
Imagina que queremos entrenar a un coche de auto-conducción en Nueva York para que podamos llevarlo todo el camino hasta Seattle sin conducirlo tediosamente durante más de 48 horas. Esperamos que nuestro coche puede manejar todo tipo de entornos en el viaje y nos envía de forma segura a el destino. Sabemos que las condiciones de la carretera y las vistas pueden ser muy diferentes.
Es intuitivo recoger simplemente los datos de la carretera de este viaje, dejar que el coche aprenda de todas las condiciones posibles, y espero que se convierta en el perfecto autoconductor
para nuestro viaje de Nueva York a Seattle. Necesita entender el tráfico y rascacielos en grandes ciudades como Nueva York y Chicago, un clima más impredecible en Seattle, montañas y bosques en Montana, y todo tipo de vistas del campo, tierras de cultivo, animales, etc. Sin embargo, ¿cuántos datos son suficientes? ¿Cuántas ciudades ¿deberíamos recoger datos de…? ¿Cuántas condiciones climáticas deberíamos considerar? Nosotros nunca se sabe, y estas preguntas nunca se detienen.
Figura 1: Los límites de los dominios raramente son claros. Por lo tanto, es difícil establecer descripciones de dominio definitivas para todos los dominios posibles.
En cuanto al clima, el número de condiciones diferentes puede ser infinito, mientras que
las palabras que se pueden usar para describir las condiciones climáticas (como soleado y
lluvioso) son siempre limitados. Algunas condiciones tienen sutiles diferencias que incluso
los humanos no pueden saberlo. Por ejemplo, el nublado v.s. nublado, el estado de transición de
lluvioso a no lluvioso, nieve ligera v.s. lluvia ligera, etc. Siempre podemos intentar
recoger datos para cada posible condición meteorológica que podamos imaginar y utilizar
los métodos tradicionales de adaptación de dominios para ayudar a nuestro coche a adaptarse a estos
condiciones. Pero nuestra imaginación es limitada cuando se trata del clima, y la
La razón principal es que no hay límites claros entre las condiciones climáticas.
En ese caso, ninguno de los enfoques tradicionales de adaptación de dominios, donde se
se asumen los límites, puede ayudarnos en la adaptación al clima del mundo real. Por lo tanto,
empezamos a repensar el aprendizaje automático y los sistemas de adaptación de dominios, e intentamos
introducir un protocolo de aprendizaje continuo en el escenario de adaptación de los dominios.
El objetivo de la adaptación del dominio es adaptar el modelo aprendido en la capacitación
a los datos de prueba de una distribución diferente. Tal brecha distributiva es
a menudo formulado como un cambio entre conceptos discretos de datos bien definidos
por ejemplo, las imágenes recogidas en tiempo soleado frente a las de tiempo lluvioso.
Aunque la generalización de los dominios y la adaptación de los dominios latentes han intentado
abordan dominios objetivos complejos, la mayoría de los trabajos existentes suelen asumir que hay
una clara distinción conocida entre los dominios. Tal distinción conocida y clara
entre dominios es difícil de definir en la práctica, por ejemplo, las imágenes de prueba podrían ser
recogidas en un clima mixto, continuamente variable, y a veces nunca visto
condiciones. Con numerosos factores que contribuyen conjuntamente a la variación de los datos, se
se vuelve improbable separar los datos en dominios discretos.
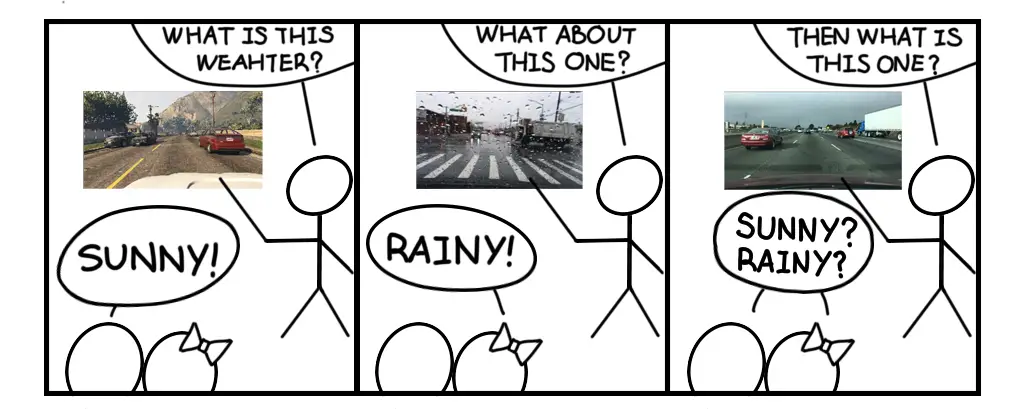
Nos proponemos estudiar Adaptación del dominio compuesto abierto (OCDA)un continuo…
y un escenario más realista para la adaptación del dominio (Figura 2). La tarea es
aprender un modelo a partir de los datos del dominio de la fuente etiquetada y adaptarlo a los datos no etiquetados
datos compuestos del dominio de destino que podrían diferir del dominio de origen en
varios factores. Nuestro dominio objetivo puede considerarse como una combinación de múltiples
dominios tradicionalmente homogéneos donde cada uno es distintivo en uno o dos grandes
factores, y sin embargo no se da ninguna de las etiquetas del dominio. Por ejemplo, los cinco
conocidos conjuntos de datos sobre reconocimiento de dígitos (SVHN, MNIST, MNIST-M, USPS, y
SynNum) se diferencian principalmente por los fondos y las fuentes de texto. Es
no es necesariamente la mejor práctica, y no es factible en algunos escenarios, para
los consideran como dominios distintos. En cambio, nuestros grupos de dominios de destino compuestos
…que están juntos. Además, en la etapa de inferencia, la OCDA prueba el modelo no
sólo en el dominio de destino compuesto, pero también en los dominios abiertos que tienen
que no se había visto antes durante el entrenamiento.
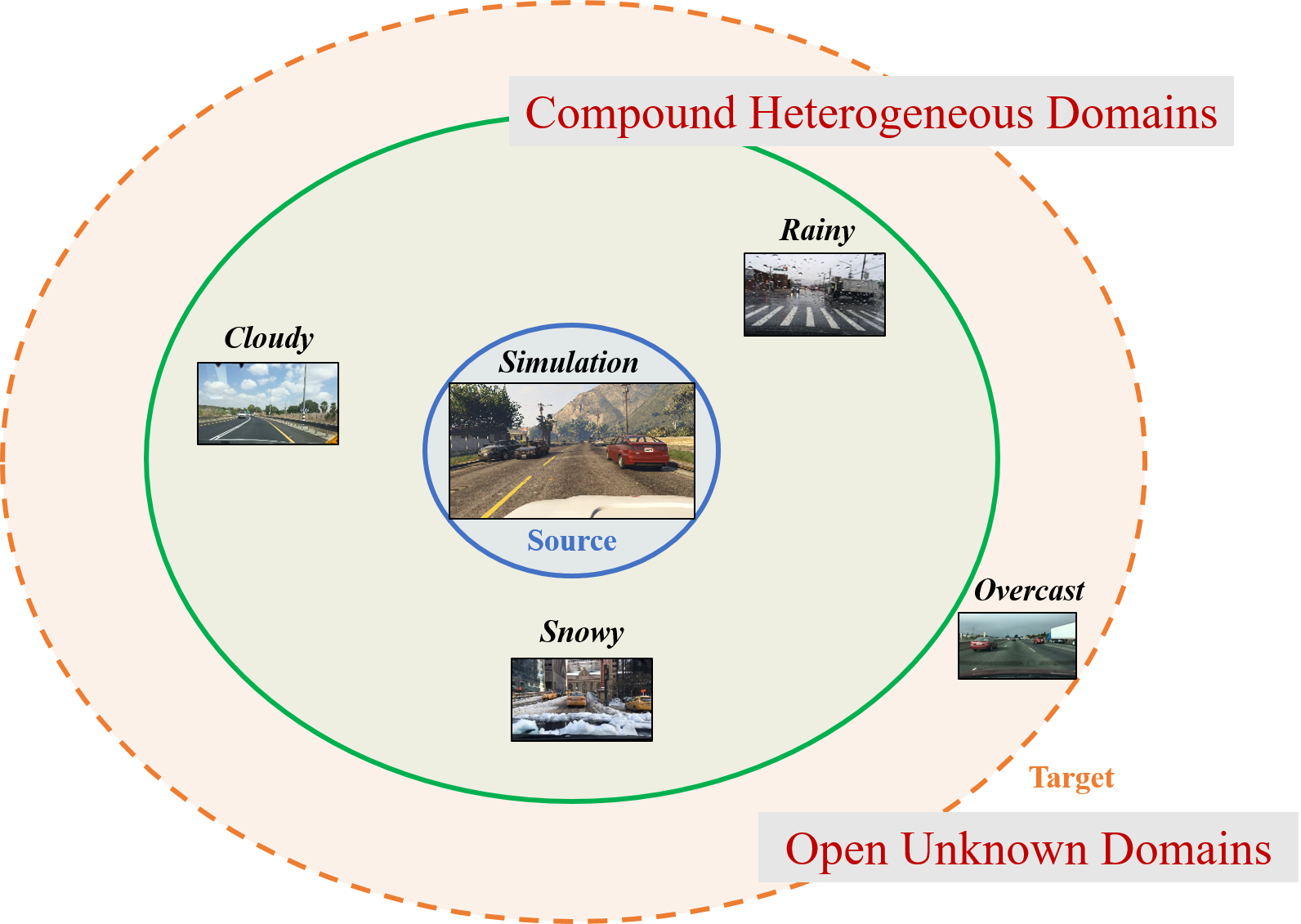
Figura 2: Adaptación del dominio compuesto abierto problema. A diferencia de los existentes
adaptación de los dominios que supone una clara distinción entre los dominios discretos,
nuestro dominio objetivo compuesto es una combinación de múltiples tradicionalmente
dominios homogéneos sin ninguna etiqueta de dominio. También permitimos que los nuevos dominios
aparecen en el momento de la inferencia.
Mientras que el OCDA no ha sido definido en la literatura, hay dos estrechamente
tareas relacionadas que a menudo se estudian de forma aislada: el dominio de un solo objetivo
y la adaptación de los dominios multiobjetivo. La figura 3 resume su
diferencias. La recién propuesta Adaptación del Dominio Compuesto Abierto (OCDA) sirve
como una piedra de toque más completa y más realista para evaluar el dominio
sistemas de aprendizaje de adaptación y transferencia.
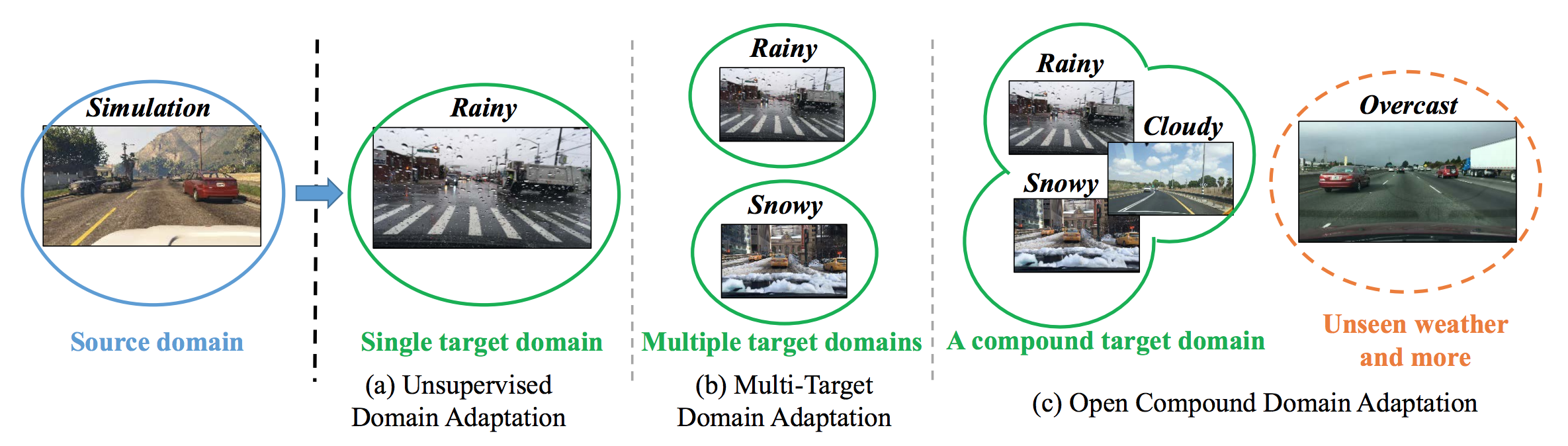
Figura 3: Las diferencias entre la adaptación de un dominio de un solo objetivo, de varios objetivos
y nuestra adaptación de dominio compuesto abierto (OCDA).
En nuestro entorno OCDA, el dominio de destino ya no tiene un predominio uni-modal
distribución, lo que plantea problemas a los métodos de adaptación de los dominios existentes. Nosotros
proponer un enfoque novedoso basado en dos conocimientos técnicos sobre el OCDA: 1) a
adaptación de los dominios del currículo estrategia de generalización de bootstrap a través de
distinción de dominios de una manera auto-organizada basada en datos y 2) a memoria
módulo para aumentar la agilidad del modelo hacia los nuevos dominios, como se ilustra
en la figura 4.
En primer lugar, a diferencia de los métodos de adaptación de los planes de estudio existentes que dependen de algunos
medida holística de la dificultad de la instancia, programamos el aprendizaje de la
en el dominio del objetivo compuesto según sus brechas individuales a
el dominio de la fuente etiquetada, de modo que resolvemos un dominio cada vez más difícil
problema de adaptación hasta que cubramos todo el dominio del objetivo.
Nuestra segunda visión técnica es preparar nuestro modelo para los dominios abiertos durante
inferencia con un módulo de memoria que aumenta efectivamente las representaciones de
una entrada para la clasificación. Intuitivamente, si la entrada está lo suficientemente cerca de la
dominio de la fuente, la característica extraída de sí misma puede muy probablemente ya resultar
en la clasificación exacta. De lo contrario, las características de la memoria activada por la entrada pueden
…y jugar un papel más importante. En consecuencia, esta memoria aumentada
La red es más ágil en el manejo de dominios abiertos que su contraparte de vainilla.

Figura 4: Visión general de nuestro enfoque. 1) Separamos las características específicas de
dominios de los que discriminan entre clases. El dominio arrancado
se utiliza para construir un plan de estudios para el aprendizaje de los dominios. 2) Nosotros
mejorar nuestra red con un módulo de memoria que facilita la transferencia de conocimientos
del dominio de origen a las instancias del dominio de destino, de modo que la red pueda
equilibrar dinámicamente la información de entrada y el conocimiento transferido por la memoria
para tener más agilidad hacia los dominios no vistos anteriormente.
Controlamos la complejidad del compuesto y el dominio del objetivo abierto variando la
número de dominios de destino tradicionales / conjuntos de datos en él. Aquí, gradualmente
aumentar los dominios constitutivos de un solo dominio de destino a dos, y
eventualmente tres. Como se muestra en la figura 5, observamos que nuestro enfoque es
más resistente a los diversos números de dominios compuestos y abiertos. 1) El
El plan de estudios aprendido permite una transferencia gradual de conocimientos que es capaz de hacer frente
con estructuras complejas en el dominio del objetivo compuesto. 2) Además, el
El módulo indicador de dominio en nuestro marco ayuda a calibrar dinámicamente el
incrustado, aumentando así la robustez de los dominios abiertos.
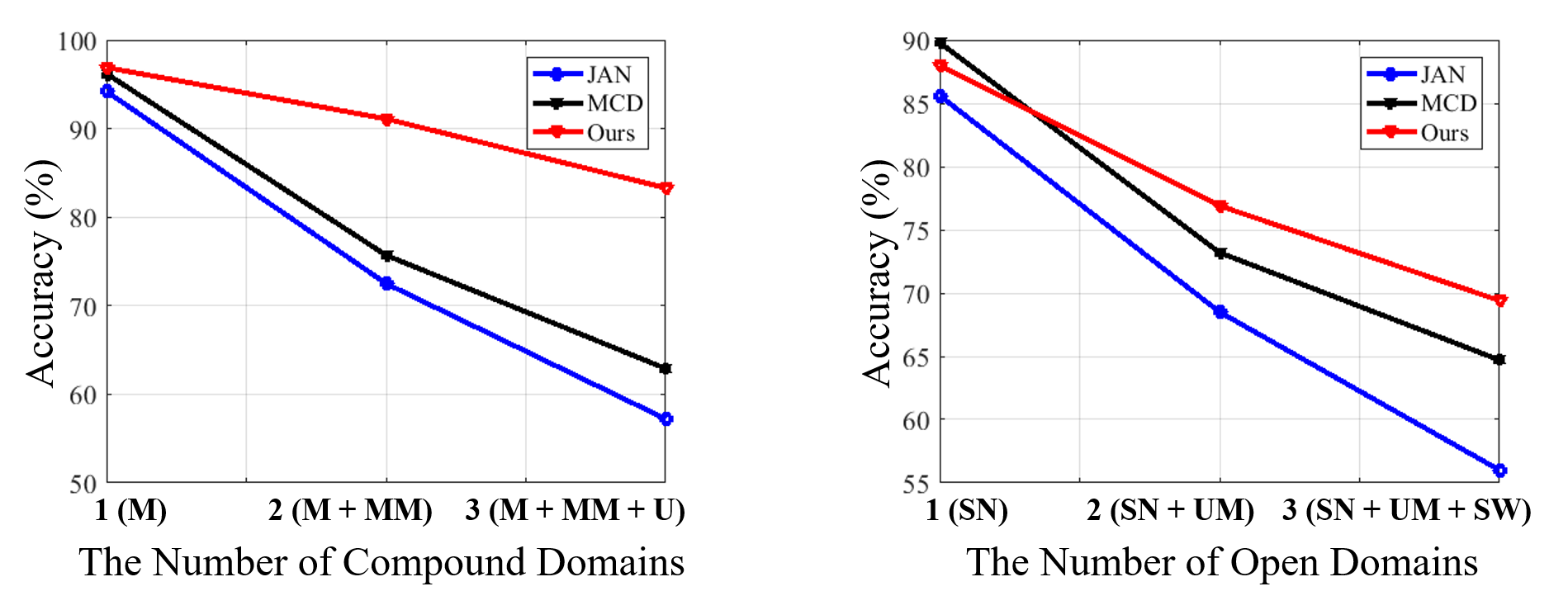
Figura 5: El cambio de rendimiento con el número de compuestos y abiertos
dominios.
A continuación se muestra una visualización de las características del dominio de desenmarañamiento. Separamos
características específicas de los dominios de los que se discrimina entre clases.
Se logra mediante un algoritmo de confusión de clases de manera no supervisada. Figura
6 (a) y (b) visualizar los ejemplos incorporados por el codificador de clase y dominio
codificador, respectivamente. El codificador de clase coloca instancias de la misma clase en
un grupo, mientras que el codificador de dominio coloca las instancias de acuerdo a su común
las apariencias, independientemente de sus clases.
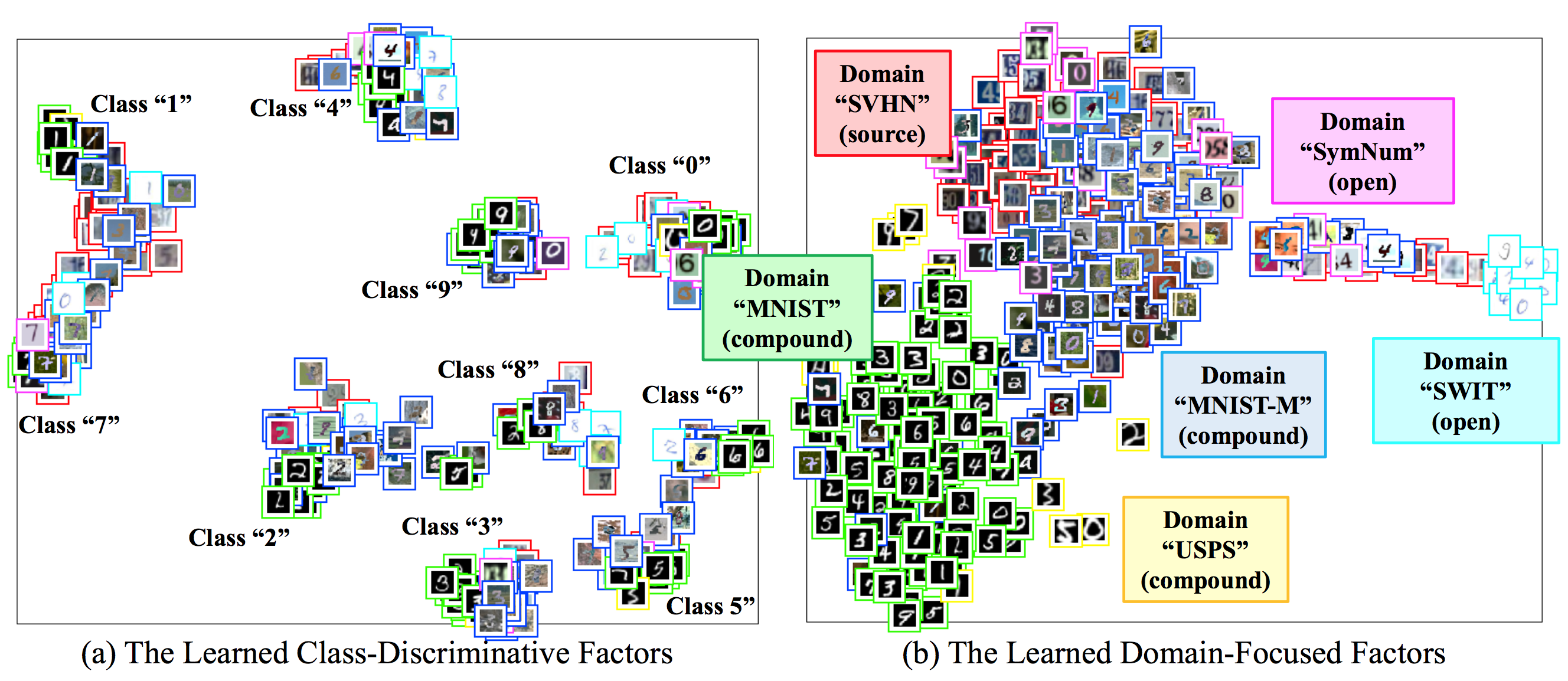
Figura 6: Visualización del t-SNE de nuestras (a) características de discriminación de clase, y (b)
características del dominio. Nuestro marco de trabajo desenreda los datos de los dominios mixtos en
factores de discriminación de clase y factores centrados en el dominio.
Agradecimientos: Agradecemos a todos los coautores del documento «Dominio Compuesto Abierto».
Adaptación» por sus contribuciones y discusiones en la preparación de este blog. El
Los puntos de vista y opiniones expresados en este blog son únicamente de los autores de este
papel.