latencia de la red, la tolerancia a los fallos se incorporará especialmente para el modo de comunicación TCP.
- Kafka transporta mensajes en formato de byte. La práctica de la industria consiste en transferir mensajes en formato Avro en Kafka y mantener el esquema de apoyo en el registro de esquemas para la evolución de los mismos.
- Si el componente de recolección no tiene una persistencia inherente como Kafka, entonces debe hacerse un almacenamiento explícito para evitar la pérdida de eventos.
Proceso
Los eventos/mensajes comerciales tal como están no pueden añadir valor a los clientes o consumidores finales. Los eventos implícitamente significan la ocurrencia de algo significativo desde la perspectiva empresarial.
Aplicaciones
En un proceso típico de solicitud de un préstamo hipotecario, se puede desencadenar un evento tan pronto como se apruebe/rechace la verificación de crédito de la solicitud. En el proceso de pago en línea, se puede desencadenar un evento si el cliente llegó al paso de pago o justo antes pero no ha completado el pago.
Los eventos mencionados son un acontecimiento significativo en el viaje del cliente desde el punto de vista de la aplicación. Estos desencadenarán diferentes conversaciones que las empresas necesitan tener con los clientes.
Tecnologías
Cada vez que se dispara un evento crudo desde el sistema de origen, debe someterse a los siguientes posibles pasos de procesamiento (no todo es obligatorio)
- Transformación: La transformación de los datos para ayudar en los pasos siguientes
- Enriquecimiento: Apoyando los datos de las búsquedas para enriquecer el evento.
- Motor de reglas: Un motor de reglas de negocios como Drools ayudará aquí a ejecutar las reglas.
- Persistencia: Evento persistente transformado/enriquecido y procesado para la auditoría
La lista que figura a continuación no es una lista exhaustiva de tecnologías, sino las principales que se utilizan para el procesamiento de corrientes:
Spark
Motor de procesamiento de corrientes y lotes distribuidos que funciona con microlotes de registros/eventos que deben ser procesados. Un rico conjunto de APIs disponibles y tiene librerías para el procesamiento de ML y de gráficos también. Arquitectura muy potente y el rendimiento de procesamiento es muy alto. Podría haber una latencia inherente debido a los micro lotes.
Flink
Un motor de procesamiento de corriente que es muy eficiente y de alto rendimiento. El Flink actúa en cada evento como y cuando ocurre y no en micro-lotes como la chispa. Por lo tanto, es muy eficiente y puede alcanzar una latencia inferior al segundo.
NiFi
El NiFi es un motor de transporte y procesamiento de datos configurable que presenta una bonita interfaz de usuario que tiene soporte para 100s de procesadores y conectores incorporados. Es fácil de desarrollar y puede construir tuberías de datos en minutos. El procesamiento pesado no puede hacerse como la chispa y el parpadeo y se utiliza principalmente en la industria para el procesamiento de peso ligero.
Cosas a tener en cuenta
- Consciente de la creación de múltiples objetos de conexión a las bases de datos, ya que puede ser rápidamente abrumador.
- Adherirse a los principios de diseño de software (SOLID) cuando se crean aplicaciones/servicios para permitir un acoplamiento suelto y mejorar la generalización.
- La optimización debe venir en una etapa posterior. Desarrollar para implementar funcionalidades y luego una vez que se identifiquen los cuellos de botella, concentrarse en la optimización.
Almacenamiento
El almacenamiento se convierte en crucial en la arquitectura de streaming tanto para escribir como para leer más rápido. Los eventos deben persistir en las etapas de la tubería para asegurarnos de que tenemos una pista de cómo los eventos fluyeron a través de la tubería. Supongamos que si el evento se cae por no pasar la regla, necesita ser capturado también para la auditoría.
Aquí se pueden pensar dos tipos de almacenamiento: la persistencia y el almacenamiento temporal.
Persistencia
La persistencia es el almacenamiento permanente de datos que pueden utilizarse para mantener un historial de acontecimientos y auditorías. Cualquier aplicación necesitará algún tipo de persistencia principalmente para el análisis histórico, el registro, la depuración y la auditoría. Sin la persistencia, no habrá ningún rastro de lo que pasó por el sistema y los datos no estarán disponibles para casos de uso futuro.
Tecnologías
Se utilizan principalmente para la persistencia, ya que están muy distribuidos y tienen una lectura y escritura más rápida. Las bases de datos NoSQL se evalúan en base al mecanismo CAP (Consistent, Availability and Partition Tolerance)
Hbase
Nativo del ecosistema Hadoop, altamente consistente en lectura y escritura rápida. La disponibilidad no es muy alta en HBase debido a su arquitectura de amo-esclavo.
Cassandra
Altamente distribuidos y eficientes y tienen lecturas y escritos más rápidos que HBase. Esto es eventualmente consistente a diferencia de HBase pero altamente disponible.
DynamoDB (AWS)
Oferta NoSQL de la nube AWS. AWS gestiona la infraestructura y se asegura de que la base de datos esté altamente disponible y sea consistente. Puede dar un rendimiento de recuperación de registros de milisegundos.
CosmosDB (Azul)
La oferta de NoSQL de Azure. Es similar al DynamoDB y altamente eficiente, y el mantenimiento de la infraestructura está a cargo de nosotros.
La elección de la base de datos NoSQL se reduce a los requisitos en términos de disponibilidad, coherencia y el rendimiento esperado. Además, la disponibilidad de conectores adecuados para interactuar con otros componentes del sistema marcará una gran diferencia durante esta selección.
Caching
El almacenamiento en memoria caché es un almacenamiento efímero que se sitúa encima de las bases de datos para permitir búsquedas muy rápidas de submilésimas de segundo en los oleoductos y gasoductos. El caching en memoria se utiliza principalmente para aliviar la carga de la base de datos especialmente para la lectura.
Tecnologías
Los principales casos de uso para el caching en memoria son: gestión de sesiones, caching de resultados de consultas, tabla de clasificación de juegos, los 10 mejores productos cada hora y así sucesivamente. edis y Memcached son populares, de código abierto, almacenes de datos en memoria. que están disponibles en el mercado.
Redis
Redis tiene un rico conjunto de características como la persistencia, pub-sub, estructuras de datos complejas, soporte geoespacial, etc., lo que hace que Redis sea adecuado para una mayor variedad de casos de uso aparte de los mencionados anteriormente como las sesiones pegajosas, permite la disociación entre los servicios a través de pub-sub, etc,
Memcached
El almacenamiento en memoria intermedia también es relativamente popular, pero se utiliza principalmente cuando las necesidades son sencillas y no se requieren estructuras avanzadas de datos. La página explica las diferencias en detalle entre los dos – https://aws.amazon.com/elasticache/redis-vs-memcached/
Cosas a tener en cuenta
- No lo use a menos que sea absolutamente necesario. Se utilizan especialmente para las tuberías de datos que tienen requisitos de latencia de submilisegundos.
- En la mayoría de los casos generales se podrá lograr un rendimiento sustancial con los almacenes de datos NoSQL.
- La modelización de los almacenes de datos es crucial – Asegurarse de que los datos puedan ser leídos rápidamente desde el almacén de datos y también fácilmente rastreables desde la capa de consumo hasta la fuente.
Analice
Tradicionalmente, el procesamiento en corriente ha consistido en reunir, procesar, evaluar un conjunto de reglas comerciales y enviarlo para su consumo en sistemas posteriores. Hay muy pocos conocimientos generados sobre la marcha. Con el advenimiento de nuevas herramientas que se discuten a continuación, el espacio de análisis de flujo se ha vuelto muy popular y se pueden generar poderosos análisis sobre la marcha. Las herramientas nos permiten escribir SQL sobre los datos de streaming independientemente del formato subyacente y pueden realizar análisis como agregaciones, uniones, cálculos en ventanas, etc,
Aplicaciones
Hay una gran variedad de aplicaciones para el análisis de la transmisión. Algunas de las predominantes son las siguientes:
Detección de anomalías
Detectar si hay alguna anomalía en el comportamiento del sistema que signifique fallos.
Tableros de KPI en tiempo real
Vigilancia operacional que ayuda a rastrear el desempeño en tiempo real.
Ataques de seguridad
Los ataques DDoS pueden ser rastreados en base a un gran volumen de solicitudes y pueden ser prevenidos.
Mercadeo dirigido
Analizar las preferencias de los clientes en tiempo real y utilizarlas para la comercialización dirigida.
Tecnologías
SparkSQL
El SparkSQL nos permite realizar cualquier consulta SQL sobre los flujos estructurados y escribirla en cualquier fregadero compatible. Los dataframes, que es la abstracción de alto nivel en el Spark, está optimizado para el rendimiento y tiene un rico conjunto de APIs para realizar análisis de streaming.
KSQL
KSQL está construido sobre KStreams por confluente y es ampliamente utilizado para escribir consultas SQL sobre flujos continuos en Kafka. KSQL tiene opciones para crear STREAM y TABLE. A continuación se muestran los ejemplos de STREAM y TABLE creados con el comando SQL.
Referencia KSQL – https://github.com/confluentinc/ksql/blob/0.1.x/docs/syntax-reference.md
Cosas a tener en cuenta
- Se deben tomar decisiones si los datos analizados son necesarios para el consumo en tiempo real. En otras palabras, ¿ese análisis constituye el camino crítico.
- La mayoría de las veces, la fase de análisis se desvía del camino crítico que ayudará a servir más casos de uso como los informes OLAP, los conocimientos históricos, etc,
- Dicho esto, podría haber casos de uso como la vigilancia en tiempo real de los ataques a la seguridad, la detección de fraudes, las anomalías en el comportamiento de los usuarios, etc., que sin duda tendrán un análisis en el camino crítico, ya que esa información es esencial para la toma de decisiones a tiempo.
Consumir
El consumo de datos de transmisión puede provenir de una amplia variedad de sistemas de transmisión, aparte de la notificación en tiempo real, los tableros y demás. Una vez introducidos los datos en el lago de datos, deben persistir en forma adecuada para el consumo y la consulta ad-hoc de las herramientas OLAP también para obtener conocimientos históricos.
Aplicaciones
Si el oleoducto está alimentando un sistema médico que detecta la presencia de ciertas enfermedades, entonces es imperativo tener todas las variables que el sistema está utilizando para tomar decisiones que se capturen tanto para el mejoramiento continuo como para propósitos de auditoría.
Tecnologías
El patrón preferido es tener los eventos crudos almacenados en el lago de datos y luego transformar los eventos en un modelo de datos aceptable y publicarlo en Datawarehouse para que las herramientas de BI como Tableau, Power BI, Business Objects o cualquier aplicación compatible con los drivers JDBC/ODBC consuman los datos. Esto asegurará que el viaje de los datos no termine tan pronto como el caso de uso del flujo se complete. Incluso si no hay una necesidad apremiante de almacenamiento en este punto, debería haber un plan para capturar esos eventos para no perderse conocimientos cruciales a través de cualquier herramienta de Inteligencia de Negocios.
Cosas a tener en cuenta
- Se debe conocer el patrón de consumo o de consulta para realizar una modelización eficiente de los datos
- Una buena práctica es reunir un montón de preguntas que querrían hacer a los datos, especialmente en el espacio de la OLAP, para ayudar a la modelización eficiente de los datos.
- Incluso si no hay detalles específicos disponibles, sería mejor tener supuestos generales y almacenar los datos en un lago de datos para que puedan ser utilizados en el futuro cuando surja el propósito.
Asegure
La seguridad es integral para cualquier plataforma de datos y mucho menos para el flujo de datos. En el mundo relacional, la seguridad está intrínsecamente incorporada en las bases de datos y los roles que tienen acceso a esas tablas e incluso los datos están encriptados en algunas formas para enmascarar la PII (Información de Identificación Personal). Pero en los lagos de datos, que son sistemas de archivos distribuidos masivamente, es muy importante asegurar el acceso a esos sistemas de archivos. La seguridad a nivel de fila es algo difícil de lograr, pero hay que tener cuidado de que no se proporcione un acceso general a ningún usuario del entorno.
Aplicaciones
Los instrumentos de seguridad en el entorno del Hadoop abordan las preocupaciones relacionadas con la autenticación, la autorización y la auditoría. La autenticación significa verificar que la persona es quien dice ser. La Autorización es lo que la persona es capaz de hacer en el entorno y la Auditoría es tener un seguimiento de cada acción realizada en el entorno. Los entornos Hadoop suelen estar habilitados por Kerberos para realizar la autenticación. La encriptación se realiza normalmente en los campos PII en reposo y sobre el cable el clúster Kerberos está aislado y será protegido de las peticiones maliciosas. Dos proyectos Apache de código abierto en el espacio de seguridad son – Knox y Ranger.
Tecnologías
Knox
El Apache Knox Gateway («Knox») proporciona seguridad perimetral para que la empresa pueda ampliar con confianza el acceso a Hadoop a más de esos nuevos usuarios, manteniendo al mismo tiempo el cumplimiento de las políticas de seguridad de la empresa. Apache knox se sitúa encima de kerberos y proporciona un patrón de acceso fácil para los clientes, eliminando la necesidad de una compleja configuración y autentificación de kerberos. Más detalles pueden ser encontrados aquí – https://www.cloudera.com/products/open-source/apache-hadoop/apache-knox.html.
Ranger
El Ranger es un sistema de gestión de autorizaciones que proporcionará un acceso de grano fino a los recursos del Hadoop como la Colmena, la HBase, el Hilo, etc., el Ranger asume que el usuario está autentificado para acceder al cúmulo y controla la pieza de autorización del rompecabezas. La autorización es importante, ya que determinará a qué pueden acceder los usuarios, incluso si están autenticados en el grupo. Las políticas de los Rangers ayudan a especificar controles de acceso de grano fino para restringir cada uno de los recursos dentro del clúster para determinados usuarios/cuentas de servicio.
Cosas a tener en cuenta
- Segregación de entornos a través de espacios de nombres – Desarrollo, SIT y PROD
- Implementar funciones que puedan proporcionar un acceso de grano fino a nivel de la mesa.
- Hay que tener cuidado de que haya un acceso mínimo para hacer los deberes.
- Cifrado de la información sensible a través de la política de cifrado de toda la empresa.
- No se replican los datos de producción en el entorno de desarrollo.
- Las pruebas de rendimiento y de carga deben realizarse en un entorno separado y seguro una vez que las pruebas de funcionalidad se realizan en los entornos inferiores.
¡Está bien! Ahora tienes toda la información que necesitas para elegir las herramientas adecuadas y diseñar una arquitectura adecuada para construir una aplicación de streaming lista para la producción.