
Shuffle Hash Join, como el nombre indica funciona barajando ambos conjuntos de datos. Así que las mismas claves de ambos lados terminan en la misma partición o tarea. Una vez que se barajan los datos, el más pequeño de los dos se agrupa en cubos y se realiza una unión de hash dentro de la partición.
Shuffle Hash Join es diferente de Broadcast Hash Join porque el conjunto de datos completo no se transmite en su lugar ambos conjuntos de datos se barajan y luego los datos del lado más pequeño se mezclan y se unen con el lado más grande en todas las particiones.
El Shuffle Hash Join se divide en 2 fases.
Fase de barajado – ambos conjuntos de datos están mezclados
Fase de unión de Hash – Los datos de los lados pequeños se mezclan y se unen con los de los lados grandes en todas las particiones.
No es necesario clasificar con Shuffle Hash Joins dentro de los tabiques.
Ejemplo
spark.sql.join.preferSortMergeJoin debe estar en false y spark.sql.autoBroadcastJoinThreshold debe estar en un valor menor para que Spark pueda elegir usar Shuffle Hash Join sobre Sort Merge Join.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
scala> chispa.conf.set(«spark.sql.autoBroadcastJoinThreshold», 2) scala> chispa.conf.set(«chispa.sql.join.preferSortMergeJoin», «falso») scala> chispa.conf.consigue(«chispa.sql.join.preferSortMergeJoin») res2: Cuerda = falso scala> chispa.conf.consigue(«spark.sql.autoBroadcastJoinThreshold») res3: Cuerda = 2 scala> val datos1 = Seq(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50) datos1: Seq[[Int] = Lista(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50) scala> val df1 = datos1.toDF(«id1») df1: org.apache.chispa.sql.DataFrame = [[id1: int] scala> val datos2 = Seq(30, 20, 40, 50) datos2: Seq[[Int] = Lista(30, 20, 40, 50) scala> val df2 = datos2.toDF(«id2») df2: org.apache.chispa.sql.DataFrame = [[id2: int] scala> val dfJoined = df1.unirse a(df2, $«id1» === $«id2») dfJoined: org.apache.chispa.sql.DataFrame = [[id1: int, id2: int] |
Cuando vemos el plan que se ejecutará, podemos ver que se utiliza ShuffledHashJoin.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
scala> dfJoined.queryExecution.executedPlan res4: org.apache.chispa.sql.ejecución.SparkPlan = ShuffledHashJoin [[id1#3], [id2#8]Interior, BuildRight… :– Intercambio hashpartitioning(id1#3, 200) : +– LocalTableScan [[id1#3] +– Intercambio hashpartitioning(id2#8, 200) +– LocalTableScan [[id2#8] scala> dfJoined.mostrar +—–+—–+ |id1|id2| +—–+—–+ | 20| 20| | 20| 20| | 40| 40| | 40| 40| | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 50| 50| | 30| 30| +—–+—–+ |
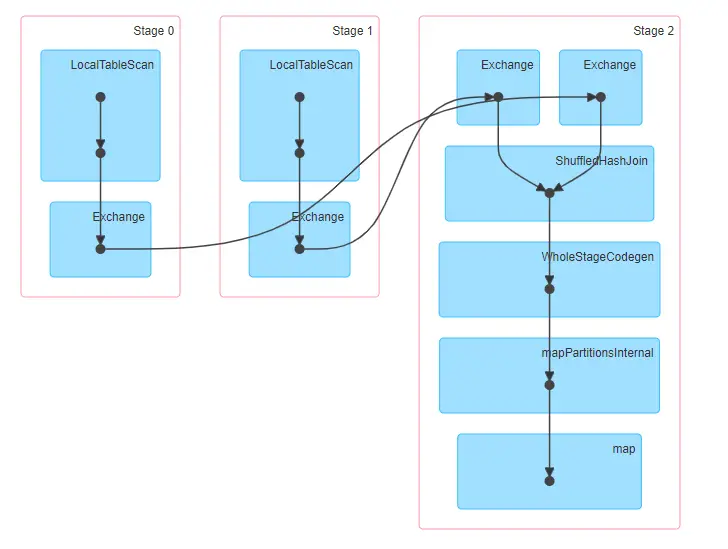
Las etapas involucradas en Shuffle Hash se unen
Como podemos ver a continuación, se necesita una barajadura con Shuffle Hash Join. El primer conjunto de datos se lee en la Etapa 0 y el segundo conjunto de datos se lee en la Etapa 1. La etapa 2 de abajo representa la barajadura.
Funcionamiento interno de Shuffle Hash Join
Hay 2 fases en una unión de Hash Shuffle – fase de Shuffle y fase de unión de Hash.
Fase de barajado
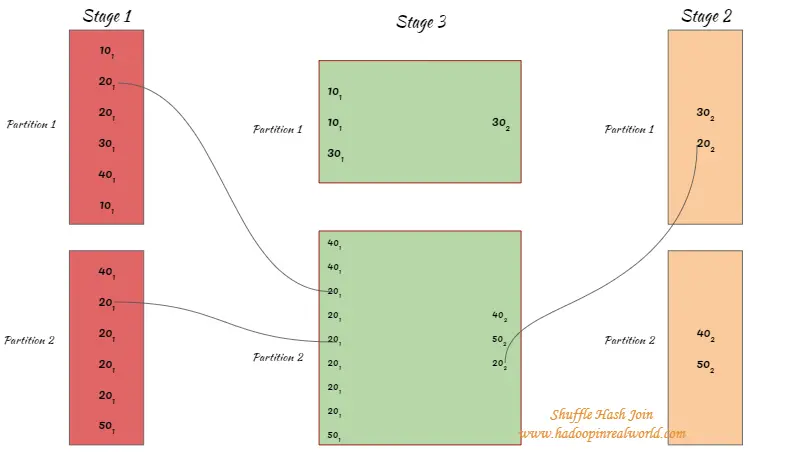
Los datos de ambos conjuntos de datos se leen y se mezclan. Después de la operación de barajado, los registros con las mismas claves de ambos conjuntos de datos terminarán en la misma partición después del barajado. Tenga en cuenta que el conjunto de datos completo no se emite con esta unión. Esto significa que el conjunto de datos de cada partición tendrá un tamaño manejable después de la barajadura.
Hash Join
- Después de la barajadura, Spark escoge un lado basado en las estadísticas y lo va a meter en cubos…
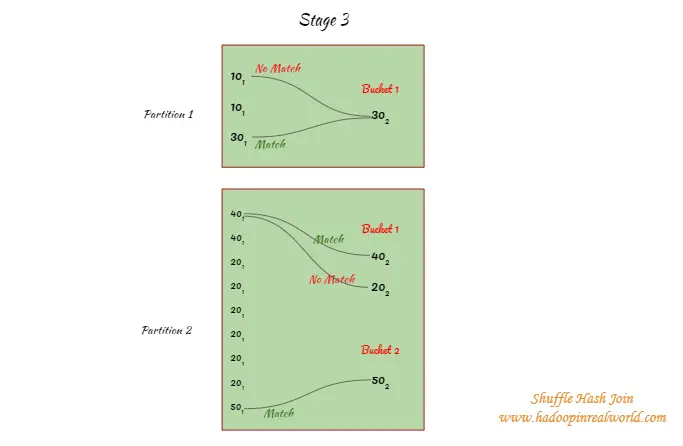
- En el siguiente ejemplo, tenemos 2 particiones y el lado 2 es un piquete para el hashing y será asignado a los cubos. Hay un cubo en la partición 1 con la llave 20. La partición 2 tiene 2 cubos 20 y 40 están asignados al cubo 1 y 50 asignados al cubo 2.
- Las claves del gran conjunto de datos se intentarán hacer coincidir SOLAMENTE con los respectivos cubos. Por ejemplo, en la partición 1 cuando el valor hash de 101 resulta en cualquier otra cosa que no sea el cubo 1 un partido no se intentará. En la partición 2, 401 sólo se intentará hacer coincidir con las llaves del cubo 1 y no con el cubo 1 porque el 401 se apresura a la cubeta 2.
- La unión del hash se realiza a través de todas las particiones después de la barajadura.
La clasificación no es necesaria para los Shuffle Hash Joins.
¿Cuándo funciona el Shuffle Hash Join?
- Es más rápido que una fusión de clases, ya que la clasificación no está involucrada.
- Funciona sólo para las uniones equi
- Funciona para todos los tipos de unión
- Funciona bien cuando un conjunto de datos no puede ser transmitido, pero un lado de los datos divididos después de barajar será lo suficientemente pequeño para la unión de hachís.
¿Cuando el Shuffle Hash Join no funciona?
- No funciona para las uniones no equi
- No funciona con datos muy sesgados. Digamos que nos unimos a un conjunto de datos de ventas en la clave de producto. Es posible que el conjunto de datos tenga un número desproporcionado de registros para una cierta clave de producto. La barajadura resultará en el envío de todos los registros de esta clave de producto a una sola partición. Si se mezclan todos los registros de esta clave de producto dentro de una sola partición, se producirá una excepción de «Fuera de la memoria». Así que la unión del hash barajado funcionará para un conjunto de datos equilibrado pero no para un conjunto de datos sesgados.