

El reciente éxito de las redes neuronales profundas (DNN) ha inspirado un resurgimiento de las arquitecturas de dominio específico (DSA) para ejecutarlas, en parte como resultado de la desaceleración de la mejora del rendimiento de los microprocesadores debido a la ralentización de la Ley de Moore.17 Los DNN tienen dos fases: formaciónque construye modelos precisos, y inferenciaque sirve a esos modelos. La Unidad de Procesamiento Tensorial (TPU) de Google ofreció una mejora de 50 veces en el rendimiento por vatio sobre las arquitecturas convencionales para la inferencia.19,20 Naturalmente nos preguntamos si un sucesor podría hacer lo mismo para el entrenamiento. Este artículo explora cómo Google construyó la primera DSA de producción para el problema de entrenamiento mucho más difícil, desplegada por primera vez en 2017.
Ideas clave
Los arquitectos informáticos intentan crear diseños que maximicen el rendimiento en un conjunto de puntos de referencia y al mismo tiempo minimicen los costes, como los de fabricación o los de explotación.16 En el caso de los ASD como las TPU de Google, muchos de los principios y experiencias de décadas de construcción de CPU de uso general cambian o no se aplican. Por ejemplo, a continuación se presentan las características de la inferencia TPU (TPUv1) y de la formación TPU (TPUv2) que comparten pero que no son comunes en las CPU:
- 1-2 núcleos grandes frente a 32-64 núcleos pequeños en las CPU de los servidores.
- El levantamiento pesado computacional es manejado por matrices sistólicas bidimensionales (2D) de 128×128- o 256×256-elementos de multiplicadores por núcleo, frente a unos pocos multiplicadores escalares o multiplicadores SIMD (unidimensionales, 16-32-elemento) por núcleo en las CPUs.
- Usando datos más estrechos (8-16 bits) para mejorar la eficiencia de la computación y la memoria en comparación con 32-64 bits en las CPU.
- Dejando de lado las características de propósito general irrelevantes para los DNN pero críticas para las CPU como los cachés y los predictores de rama.
El entrenamiento de DNN más efectivo es el aprendizaje supervisado, donde empezamos con un enorme (a veces mil millones de ejemplos) conjunto de datos de entrenamiento de conocido-correcto (input, result) pares. Los pares pueden ser una imagen y lo que representa o una forma de onda de audio y el fonema que representa. También comenzamos con un modelo de red neuronal, que transforma la entrada en el resultado a través de un cálculo intensivo de pesos (también llamados parámetros); los pesos son aleatorios inicialmente. Los modelos se definen típicamente como un gráfico de capas, donde una capa contiene una parte de álgebra lineal (a menudo una multiplicación matricial o una convolución usando los pesos) seguida de una función de activación no lineal (a menudo una función escalar, aplicada elementalmente; llamamos a los resultados activaciones). El entrenamiento «aprende» pesos que aumentan la probabilidad de mapear correctamente desde la entrada hasta el resultado.
Para algunos tipos de datos de entrada, una incrustación al principio del modelo se transforma de representaciones escasas en una representación densa adecuada para el álgebra lineal; las incrustaciones también contienen pesos.27,29 Las incrustaciones pueden utilizar vectores en los que los rasgos pueden representarse mediante nociones de distancia entre vectores. Las incrustaciones implican búsquedas de tablas, travesías de enlaces y campos de datos de longitud variable, por lo que son irregulares y requieren mucha memoria.
¿Cómo pasamos de los pesos iniciales aleatorios a los pesos entrenados? Las mejores prácticas actuales utilizan variantes de descenso de gradiente estocástico (SGD).31 El SGD consiste en muchas iteraciones de tres pasos: propagación hacia adelante, retropropagación y actualización de peso. La propagación hacia adelante toma un ejemplo de entrenamiento elegido al azar, aplica sus entradas al modelo y ejecuta el cálculo a través de las capas para producir un resultado (que con los pesos iniciales aleatorios, es basura la primera vez). La propagación hacia adelante es funcionalmente similar a la inferencia del DNN, y si construyéramos un acelerador de inferencia, podríamos detenernos ahí. Para el entrenamiento, esto es menos de un tercio de la historia. El SGD a continuación mide la diferencia o error entre el resultado del modelo y el buen resultado conocido del conjunto de entrenamiento usando una función de pérdida. Luego, la retropropagación ejecuta el modelo en forma inversa, capa por capa, para producir un conjunto de valores de error/pérdida para el resultado de cada capa. Estas pérdidas miden la desviación del resultado deseado. Por último, la actualización de peso combina la entrada de cada capa con el valor de pérdida para calcular un conjunto de deltas -cambios en los pesos- que, al añadirse a los pesos, habrían dado como resultado una pérdida casi nula. Las actualizaciones pueden tener una pequeña magnitud. Al reducirse aún más, las actualizaciones se reducen según la tasa de aprendizaje para mantener el SGD numéricamente estable. Además, un conjunto de refinamientos algorítmicos, incluyendo el impulso,30 la normalización de los lotes,18 y optimizadores como el Gradiente Adaptativo (AdaGrad)14-requieren su propio estado y alteran el algoritmo del SGD para reducir el número de pasos para lograr la precisión deseada.
La sabiduría de la DNN (Red Neural Profunda) es que las máquinas más grandes conducen a mayores avances.
Cada paso del SGD hace un pequeño ajuste de los pesos que mejora el modelo con respecto a un solo (input, result) par. Cada paso a través de todo el conjunto de datos es un épocaLos DNNs típicamente toman de diez a cientos de épocas para entrenar. El SGD transforma gradualmente los pesos aleatorios iniciales en un modelo entrenado, a veces capaz de una precisión sobrehumana.
Dados estos antecedentes, podemos comparar la inferencia y el entrenamiento. Ambos comparten algunos elementos computacionales incluyendo multiplicaciones de la matriz, convoluciones y funciones de activación, por lo que los ASD de inferencia y entrenamiento podrían tener unidades funcionales similares. Los aspectos arquitectónicos clave en los que los requisitos difieren incluyen:
- Paralelización más dura: Cada inferencia es independiente, por lo que un simple grupo de servidores con chips DSA puede ampliar la inferencia. Una ejecución de entrenamiento itera sobre millones de ejemplos, coordinándose a través de recursos paralelos porque debe producir un único conjunto consistente de pesos para el modelo. El número de ejemplos procesados en paralelo, y el tiempo para evaluar ese ejemplo múltiple minibatch-a menudo acortado a lote-…afectan directamente al tiempo total de entrenamiento de principio a fin. A paso es la computación para procesar un mini-reloj.
- Más cálculos: La retropropagación requiere derivados para cada cálculo en un modelo. Incluye funciones de activación (algunas de las cuales son trascendentales), y la multiplicación por matrices de peso transpuestas.
- Más memoria: La actualización del peso accede a valores intermedios de propagación hacia adelante y hacia atrás, lo que aumenta enormemente los requisitos de almacenamiento; el almacenamiento temporal puede ser 10x almacenamiento de peso. Por inferencia, un pequeño juego de trabajo de activación puede ser guardado en un chip.
- Más programabilidad: Los algoritmos y modelos de entrenamiento cambian continuamente, por lo que una máquina restringida a los algoritmos de mejores prácticas actuales durante el diseño podría quedar rápidamente obsoleta.
- Datos más amplios: La aritmética cuantificada -un entero de 8 bits en lugar de un punto flotante (FP) de 32 bits- puede funcionar para la inferencia como en el TPUv1, pero el entrenamiento de precisión reducida es un área de investigación activa.21,25 El reto es capturar suficientemente la suma de SGD de muchas pequeñas actualizaciones de peso para preservar la precisión del uso de la aritmética FP de 32 bits para entrenar los modelos.
Después de explicar la arquitectura de TPUv2, describimos el lenguaje específico del dominio (TensorFlow) y el compilador (XLA) para TPUv2 y comparamos las opciones de arquitectura y tecnología para el TPUv2 frente a una GPU, el ordenador más popular para la formación de DNN. Más adelante, comparamos el rendimiento por chip y las supercomputadoras completas de las TPU y las GPU utilizando aplicaciones de producción y los puntos de referencia del MLPerf.
Diseño de una supercomputadora de dominio específico
En 2014, cuando comenzó el proyecto TPUv2, el panorama de la computación de alto rendimiento para el aprendizaje de la máquina era muy diferente al de hoy. El entrenamiento se llevó a cabo en clusters de CPUs. El entrenamiento paralelo de última generación utilizó el SGD asíncrono,12 en parte para tolerar las latencias de la cola en los cúmulos compartidos. La formación paralela también dividió las CPU en un gráfico bipartito de trabajadores (que ejecuta el bucle SGD) y servidores de parámetros (que alojan los pesos y añaden actualizaciones a los mismos).
El apetito de entrenamiento de DNN parecía ilimitado. (De hecho, los requisitos de computación para las mayores carreras de entrenamiento crecieron 10 veces al año de 2012 a 2018.2) Por lo tanto, en 2014 elegimos construir una supercomputadora DSA en lugar de agrupar los anfitriones de la CPU con chips DSA. La primera razón es que el tiempo de entrenamiento es enorme. La tabla 1 muestra que un chip TPUv2 llevaría de dos a 16 meses para entrenar una sola aplicación de producción de Google, así que una aplicación típica podría querer usar cientos de chips. En segundo lugar, la sabiduría del DNN es que los conjuntos de datos más grandes y las máquinas más grandes conducen a mayores avances. Además, los resultados como el AutoML utilizan 50 veces más computación para encontrar modelos de DNN que logren mayores puntuaciones de precisión que los mejores modelos de los expertos humanos en DNN.42

Tabla 1. Días para entrenar programas de producción en un chip TPUv2.
Diseñando una interconexión de supercomputadoras DSA. La característica de la arquitectura crítica de una supercomputadora moderna es la forma en que sus chips se comunican: cuál es la velocidad de un enlace, cuál es la topología de interconexión, si tiene conmutadores centralizados frente a distribuidos, etc. Esta elección es mucho más fácil para una supercomputadora DSA, ya que los patrones de comunicación son limitados y conocidos. Para el entrenamiento, la mayoría del tráfico es una actualización de todos los nodos de la máquina.
Si distribuimos la funcionalidad del interruptor en cada chip en lugar de como una unidad autónoma, la reducción total puede construirse de una manera dimensionalmente equilibrada y con un ancho de banda óptimo para una topología de toro 2D (ver Figura 1). Un interruptor en el dispositivo proporciona un circuito virtual, un enrutamiento sin bloqueo. Para habilitar un toro 2D, el chip tiene cuatro enlaces Inter-Core Interconnect (ICI) personalizados, cada uno de los cuales funciona a 496Gbits/s por dirección en TPUv2. El ICI permite conexiones directas entre los chips para formar una supercomputadora usando sólo el 13% de cada chip (ver Figura 3). Los enlaces directos simplifican el despliegue a nivel de rack, pero en un sistema multi-rack los racks deben ser adyacentes.
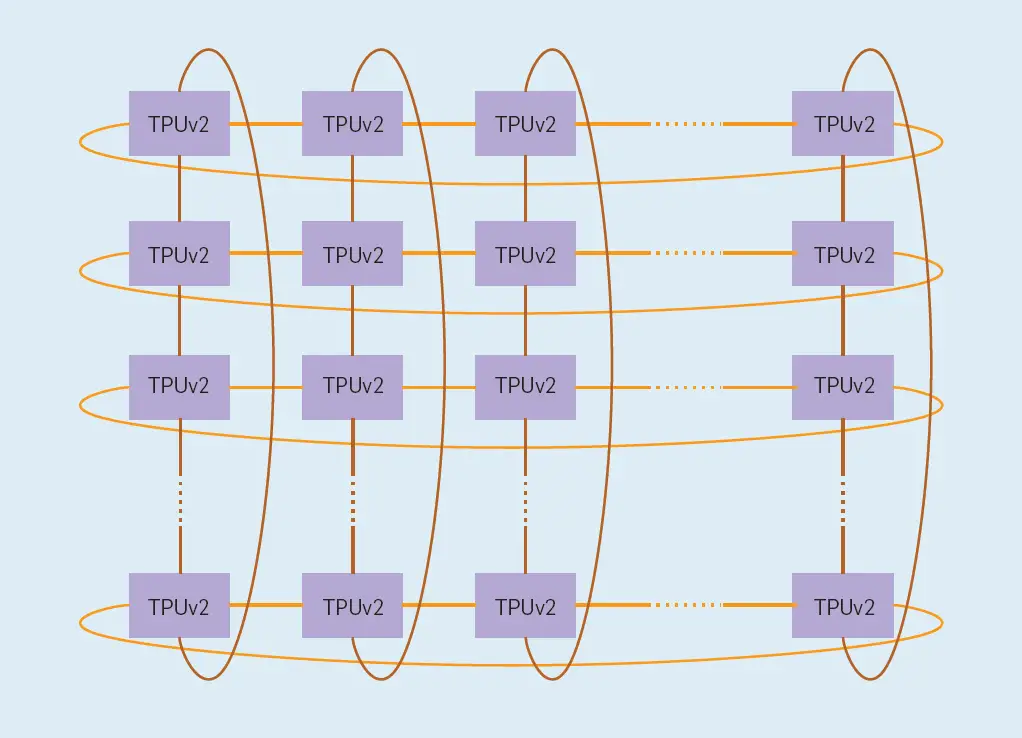
Figura 1. Una topología de toro 2D. El TPUv2 utiliza un toro 2D de 16×16.
Una medida de una interconexión es su ancho de banda de la bisección-el ancho de banda disponible entre dos mitades de una red del peor de los casos. La supercomputadora TPUv2 utiliza un toro 2D de 16×16 (256 chips), que es 32 enlaces x 496Gbits/s = 15,9Terabits/s de ancho de banda de la bisección. A modo de comparación, un conmutador Infiniband separado (utilizado en los clusters de CPU) que conectó 64 hosts (cada uno con, digamos, cuatro chips DSA) tiene 64 puertos que utilizan «sólo» enlaces de 100Gbits/s y un ancho de banda de bisección de como máximo 6,4Terabits/s. Nuestra supercomputadora TPUv2 proporciona 2,5 veces el ancho de banda de bisección sobre los conmutadores de clúster convencionales, saltándose el coste de las tarjetas de red Infiniband, el conmutador Infiniband y los retrasos en la comunicación al pasar por los hosts de CPU de los clústeres.
Fortuitamente, la construcción de una rápida interconexión inspiró avances algorítmicos. Con un hardware dedicado, y deshaciendo los ejemplos de un minibatch sobre los nodos de la máquina, hay poca latencia de cola, y el entrenamiento paralelo sincrónico se hace posible. Estudios internos5 sugería que el entrenamiento sincrónico podía vencer al SGD asincrónico con recursos equivalentes. El entrenamiento asíncrono introduce heterogeneidad más servidores de parámetros que eventualmente limitan la paralelización, ya que los pesos se desbaratan y el ancho de banda de los servidores de parámetros a los trabajadores se convierte en un cuello de botella. El entrenamiento síncrono eliminó los servidores de parámetros permitiendo el peer-to-per entre los trabajadores, usando el todo-reductor para asegurar que los trabajadores comiencen y terminen cada paso paralelo con copias consistentes de las pesas.
El entrenamiento sincrónico tiene dos fases en el camino crítico: una fase de cálculo y una fase de comunicación que reconcilia los pesos entre los alumnos. Los alumnos más lentos y los mensajes más lentos a través de la red limitan el rendimiento de un sistema sincrónico de este tipo. Dado que la fase de comunicación está en el camino crítico, una interconexión rápida que concilie rápidamente los pesos entre los alumnos con latencias de cola bien controladas es fundamental para un entrenamiento rápido. La red ICI es clave para los excelentes resultados de escalado de la supercomputadora TPU; más tarde mostramos un 96%-99% de escalado lineal perfecto.
Diseñando un nodo de supercomputadora DSA. El nodo TPUv2 del superordenador siguió las ideas principales del TPUv1: Una gran unidad multiplicadora de matriz bidimensional (MXU) que utiliza una matriz sistólica para reducir el área y la energía, además de grandes memorias en chip controladas por software en lugar de cachés. Las grandes MXU de los TPU dependen de grandes tamaños de lotes, que amortizan los accesos a la memoria por pesos – el rendimiento a menudo aumenta cuando el tráfico de la memoria se reduce.
Shallue et al.32 examinó el efecto del aumento del tamaño de los lotes en el tiempo de entrenamiento, y encontró tres regiones para todos los modelos (como se ve en el Cuadro 2):
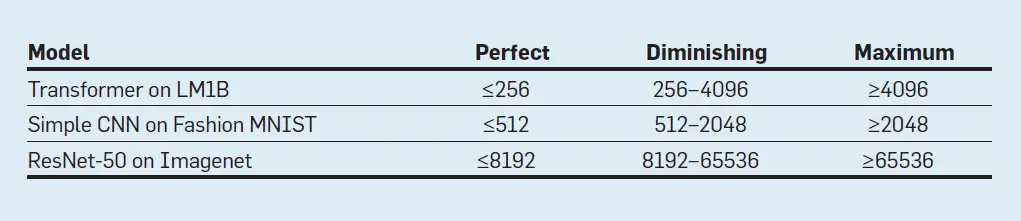
Tabla 2. Tamaño de los lotes de las tres regiones de Shallue.32 LM1B, Fashion MNIST, e Imagenet son conjuntos de datos estándar de DNN.
- Región de escalada perfecta: Cada duplicación del tamaño del lote reduce a la mitad el número de pasos de entrenamiento.
- Disminución de la región de retornos: Aumentar el tamaño del lote sigue reduciendo el número de pasos, pero más lentamente.
- Región de máximo paralelismo de datos: El aumento del tamaño de los lotes no proporciona ningún beneficio.
Tal escalamiento, al tiempo que se preservaba la precisión, requería ajustar la tasa de aprendizaje, el tamaño del lote y otros hiperparámetros.
Afortunadamente para las TPU, estos resultados recientes muestran que los tamaños de lote de 256-8.192 escalan perfectamente sin perder precisión, lo que hace que las MXU grandes sean una opción atractiva para el alto rendimiento.
A diferencia de la TPUv1, la TPUv2 utiliza dos núcleos por chip. Los cables globales de un chip no se escalan al reducirse el tamaño de la característica, por lo que su retardo relativo aumenta. Dado que la formación puede utilizar muchos procesadores, dos TensorCores más pequeños por chip evitaron las excesivas latencias de un único núcleo grande de chip completo. Nos detuvimos en dos porque es más fácil generar eficientemente programas para dos núcleos musculosos por chip que numerosos núcleos débiles.
La figura 2 muestra los seis bloques principales de un TensorCore y la figura 3 muestra su ubicación en el chip TPUv2:
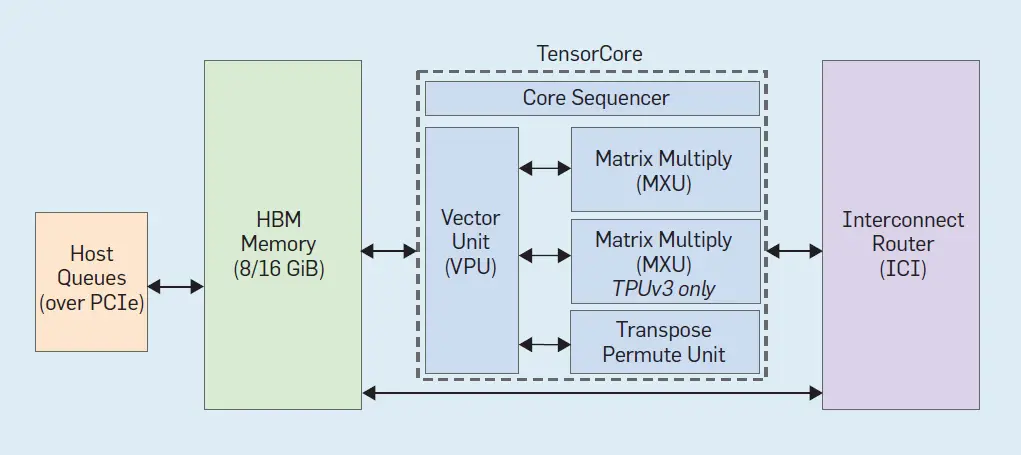
Figura 2. Diagrama de bloques de un TensorCore (nuestro nombre de desarrollo interno para un núcleo de TPU, y no relacionado con los Tensores Cores de las GPUs NVIDIA).
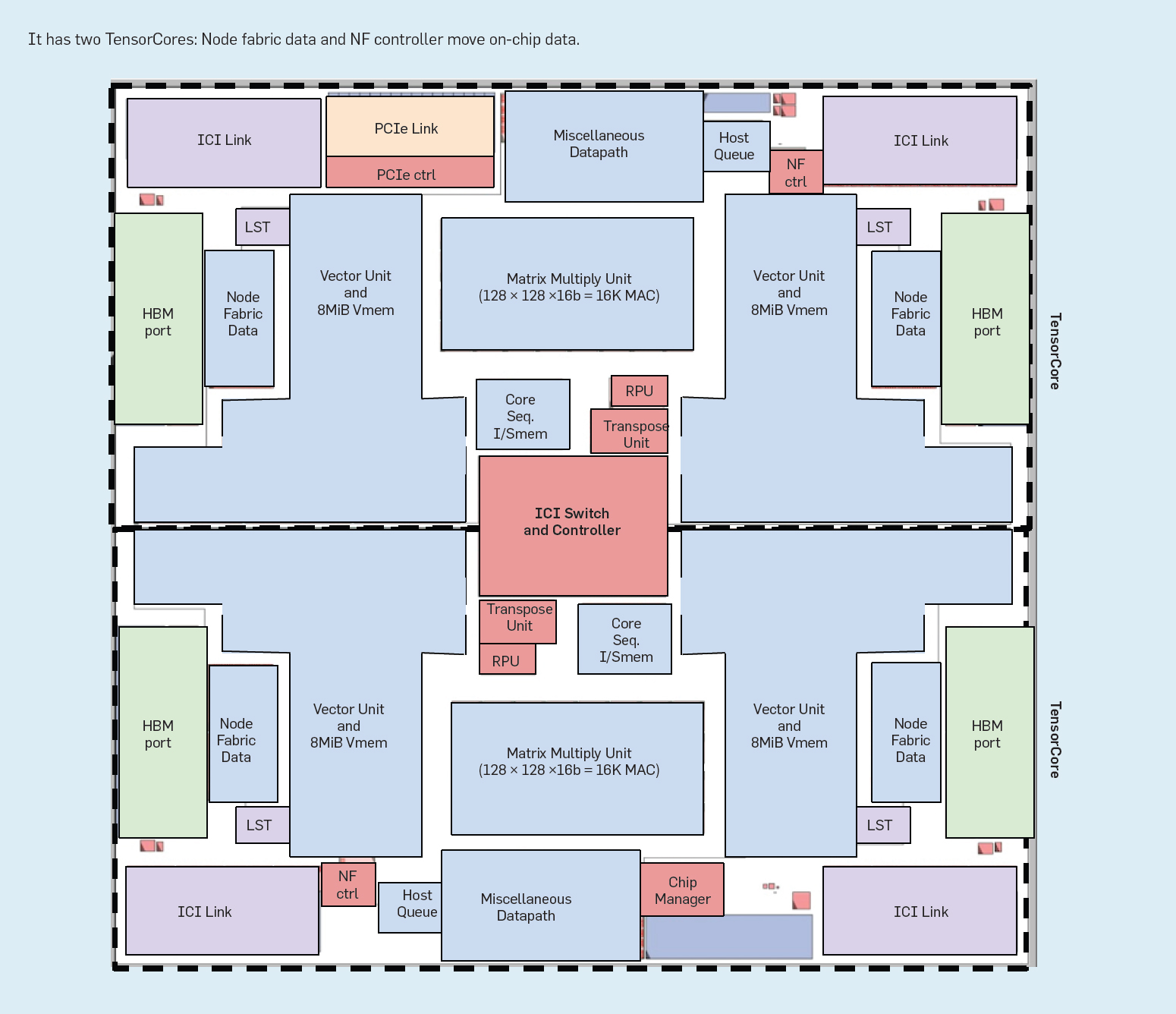
Figura 3. Plano del chip TPUv2.
- Interconexión Inter-Core (ICI). Explicado antes.
- Memoria de banda ancha (HBM). El TPUv1 estaba ligado a la memoria para la mayoría de sus aplicaciones.20 Resolvimos su cuello de botella de memoria usando DRAM de memoria de banda ancha (HBM) en TPUv2. Ofrece 20 veces el ancho de banda de TPUv1 usando un sustrato interpuesto que conecta el chip TPUv2 a través de treinta y dos buses de 128 bits a cuatro pilas cortas de chips DRAM. Los servidores convencionales soportan muchos más chips DRAM, pero con un ancho de banda mucho menor de como mucho ocho buses de 64 bits.
- El Secuenciador del núcleo busca VLIW (Una palabra de instrucción muy larga) del núcleo en el chip, la Memoria de Instrucciones gestionada por software (Imem), ejecuta operaciones escalares utilizando una memoria de datos escalares de 4K 32 bits (Smem) y 32 registros escalares de 32 bits (Sregs), y reenvía las instrucciones vectoriales a la VPU. La instrucción VLIW de 322 bits puede lanzar ocho operaciones: dos escalares, dos vectores ALU, carga y almacenamiento de vectores, y un par de ranuras que ponen en cola los datos hacia y desde la matriz multiplican y transponen las unidades. El compilador XLA programa la carga de Imem a través de superposiciones independientes de código, ya que, a diferencia de las CPU convencionales, no existe un caché de instrucciones.
- El Unidad de Procesamiento de Vectores (VPU) realiza operaciones de vectores utilizando un gran chip memoria vectorial (Vmem) con 32K 128 elementos de 32 bits (16MiB), y 32 2D registros vectoriales (Vregs) que contienen cada uno 128 x 8 elementos de 32 bits (4 KiB). La VPU transmite datos hacia y desde la MXU a través del desacoplamiento de los FIFO. La VPU recoge y distribuye datos al Vmem a través de paralelismo en el nivel de datos (unidades funcionales de matriz y vectorial 2D) y paralelismo a nivel de instrucción (8 operaciones por instrucción).
Su hermoso DSA puede fallar si los algoritmos de mejores prácticas cambian, haciéndolo prematuramente obsoleto. Manejamos tal crisis en 2015 durante nuestro diseño para apoyar la normalización de los lotes.18 Brevemente, la normalización de los lotes resta la media y la divide por la desviación estándar de un lote, haciendo que los valores parezcan muestras de la distribución normal. En la práctica, mejora la precisión de la predicción y reduce el tiempo de entrenamiento hasta 14 veces. La normalización de los lotes surgió a principios de 2015, y los resultados nos obligaron a hacerlo. La dividimos en sumas y multiplicaciones vectoriales sobre el lote, más un cálculo de raíz cuadrada inversa. Sin embargo, el recuento de operaciones vectoriales era alto. Por lo tanto, añadimos una segunda dimensión SIMD a nuestra unidad vectorial, haciendo sus registros y ALUs 128×8 (en lugar de sólo ID 128 de ancho) y añadiendo una operación de raíz cuadrada inversa a la unidad trascendental.
- La MXU produce productos de 32 bits FP a partir de entradas de 16 bits FP que se acumulan en 32 bits. Todos los demás cálculos son en FP de 32 bits, excepto los resultados que van directamente a una entrada de la MXU, que se convierten en FP de 16 bits.
Las MXU son grandes, pero hemos reducido su tamaño de 256×256 en TPUv1 a 128×128 y tienen múltiples MXU por chip. El ancho de banda necesario para alimentar y obtener resultados de una MXU es proporcional a su perímetro, mientras que el cálculo que proporciona es proporcional a su área. Las matrices más grandes proporcionan más cálculo por byte de ancho de banda de la interfaz, pero las matrices más grandes pueden ser ineficientes. Las simulaciones muestran que la utilización del modelo convolucional de cuatro MXU de 128×128 es de 37%-48%, lo que es 1,6x de un solo MXU de 256×256 (22%-30%) y sin embargo toma más o menos la misma área del dado. La razón es que algunas convoluciones son naturalmente más pequeñas que 256×256, por lo que las secciones de la MXU estarían inactivas. Dieciséis MXU de 64×64 tendrían una utilización un poco mayor (38%-52%) pero necesitarían más área. La razón es que el área de la MXU está determinada por la lógica de los multiplicadores o por los cables de su perímetro para las entradas, salidas y control. En nuestra tecnología, para 128×128 y más grandes el área de la MXU está limitada por los multiplicadores pero el área para 64×64 y más pequeñas MXU está limitada por los cables de E/S y control.
- El Unidad de reducción de transposición de permuta hace transposiciones de matriz de 128×128, reducciones y permutaciones de los carriles de la VPU.
Diseños alternativos de nodos de supercomputadoras DSA. El artículo del TPUv1 evaluó alternativas hipotéticas que examinaban los cambios en el rendimiento al variar el tamaño del MXU, la velocidad del reloj y el ancho de banda de la memoria.20 No necesitamos hacer una hipótesis aquí, ya que implementamos y desplegamos dos versiones de la arquitectura de entrenamiento: TPUv2 y TPUv3. TPUv3 tiene ≈1.35x la velocidad del reloj, el ancho de banda del ICI y el ancho de banda de la memoria más el doble de la cantidad de MXU, por lo que el rendimiento máximo se eleva 2.7x. El líquido enfría el chip para permitir 1,6 veces más potencia. También expandimos la supercomputadora TPUv3 a 1024 chips (ver Figura 4). La Tabla 3 enumera las características clave de las tres generaciones de TPU junto con una GPU contemporánea (NVIDIA Volta) que compararemos a continuación.

Figura 4. Una supercomputadora TPUv2 tiene hasta 256 chips y mide 18 pies de largo (arriba).
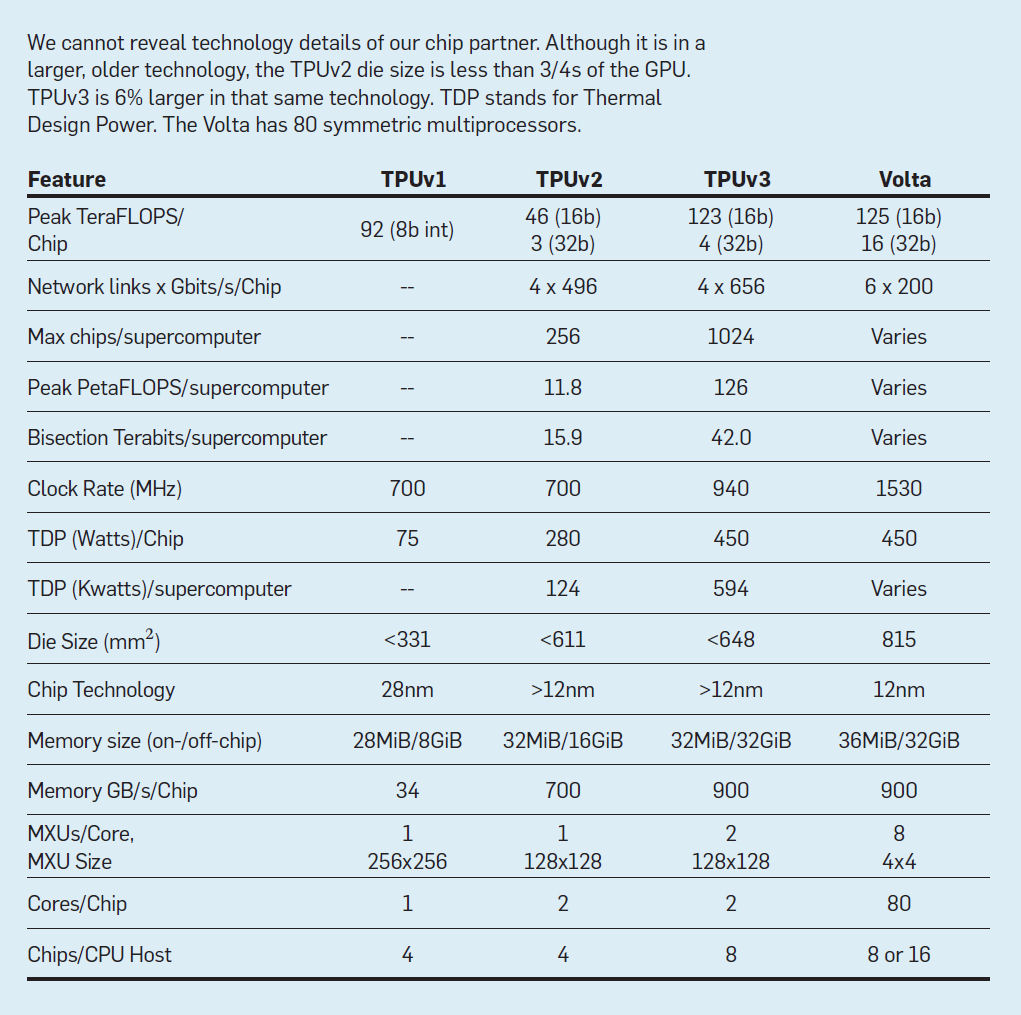
Tabla 3. Características principales del procesador.
El tamaño de la matriz de TPUv3 es sólo un 6% mayor que el de TPUv2 en la misma tecnología, a pesar de tener el doble de MXU por TensorCore simplemente porque los ingenieros tuvieron una mejor idea de antemano de los retos de diseño de los principales bloques en TPUv2, lo que condujo a un plano más eficiente para TPUv3.
Diseñando la aritmética de la supercomputadora DSA. El rendimiento máximo es ≥8x mayor cuando se utiliza FP de 16 bits en lugar de FP de 32 bits para la multiplicación de la matriz (véase la Tabla 3), por lo que es vital utilizar 16 bits para obtener el máximo rendimiento. Aunque podríamos haber construido una MXU usando los formatos de punto flotante estándar IEEE fp16 y fp32 (ver Figura 5), primero comprobamos la precisión de las operaciones de 16 bits para los DNN. Encontramos que:
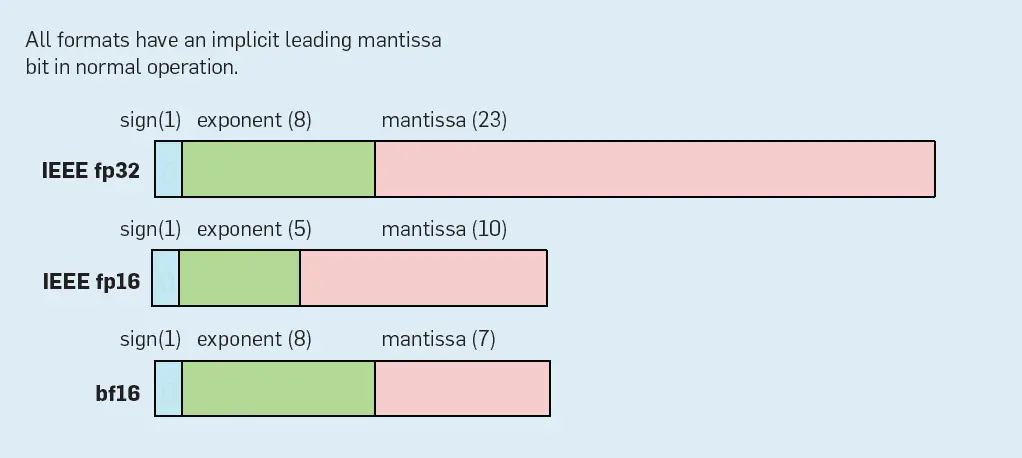
Figura 5. Formatos IEEE FP y Brain float.
- Los resultados de la multiplicación de la matriz y las sumas internas deben permanecer en fp32.
- El exponente de 5 bits de las entradas de multiplicación de la matriz fp16 lleva al fracaso de los cálculos que se salen de su estrecho rango, lo que el exponente de 8 bits de fp32 evita.
- Reducir el tamaño de la mantisa de entrada de la multiplicación de la matriz de 23 bits de fp32 a 7 bits no perjudicó la precisión.
El resultado formato flotante del cerebro (bf16) en la figura 5 mantiene el mismo exponente de 8 bits que fp32. Dado el mismo tamaño de exponente, no hay peligro de perder los pequeños valores de actualización debido al flujo insuficiente de FP de un exponente más pequeño, por lo que todos los programas de este artículo utilizaron bf16 en los TPU sin mucha dificultad. Más allá de nuestra experiencia de que funciona para aplicaciones de producción de entrenamiento, un reciente estudio de Intel corroboró sus beneficios.21 Sin embargo, el fp16 requiere ajustes en los programas informáticos de capacitación (escalado de pérdidas) para lograr la convergencia y la eficiencia. Preserva el efecto de los pequeños gradientes escalando las pérdidas para que se ajusten a los exponentes más pequeños de fp16.26
Como el tamaño de un multiplicador de FP escala con el cuadrado de la mantissa el multiplicador bf16 es media el tamaño y la energía de un multiplicador fp16: 82 / 112 ≈ 0.5 (teniendo en cuenta el bit de mantisa principal implícito). Bf16 ofrece una rara combinación: reducir el hardware y la energía mientras se simplifica el software haciendo innecesario el escalado de pérdidas. Por lo tanto, ARM e Intel han revelado los futuros chips con bf16.
Diseñando un compilador de supercomputadora DSA
El siguiente paso era conseguir software para nuestro hardware. Para programar las CPUs y GPUs para el aprendizaje de la máquina, un marco como TensorFlow (TF)1 especifica el modelo y las operaciones de datos de forma independiente de la máquina. TF es una biblioteca de dominio específico construida en Python. El trabajo dependiente de la GPU de NVIDIA está soportado por una combinación del lenguaje CUDA, las librerías CuBLAS y CuDNN, y el sistema TensorRT. Los TPUv2/v3 también utilizan TF, con el nuevo sistema XLA (para álgebra lineal acelerada) manejando el mapeo dependiente de TPU. XLA también tiene como objetivo las CPU y las GPU. Al igual que muchos sistemas que mapean desde lenguajes específicos de dominio al código, XLA integra una biblioteca de alto nivel y un compilador. Un front end TF genera código en una representación intermedia para XLA.
Parece que debería ser más difícil conseguir un gran rendimiento en un sistema de programación basado en Python como TF. Sin embargo, los marcos ML ofrecen tanto un mayor nivel de expresividad como la posibilidad de obtener una información de optimización mucho mejor que los lenguajes de menor nivel como C++. Los programas TF son gráficos de operaciones, donde las operaciones de matriz multidimensional son ciudadanos de primera clase:
- Operan en matrices multidimensionales explícitamente, en lugar de implícitamente a través de bucles anidados como en C++.
- Utilizan patrones de acceso a datos explícitos, analizables y delimitados frente a patrones de acceso arbitrarios como C++.
- Han conocido un comportamiento de alias de memoria, a diferencia de C++.
Estos tres factores permiten al compilador XLA transformar de forma segura y correcta los programas en formas que los compiladores tradicionales raramente logran.
XLA hace análisis y optimización de todo el programa. Con los registros vectoriales 2D y las unidades de cálculo en TPUv2/v3, la disposición de los datos tanto en las unidades de cálculo como en la memoria es crítica para el rendimiento, quizás más que para un procesador vectorial o SIMD. La creación de un código eficiente para las máquinas vectoriales, con memoria 1D y unidades de cálculo, se entiende bien. Para la MXU, dos entradas 2D interactúan para producir una salida 2D. Cada operando tiene una disposición de memoria, que se transforma en una disposición en registros 2D, que a su vez deben ser alimentados en el momento exacto para cumplir con la sincronización de la matriz sistólica en la MXU. (Una matriz sistólica reduce los accesos al registro coreografiando los datos que fluyen desde diferentes direcciones para llegar regularmente a los puntos de cruce que los combinan). Dependiendo de las opciones de diseño, las dimensiones de los registros 2D de 128 y 8 podrían no llenarse, disminuyendo la ALU y la utilización de la memoria. Además, al carecer de cachés, XLA gestiona todas las transferencias de memoria, incluyendo superposiciones de códigos y empujes DMA a nodos remotos sobre ICI.
El XLA explota el enorme paralelismo que representa un gráfico de flujo de datos de entrada TF. Más allá del paralelismo de las operaciones («ops») en un gráfico, cada operación puede comprender millones de multiplicaciones y sumas en tensores de datos de millones de elementos. XLA mapea este abundante paralelismo a través de cientos de chips en una supercomputadora, unos pocos núcleos por chip, múltiples unidades por núcleo, y miles de multiplicadores y sumadores dentro de cada unidad funcional. El lenguaje TF específico del dominio y la representación XLA permiten un razonamiento preciso sobre el uso de la memoria en cada punto del programa. No existen problemas de «aliasing» en los que el compilador deba determinar si dos punteros pueden dirigirse a la misma memoria -cada pieza de memoria corresponde a una variable de programa conocida o temporal. El compilador XLA es libre de rebanar, organizar y distribuir la memoria y las operaciones para utilizar mejor el ancho de banda de la memoria en el chip y reducir la huella de la memoria en el chip o fuera de él.
Los TPUs usan una arquitectura VLIW para expresar el paralelismo a nivel de instrucción con las muchas unidades de cálculo de un TensorCore. XLA utiliza técnicas de compilación estándar de VLIW, incluyendo el desenrollado de bucles, la programación de instrucciones y la canalización de software para mantener todas las unidades de cálculo ocupadas y para mover simultáneamente los datos a través de la jerarquía de memoria para alimentarlas.
Dada una disposición de memoria de datos, fusión del operador puede reducir el uso de la memoria y aumentar el rendimiento. La fusión es una optimización tradicional de los compiladores -pero aplicada ahora a los datos 2D- que combina operaciones para reducir el tráfico de memoria en comparación con la ejecución de los operadores de forma secuencial. Por ejemplo, al fusionar una multiplicación de matriz con una función de activación posterior se salta la escritura y la lectura de los productos intermedios de la memoria. El cuadro 4 muestra que la velocidad de la optimización de la fusión en los datos 2D es de 1,8 a 6,3.
![]()
Tabla 4. XLA acelera en TPUv2 con fusión versus sin fusión.
La forma intermedia de TF para XLA tiene miles de operaciones. El número de operaciones aumenta cuando los programadores no pueden combinar las operaciones existentes si la composición es ineficiente. Desgraciadamente, ampliar el número de ops es un desafío de ingeniería, ya que es necesario desarrollar bibliotecas de software para CPU, GPU y TPU. La esperanza era que el compilador XLA pudiera sintetizar estos miles de ops a partir de un conjunto más pequeño de ops primitivas.
El equipo XLA sólo necesitó 96 operaciones como objetivo del compilador para reducir el trabajo de la biblioteca/compilador mejorando la composición. Por ejemplo, XLA tiene una sola operación para la convolución (kConvolution) dejando que el compilador se encargue de todas las variaciones de la disposición de la memoria. La forma intermedia de TF tiene nueve; por ejemplo, Conv2D, Conv2dBackpropFilter, DepthwiseConv2dNative…y… DepthwiseConv2dNativeBackprop-Filter. Para el programa CNN1, el compilador XLA fusionó 63 operaciones diferentes con al menos una kConvolution.
Dado que las plataformas de ML y los DSA ofrecían un nuevo conjunto de desafíos de compilación, no estaba claro a qué velocidad mejorarían. La Tabla 5 muestra que la ganancia media en sólo seis meses para MLPerf de la versión 0.5 a 0.6 fue de 1.3x para las GPU y 2.1x para las TPU! (Tal vez el compilador XLA más joven tenga más oportunidades de mejorar que la pila CUDA más madura). Una de las razones de esta gran ganancia es el enfoque en los puntos de referencia, pero las aplicaciones de producción también avanzan. El aumento del uso de bf16, la optimización de la arquitectura del modelo y la generación de XLA de un mejor código aceleró el CNN0 en 1,8x en 15 meses y la mejora de la partición/ubicación para las incrustaciones y las optimizaciones de XLA aceleró el MLP0 en 1,65x.

Tabla 5. Aceleración del MLPerf 0,6 sobre 0,5 en seis meses.
Contrastando las arquitecturas de GPU y TPU
Como los detalles de las arquitecturas de TPU y GPU son ahora públicos, comparemos las opciones de TPU y GPU antes de comparar el rendimiento.
La paralelización multichip está incorporada en los TPU a través de la ICI y apoyada a través de operaciones de reducción total que van desde el XLA hasta el TF. Los sistemas de GPU multichip de tamaño similar utilizan un enfoque de red por niveles, con el NVLink de NVIDIA dentro de un chasis y redes y conmutadores InfiniBand controlados por el host para unir varios chasis.
Los TPUs ofrecen aritmética bf16 FP diseñada para DNNs dentro de matrices sistólicas de 128×128 que reduce a la mitad el área y la energía del dado frente a los multiplicadores IEEE fp16 FP. Las GPUs Volta también han adoptado matrices sistólicas de precisión reducida, con una granularidad más fina -4×4 o 16×16 dependiendo de las descripciones del hardware o el software- mientras utilizan fp16 en lugar de bf16, por lo que pueden requerir software para realizar el escalado de pérdidas más el área y la energía extra del dado.
Las TPU son máquinas de doble núcleo, de pedido, en las que el compilador XLA se superpone a las actividades de computación, memoria y red. Las GPU son máquinas de muchos núcleos con tolerancia a la latencia, donde cada núcleo tiene muchos hilos y, por lo tanto, archivos de registro muy grandes (20MiB). El hardware de los hilos, además de las convenciones de codificación de CUDA, soporta operaciones superpuestas.
Los TPUs usan memorias de 32MiB para scratchpad controladas por software que el compilador programa, mientras que el hardware de Volta maneja un caché de 6MiB y el software maneja una memoria de 7.5MiB para scratchpad. El compilador XLA dirige los accesos secuenciales DRAM típicos de las DNN a través de controladores de acceso directo a la memoria (DMA) en las TPU, mientras que las GPU utilizan multihilo y hardware de coalescencia para ellos.
Thottethodi y Vijaykumar35 llegó a la conclusión de que, en comparación con las UTP:
«[[GPU] incurren en una gran sobrecarga de rendimiento, área y energía debido a la pesada multihiladura que es innecesaria para las DNN que tienen accesos de memoria secuenciales preestablecidos. La organización sistólica [[de TPU]… captura[[s] La reutilización de los datos de los DNNs es simple evitando el multihilo».
Además de las opciones arquitectónicas contrastadas, los chips de TPU y GPU utilizan diferentes tecnologías, áreas de troquelado, velocidades de reloj y potencia. La tabla 6 da tres medidas de coste relacionadas de estos sistemas: tamaño aproximado del troquel ajustado a la tecnología; potencia para un sistema de 16 chips; y precio de la nube por chip. El tamaño del troquel ajustado a la GPU es más del doble que el de las TPU, lo que sugiere que el costo de capital de los chips es por lo menos el doble, ya que habría por lo menos el doble de troqueles de TPU por oblea. La potencia de la GPU es 1,3x-1,6x mayor, lo que sugiere mayores gastos de explotación, ya que el coste total de propiedad está correlacionado con la potencia.19 Finalmente, los precios de alquiler por hora en Google Cloud Engine son 1.6x-2.9x más altos para la GPU. Estas tres medidas diferentes sugieren consistentemente que el TPUv2 y el TPUv3 son aproximadamente de la mitad a tres cuartas partes más caros que la GPU del Volta.
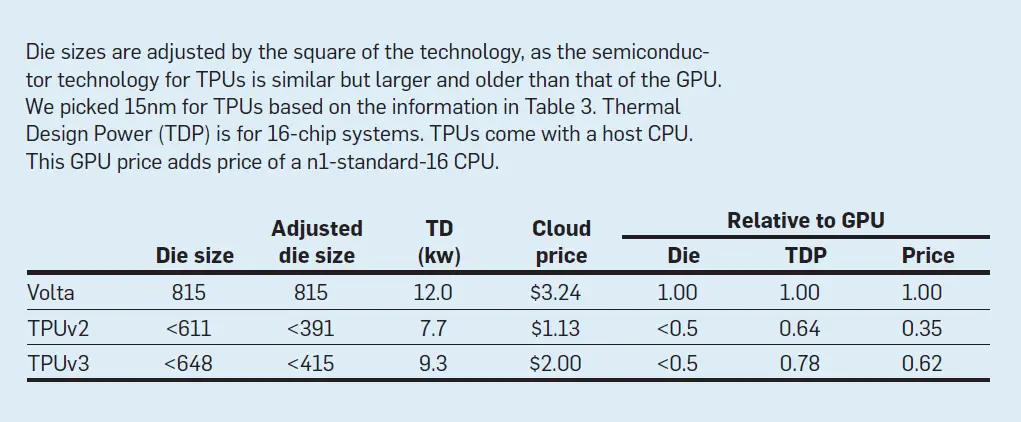
Tabla 6. Comparación ajustada de la GPU y la TPU.
Evaluación del desempeño
En la arquitectura de los ordenadores, «calificamos en una curva» versus «calificamos en una escala absoluta», por lo que necesitamos medir el rendimiento en relación con la competencia. Antes de mostrar el rendimiento de las supercomputadoras TPU, debemos establecer las virtudes de un solo chip, ya que un aumento de velocidad de 1024x a partir de 1.024 chips débiles no es interesante.
Primero comparamos el rendimiento del entrenamiento para un conjunto estándar de puntos de referencia ML y aplicaciones de producción de Google para el chip TPUv2/v3 y el chip GPU Volta; TPUv3 y Volta tienen más o menos la misma velocidad. Luego comprobamos si cuatro MXU por chip en TPUv3 realmente ayudaron, o si otros cuellos de botella en el chip TPUv3 hicieron que las MXU extra fueran superfluas; ¡ayudaron! Concluimos la comparación de chips mirando la inferencia para TPUv2/v3 versus TPUv1; TPUv2/v3 son mucho más rápidos.
Habiendo establecido los méritos de los chips TPU, entonces evaluamos la supercomputadora TPUv2/v3. El primer paso es ver lo bien que escala; vemos el 96%-99% de la velocidad lineal perfecta a 1024 chips. Luego comparamos la fracción del rendimiento máximo y el rendimiento por vatio del TPU y de las supercomputadoras tradicionales; el TPU tiene un rendimiento 5x-10x mejor por vatio.
El rendimiento del chip: TPUv2/v3 contra la GPU Volta. La figura 6 muestra el rendimiento de TPUv3 y la GPU Volta sobre TPUv2 para dos conjuntos de programas. El primer conjunto es de cinco programas que Google y NVIDIA enviaron a MLPerf 0.6 en mayo de 2019, y ambos utilizan la multiplicación de 16 bits con el software de NVIDIA para realizar el escalado de pérdidas. La velocidad media geométrica de estos programas sobre TPUv2 es de 1,8 para TPUv3 y 1,9 para Volta.
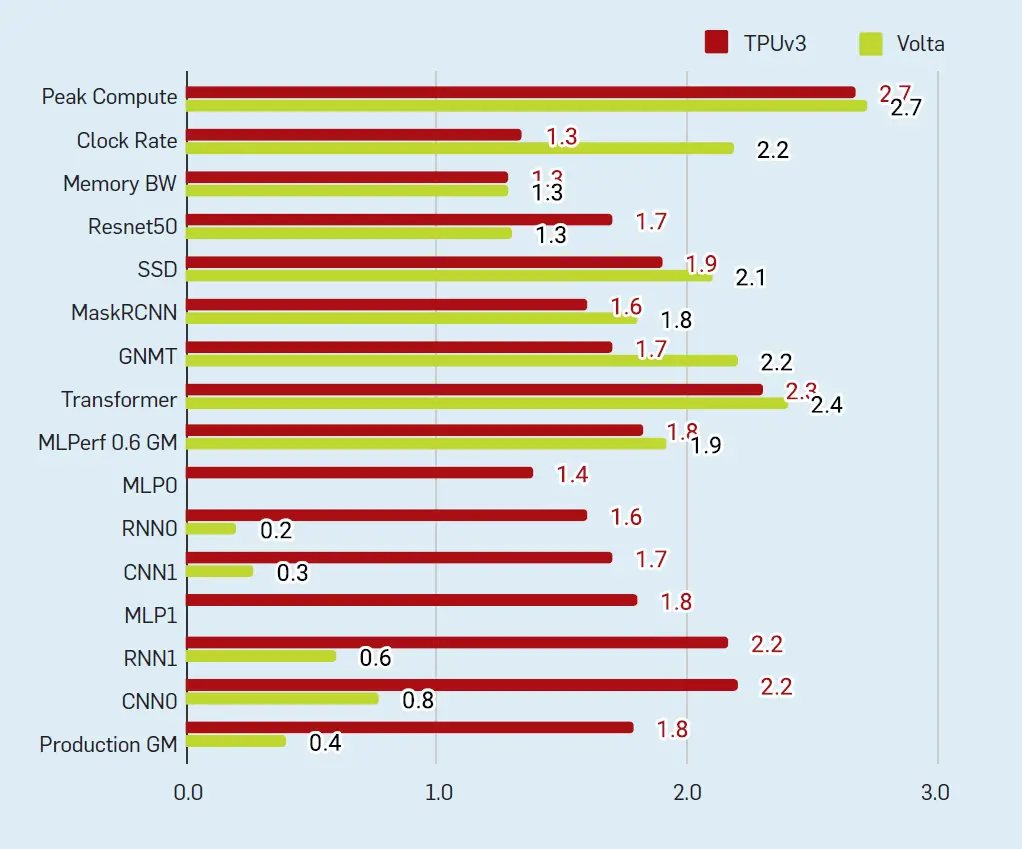
Figura 6. Rendimiento por chip en relación con el TPUv2 para cinco puntos de referencia MLPerf 0,6 y seis aplicaciones de producción.
También queríamos medir el rendimiento de las cargas de trabajo de producción. Elegimos seis aplicaciones de producción similares a las que usamos para TPUv1 como representativas de la carga de trabajo de Google:
- En Percepciones multicapas (MLP) cada nueva capa de un modelo es un conjunto de funciones no lineales de una suma ponderada de todas las salidas (totalmente conectadas) de una anterior. Este clásico DNN suele tener texto como entrada. El MLP0 es inédito pero el MLP1 es RankBrain,9 que clasifica los resultados de búsqueda de una página web.
- En Redes neuronales convolucionales (CNN), cada capa subsiguiente es un conjunto de funciones no lineales de sumas ponderadas de subconjuntos de productos espacialmente cercanos de la capa anterior. Las CNN suelen tener imágenes como entradas. CNN0 es AlphaZero, un algoritmo de aprendizaje de refuerzo con un uso extensivo de CNN, que domina los juegos de ajedrez, Go y shogi.34 La CNN1 es un modelo interno de Google para el reconocimiento de imágenes.
- En Redes neuronales recurrentes (RNN), cada capa de modelo posterior es una colección de funciones no lineales de sumas ponderadas de resultados y el estado anterior. Los problemas de predicción de secuencias, como la traducción del lenguaje, usan RNNs. RNN0 es RNMT+6 y el RNN1 es LAS mejorado.8
Recientemente comparamos las cargas de trabajo representativas del centro de datos por tipo de modelo para inferir en TPUv120 contra TPUv2/v3 para el entrenamiento. El cuadro 7 ilustra la naturaleza rápidamente cambiante de los DNN. Originalmente usamos el nombre LSTM (Memoria de Largo Corto Plazo) para las aplicaciones de TPUv1, un tipo de RNN. Aunque muestreados tres años antes -julio 2016 versus abril 2019- nos sorprendió que las RNN fueran una parte mucho más importante del entrenamiento en el centro de datos, y que un nuevo modelo Transformador36-publicado el año en que se desplegó el TPUv2- fue tan popular como los RNN. (El transformador es parte del MLPerf 0.5.)
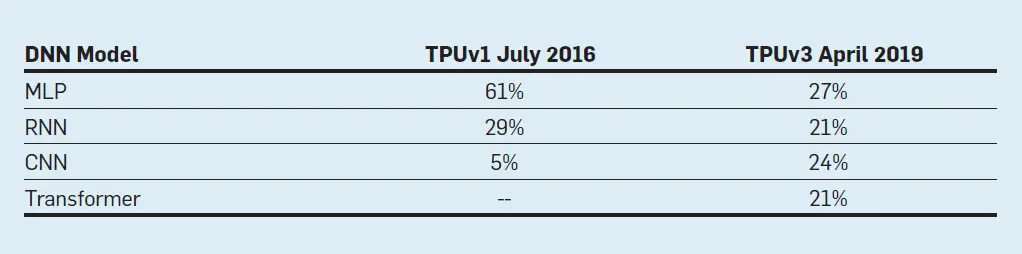
Tabla 7. Cargas de trabajo de inferencia (Julio 2016) y de entrenamiento (Abril 2019) de Google por tipo de modelo DNN.
El transformador está destinado a las mismas tareas que los RNN, como la traducción, pero es considerablemente más rápido ya que se presta a la paralelización mientras que los RNN tienen dependencias secuenciales. Las capas de Transformer son una mezcla de MLPs y capas de atención.4 La atención es el nuevo mecanismo clave utilizado en Transformer; permite a las redes neuronales buscar datos de forma asociativa, en una estructura similar a la memoria cuyos índices se aprenden por sí mismos. Los componentes de la atención se asemejan a los de otras capas, incluidas las multiplicaciones de la matriz y los productos de puntos, que se corresponden bien con el hardware del TPU. Una diferencia es que las matrices de atención crecen con la longitud de la secuencia, añadiendo requisitos de forma dinámica y de memoria que complican algunas optimizaciones realizadas por XLA. El éxito de este modelo reciente (ver Figura 6) pone de relieve la programabilidad del TPU.
La velocidad media geométrica de las seis aplicaciones de producción fue de 1,8 para el TPUv3 pero sólo de 0,4 para el Volta, principalmente porque utilizan 8 veces más lenta fp32 en las GPU en lugar de fp16 (Tabla 3). Se trata de aplicaciones de gran producción que se mejoran continuamente, y no de simples puntos de referencia, por lo que es mucho trabajo conseguir que funcionen del todo, y más para que funcionen bien. Como se mencionó anteriormente, los programadores de aplicaciones se centran en las TPU, ya que son de uso cotidiano, por lo que hay poca necesidad de incluir el escalado de pérdidas necesario para la fp16 (los núcleos TF para incrustaciones no se han desarrollado para las GPU, por lo que excluimos los MLP de la media geométrica de la GPU ya que no se podían ejecutar).
¿Está la memoria TPUv3 ligada a la memoria o a la computación? Mientras que el pico de mejora de cálculo de TPUv3 sobre TPUv2 es 2.7x, las mejoras en el ancho de banda de la memoria, el ancho de banda de la ICI y la velocidad del reloj son sólo ≈1.35x. Nos preguntamos si los MXU extra en TPUv3 serían subutilizados debido a los cuellos de botella en otros lugares. La figura 6 muestra que una aplicación de producción funciona un poco más alta que la mejora de la memoria en 1,4, pero las otras cinco y todos los puntos de referencia del MLPerf 0,6 funcionan mucho más rápido en 1,6x a 2,3x. Los grandes tamaños de los lotes de aplicación y el suficiente almacenamiento en el chip permitieron estos buenos resultados. Como las MXU no son una gran parte del chip (Figura 3), doblar las MXU en el TPUv3 resultó claramente beneficioso.
Inferencia en un chip de entrenamiento: TPUv2/v3 contra TPUv1. ¿Qué hay de la velocidad de inferencia? Ejecutarlo en un chip de entrenamiento -que funciona ya que es como el paso adelante- podría ayudar a las aplicaciones que requieren un entrenamiento frecuente en datos frescos. El TPUv2/v3 no soporta tipos de datos enteros de 8 bits, así que Inference usa el bf16. Una ventaja de usar la misma aritmética para el entrenamiento y la inferencia es que los expertos en ML no necesitan hacer un trabajo extra llamado cuantificación-para asegurar la misma precisión del modelo DNN.
Uno de los peligros es que los grandes lotes necesarios para funcionar eficientemente en TPUv2/v3 podrían perjudicar la latencia de la inferencia. Afortunadamente, tenemos modelos DNN que pueden cumplir sus objetivos de latencia con tamaños de lote superiores a 1.000. Con miles de millones de usuarios diarios, las inferencias por segundo en toda la flota del centro de datos pueden ser muy altas.
El punto de referencia LSTM0, por ejemplo, funcionó a 48 inferencias por segundo con un tiempo de respuesta de 122ms en TPUv1.19 El TPUv2 lo ejecuta 5,6 veces más rápido con un tiempo de respuesta 2,8 veces menor (44ms) en el mismo tamaño de lote. La menor latencia permite a su vez que se sirvan lotes más grandes en comparación con el TPUv1 en la producción, sin dejar de cumplir los objetivos de latencia. Con lotes más grandes, el rendimiento se elevó a 11x con una mejora de latencia de 2x (58ms) frente al TPUv1. El TPUv3 reduce la latencia 1,3x (45ms) frente al TPUv2 con el mismo tamaño de lote.
Rendimiento de escalado de la supercomputadora DSA. Desgraciadamente, sólo ResNet-50 de MLPerf 0.6 puede escalar más allá de 1.000 TPU y GPU. La Figura 7 muestra tres resultados de ResNet-50. Ying y otros publicaron los resultados de ResNet-50 en TPUv3 que entregaron el 77% de la escalada lineal perfecta a 1.024 chips,41 pero la versión TPUv3 para MLPerf 0.6 sólo funciona al 52%. La diferencia está en las reglas básicas del MLPerf. MLPerf requiere incluir evaluación en el tiempo de entrenamiento. (La evaluación ejecuta un conjunto de datos de retención después de que un modelo de entrenamiento termine para determinar su precisión). Como Ying y otros, la mayoría de los investigadores lo excluyen cuando informan sobre el rendimiento. Más inusualmente, el MLPerf requiere la evaluación de la ejecución al final de cada cuatro épocas para disuadir a los tramposos de la referencia. Los desarrolladores de ML nunca evaluarían eso con frecuencia. Para MLPerf 0.6, NVIDIA ejecutó ResNet-50 en un cluster de 96 DGX-2H cada uno con 16 voltios conectados a través de interruptores Infiniband al 41% de la escala lineal para 1.536 chips.
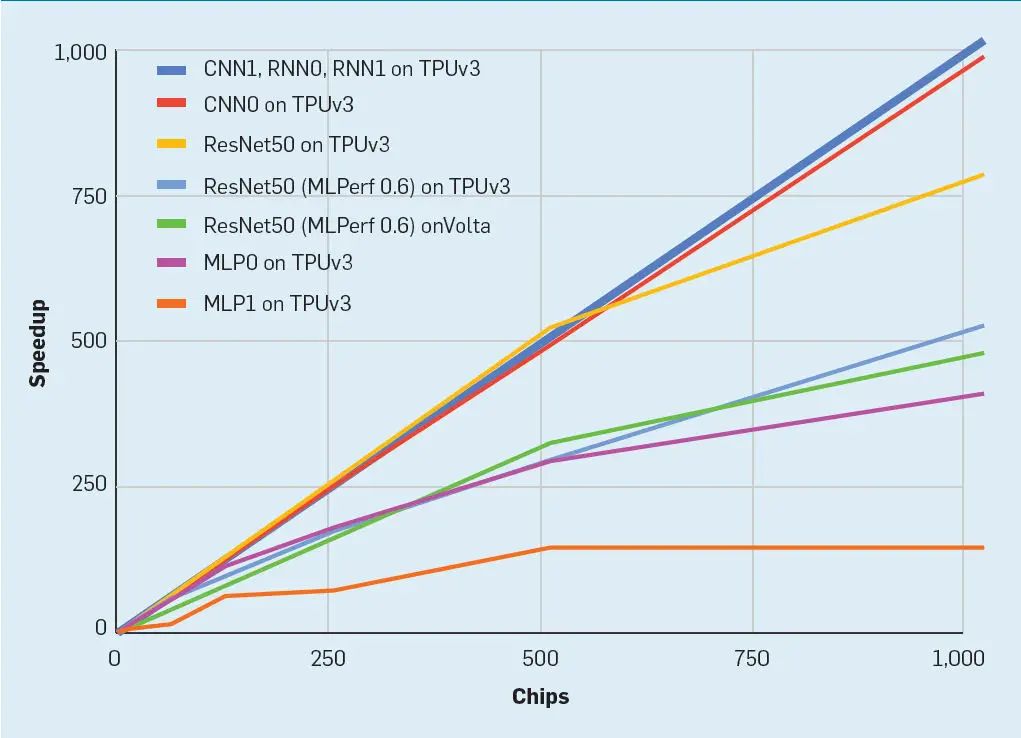
Figura 7. Escalado de superordenadores: TPUv3 y Volta.
Los puntos de referencia del MLPerf 0,6 son mucho más pequeños que las aplicaciones de producción; la Tabla 8 muestra que el tiempo para entrenarlas en un chip de TPUv2 es órdenes de magnitud menores que en la Tabla 1. Por lo tanto, incluimos seis aplicaciones de producción en gran parte para mostrar programas sustanciales que pueden escalar al tamaño de una supercomputadora. Los MLP están limitados por las incrustaciones y funcionan sólo al 14% y 40% de la escala lineal perfecta en 1.024 chips de TPUv3, ¡pero uno funciona al 96% y tres al 99%!

Tabla 8. Días para entrenar los puntos de referencia del MLPerf 0,5 en un chip TPUv2. Véase la tabla 1 para el tiempo de entrenamiento de las aplicaciones de producción.
Tengan en cuenta que CNN1 es un reconocimiento de imagen DNN muy parecido a ResNet101. Escala mucho mejor en los TPU porque los conjuntos de datos de imágenes internas de Google son mucho más grandes que los que utiliza ResNet50 (Imagenet).
Rendimiento de la supercomputadora tradicional vs. DSA. Las supercomputadoras tradicionales miden el rendimiento utilizando el benchmark de computación de alto rendimiento (HPC) Linpack y clasificando el Top500 (top500.org). La lista Green500 relacionada reordena el Top500 en base al rendimiento por vatio. Para que estas grandes computadoras obtengan una utilización superior al 60%, el HPC amplía el tamaño de la matriz que se está resolviendo (Escala débil). (Por lo cual Linpack ha sido criticado durante mucho tiempo dentro del HPC.13) La ampliación del TPU, sin embargo, utiliza programas de producción en conjuntos de datos del mundo real.
La tabla 9 muestra dónde se clasificarían los PetaFLOPs/segundo y los FLOPs/Watt de AlphaZero en TPUv2/v3 en las listas Top500 y Green500. Esta comparación es imperfecta: las supercomputadoras convencionales procesan datos de 32 y 64 bits en lugar de los datos de 16 y 32 bits de las TPU. Sin embargo, los TPU están ejecutando una aplicación real sobre datos reales frente a un punto de referencia débilmente escalado sobre datos sintéticos. El TPUv3 tiene 44 veces el FLOPS/Watt de Tianhe y 10 veces el SaturnV y el ABCI.
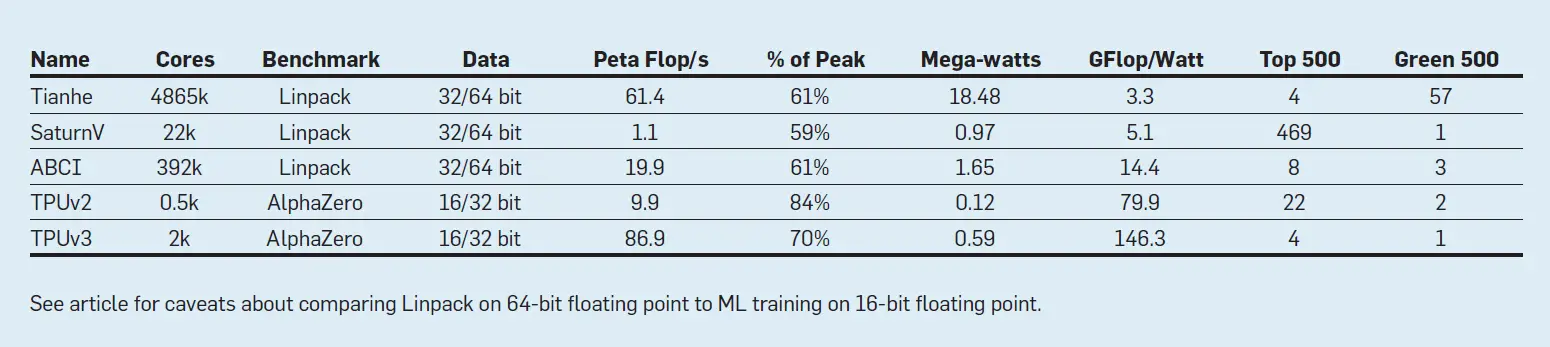
Tabla 9. Rango de la superordenador tradicional versus TPU Top500 y Green500 (Junio 2019) para Linpack y AlphaZero.
La supercomputadora Fujitsu ABCI de la Tabla 9 incluye 2.176 CPUs de Intel junto con 4352 GPUs Volta. Además de ejecutar Linpack, Fujitsu presentó un resultado de ResNet-50 para MLPerf 0.6 usando 2.048 GPU. La Tabla 10 muestra el tiempo de entrenamiento para ResNet-50 en MLPerf 0.6 y el número de chips para un clúster de GPU NVIDIA, el superordenador Fujitsu ABCI y un superordenador TPUv3 de Google. Fujitsu se apartó de las estrictas pautas de referencia MLPerf 0.6 cerradas de los otros envíos, modificando el optimizador LARS y el hiperparámetro de impulso, por lo que no es una comparación de manzanas con manzanas. Estos cambios mejoran el rendimiento en un 10%-15%, lo que también ayudaría a NVIDIA y TPUv3.

Tabla 10. Es hora de entrenar a las supercomputadoras de NVIDIA, Fujitsu y Google en el benchmark ResNet-50 de MLPerf 0.6.
Trabajos relacionados
Una encuesta documenta más de 25 años de chips de red neural personalizados,3 pero los recientes éxitos de la DNN llevaron a una explosión en su desarrollo. La mayoría de los diseños se centran en la inferencia; muchos menos, incluyendo el TPUv2/v3, en el entrenamiento de objetivos. No tenemos conocimiento de otros resultados que muestren la precisión más avanzada en un hardware DSA que funcione para el entrenamiento.
De los cinco inicios del entrenamiento, SambaNova aún no ha sido publicado. Cerebras utiliza una oblea entera de silicio para construir su sistema, esencialmente tratando 84 grandes «dados» como una sola unidad.24 Cada «dado» tiene 220MB de SRAM junto con unos 5k núcleos, lo que da un total de 18GB de memoria en el chip y 400k núcleos que en conjunto utilizan 15 kilovatios. Al igual que GraphCore, no hay DRAM en el sistema, por lo que apuntan a lotes pequeños para reducir las necesidades de memoria. El GraphCore15 El chip GC2 contiene 1.216 Unidades de Procesamiento de Inteligencia que soportan siete hilos, cada uno de los cuales tiene un rendimiento máximo de 100GFLOPS/s o 122TFLOPS/s por chip, casi idéntico al rendimiento máximo de TPUv3 y Volta. Se basa en el SRAM de 300MB en el chip para la memoria, con dos chips GC2 por placa PCIe. La Habana Gaudí38 tiene ocho núcleos VLIW SIMD, cuatro pilas de memoria HBM2, bf16 aritmética, y ocho enlaces Ethernet de 100Gbit/seg. para conectar muchos chips entre sí para formar sistemas más grandes. La computación por ondas28 El chip de la Unidad de Procesamiento de Flujo de Datos tiene 16k procesadores, 8k unidades aritméticas, 16MB de memoria en el chip, y la novedad es que se basa en la lógica asíncrona en lugar de un reloj. Tiene DRAM externa, ofreciendo tanto el Cubo de Memoria Híbrido como los puertos DDR4. A partir de febrero de 2020, ninguna de las cinco empresas de formación ha informado sobre la precisión de la formación o el tiempo de resolución.
Los estudios de formación académica incluyen la familia de arquitecturas DianNao (una de las cuales entrena)7 y ScaleDeep;37 hasta donde sabemos, ninguno de los dos ha sido fabricado.
Varios estudios exploraron el entrenamiento de precisión reducida teniendo en cuenta la construcción del acelerador. El Flexpoint de Intel22 es un formato de bloque FP,39 aunque esos desarrolladores cambiaron a usar bf16 para sus chips DNN.40 De Sa et al.10 …una precisión reducida y una coherencia relajada de la memoria caché. HALP11 también hizo cambios algorítmicos para reducir el ruido de la cuantificación y utiliza números enteros de 8 bits para entrenar algunos modelos. Ninguno de ellos está aún disponible en un sistema comercial.
Los TPUv2/v3 no son las primeras supercomputadoras de dominio específico que muestran grandes ganancias de eficiencia, rendimiento y escalabilidad. Los sistemas de Anton33 mostraron dos aceleraciones de orden de magnitud sobre las supercomputadoras tradicionales en cargas de trabajo de dinámica molecular. También resultaron del diseño de códigos de hardware/software/algoritmos, con chips personalizados, interconexión y aritmética.
Conclusión
Los puntos de referencia sugieren que el chip TPUv3 tiene un rendimiento similar al del chip contemporáneo de la GPU Volta, pero el escalado paralelo para aplicaciones de producción es más fuerte para la supercomputadora TPUv3:
- Tres escalas a 1.024 chips a una velocidad lineal del 99%;
- Se escala a 1.024 chips a una velocidad lineal del 96%; y
- Dos escalas a 1.024 chips pero están limitadas por las incrustaciones.
Notablemente, una supercomputadora TPUv3 ejecuta una aplicación de producción utilizando datos del mundo real a un 70% de su rendimiento máximo, más alto que las supercomputadoras de propósito general que ejecutan el benchmark Linpack utilizando un escalamiento débil de los datos manufacturados. Además, las supercomputadoras TPU con 256-1.024 chips que ejecutan una aplicación de producción tienen 5x-10x rendimiento/Watt de la supercomputadora tradicional número 1 de la lista Green500 que ejecuta Linpack y 24x-44x de la supercomputadora número 4 de la lista Top500. Las razones de este éxito incluyen la red ICI incorporada, grandes arreglos sistólicos y aritmética bf16, que esperamos se convierta en un tipo de datos estándar para los ASD de DNN.
Los TPUv2/v3 tienen matrices más pequeñas en un proceso de semiconductor más antiguo y precios de nube más bajos a pesar de ser menos maduros en muchos niveles de la pila del sistema de hardware/software que las CPU y las GPU. Estos buenos resultados a pesar de las desventajas tecnológicas sugieren que el enfoque del TPU es rentable y puede ofrecer una alta eficiencia arquitectónica en el futuro.
En el futuro, nuestros voraces colegas de DNN quieren la computadora más rápida que podamos construir.2 A pesar de que la Ley de Moore terminó, esperamos que la demanda de supercomputadoras específicas de DNN crezca más rápido de lo que Moore predijo. Tratar de satisfacer esa demanda sin la ayuda de la Ley de Moore ofrece nuevos y excitantes desafíos para los arquitectos de computadoras por al menos una década.17
Agradecimientos
Los autores analizaron los sistemas de TPU que implicaban contribuciones de muchos Googlers. Muchas gracias a los equipos de hardware y software y a los ingenieros por hacer posible las supercomputadoras TPU, incluyendo a Paul Barham, Eli Bendersky, Dehao Chen, Chiachen Chou, Jeff Dean, Peter Hawkins, Blake Hechtman, Mark Heffernan, Robert Hundt, Michael Isard, Fritz Kruger, Naveen Kumar, Sameer Kumar, Chris Leary, Hyouk-Joong Lee, David Majnemer, Lifeng Nai, Thomas Norrie, Tayo Oguntebi, Andy Phelps, Bjarke Roune, Brennan Saeta, Julian Schrittwieser, Andy Swing, Shibo Wang, Tao Wang, Yujing Zhang, y muchos más.
Referencias
1. Abadi, M. y otros. Tensorflow: Aprendizaje automático a gran escala en sistemas distribuidos heterogéneos. 2016; preimpresión de arXiv arXiv:1603.04467.
2. Amodei, D. y Hernandez, D. AI y computación, 2018; https://blog.openai.com/aiandcompute.
3. Asanović, K. Neurocomputación programable. El Manual de Teoría del Cerebro y Redes Neurales, 2y EdiciónM.A. Arbib, ed. MIT Press, 2002.
4. Bahdanau, D., Cho, K. y Bengio, Y. Traducción automática neuronal aprendiendo conjuntamente a alinear y traducir. 2014; preimpresión de arXiv arXiv:1409.0473.
5. Chen, J. y otros. Revisando el SGD síncrono distribuido. 2016; preimpresión arXiv arXiv:1604.00981.
6. Chen, M.X. y otros. Lo mejor de ambos mundos: Combinando los recientes avances en la traducción automática neural. 2018; preimpresión de arXiv arXiv:1804.09849.
7. Chen, Y. et al. Dadiannao: Una supercomputadora de aprendizaje automático. En Las actas del 47th Simposio Internacional sobre Microarquitectura, (2014), 609–622.
8. Chiu, C.C. y otros. Reconocimiento de voz de última generación con modelos de secuencia a secuencia. En Actas de la Conferencia Internacional del IEEE sobre Acústica, Procesamiento de Habla y Señal(Abril 2018), 4774-4778.
9. Clark, J. Google está convirtiendo su lucrativa búsqueda en la web en máquinas de inteligencia artificial. Bloomberg Technology, 26 de octubre de 2015.
10. De Sa, C. y otros. Comprensión y optimización del descenso de gradientes estocásticos asíncronos de baja precisión. En Las actas del 44th Int’l Symp, en Arquitectura de Computadoras, (2017), 561–574.
11. De Sa, C. y otros. Entrenamiento de alta precisión y baja precisión. 2018; preimpresión arXiv arXiv:1803.03383.
12. Dean, J. y otros. Redes profundas distribuidas a gran escala. Advances in Neural Information Processing Systems, (2012), 1223-1231.
13. Dongarra, J. La referencia del desafío HPC: ¿un candidato para reemplazar a Linpack en el Top500? En Actas del taller de referencia del SPEC(enero de 2007); www.spec.org/workshops/2007/austin/slides/Keynote_Jack_Dongarra.pdf.
14. Duchi, J., Hazan, E. y Singer, Y., Métodos de subgraduado adaptativos para el aprendizaje en línea y la optimización estocástica. J. Investigación sobre el aprendizaje automático 12 (julio de 2011), 2121-2159.
15. Unidad de Procesamiento de Inteligencia Graphcore. (https://www.graphcore.ai/products/ipu
16. Hennessy, J.L. y Patterson, D.A. Arquitectura de computadoras: Un enfoque cuantitativo, 6th Edición. Elsevier, 2019.
17. Hennessy, J.L. y Patterson, D.A. Una nueva edad de oro para la arquitectura informática. Comun. ACM 622 (Febrero 2019), 48-60.
18. Ioffe, S. y Szegedy, C. Normalización de lotes: Aceleración de la formación de la red profunda mediante la reducción del cambio de covariable interno. 2015; preimpresión arXiv arXiv:1502.03167.
19. Jouppi, N.P. y otros. Análisis del rendimiento en el centro de datos de una unidad de procesamiento de tensores. En Las actas del 44th Int’l Symp. en Arquitectura de Computadoras(Junio 2017), 1-12.
20. Jouppi, N.P., Young, C., Patil, N. y Patterson, D. Una arquitectura específica de dominio para redes neuronales profundas. Comun. ACM 619 (septiembre de 2018), 50-59.
21. Kalamkar, D. y otros. Un estudio de Bfloat16 para la formación de aprendizaje profundo. 2019; preimpresión arXiv arXiv:1905.12322.
22. Köster, U. y otros. Flexpoint: Un formato numérico adaptable para el entrenamiento eficiente de las redes neuronales profundas. En Actas del 31st Conf. sobre Sistemas de Procesamiento de Información Neural, (2017).
23. Kung, H.T. y Leiserson, C.E. Algoritmos para conjuntos de procesadores VLSI. Introducción a los sistemas VLSI, 1980.
24. Mentira, escala de S. Wafer aprendizaje profundo. En Actas de la Simulación de Hot Chips 31 del IEEE.(Agosto 2019).
25. Mellempudi, N. y otros. Entrenamiento de precisión mixto con punto flotante de 8 bits. 2019; preimpresión arXiv arXiv:1905.12334.
26. Micikevicius, P. y otros. Entrenamiento de precisión mixto. 2017; preimpresión arXiv arXiv:1710.03740.
27. Mikolov, T. y otros. Representaciones distribuidas de palabras y frases y su composición. Avances en los sistemas de procesamiento de información neuronal (2013), 3111–3119.
28. Nicol, C. Un chip de procesamiento de flujo de datos para el entrenamiento de redes neuronales profundas. En Actas de la IEEE Hot Chips 29 Symp.(Agosto 2017).
29. Olah, C. Aprendizaje profundo, PNL y representaciones. El blog de Colah, 2014; http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/.
30. Polyak, B.T. Algunos métodos para acelerar la convergencia de los métodos de iteración. Matemáticas computacionales y física matemática de la URSS 4, 5 (1964), 1–17.
31. Robbins, H. y Monro, S. Un método de aproximación estocástica. Los anales de las estadísticas matemáticas 223 (septiembre de 1951), 400-407.
32. Shallue, C.J. y otros. Medición de los efectos del paralelismo de datos en el entrenamiento de redes neuronales. 2018; preimpresión de arXiv arXiv:1811.03600.
33. Shaw, D.E. y otros, Anton, una máquina especial para la simulación de la dinámica molecular. Comun. ACM 517 (julio de 2008), 91-97.
34. Silver, D. y otros. Un algoritmo de aprendizaje de refuerzo general que el ajedrez de los maestros, el shogi y el juego personal. Ciencia 362, 6419 (2018), 1140–1144.
35. Thottethodi, M. y Vijaykumar, T. Por qué la GPGPU es menos eficiente que la TPU para los DNN. Blog de Arquitectura de Computadoras Hoy, 2019; www.sigarch.org/why-the-gpgpu-is-less-efficientthan-the-tpu-for-dnns/
36. Vaswani, A. y otros. La atención es todo lo que necesitas. Avances en los sistemas de procesamiento de información neuronal (2017), 5998–6008.
37. Venkataramani, S. et al. Scaledeep: Una arquitectura de computación escalable para el aprendizaje y la evaluación de redes profundas. En Las actas del 45th Int’l Symp. en Arquitectura de Computadoras, (2017), 13–26.
38. Ward-Foxton, S. Habana debuta con un chip de entrenamiento de IA que bate récords, (junio de 2019); https://www.eetimes.com/document.asp?doc_id=1334816.
39. Wilkinson, J.H. Errores de redondeo en los procesos algebraicos, 1ª edición. Prentice Hall, Englewood Cliffs, NJ, 1963.
40. Yang, A. Entrenamiento de aprendizaje profundo a escala Spring Crest Deep Learning Accelerator (Intel® Nervana™ NNP-T). En Las actas de las Hot Chips(agosto de 2019); www.hotchips.org/hc31/HC31_1.12_Intel_Intel.AndrewYang.v0.92.pdf.
41. Ying, C. y otros. Clasificación de imágenes a escala de supercomputadora. 2018; preimpresión arXiv arXiv:1811.06992.
42. Zoph, B. y Le, Q.V. Búsqueda de arquitectura neuronal con aprendizaje de refuerzo. 2019; preimpresión de arXiv arXiv:1611.01578.