
ksqlDB es una base de datos de transmisión de eventos que permite crear potentes aplicaciones de procesamiento de flujos sobre Apache Kafka mediante el uso de la conocida sintaxis SQL, que se denomina KSQL. Este es un concepto poderoso que abstrae del usuario gran parte de la complejidad del procesamiento de flujos. Los usuarios comerciales o analistas con conocimientos de SQL pueden consultar las complejas estructuras de datos que pasan por kafka y obtener información en tiempo real. En este artículo, vamos a ver cómo configurar el ksqlDB y también veremos conceptos importantes en el ksql y su uso.
El razonamiento detrás de la evolución del KSQL
Apache Kafka es el software de procesamiento de flujo de código abierto más popular que ayuda a proporcionar plataformas unificadas de alto rendimiento y baja latencia para el transporte y la manipulación de los flujos en tiempo real. La analítica de flujos es un método para analizar los flujos a medida que fluyen a través de kafka usando la lógica de negocios y obtener información en tiempo real.
Algunas de las aplicaciones podrían ser tableros de operaciones de vigilancia en tiempo real que muestren los indicadores clave de rendimiento (KPI), el comportamiento de compra de los clientes para enviar ofertas promocionales a sus hogares para realizar compras frecuentes, recompensas por fidelidad si el cliente ha superado un umbral de compras durante un número determinado de veces en una ventana de tiempo y mucho más.
Apache Kafka Streams (escrito en Java o Scala) fue bastante popular en la construcción de aplicaciones de análisis de streaming, pero requiere conocimientos de programación y por lo tanto bastante distantes para la gente que querría usar SQL. KSQL salva esta brecha al exponer una interfaz SQL familiar, que puede ser utilizada por una amplia audiencia, pero entre bastidores convierte la aplicación KSQL a Kafka Streams automáticamente y hace todo el trabajo duro.
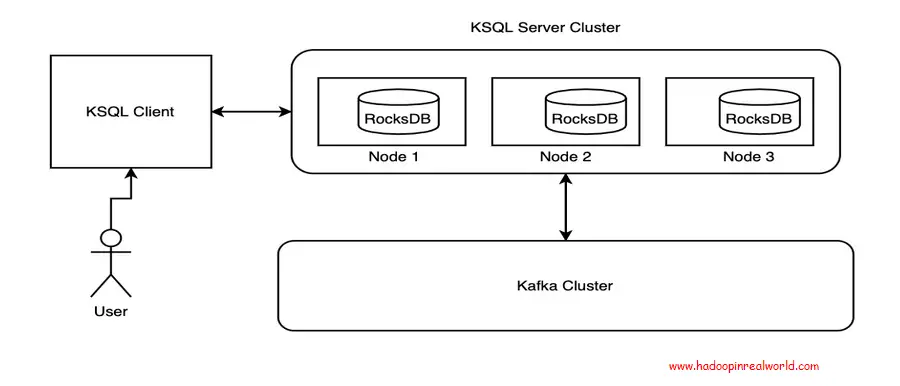
Arquitectura de referencia
El cliente KSQL proporciona una interfaz de línea de comandos para interactuar con el clúster de servidores KSQL. El Servidor KQL gestiona la interacción con el tema kafka para obtener los eventos como y cuando se produce y llega a kafka. El almacén de estados se mantiene dentro de cada nodo donde los estados se mantienen en base a la clave y se distribuyen a través de los nodos. Aprenderemos sobre cada uno de esos componentes a lo largo del resto de las secciones.
Ejemplo de configuración del entorno
El primer paso para empezar a usar el ksqlDB es configurarlo en su máquina local.
- Visite https://www.confluent.io/product/ksql/ y descargue la plataforma del confluente.
- Descargar interfaz de línea de comando confluente: curl -L https://cnfl.io/cli | sh -s – -b
- Asegúrate de que el directorio bin instalado se agregue a $PATH.
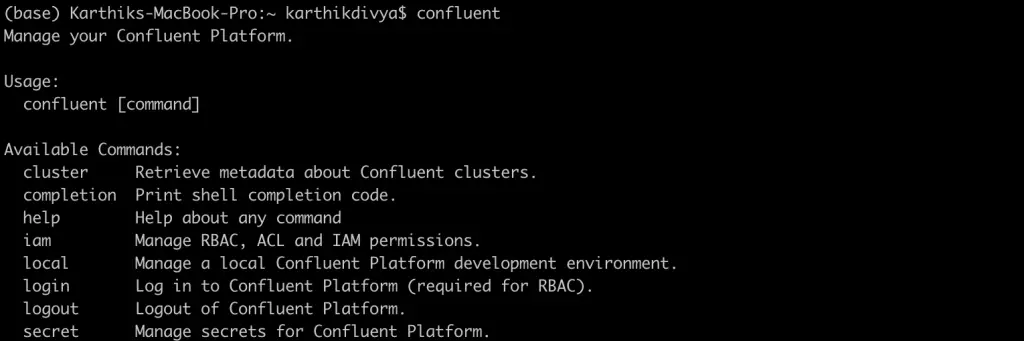
- Una vez instalado con éxito, teclee confluente en terminal y debería ver abajo
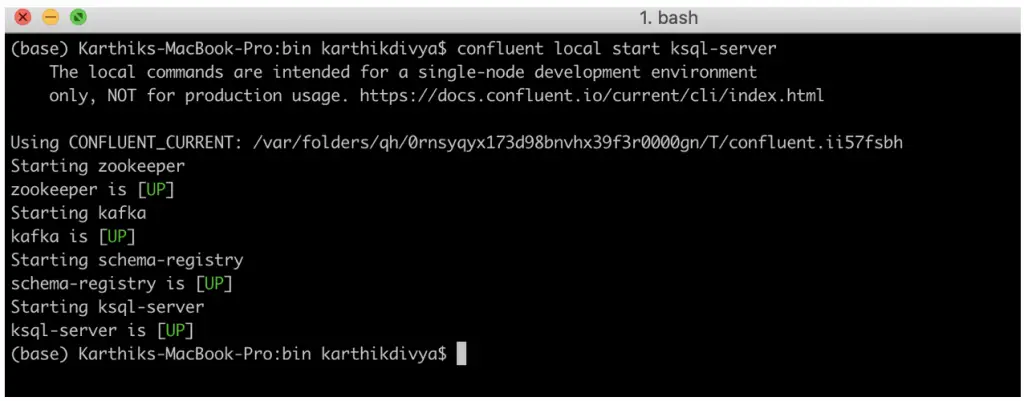
Una vez completados los pasos anteriores, estáis listos para continuar vuestra aventura con ksqlDB. El servidor confluente puede ser iniciado usando el comando:
confluente local iniciar ksql–servidor
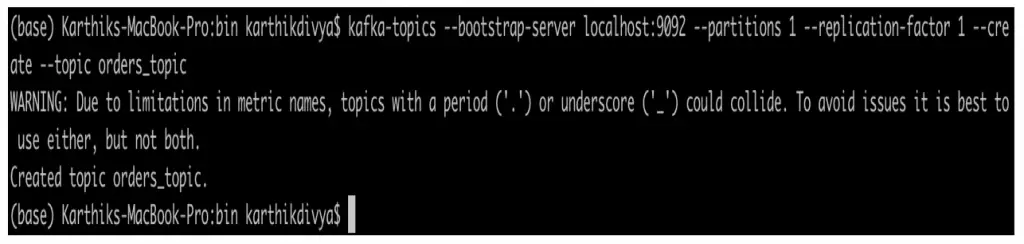
Ejemplo de comando para crear un nuevo tema de kafka
|
kafka–temas —bootstrap–servidor localhost:9092 —particiones 1 —réplica–factor 1 —crear —tema tema de las órdenes |
KSQL-Datagen
KSQL-Datagen es una poderosa utilidad generadora de datos que se envía con la plataforma confluente que se descargó en la sección anterior. Esto ayuda a crear datos basados en el esquema definido por nosotros y sería una herramienta útil para generar datos aleatorios para el desarrollo y las pruebas.
Para el resto del artículo, vamos a ver dos conjuntos de datos: los pedidos y los clientes.
Imaginemos que tenemos una tienda online en la que se hacen pedidos continuamente y los detalles que capturamos están abajo (para simplificar). La información del pedido contiene el identificador único del pedido, el nombre del cliente, la fecha de compra (formato de sello de tiempo único), la cantidad total y el número de artículos comprados.
|
{«id»:1009,«nombre personalizado»:«Peter»,«fecha»:1588907310,«cantidad»:1144.565,«item_quantity»:26} |
La información del cliente que se captura como abajo. La información del cliente contiene el nombre del cliente, el país y el estado del cliente.
|
{«nombre personalizado»:«Peter», «país»: «AUSTRALIA», «tipo_de_cliente»: «PLATINO»} |
Carga de datos
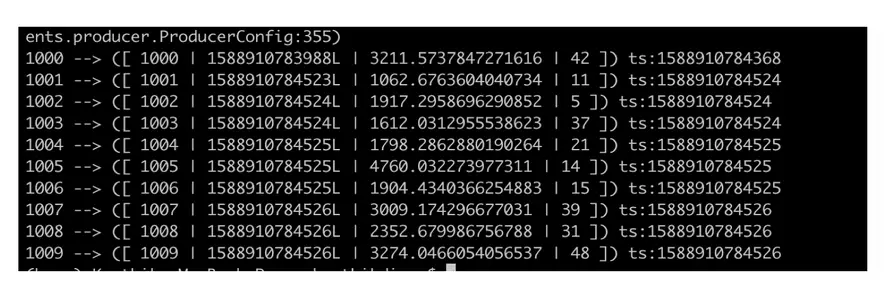
Podemos usar el comando ksql-datagen de abajo para generar las órdenes por nosotros:
|
ksql–datagen esquema=./blog/datagen/órdenes.avro formato=avro tema=órdenes clave=id maxInterval=5000 iteraciones=10 |
Los parámetros del comando se explican a continuación:
|
Esquema: Esquema a consulte a a generar datos Formato: Formato de el salida Tema: Tema a producir datos a Clave: Clave para el datos MaxInterval: Frecuencia intervalo entre cada uno datos generada Iteraciones: Número de registros a generar. |
Código y conjunto de datos
El código, los comandos y las consultas utilizados en este post están disponibles en el enlace github aquí
El archivo commands.md contiene todos los comandos, código y consultas usados a lo largo de este artículo. La carpeta blog/datagen contiene los archivos de esquema orders.avro y clients.avro que se utilizan mientras la utilidad ksql-datagen intenta generar los datos de muestra. Por favor, siéntete libre de manipular el esquema para generar diferentes registros.
Si estás disfrutando de este post, también puedes estar interesado en aprender sobre Registro del esquema de Kafka y evolución del esquema
Corrientes
El ksqlDB tiene el concepto de corrientes. El ksqlDB opera sobre el tema subyacente del kafka y los datos que vienen a través de él. Las corrientes pueden pensarse como la capa que se extiende sobre el tema kafka con el esquema definido de los datos que se esperan en el tema. Una vez que esta corriente se registra con ksqlDB, podemos empezar a consultar la corriente con la sintaxis KSQL y empezar a recopilar información de la misma.
Crear un tema con el nombre «órdenes»
|
kafka–temas —cuidador del zoológico localhost:2181 —particiones 1 —réplica–factor 1 —crear —tema órdenes |

Escriba «ksql» desde la línea de comandos para lanzar el cliente ksql. Debería ver el símbolo del sistema ksql> como se indica a continuación y luego escriba el siguiente comando para ver la lista de temas

Crear un flujo con el nombre «flujo_de_órdenes» con el siguiente comando
|
CREAR STREAM flujo_de_órdenes(id INT, nombre personalizado VARCHAR, fecha BIGINT, cantidad DOBLE, item_quantity INT) CON (FORMATO DE VALOR=JSON, KAFKA_TOPIC=«órdenes) |

En ksql prompt, escriba «lista de corrientes;» para ver la lista de corrientes que están disponibles actualmente.

El comando «CREATE STREAM» se utiliza para registrar el flujo con el esquema especificado y también menciona el tema que el flujo debe escuchar. Una vez que está todo listo, podemos empezar a girar algunas consultas de ksql encima de él para escuchar los análisis en tiempo real !
¿Por qué no hacemos la siguiente consulta para identificar la información agregada del pedido en términos de cantidad total de compra por cliente y el número de artículos comprados cada día? Esto nos dará una visión en tiempo real de las compras de los clientes y probablemente podamos ofrecer algunos descuentos en el momento!!
|
SELECCIONE nombre personalizado,TIMESTAMPTOSTRING(fecha, «dd/MMM) AS fecha_de_compra, SUM(cantidad) AS cantidad_total, SUM(item_quantity) DE flujo_de_órdenes GRUPO POR nombre personalizado, TIMESTAMPTOSTRING(fecha, «dd/MMM) emiten cambios; |
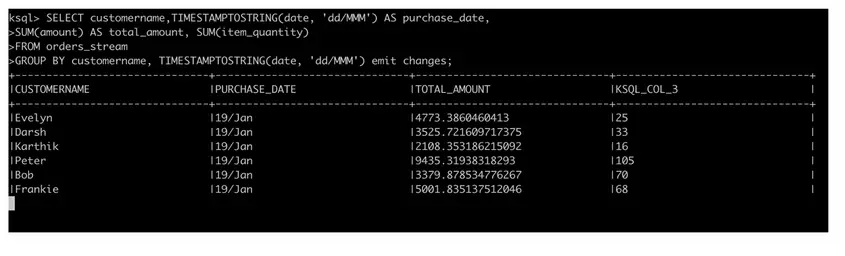
Como puede ver, la consulta ksql anterior se parece a la típica consulta SQL que usamos para consultar tablas relacionales. Un cambio sería el «emitir cambios» en sintaxis. A partir de la versión reciente de la plataforma confluente, es necesario utilizar «emitir cambios» como parte de la sintaxis. Todas las consultas deben terminar con un punto y coma.
En el indicador ksql, escriba la consulta ksql mencionada anteriormente
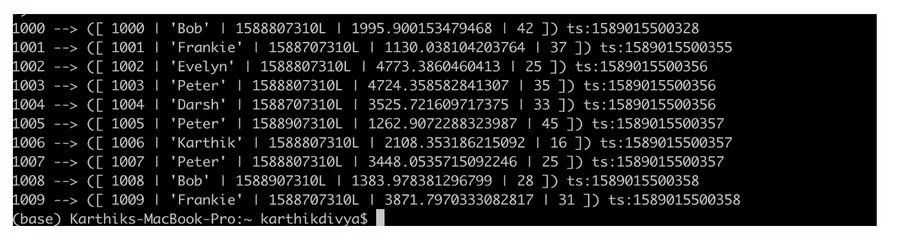
Tomemos la ayuda de nuestro ksql-datagen para generar algunos datos al tema de nuestras órdenes
|
ksql–datagen esquema=./blog/datagen/órdenes.avro formato=json tema=órdenes clave=id maxInterval=5000 iteraciones=10 |
Tablas
Habiendo mirado las corrientes en la sección anterior, sería el momento adecuado para mirar las Tablas en ksql. Sí, significa lo mismo que las tablas relacionales. Las tablas se utilizan para almacenar información de estado en la base de datos incorporada de ksqlDB – RocksDB. RocksDB persiste los datos en el disco en un formato de consulta local. Los datos que persisten estarán disponibles y distribuidos en todos los nodos del clúster de ksql en base a la clave. Por lo tanto, los datos no serán borrados o eliminados una vez que los mensajes/eventos sean emitidos desde el tema kafka subyacente. Para mirar el directorio donde los datos son perseguidos, escriba «listar propiedades;» en ksql indicar y navegar a la propiedad – ksql.streams.state.dir. Este es el directorio en el que se persigue la información de estado. Nunca manipule este directorio ya que puede corromper la base de datos.

Mediante el uso de tablas, podemos hacer consultas de estado que pueden buscar en la tabla para obtener información adicional para proporcionar una mayor comprensión a medida que los datos fluyen a través del tema de forma continua.
Tenemos la información del cliente con nosotros. Asumamos que el estado del cliente, que podría ser PLATA, ORO y PLATINO, cambia continuamente basado en el comportamiento de compra y queremos mantener la información del estado en una tabla.
Comencemos el simulacro con la creación de un tema
|
kafka–temas —cuidador del zoológico localhost:2181 —particiones 1 —réplica–factor 1 —crear —tema clientes |

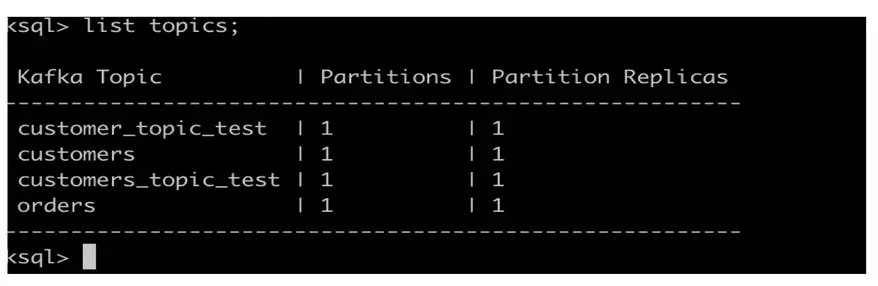
Escriba “
lista temas; ” en ksql se pide que se enumeren los temas disponibles en ksqlDB.
El comando «CREAR TABLA» se usa para crear tablas y el comando se ve similar al comando CREAR STREAM pero es mejor mencionar la tecla de fila en el comando de creación de tablas para ser explícito. Recuerde que la clave de fila debe coincidir con una de las columnas presentes.
|
CREAR TABLA tabla_de_clientes(nombre personalizado VARCHAR, país VARCHAR, tipo_de_cliente VARCHAR) CON (FORMATO DE VALOR=JSON, KAFKA_TOPIC=«clientes, CLAVE=‘nombre personalizado’…); |

Escriba lo siguiente en ksql prompt
|
SELECCIONE nombre personalizado, país, tipo_de_cliente de tabla_de_clientes emiten cambios; |
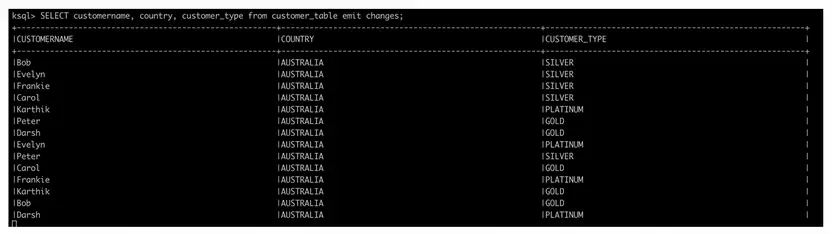
Usemos nuestro ksql-datagen para encender algunos datos de clientes para nosotros y girar la consulta ksql para escuchar esos datos.
|
ksql–datagen esquema=/Usuarios/karthikdivya/Escritorio/Personal/Udemy/KSQL/blog/datagen/clientes.avro formato=json tema=prueba_de_clientes clave=nombre personalizado maxInterval=10000 iteraciones=10 |
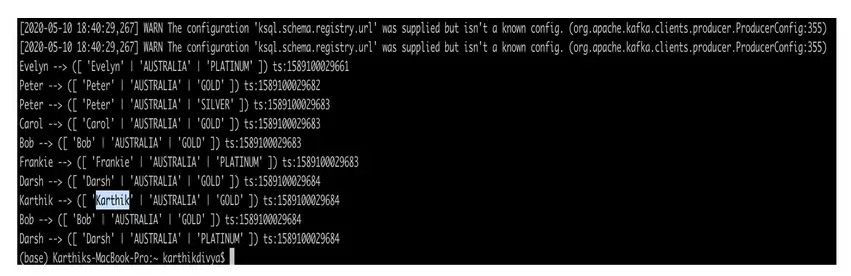
A medida que se empiezan a enviar los datos generados a través del ksql-datagen al tema, la tabla debería empezar a mostrar la información. La información de estado se persigue continuamente en la tabla en base a la clave de fila que puede ser consultada en cualquier momento.
Corrientes vs. Tablas
La pregunta típica que surge en este punto sería cuándo usar lo que como ambos luce sintácticamente similar. Tanto los arroyos como las mesas son envoltorios alrededor del tema del kafka, como has visto. Creamos un tema de kafka y empujamos los mensajes a través de él para que se consuma a través de corrientes o tablas.
Los arroyos son ilimitados e inmutables. Funcionan con un flujo continuo de datos en el tema de kafka y los nuevos datos se añaden continuamente a la corriente y los registros existentes no se modifican. En otras palabras, las corrientes operan con datos en movimiento. Un caso típico de uso sería alimentar el tablero operativo en tiempo real y mantenerlo actualizado con los nuevos acontecimientos.
Las tablas son limitadas y mutables. Funcionan con datos en reposo, con la tecla de fila de la tabla actualizándose con el último valor de los eventos que se producen en el tema de kafka. Si la clave ya está presente, entonces el valor se actualiza, de lo contrario la nueva clave se insertará en la tabla.
Se une a
Vimos tanto corrientes como tablas y cómo somos capaces de escribir poderosas consultas agregadas sobre los datos de las corrientes para obtener poderosas percepciones sobre la marcha. Una de las características más poderosas de SQL es JOINS. JOINS nos permite relacionar múltiples tablas que serán necesarias para obtener información más rica. ¿De qué servirá si no tenemos la capacidad de JOIN en ksql? Afortunadamente, no tenemos que preocuparnos ya que tenemos uno en KSQL.
Unamos nuestra corriente y mesa y emitamos la información combinada. Así podremos obtener la ubicación y el estado del cliente, así como la información del pedido.
Consulta Ksql que une el flujo de pedidos y la mesa de clientes
|
SELECCIONE cliente.nombre personalizado, cliente.país, cliente.tipo_de_cliente como estado_del_cliente,TIMESTAMPTOSTRING(ordena.fecha, «dd/MMM) AS fecha_de_compra, SUM(ordena.cantidad) como cantidad_total, SUM(ordena.item_quantity) como cantidad_total DE flujo_de_órdenes como ordena IZQUIERDA ÚNETE A tabla_de_clientes como cliente EN ordena.nombre personalizado = cliente.nombre personalizado GRUPO POR cliente.nombre personalizado, cliente.país, cliente.tipo_de_cliente, TIMESTAMPTOSTRING(ordena.fecha, «dd/MMM) emiten cambios; |
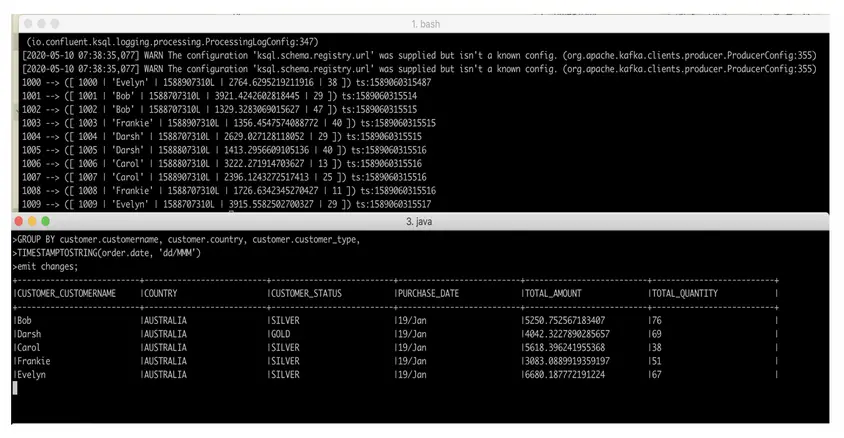
Iniciemos nuestro flujo de órdenes y enviemos algunos datos a través de ksql-datagen usando un comando similar al anterior:
|
ksql–datagen esquema=/Usuarios/karthikdivya/Escritorio/Personal/Udemy/KSQL/blog/datagen/órdenes.avro formato=json tema=órdenes clave=id maxInterval=5000 iteraciones=10 |
Conclusión
El artículo debería haberle dado una buena visión general sobre el ajuste del ksql, las aplicaciones, el montaje y los conceptos y construcciones importantes. El post es muy práctico y te recomendaría que siguieras el enlace de github para descargar el código y probarlo por tu cuenta usando diferentes conjuntos de datos para conseguir una buena comprensión. En general, KSQL es bastante popular en el espacio de análisis de streaming y tiene una amplia variedad de funciones incorporadas. Les recomendaría a todos que echen un vistazo a la documentación oficial del confluente en KSQL – https://docs.confluent.io/4.1.0/ksql/docs/index.html#ksql-documentation