

La coincidencia de entidades (EM) encuentra instancias de datos que se refieren a la misma entidad del mundo real. En 2015, iniciamos el proyecto Magellan en la UW-Madison, junto con socios industriales, para construir sistemas EM. La mayoría de los sistemas EM actuales son monolitos independientes. En cambio, Magallanes toma prestadas ideas del campo de la ciencia de los datos (DS), para construir un nuevo tipo de sistemas EM, que son ecosistemas de herramientas interoperables para múltiples entornos de ejecución, como en las instalaciones, en la nube y en el móvil. Este documento describe a Magallanes, centrándose en los aspectos del sistema. Argumentamos por qué el EM puede ser visto como una clase especial de problemas de DS y por lo tanto puede beneficiarse de las ideas de construcción de sistemas en DS. Discutimos cómo estas ideas han sido adaptadas para construir PyMatcher y CloudMatcher…herramientas sofisticadas en el lugar para usuarios avanzados y herramientas de nube de autoservicio para usuarios no profesionales. Estas herramientas explotan técnicas de los campos de aprendizaje automático, gran escalamiento de datos, interacción eficiente con el usuario, bases de datos y sistemas de nubes. Se han utilizado con éxito en 13 empresas y grupos de ciencias del dominio, se han puesto en producción para muchos clientes y se están comercializando. Discutimos las lecciones aprendidas y exploramos la aplicación de la plantilla de Magellan a otras tareas de exploración, limpieza e integración de datos.
1. Introducción
La coincidencia de entidades (EM) encuentra instancias de datos que se refieren a la misma entidad del mundo real, como tuplas (David Smith, UW-Madison) y (D. Smith, UWM). Este problema, también conocido como resolución de entidades, vinculación de registros, deduplicación, cotejo de datos, etc., ha sido un problema de larga data en las comunidades de bases de datos, IA, KDD y Web.2,6
A medida que proliferen las aplicaciones basadas en datos, el EM será aún más importante. Por ejemplo, para analizar los datos en bruto para obtener información, a menudo integramos múltiples conjuntos de datos en bruto en uno solo unificado, antes de realizar el análisis, y dicha integración a menudo requiere EM. Para construir un gráfico de conocimiento, a menudo comenzamos con un pequeño gráfico y luego lo expandimos con nuevos conjuntos de datos, y tal expansión requiere EM. Cuando manejamos un lago de datos, a menudo utilizamos el EM para establecer vínculos semánticos entre los dispares conjuntos de datos del lago.
Dada la creciente importancia de la EM, en el verano de 2015, junto con socios industriales, iniciamos el proyecto Magellan en la Universidad de Wisconsin-Madison, para desarrollar soluciones de EM.9 Numerosos trabajos han estudiado la EM, pero la mayoría de ellos desarrollan Algoritmos EM para pasos aislados en el flujo de trabajo de la EM. En contraste, buscamos construir Sistemas EMya que creemos que tales sistemas son críticos para el avance del campo electromagnético. Entre otros, ayudan a evaluar los algoritmos EM, integrar los esfuerzos de I+D, y hacer impactos prácticos, de la misma manera que sistemas como System R, Ingres, Apache Hadoop, y Apache Spark han ayudado a avanzar en los campos de los sistemas de gestión de bases de datos relacionales (RDBMSs) y Big Data.
Por supuesto, Magallanes no es el primer proyecto de construcción de sistemas EM. Se han desarrollado muchos de estos sistemas.9,2 Sin embargo, hasta donde podemos decir, virtualmente todos ellos han sido construidos como sistemas EM monolíticos independienteso partes de sistemas monolíticos más grandes que realizan la limpieza e integración de datos.2,6,9 Estos sistemas a menudo emplean la plantilla de construcción de RDBMS. Es decir, dado un flujo de trabajo EM compuesto de operadores lógicos (especificados declarativamente o a través de una GUI por un usuario), compilan este flujo de trabajo en uno que consiste en operadores físicos y luego optimizan y ejecutan el flujo de trabajo compilado.
Por el contrario, Magallanes desarrolla una plantilla de construcción de sistemas radicalmente diferente para la EM, aprovechando las ideas del campo de la ciencia de los datos (DS). Aunque la DS es todavía «joven», han surgido varios temas comunes.
- Para muchas tareas de DS, existe un consenso general de que no es posible automatizar completamente las dos etapas de desarrollo y producción de los flujos de trabajo de DS. Por lo tanto, los usuarios deben «estar al tanto», y se han desarrollado muchas guías paso a paso que indican a los usuarios cómo ejecutar las dos etapas anteriores.
- Se han identificado muchos «puntos débiles» en estas guías, es decir, pasos que consumen mucho tiempo a los usuarios, y se han desarrollado herramientas (semi)automatizadas para reducir el esfuerzo de los usuarios.
- Los usuarios suelen utilizar múltiples entornos de ejecución (EE), como el local, la nube y el móvil, cambiando entre ellos. Así que se han desarrollado herramientas para todos estos EE.
- Finalmente, dentro de cada EE, se han diseñado herramientas para ser atómicas e interoperables, formando un creciente ecosistema de herramientas de DS. Los ejemplos incluyen PyData, el ecosistema de más de 184.000 paquetes de Python interoperables (hasta junio de 2019), R, tidyverse, y muchos otros.4
Observamos que el EM tiene fuertes similitudes con muchas tareas del DS.9 Como resultado, aprovechamos las ideas anteriores para construir un nuevo tipo de sistemas EM. Específicamente, desarrollamos guías que le dicen a los usuarios cómo realizar la EM paso a paso, identificando los «puntos dolorosos» en las guías, y luego desarrollamos herramientas para tratar estos puntos dolorosos. Desarrollamos herramientas para entornos de ejecución múltiple (EE), de tal manera que dentro de cada EE, las herramientas destemplen y construyan sobre las herramientas de EE existentes en ese EE.
Por lo tanto, la noción de «sistema» en Magallanes ha cambiado. Ya no es un sistema monolítico autónomo como los RDBMS o la mayoría de los sistemas EM actuales. En lugar de eso, este nuevo «sistema» abarca múltiples EEs. Dentro de cada EE, proporciona un creciente ecosistema de herramientas EM interoperables, situado en un ecosistema mayor de herramientas DS. Finalmente, provee guías detalladas que le dicen a los usuarios cómo usar estas herramientas para realizar la EM.
Desde el verano de 2015, hemos seguido el programa de EM mencionado anteriormente y hemos desarrollado pequeños ecosistemas de herramientas de EM para las EEs en las instalaciones y en las nubes. Estas herramientas explotan técnicas de los campos de aprendizaje automático, gran escalamiento de datos, interacción eficiente con el usuario, bases de datos y sistemas de nubes. Se han utilizado con éxito en 13 empresas y grupos de ciencias del dominio, se han puesto en producción para muchos clientes y se están comercializando. Su desarrollo también ha planteado muchos retos de investigación.4
En este documento, describimos los avances mencionados, centrándonos en los aspectos del sistema. La siguiente sección discute el problema de la EM y el trabajo relacionado. La sección 3 discute los principales temas de construcción de sistemas de la ciencia de los datos y la agenda de Magallanes. Las secciones 4-5 discuten PyMatcher y CloudMatcherdos empujes actuales de Magallanes. La sección 6 discute la aplicación de las herramientas de Magellan a los problemas del mundo real de la EM. La sección 7 discute las lecciones aprendidas y el trabajo en curso. La sección 8 concluye explorando cómo aplicar la plantilla de Magellan a otras tareas de exploración, limpieza e integración de datos. Se puede encontrar más información sobre Magellan en los sitios web: google.com/site/anhaidgroup/projects/magellan.
Volver al principio
2. El problema de la coincidencia de entidades
La comparación de entidades, también conocida como resolución de entidades, vinculación de registros, comparación de datos, etc., ha recibido una enorme atención.2, 6, 5, 13 Un escenario EM común encuentra todos los pares tuples que coinciden, es decir, se refieren a la misma entidad del mundo real, entre dos tablas A y B (véase la figura 1). Otros escenarios de EM incluyen la coincidencia de tuplas dentro de una sola tabla, la coincidencia en un gráfico de conocimiento, la coincidencia de datos XML, etc.2
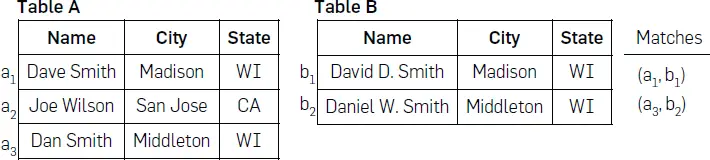
Figura 1. Un ejemplo de la coincidencia de dos tablas.
Cuando se combinan dos tablas A y Bconsiderando todos los pares en A x B a menudo toma mucho tiempo. Así que los usuarios a menudo ejecutan un paso de bloqueo seguido de un paso de concordancia.2El paso de bloqueo emplea la heurística para eliminar rápidamente los pares de tuplas obviamente no coincidentes (por ejemplo, las personas que residen en diferentes estados). El paso de la coincidencia… aplica un comparador a los pares restantes para predecir las coincidencias.
El vasto cuerpo de trabajo en EM se divide aproximadamente en tres grupos: algorítmico, centrado en el humano y de sistema. La mayoría de los trabajos en EM desarrollan soluciones algorítmicas para bloquear y emparejar, explotar las reglas, aprender, agrupar, crowdsourcing, datos externos, etc.2,6,5 El objetivo es mejorar la precisión, reducir al mínimo el tiempo de ejecución y reducir al mínimo los costos (por ejemplo, los honorarios de los proveedores), entre otros.13,6
Un cuerpo más pequeño pero creciente de trabajo de EM (por ejemplo, HILDA1) estudios centrado en el ser humano desafíos, como el crowdsourcing, la interacción efectiva con el usuario y el comportamiento del usuario durante el proceso EM.
El tercer grupo de trabajo de EM desarrolla Sistemas EM. En 2016, estudiamos 18 sistemas no comerciales (por ejemplo, D-Dupe, Febrl, Dedoop y Nadeef) y 15 comerciales (por ejemplo, Tamr, Informatica e IBM InfoSphere).9,12 La mayoría de estos sistemas son monolitos independientes, construidos usando la plantilla RDBMS. Concretamente, ese sistema tiene un conjunto de operaciones lógicas (por ejemplo, el bloqueo y el emparejamiento) con múltiples implementaciones físicas. Dado un flujo de trabajo de EM (compuesto por estas operaciones) especificado por el usuario mediante una interfaz gráfica de usuario o un lenguaje declarativo, el sistema traduce el flujo de trabajo en un plan de ejecución y luego optimiza y ejecuta este plan.
3. La Agenda de Magallanes
Ahora discutimos las ideas de construcción de sistemas en el campo de la ciencia de los datos (DS). Luego argumentamos que la EM es muy similar en naturaleza a la DS y por lo tanto puede beneficiarse de estas ideas. Por último, sugerimos una agenda de construcción de sistemas para Magallanes.
Ideas de construcción de sistemas de ciencia de datos: Aunque el campo DS ha crecido rápidamente, no tenemos conocimiento de ninguna descripción explícita de su «plantilla de sistema». Pero nuestro examen revela las siguientes ideas importantes.
En primer lugar, muchas tareas de la DS distinguen entre dos etapas, desarrollo y producción, ya que estas etapas plantean desafíos diferentes. La etapa de desarrollo encuentra un flujo de trabajo preciso de DS, a menudo utilizando muestras de datos. Esto plantea desafíos en la exploración de datos, la creación de perfiles, la comprensión, la limpieza, el ajuste y la evaluación de modelos, etc. La etapa de producción (también conocida como despliegue) ejecuta el flujo de trabajo de DS descubierto en la totalidad de los datos, lo que plantea desafíos en la escalada, el registro, la recuperación de accidentes, la supervisión, etc.
En segundo lugar, los desarrolladores de la DS no asumen que las dos etapas anteriores puedan ser automatizadas. Los usuarios a menudo deben estar «al tanto» y a menudo no saben qué hacer, cómo empezar, etc. Como resultado, los desarrolladores proporcionan guías detalladas que indican a los usuarios cómo resolver un problema de DS, paso a paso. Se han desarrollado numerosas guías, descritas en libros, documentos, cuadernos Jupyter, campos de entrenamiento, blogs, tutoriales, etc.
Es importante señalar que tal guía es no un manual de usuario sobre cómo utilizar una herramienta. Es más bien una instrucción paso a paso para el usuario sobre cómo empezar, cuándo usar qué herramientas y cuándo hacer qué manualmente, para resolver la tarea de DS de principio a fin. Dicho de otra manera, es un algoritmo (a menudo complejo) para que el usuario lo siga. (Véase la Sección 4 para un ejemplo).
Tercero, incluso sin herramientas, los usuarios deben ser capaces de seguir una guía y ejecutar manualmente todos los pasos para resolver una tarea de DS. Pero algunos de los pasos pueden llevar mucho tiempo. Los desarrolladores de DS han identificado tales pasos de «punto de dolor» y han desarrollado herramientas (semi-)automáticas para reducir el esfuerzo humano.
En cuarto lugar, estos instrumentos están dirigidos no sólo a los usuarios avanzados, sino también a los usuarios no expertos (ya que estos usuarios necesitan trabajar cada vez más con los datos), y utilizan diversas técnicas, por ejemplo, el aprendizaje automático (ML), el RDBMS, la visualización, la interacción efectiva con el usuario, el escalado de grandes datos y las tecnologías de nubes.
En quinto lugar, se acepta en general que los usuarios a menudo utilizarán múltiples entornos de ejecución (EEs), como el local, la nube y el móvil, cambiando entre estos EEs según sea apropiado, para ejecutar una tarea de DS. Como resultado, se han desarrollado herramientas para todos estos EEs.
Finalmente, dentro de cada EE, las herramientas han sido diseñadas para ser atómicas (es decir, cada herramienta hace una sola cosa) e interoperables, formando un creciente ecosistema de herramientas de DS. Ejemplos populares de tales ecosistemas incluyen PyData, R, tidyverse, y muchos otros.4
Las similitudes entre EM y DS: Sostenemos que el EM tiene fuertes similitudes con muchas tareas del DS. La EM a menudo comparte las mismas dos etapas: desarrollo, donde los usuarios encuentran un flujo de trabajo EM preciso usando muestras de datos, y producción, donde los usuarios ejecutan el flujo de trabajo en la totalidad de los datos (ver sección 4 para un ejemplo).
Las dos etapas de la EM mencionadas anteriormente plantean desafíos que son notablemente similares a los de las tareas del SD, por ejemplo, la comprensión de los datos, el ajuste de los modelos, el escalado, etc. Además, también existe un consenso emergente de que no es posible automatizar completamente las dos etapas anteriores para la EM. Al igual que en el caso del SD, esto también plantea la necesidad de contar con guías paso a paso que indiquen a los usuarios cómo estar «al tanto», así como la necesidad de identificar «puntos dolorosos» en la guía y desarrollar herramientas para estos puntos dolorosos (para reducir el esfuerzo del usuario). Por último, esos instrumentos también deben estar dirigidos tanto a los usuarios avanzados como a los legos en la materia, y utilizar diversas técnicas, por ejemplo, el ML, el RDBMS, la visualización, el escalado, etc.
Por lo tanto, creemos que el EM puede ser visto como una clase especial de problemas de DS, que se centra en encontrar las coincidencias semánticas, por ejemplo, «(David Smith, UWM) = (D. Smith, UW-Madison)». Como tal, creemos que el EM puede beneficiarse de las ideas de construcción de sistemas en el DS.
Nuestra agenda: Usando la «plantilla del sistema» de DS, desarrollamos la siguiente agenda para Magallanes. Primero, identificamos escenarios comunes de EM. Luego, desarrollamos guías de cómo resolver estos escenarios de punta a punta, prestando especial atención a decirle al usuario exactamente qué hacer. Luego identificamos los puntos débiles de las guías y desarrollamos herramientas (semi-)automáticas para reducir el esfuerzo del usuario. Diseñamos herramientas para ser atómicas e interoperables, como parte de un creciente ecosistema de herramientas para el DS. El desarrollo de estas herramientas plantea desafíos de investigación, que abordamos. Finalmente, trabajamos con los usuarios (por ejemplo, científicos del dominio, empresas y estudiantes) para evaluar nuestras herramientas EM.
En los últimos años, hemos estado desarrollando herramientas EM para dos entornos de ejecución populares: en las instalaciones y en la nube. Específicamente, PyMatcher es un pequeño ecosistema de herramientas EM para usuarios de energía, construido como parte del ecosistema PyData de herramientas DS, y CloudMatcher es un pequeño ecosistema de herramientas de EM de nubes para usuarios legos, construido como parte del ecosistema de herramientas de DS de AWS. Las dos secciones siguientes describen brevemente estos ecosistemas
4. Pymatcher
Ahora describimos PyMatcherun sistema EM desarrollado para los usuarios de energía en el entorno de ejecución en el lugar.
Escenarios problemáticos: En este primer impulso de Magallanes, consideramos un escenario de EM que comúnmente ocurre en la práctica, donde un usuario U quiere hacer coincidir dos tablas (por ejemplo, véase la figura 1), con la mayor precisión de coincidencia posible, o con una precisión superior a un umbral. U es un «usuario de poder» que sabe de programación, EM y ML.
Desarrollando la Guía de Cómo Hacer: Desarrollamos una guía inicial basada en nuestra experiencia y luego seguimos refinándola en base a la retroalimentación de los usuarios y a la observación de cómo los usuarios reales hacen EM. A partir de noviembre de 2018, hemos desarrollado una guía para el mencionado escenario EM, que consiste en dos guías más pequeñas para las etapas de desarrollo y producción, respectivamente. Aquí nos centramos en la guía para la etapa de desarrollo (discutiendo brevemente la guía para la etapa de producción al final de esta sección).
En esta guía (que se ilustra en la figura 2) se utiliza mucho la ML. Para explicarlo, supongamos que el usuario U quiere hacer coincidir dos tablas A y Bcada una con un millón de tuplas. Tratar de encontrar un flujo de trabajo preciso usando estas dos tablas sería demasiado largo, porque son demasiado grandes. Por lo tanto, U primero «bajará la muestra» de las dos tablas para obtener dos tablas más pequeñas A’ y B’cada una con 100 mil tuplas, digamos (ver la figura).
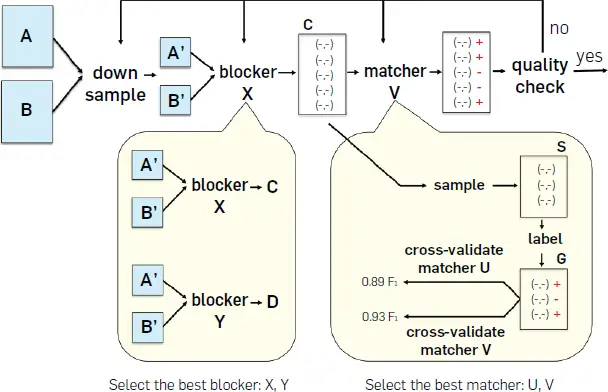
Figura 2. Los pasos de la guía para la etapa de desarrollo de PyMatcher.
A continuación, supongamos que el sistema EM proporciona dos bloqueadores X y Y. Entonces.., U experimentos con estos bloqueadores (por ejemplo, ejecutando ambos en Tablas A’ y B’ y examinando su salida) para seleccionar el bloqueador que se juzgara mejor (según algún criterio). Supongamos que U selecciona el bloqueador X. Luego el siguiente, U ejecuta X en las mesas A’ y B’ para obtener un conjunto de parejas tupla candidatas C.
El siguiente, U toma una muestra S de C y etiqueta los pares en S como «coincidencia»/»no coincidencia» (ver la figura). Deje que el conjunto etiquetado sea Gy supongamos que el sistema EM proporciona dos parejas basadas en el aprendizaje U y V (por ejemplo, árboles de decisión y regresión logística). Entonces, U utiliza el conjunto etiquetado G para realizar la validación cruzada de U y V. Supongamos que V produce una mayor precisión de coincidencia (como F1 puntuación de 0,93, ver la figura). Entonces.., U selecciona V como la pareja y se aplica V al set C para predecir «coincidencia»/»no coincidencia», que se muestra como «+» o «-» en la figura. Por último, U puede realizar un control de calidad (examinando una muestra de las predicciones y calculando la precisión resultante) y luego volver a depurar y modificar los pasos anteriores según corresponda. Esto continúa hasta que U está satisfecho con la precisión del flujo de trabajo de la EM.
Desarrollo de herramientas para los pasos de la guía: En los últimos tres años y medio, 13 desarrolladores han elaborado instrumentos para los pasos de la guía anterior (véase Govind et al.8). A partir de septiembre de 2019, PyMatcher consiste en 6 paquetes Python con 37K líneas de código y 231 comandos (y es de fuente abierta9). Está construido sobre 16 paquetes diferentes en el ecosistema de PyData (por ejemplo, pandas y scikit-learn). Hasta donde podemos decir, PyMatcher es el sistema EM de código abierto más completo hoy en día, en términos del número de características que soporta.
Principios para el desarrollo de herramientas y paquetes: En PyMatchercada herramienta es aproximadamente equivalente a un comando Python, y las herramientas están organizadas en paquetes Python. Adoptamos cinco principios para desarrollar herramientas y paquetes:
- Deberían interoperar entre sí, y con los paquetes PyData existentes.
- Deberían ser atómicoes decir, cada uno hace sólo una cosa.
- Deberían ser autónomaes decir, pueden ser usados por sí mismos, sin depender de nada externo.
- Deberían ser personalizable.
- Deberían ser eficiente tanto para los humanos como para las máquinas.
Ahora ilustramos estos principios. Como ejemplo de facilitar interoperabilidad entre los comandos de los diferentes paquetes, usamos sólo estructuras de datos genéricos bien conocidas como el Pandas DataFrame para sostener las tablas (por ejemplo, las dos tablas A y B y la tabla de salida después del bloqueo).
Diseñando cada comando, es decir, herramienta, para ser «atómico» es algo sencillo. Diseñar cada paquete para que lo sea es más difícil. Inicialmente, diseñamos un solo paquete para todas las herramientas de todos los pasos de la guía. Luego, tan pronto como fue obvio que un conjunto de herramientas forman un grupo coherente e independiente, lo extrajimos como un nuevo paquete. Sin embargo, esta extracción no siempre es fácil de hacer, como discutiremos pronto.
Ignorando la autocontención por ahora, para hacer herramientas y paquetes altamente personalizableexponemos todas las «perillas» posibles para que el usuario las modifique y le proporcionamos formas fáciles de hacerlo. Por ejemplo, dadas dos mesas A y B para que coincidan, PyMatcher puede definir automáticamente un conjunto de características (por ejemplo, jaccard(3gramo(A.nombre), 3gramo(B.name))). Almacenamos este conjunto de características en una variable global F. Damos a los usuarios formas de eliminar características de F y para definir declarativamente más características y luego agregarlas a F.
Como ejemplo de hacer una herramienta, es decir, un comando, X eficiente para un usuariopodemos hacer X fácil de recordar y especificar (es decir, no requiere que el usuario introduzca muchos argumentos). A menudo, esto también significa que proporcionamos múltiples variaciones para Xporque cada usuario puede recordar mejor una variación particular.
Comando X es eficiente para la máquina si se minimiza el tiempo de ejecución y el espacio. Por ejemplo, que A y B ser dos tablas con el esquema (identificación, nombre, edad). Supongamos que X es un comando bloqueador que cuando se aplica a A y B produce un conjunto de pares de tuplas C. Entonces, para ahorrar espacio, X no debe utilizar (A.id, A.name, A.age, B.id, B.name, B.age), sino sólo (A.id, B.id) como esquema de C.
Si es así, necesitamos almacenar la «información de metadatos» que hay una relación clave-extraña (FK) entre las tablas A, B…y… C. Almacenar estos metadatos en las propias tablas no es una opción si ya hemos elegido almacenar las tablas utilizando el DataFrame de Pandas (que no puede almacenar tales metadatos, a menos que redefinamos la clase DataFrame). Así que podemos usar un catálogo independiente Q para almacenar tales metadatos para las tablas.
Pero esto plantea un problema. Si usamos un comando Y de algún otro paquete para quitar una tupla de la mesa A, Y ni siquiera conoce el catálogo Q y por lo tanto no modificará los metadatos almacenados en Q. Como resultado, los metadatos son ahora incorrectos: Q sigue afirmando que existe una relación FK entre las mesas A y C. Pero esto ya no es cierto.
Para abordar este problema, podemos diseñar las herramientas para ser …autónoma. Por ejemplo, si una herramienta Z está a punto de operar en la mesa C y necesita los metadatos «hay una restricción de FK entre A y C» para ser verdad, primero comprobará esa restricción. Si la restricción sigue siendo verdadera, entonces Z procederá normalmente. De lo contrario, Z emite una advertencia de que la restricción FK ya no es correcta y luego se detiene o procede (dependiendo de la naturaleza del comando). Así, Z es autónoma en el sentido de que no depende de nada externo para asegurar la corrección de los metadatos que necesita.
Intercambios entre los principios: A estas alturas debería quedar claro que los principios mencionados anteriormente a menudo interactúan y entran en conflicto entre sí. Por ejemplo, como se ha dicho, para hacer que los comandos interoperen, podemos usar Pandas DataFrames para mantener las tablas, y para hacer que los comandos sean eficientes, podemos necesitar almacenar metadatos como las restricciones de FK. Pero esto significa que las restricciones deben ser almacenadas en un catálogo global. Esto dificulta la extracción de un conjunto de comandos para crear un nuevo paquete, porque los comandos necesitan acceso a este catálogo global.
Hay muchos ejemplos como éste que, en conjunto, sugieren que para diseñar un «ecosistema» de herramientas y paquetes que sigan los principios anteriores es necesario hacer concesiones. Hemos hecho varias de estas concesiones al diseñar PyMatcher. Pero obtener una clara comprensión de estas compensaciones y utilizarla para diseñar un mejor ecosistema es un trabajo todavía en curso.
La etapa de producción: Hasta ahora, nos hemos centrado en la etapa de desarrollo de PyMatcher y han desarrollado sólo una solución básica para la etapa de producción. Específicamente, asumimos que después de la etapa de desarrollo, el usuario ha obtenido un flujo de trabajo EM preciso Wque es capturado como un script Python (de una secuencia de comandos). Hemos desarrollado herramientas que pueden ejecutar estos comandos en una sola máquina multinúcleo, utilizando código personalizado o Dask (que es un paquete Python desarrollado por Anaconda que puede ser utilizado para modificar rápidamente un comando Python para que se ejecute en múltiples núcleos, entre otros). También hemos desarrollado una guía de cómo hacerlo que le indica al usuario cómo escalar usando estas herramientas.
5. Cloudmatcher
Ahora describimos CloudMatcher…un sistema EM desarrollado para usuarios no profesionales en el entorno de la nube.
Escenarios problemáticos: Utilizamos el término «usuario lego» para referirnos a un usuario que no sabe programar, ML o EM, pero que entiende lo que significa ser compatible (y por lo tanto puede etiquetar los pares tuples como compatibles/no compatibles). Nuestro objetivo es construir un sistema que esos usuarios legos puedan utilizar para emparejar dos tablas A y B. Llamamos a estos sistemas sistemas EM de autoservicio.
Desarrollando un sistema EM para un solo usuario: En un trabajo reciente,3 hemos desarrollado Falcon…un sistema EM de autoservicio que puede servir a un solo usuario. Como CloudMatcher se basa en Falconcomenzamos describiendo brevemente Falcon.
Para hacer coincidir dos tablas A y Bcomo la mayoría de las soluciones EM actuales, Falcon realiza el bloqueo y el emparejamiento, pero hace que ambas etapas sean de autoservicio (véase la figura 3). En la etapa de bloqueo (Figura 3a), toma una muestra S de pares de tuplas (Paso  ) y luego realiza un aprendizaje activo con el usuario lego en S (en el que el usuario etiqueta los pares tuples como coincidentes/no coincidentes) para aprender un bosque al azar F (Paso
) y luego realiza un aprendizaje activo con el usuario lego en S (en el que el usuario etiqueta los pares tuples como coincidentes/no coincidentes) para aprender un bosque al azar F (Paso  ), que es un conjunto de n árboles de decisión. El bosque F declara un par de tuplas p una coincidencia si al menos αn árboles en F declarar p una coincidencia (donde α está preespecificado).
), que es un conjunto de n árboles de decisión. El bosque F declara un par de tuplas p una coincidencia si al menos αn árboles en F declarar p una coincidencia (donde α está preespecificado).
![]()
Figura 3. El flujo de trabajo de Falcon, donde un usuario lego etiqueta los pares tuples como coincidentes/no coincidentes en los pasos , 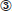 …y…
…y… 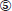 .
.
En el paso , Falcon extrae todas las ramas de la raíz de un árbol (en el bosque al azar F) a una hoja de «No» como reglas de bloqueo de candidatos. Por ejemplo, el árbol de la figura 4a predice que dos tuplas de libros coinciden sólo si sus ISBN coinciden y el número de páginas coincide. La Figura 4b muestra dos reglas de bloqueo extraídas de este árbol. Falcon recluta al usuario lego para evaluar las reglas de bloqueo extraídas y conserva sólo las reglas precisas. En el paso 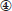 ,
, Falcon ejecuta estas reglas en las mesas A y B para obtener un conjunto de parejas tupla candidatas C. Esto completa la etapa de bloqueo (Figura 3a). En la etapa de emparejamiento (Figura 3b), Falcon realiza un aprendizaje activo con el usuario lego en C para obtener otro bosque al azar G y luego se aplica G a C para predecir las coincidencias (Pasos y 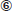 ).
).
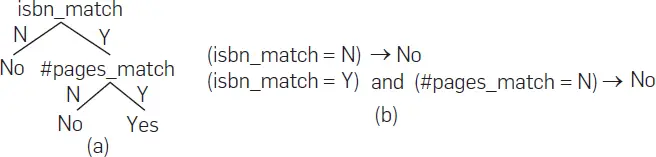
Figura 4. a) Un árbol de decisión aprendido por Falcon y b) reglas de bloqueo extraídas del árbol.
Como se ha descrito, Falcon es muy adecuado para usuarios no profesionales, que sólo tienen que etiquetar los pares de tuplas como coincidentes o no coincidentes. Hemos implementado Falcon como CloudMatcher 0.1 y se desplegó como se muestra en la Figura 5, con el objetivo de proporcionar EM de autoservicio a los científicos del dominio en UW. Cualquier científico que quiera hacer coincidir dos tablas A y B puede ir a la página web de CloudMatcher…sube las tablas, y luego etiqueta un conjunto de pares de tuplas… …o pide a los trabajadores de la multitud que digan en Turco Mecánico que lo hagan. CloudMatcher utiliza los pares etiquetados para bloquear y emparejar, como se describió anteriormente, y luego devuelve el conjunto de coincidencias entre A y B.
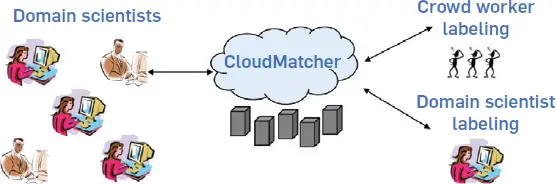
Figura 5. Autoservicio EM con CloudMatcher.
Desarrollando un sistema EM para múltiples usuarios: Sin embargo, pronto reconocimos que CloudMatcher 0,1 no escala, porque sólo puede ejecutar un flujo de trabajo EM a la vez. Así que diseñamos CloudMatcher 1.0, que puede ejecutar eficientemente múltiples flujos de trabajo EM concurrentes (por ejemplo, presentados por múltiples científicos al mismo tiempo). Desarrollando CloudMatcher 1.0 fue un gran desafío.7 Nuestra solución fue dividir cada flujo de trabajo EM en múltiples fragmentos DAG, donde cada fragmento realiza sólo un tipo de tarea, por ejemplo, la interacción con el usuario, el procesamiento de datos por lotes, la obtención de datos en masa, etcétera. A continuación, ejecutamos cada fragmento en un motor de ejecución apropiado. Desarrollamos tres motores de ejecución: el motor de interacción con el usuario, el motor de multitudes y el motor de lotes. Para escalar, intercalamos la ejecución de fragmentos DAG provenientes de diferentes flujos de trabajo EM y coordinamos todas las actividades usando un «metamanager». Ver Govind et al.7 para más detalles.
Proporcionando múltiples servicios básicos: CloudMatcher 1.0 implementado sólo el rígido anterior Falcon Flujo de trabajo de EM. Sin embargo, al interactuar con usuarios reales, observamos que muchos usuarios quieren personalizar y experimentar de forma flexible con diferentes flujos de trabajo EM. Por ejemplo, un usuario puede que ya conozca una regla de bloqueo, por lo que quiere saltarse el paso de aprender dichas reglas. Sin embargo, otro usuario puede querer utilizar CloudMatcher sólo para etiquetar pares de tuplas (por ejemplo, para ser usados en PyMatcher).
Así que desarrollamos CloudMatcher 2.0, que extrae un conjunto de servicios básicos de la Falcon flujo de trabajo de EM y los hace disponibles en CloudMatchery luego permite a los usuarios combinarlos de manera flexible para formar diferentes flujos de trabajo EM (como el original Falcon uno). Apéndice C de Govind et al.8 muestra la lista de servicios que actualmente ofrecemos. Servicios básicos incluyen la carga de un conjunto de datos, el perfilado de un conjunto de datos, la edición de los metadatos de un conjunto de datos, el muestreo, la generación de características, la capacitación de un clasificador, etc. Hemos combinado estos servicios básicos para proporcionar servicios compuestoscomo el aprendizaje activo, la obtención de reglas de bloqueo, y el Falcon. Por ejemplo, el usuario puede invocar el servicio «Obtener reglas de bloqueo» para pedir CloudMatcher para sugerir un conjunto de reglas de bloqueo que puede utilizar. Como otro ejemplo, el usuario puede invocar el servicio «Falcon» para ejecutar el Falcon Flujo de trabajo de EM.
6. Aplicaciones en el mundo real
Ahora discutimos las aplicaciones en el mundo real de PyMatcher y CloudMatcherasí como sus patrones de uso típicos. En la discusión aquí, medimos la precisión de la EM usando precisiónla fracción de coincidencias pronosticadas que son correctas, y recuerdala fracción de coincidencias verdaderas que se devuelven en el conjunto de coincidencias pronosticadas.
Aplicaciones de PyMatcher: PyMatcher se ha aplicado con éxito a múltiples aplicaciones de EM en el mundo real, tanto en la industria como en las ciencias del dominio. Ha sido empujado a la producción en la mayoría de estas aplicaciones y ha atraído una importante financiación (por ejemplo, 950.000 dólares de UW-Madison, 1,1 millones de dólares de la NSF y 480.000 dólares de la industria). También ha sido utilizado por más de 400 estudiantes en 5 clases de ciencias de la información en UW-Madison. Finalmente, ha dado lugar a múltiples publicaciones, tanto en el campo de la base de datos como en el de las ciencias del dominio.4
El cuadro 1 resume las aplicaciones en el mundo real. La primera columna muestra que PyMatcher se ha utilizado en una variedad de empresas y ciencias del dominio. La segunda columna muestra que PyMatcher se ha utilizado para tres propósitos: depurar un conducto de EM en producción (Walmart), construir un mejor conducto de EM que uno existente (economía y uso de la tierra), e integrar conjuntos de datos dispares (por ejemplo, Reclutamiento, Clínica Marshfield y limnología).
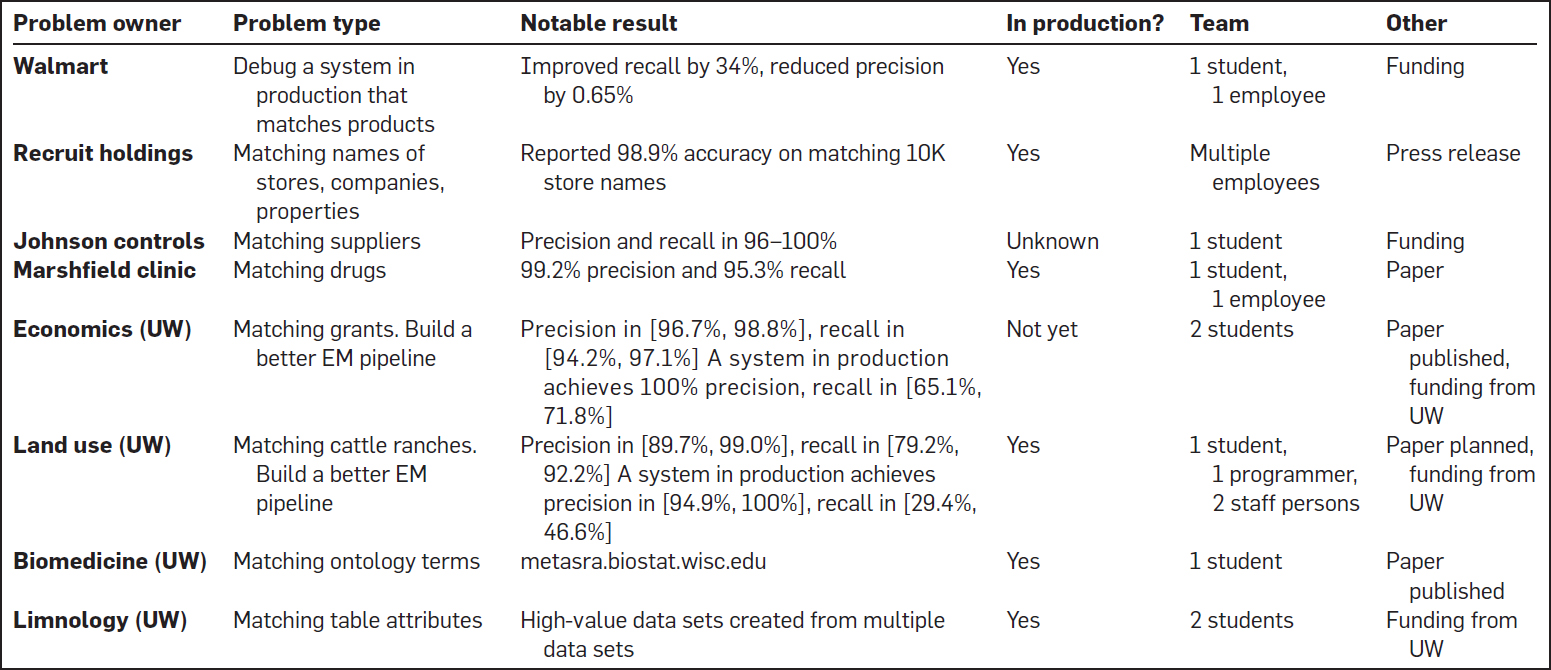
Tabla 1. Despliegue en el mundo real de PyMatcher.
La tercera columna muestra los principales resultados. Esta columna muestra que PyMatcher encontró flujos de trabajo de EM que eran significativamente mejores que los flujos de trabajo de EM en producción en tres casos: Walmart, Economía (UW) y Uso de la Tierra (UW). La cuarta columna indica que, en base a esos resultados, PyMatcher se ha puesto en producción en 6 de cada 8 aplicaciones. Esto se define como PyMatcher se utiliza en una parte de una tubería de EM en producción o b) los datos resultantes de utilizar PyMatcher ha sido empujado a la producción, es decir, siendo enviado y consumido por los clientes del mundo real.
La quinta columna muestra que en todos los casos que conocemos, PyMatcher no requiere un gran equipo para trabajar en él (y los equipos son sólo a tiempo parcial). La última columna enumera otros resultados notables. (Nótese que la financiación de UW vino de competiciones internas altamente selectivas.) Más detalles sobre estas solicitudes se pueden encontrar en Govind et al.8 y Konda et al.10
CloudMatcher: CloudMatcher se ha aplicado con éxito a múltiples aplicaciones de EM y ha atraído el interés comercial. Ha estado en producción en American Family Insurance desde el verano de 2018 y se está considerando su producción en otras dos grandes compañías.
El cuadro 2 resume CloudMatcher's rendimiento en 13 tareas EM del mundo real. Las dos primeras columnas muestran que CloudMatcher se ha utilizado en 5 empresas, 1 sin ánimo de lucro y 1 grupo científico de dominio, para una variedad de tareas de EM. Las siguientes dos columnas muestran que CloudMatcher se usó para hacer coincidir tablas de varios tamaños, de 300 a 4.9M tuplas.
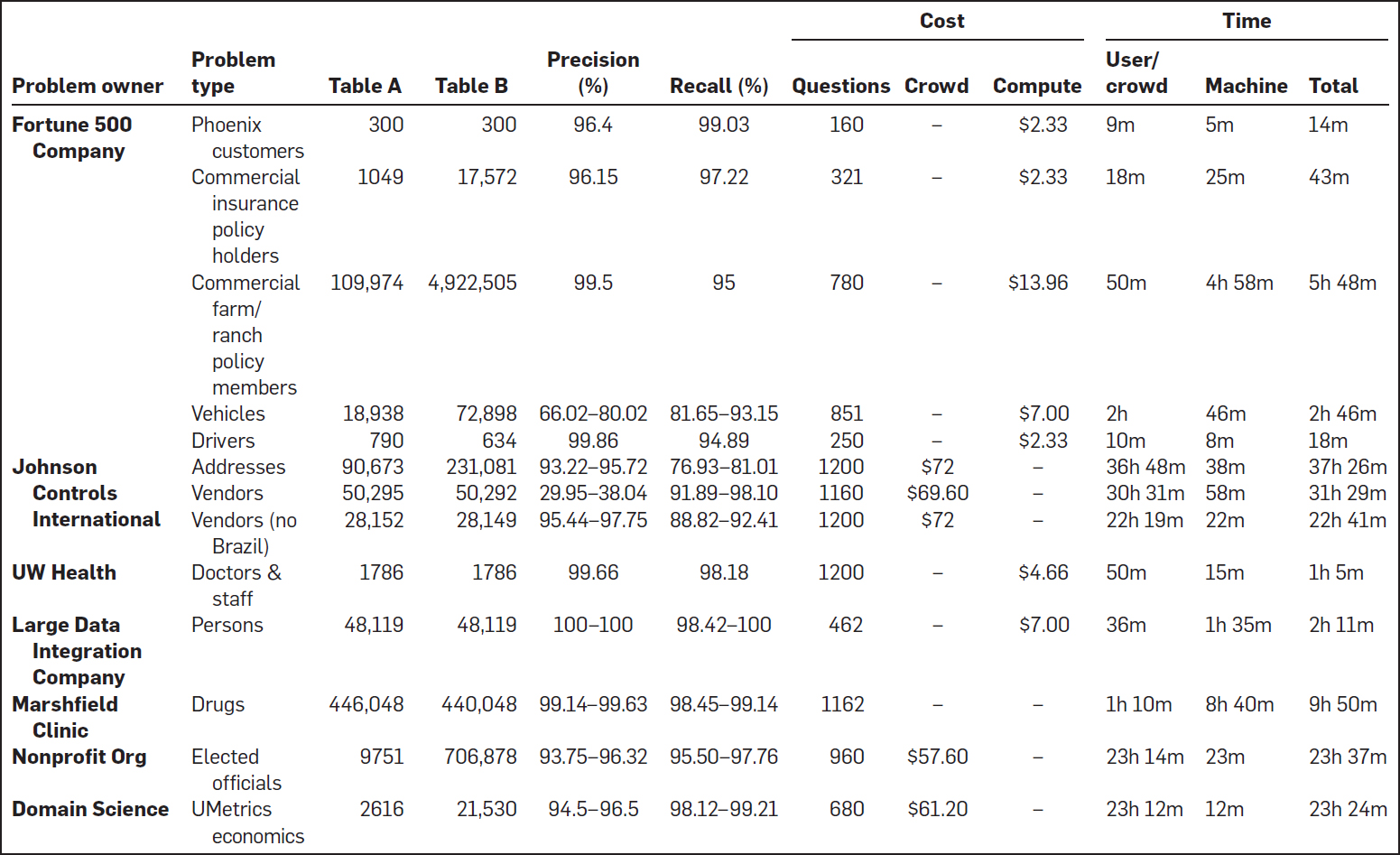
Tabla 2. Despliegue en el mundo real de CloudMatcher.
Ignorando las dos siguientes columnas sobre la precisión, hagamos un zoom en las tres columnas de «Costo» de la Tabla 2. La primera columna («Preguntas») lista el número de preguntas CloudMatcher tuvo que preguntar, es decir, el número de pares de tuplas a etiquetar. Este número oscila entre 160 y 1200 (el límite superior de la corriente CloudMatcher).
En la siguiente columna («Multitud»), una celda como «72 dólares» indica que para la tarea correspondiente de EM, CloudMatcher usó trabajadores de multitudes en el Turco Mecánico para etiquetar pares de tuplas, y costó $72. Una celda «-» indica que la tarea no usó el crowdsourcing. Utilizó un solo usuario, típicamente la persona que envió la tarea EM, para etiquetar, y por lo tanto no incurrió en ningún costo monetario.
En la tercera columna («Compute»), una celda como «$2.33» indica que la tarea EM correspondiente usó AWS, que cobró $2.33. Una celda como «-» indica que la tarea EM usó una máquina local de nuestra propiedad, y por lo tanto no tuvo ningún costo monetario.
Volviendo nuestra atención a las últimas tres columnas bajo «Tiempo», la primera columna («Usuario/Mayoría») lista el tiempo total de etiquetado, ya sea por un solo usuario o por la multitud de Turcos Mecánicos. Podemos ver que cuando un solo usuario etiquetó, fue típicamente bastante rápido, con un tiempo de 9m a 2h. Cuando una multitud etiquetó, el tiempo fue de 22h a 36h (esto no significa que los trabajadores de la multitud etiquetaron sin parar y tardaron tanto; sólo significa que el Turco Mecánico tardó ese tiempo en terminar la tarea de etiquetado). Estos resultados sugieren que CloudMatcher puede ejecutar una amplia gama de tareas EM con un tiempo de etiquetado muy razonable tanto de los usuarios como de los trabajadores de la multitud. Las siguientes dos columnas bajo «Tiempo» muestran el tiempo de la máquina y el tiempo total.
Ahora nos acercamos a la precisión. Las columnas «Precisión» y «Recordatorio» muestran que en todos los casos, excepto en tres, CloudMatcher logra una gran precisión, a menudo en el 90 por ciento. Los tres casos de precisión limitada son «Vehículos», «Direcciones» y «Proveedores». Un experto en dominios de American Family Insurance (AmFam) etiquetó pares de tuplas para «Vehículos». Pero los datos eran tan incompletos que incluso él no estaba seguro en muchos casos de si el par tuple coincide. En algún momento, se dio cuenta de que había etiquetado incorrectamente un conjunto de pares tuples, pero CloudMatcher no le proporcionó ninguna forma de «deshacer» el etiquetado, de ahí la baja precisión. Esta tarea EM está siendo actualmente re-ejecutada en la AmFam.
En el caso de «Vendedores», resultó que la parte de los datos que consiste en los vendedores brasileños es simplemente incorrecta: los vendedores introdujeron algunas direcciones genéricas en lugar de sus direcciones reales. Como resultado, incluso los usuarios no pueden coincidir con esos vendedores. Una vez que eliminamos tales vendedores de los datos, la precisión mejoró significativamente (véase la fila de «Vendedores (no Brasil)»). Resultó que «Direcciones» tenía problemas similares de datos sucios, lo que explicaba la baja recordación del 76-81%.
Patrones de uso típicos: Observamos las siguientes pautas de uso PyMatcher y CloudMatcher. Cuando se trabaja con clientes empresariales, un escenario común es que el equipo EM, que típicamente consiste en sólo unos pocos desarrolladores, está abrumado con numerosas tareas EM enviadas por muchos equipos empresariales de toda la empresa.
Para abordar este problema, el equipo EM pide a los equipos de negocios que utilicen CloudMatcher para resolver sus tareas de EM (en forma de autoservicio), contactando al equipo de EM sólo si CloudMatcher no alcanza la precisión EM deseada. En esos casos, el equipo EM se basa en los resultados de CloudMatcher pero usa PyMatcher para depurar y mejorar aún más la precisión.
Encontramos que el equipo de EM también utiliza a menudo CloudMatcher para resolver sus propias tareas EM, porque puede ser usado para resolver rápidamente una gran mayoría de tareas EM, que tienden a ser «fáciles», permitiendo que el equipo EM se concentre en resolver el pequeño número de tareas EM más difíciles usando PyMatcher.
Para las ciencias del dominio en la UW, algunos equipos sólo usaron CloudMatcherya sea porque no tienen experiencia en EM y ML o porque encontraron la precisión de CloudMatcher aceptable. Algunos otros equipos prefirieron PyMatcherya que les dio más opciones de personalización y mayores precisiones EM.
Finalmente, algunos clientes usaron ambos y cambiaron entre ellos. Por ejemplo, un cliente puede usar PyMatcher para experimentar y crear un conjunto de reglas de bloqueo y luego usar CloudMatcher para ejecutar estas reglas en mesas grandes.
7. Debate
Ahora discutimos las lecciones aprendidas y el trabajo en curso.
La necesidad de guías de instrucciones: Nuestro trabajo deja claro que es muy difícil automatizar completamente el proceso EM. La razón fundamental es que al principio, el usuario a menudo no entiende completamente los datos, la definición de la coincidencia, e incluso lo que quiere. Por ejemplo, en un reciente estudio de caso con PyMatcher,10 encontramos que los usuarios revisaron repetidamente su definición de coincidencia durante el proceso de EM, a medida que adquirían una mejor comprensión de los datos.
Esto implica que el usuario debe «estar al tanto» y que es fundamental contar con una guía que le diga al usuario qué hacer, paso a paso. Además, encontramos que estas guías proporcionan la seguridad a nuestros clientes de que podemos ayudarles a hacer EM de extremo a extremo. Las guías proporcionan un vocabulario común y un mapa de ruta para que todos los miembros del equipo lo sigan, independientemente de sus antecedentes. Incluso para los pasos de EM donde actualmente no tenemos herramientas, la guía todavía ayuda enormemente, porque le dice a los clientes lo que tienen que hacer, y pueden hacerlo manualmente o encontrar algunas herramientas externas para ayudarles. Tales guías, sin embargo, faltan por completo en la mayoría de las soluciones y sistemas EM actuales.
Dificultades en el desarrollo de guías de instrucciones: Sorprendentemente, descubrimos que desarrollar guías claras de cómo hacer es bastante desafiante. Por ejemplo, la actual guía para PyMatcher es todavía bastante preliminar. No proporciona una orientación detallada para muchos pasos, como la forma de ayudar a los usuarios a converger en una definición de coincidencia, la forma de etiquetar de forma colaborativa y la forma de depurar las coincidencias basadas en el aprendizaje, entre otros. La elaboración de orientaciones detalladas para esas medidas es una labor en curso.
Centrándose en la reducción del esfuerzo del usuario: Muchos de los trabajos de EM existentes se centran en la automatización del proceso de EM. En Magallanes, nuestro enfoque cambió a desarrollar una guía paso a paso que le dice a los usuarios cómo ejecutar el proceso de EM, identificando «puntos de dolor» de la guía y luego desarrollando herramientas para reducir el esfuerzo del usuario en los puntos de dolor. Encontramos que esta nueva perspectiva es mucho más práctica. Nos permite desarrollar rápidamente soluciones EM de extremo a extremo que podemos desplegar con usuarios reales en el día 1 y luego trabajar con ellos de cerca para mejorar gradualmente estas soluciones y reducir su esfuerzo.
Muchos nuevos puntos de dolor: El trabajo actual de EM se ha centrado en gran medida en el bloqueo y la adaptación. Nuestro trabajo deja claro que hay muchos puntos de dolor que el trabajo actual ha ignorado o no ha tenido en cuenta. Los ejemplos incluyen cómo converger rápidamente en una definición de coincidencia, cómo etiquetar de forma colaborativa, cómo depurar los bloqueadores y las coincidencias, y cómo actualizar un flujo de trabajo de EM si algo (por ejemplo, los datos y la definición de coincidencia) ha cambiado. Creemos que se debe dedicar más esfuerzo a abordar estos puntos dolorosos reales en la práctica.
Sistemas monolíticos vs. Ecosistemas de herramientas: Descubrimos que el EM es mucho más complicado de lo que pensábamos. Fundamentalmente, fue un proceso de «prueba y error», donde los usuarios siguieron experimentando hasta encontrar un flujo de trabajo EM satisfactorio. Como resultado, los usuarios probaron todo tipo de flujos de trabajo, personalización, procesamiento de datos, etc. (por ejemplo, véase Konda et al.10).
Debido a que el EM es tan desordenado y los usuarios quieren probar tantas cosas diferentes, encontramos que un ecosistema de herramientas es ideal. Para cada nuevo escenario que los usuarios quieran probar, podemos reunir rápidamente un conjunto de herramientas y una mini guía de cómo usarlas. Esto nos da mucha flexibilidad.
Muchos escenarios «de prueba» requieren sólo una parte de todo el ecosistema EM. Tener un ecosistema nos permite sacar muy rápidamente la parte necesaria, y las partes populares terminan siendo utilizadas en todas partes. Por ejemplo, varios paquetes de coincidencia de cadenas en PyMatcher son tan útiles en muchos proyectos (no sólo en EM) que terminaron siendo instalados en Kaggle, una popular plataforma de ciencia de datos.
La extensibilidad también es mucho más fácil con un ecosistema. Por ejemplo, recientemente, hemos desarrollado un nuevo comparador que utiliza el aprendizaje profundo para comparar datos textuales.11 Usamos PyTorch, una nueva biblioteca de Python, para desarrollarla, la lanzamos como un nuevo paquete de Python en el PyMatcher ecosistema, y luego extendimos nuestra guía para mostrar cómo usarlo. Esta guía, suavemente extendida PyMatcher con relativamente poco esfuerzo.
Claramente, podemos tratar de lograr los tres rasgos deseables anteriores (flexibilidad/personalizabilidad, reutilización parcial y extensibilidad) con sistemas monolíticos autónomos para EM, pero nuestra experiencia sugiere que sería significativamente más difícil hacerlo. Finalmente, encontramos que es más fácil para los investigadores académicos desarrollar y mantener herramientas (relativamente pequeñas) en un ecosistema, que los grandes sistemas monolíticos.
Usando múltiples entornos de ejecución (EEs): Encontramos que los usuarios a menudo quieren usar múltiples EEs para la EM. Por ejemplo, un usuario puede querer trabajar in situ usando su escritorio para experimentar y encontrar un buen flujo de trabajo de EM y luego subir y ejecutar el flujo de trabajo en una gran cantidad de datos en la nube. Mientras que el trabajo en las instalaciones, si el usuario tiene que realizar una tarea de cálculo intensivo, como la ejecución de un bloqueador, puede optar por mover esa tarea a la nube y ejecutarla allí. Del mismo modo, las tareas de colaboración, como el etiquetado y la limpieza de datos, suelen ejecutarse en la nube, utilizando interfaces web o en dispositivos móviles, aunque el usuario tome el autobús, por ejemplo.
Esto plantea dos desafíos. Primero, necesitamos desarrollar un ecosistema de herramientas EM para cada EE, por ejemplo, paquetes Python para el EE en las instalaciones, aplicaciones en contenedores para la nube, y aplicaciones móviles para teléfonos inteligentes. Segundo, necesitamos desarrollar formas de mover rápidamente datos, modelos y flujos de trabajo a través de los EE, para permitir a los usuarios cambiar sin problemas entre los EE. En Magallanes, hemos dado algunos pasos iniciales para abordar estos dos desafíos. Pero claramente queda mucho más por hacer.
Sirviendo tanto a los usuarios legos como a los usuarios poderosos: En Magallanes, hemos desarrollado PyMatcher como una solución para los usuarios de energía y CloudMatcher como una solución de autoservicio para usuarios no profesionales. Servir a ambos tipos de usuarios es importante, como sugiere nuestra experiencia con los equipos de EM y los equipos de negocios en las empresas, así como con los científicos del dominio en UW (ver sección 6).
Apoyo a la colaboración fácil: Encontramos que en muchos entornos de EM hay un equipo de personas que quieren trabajar en el problema. La mayoría de las veces, colaboran para etiquetar un conjunto de datos, depurar, limpiar los datos, etc. Sin embargo, la mayoría de las herramientas actuales de EM son rudimentarias para ayudar a los usuarios a colaborar de manera fácil y efectiva. Como los usuarios suelen estar en lugares diferentes, es importante que esas herramientas se basen en la nube, para permitir una colaboración fácil.
Gestionando el aprendizaje automático «en la naturaleza»: Nuestro trabajo deja claro que el ML puede ser muy beneficioso para el EM, principalmente porque proporciona una forma efectiva de capturar patrones complejos de coincidencia en los datos y de captar el conocimiento de los expertos del dominio sobre dichos patrones. La ML está claramente en el corazón de los flujos de trabajo de la EM apoyados por PyMatcher y CloudMatcher. En muchas aplicaciones del mundo real con las que hemos trabajado, el ML ayuda a mejorar significativamente la memoria aunque manteniendo una alta precisión, en comparación con las soluciones EM basadas en reglas.
Sin embargo, para nuestra sorpresa, el despliegue incluso de las técnicas tradicionales de ML para resolver los problemas de EM ya plantea muchos desafíos, como el etiquetado, la depuración, el manejo de nuevos datos, etc. Nuestra experiencia en el uso de PyMatcher también sugiere que los flujos de trabajo de EM más precisos probablemente impliquen una combinación de ML y reglas. En términos más generales, creemos que el ML debe ser usado efectivamente en conjunto con reglas artesanales, visualización, buena interacción con el usuario, y escalamiento de grandes datos, para poder realizar todo su potencial.
No puede funcionar con el EM en el aislamiento: Resultó que cuando se trabaja en la MUE, los usuarios suelen realizar una amplia variedad de tareas no relacionadas con la MUE, tales como explorar los datos (para ser comparados), comprenderlos, limpiarlos, extraer estructuras de los datos, etc. El usuario también suele realizar muchas de las denominadas tareas de DS, como la visualización, el análisis, etc., invocando las herramientas de DS (por ejemplo, llamando a Matplotlib o ejecutando un algoritmo de agrupación en scikit-learn). Peor aún, los usuarios a menudo intercalan estas tareas no-EM y DS con los pasos del proceso EM. Por ejemplo, si la precisión del flujo de trabajo actual de la EM es baja, los usuarios pueden querer limpiar los datos, luego volver a entrenar al emparejador de la EM de nuevo, y luego limpiar los datos un poco más, etcétera.
Como se ha descrito, la construcción de diferentes ecosistemas de herramientas para diferentes tareas (por ejemplo, EM, coincidencia de esquemas, limpieza, exploración y extracción) es subóptima, porque el cambio constante entre ellas crea muchos gastos generales. Más bien, creemos que es importante construir ecosistemas unificados de herramientas. Es decir, para la EE in situ, construir un (o varios) ecosistema que proporcione herramientas no sólo para la EM, sino también para la exploración, la comprensión, la limpieza, etc. Luego, repita para la nube y los EE móviles. Además, estos ecosistemas deberían «mezclarse» sin problemas con los ecosistemas de herramientas del SD, construyéndose encima de ellos.
En el futuro, continuaremos desarrollando los ecosistemas de las herramientas electromagnéticas tanto en las instalaciones como en las nubes. En particular, estamos prestando especial atención al ecosistema alojado en las nubes, donde además de CloudMatcherestamos desarrollando muchas otras herramientas de nubes para etiquetar, limpiar y explorar los datos. También estamos trabajando en formas para que los usuarios muevan sin problemas los datos, flujos de trabajo y modelos a través de estos dos ecosistemas. Por último, estamos buscando más aplicaciones del mundo real para «probar» Magallanes.
8. Conclusión
Hemos descrito a Magallanes, un proyecto para construir sistemas EM. El aspecto clave que distingue a Magellan es que, a diferencia de los sistemas EM actuales, que utilizan una plantilla de sistema monolítico autónomo RDBMS, Magellan toma prestadas ideas del campo de la ciencia de los datos para construir ecosistemas de herramientas EM interoperables. Nuestra experiencia con Magellan en los últimos años sugiere que esta nueva «plantilla de sistema» es muy prometedora para la EM. Además, creemos que también puede ser muy prometedor para otras tareas no relacionadas con la EM en la integración de datos, como la limpieza de datos, la extracción de datos y la concordancia de esquemas, entre otras.
Referencias
1. Taller sobre el análisis de datos de los seres humanos en el bucle, http://hilda.io/.
2. Christen P. Coincidencia de datos. Springer 2012.
3. Das, S., P.S.G.C., Doan, A., Naughton, J.F., Krishnan, G., Deep, R., Arcaute, E., Raghavendra, V., Park, Y. Falcon: Ampliación de la colaboración de entidades de origen colectivo para construir servicios de nube. En Actas de la Conferencia Internacional sobre Gestión de Datos de la ACM 2017, SIGMOD’17 (Nueva York, NY, EE.UU., 2017), ACM, 1431-1446.
4. Doan, A., y otros. Hacia un programa de construcción de sistemas para la integración de datos (y la ciencia de los datos). IEEE Data Eng. Bull. 41, 2 (2018), 35–46.
5. Doan, A., Halevy, A.Y., Ives, Z.G. Principios de integración de datos. Morgan Kaufmann, 2012.
6. Elmagarmid, A.K., Ipeirotis, P.G., Verykios, V.S. Detección de registros duplicados: Una encuesta. IEEE TKDE 19, 1 (2007), 1–16.
7. Govind, Y., et al. Cloudmatcher: Un servicio de nubes y multitudes para la comparación de entidades. En BIGDAS (2017).
8. Govind, Y., y otros. La coincidencia de entidades se ajusta a la ciencia de los datos: Un informe de progreso del proyecto Magallanes. En SIGMOD (2019).
9. Konda, Y., y otros. Magallanes: Hacia la construcción de sistemas de gestión de la concordancia de entidades. PVLDB 9, 12 (2016), 1197–1208.
10. Konda, P., y otros. Entidad ejecutante que coincide de extremo a extremo: Un estudio de caso. En EDBT (2019).
11. Mudgal, S., y otros. Deep learning for entity matching: A design space exploration. En IGMOD (2018).
12. Papadakis, G., y otros. The return of JedAI: End-to-End entity resolution for structured and semi-structured data. PVLDB 11, 12 (2018), 1950–1953.
13. Papadakis, G., y otros. Web-scale, Schema-Agnostic, End-to-End Entity Resolution. En La Conferencia Web (WWW), (Lyon, Francia, abril), 2018.
Volver al principio
Volver al principio
Notas a pie de página
* Otros autores son Sanjib Das (Google), Erik Paulson (Johnson Control), Palaniappan Nagarajan (Amazonas), Han Li (UW-Madison), Sidharth Mudgal (Amazonas), Aravind Soundararajan (Amazonas), Jeffrey R. Ballard (UW-Madison), Haojun Zhang (UW-Madison), Adel Ardalan (Univ. de Columbia) y otros.), Amanpreet Saini (UW-Madison), Mohammed Danish Shaikh (UW-Madison), Youngchoon Park (Johnson Control), Marshall Carter (American Family Ins.), Mingju Sun (American Family Ins.), Glenn M. Fung (American Family Ins.), Ganesh Krishnan (WalmartLabs), Rohit Deep (WalmartLabs), Vijay Raghavendra (WalmartLabs), Jeffrey F. Naughton (Google), Shishir Prasad (Instacart) y Fatemah Panahi (Google).
La versión original de este documento se titula «La coincidencia de entidades con la ciencia de los datos»: Un informe de progreso del Proyecto Magallanes» y fue publicado en Actas de la Conferencia SIGMOD 2019.
©2020 ACM 0001-0782/20/8
El permiso para hacer copias digitales o en papel de parte o de todo este trabajo para uso personal o en el aula se concede sin cargo, siempre que las copias no se hagan o distribuyan con fines de lucro o de ventaja comercial y que las copias lleven este aviso y la cita completa en la primera página. Los derechos de autor de los componentes de este trabajo que son propiedad de otros que no sean ACM deben ser respetados. Se permite hacer resúmenes con crédito. Para copiar de otra manera, para republicar, para publicar en servidores, o para redistribuir a listas, se requiere un permiso específico previo y/o una cuota. Solicite permiso para publicar en permissions@acm.org o por fax (212) 869-0481.
La Biblioteca Digital es publicada por la Asociación de Maquinaria de Computación. Derechos de autor © 2020 ACM, Inc.