

Crédito: Getty Images
El aprendizaje profundo no debería funcionar tan bien como parece: según las estadísticas tradicionales y el aprendizaje automático, cualquier análisis que tenga demasiados parámetros ajustables se ajustará demasiado a los datos de entrenamiento ruidosos y luego fallará cuando se enfrente a nuevos datos de prueba. En clara violación de este principio, las redes neuronales modernas a menudo usan muchos más parámetros que puntos de datos, pero, no obstante, generalizan bastante bien a nuevos datos.
La base teórica inestable para la generalización se ha observado durante muchos años. Una propuesta fue que las redes neuronales realizan implícitamente algún tipo de regularización, una herramienta estadística que penaliza el uso de parámetros adicionales. Sin embargo, los esfuerzos para caracterizar formalmente tal «sesgo implícito» hacia soluciones más suaves han fracasado, dijo Roi Livni, profesora avanzada en el departamento de ingeniería eléctrica de la Universidad de Tel Aviv de Israel. “Puede ser que sea como una aguja en un pajar, y si miramos más allá, al final lo encontraremos. Pero también puede ser que la aguja no esté allí”.
Volver arriba
Una profusión de parámetros
Investigaciones recientes han aclarado que los sistemas de aprendizaje operan en un régimen completamente diferente cuando están altamente parametrizados, de modo que más parámetros les permiten generalizar. mejor. Además, esta propiedad es compartida no solo por las redes neuronales sino también por métodos más comprensibles, lo que hace posible un análisis más sistemático.
«La gente era más o menos consciente de que había dos regímenes», dijo Mikhail Belkin, profesor del Instituto de Ciencias de Datos Haliciolu de la Universidad de California en San Diego. Sin embargo, «creo que definitivamente no se entendió la separación limpia» antes del trabajo que él y sus colegas publicaron en 2019. «Lo que haces en la práctica», como la regularización forzada o la interrupción temprana del entrenamiento, «los confunde».
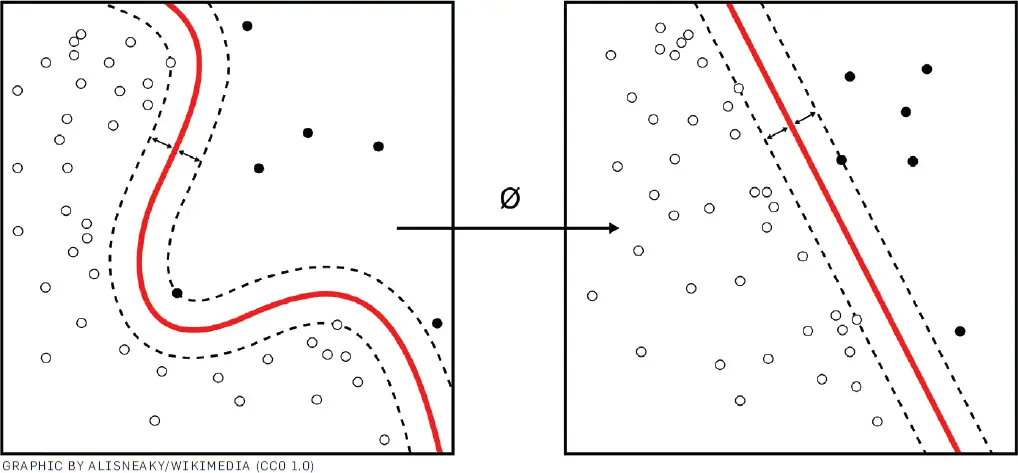
Figura. Las máquinas kernel como la anterior se utilizan para calcular funciones separables no lineales en una función separable linealmente de mayor dimensión.
Belkin y sus coautores aumentaron sistemáticamente la complejidad de varios modelos y confirmaron la degradación clásica de la generalización. Su análisis reveló un pico pronunciado en el error de predicción a medida que la cantidad de parámetros del modelo se hizo lo suficientemente alta como para ajustarse exactamente a cada punto de entrenamiento. Más allá de este umbral, sin embargo, la generalización mejoró nuevamente, por lo que la curva general mostró lo que llamaron «doble descenso».
Un modelo altamente sobreparametrizado, más allá del pico, tiene una variedad enorme y compleja de soluciones en el espacio de parámetros que pueden ajustarse igualmente bien a los datos de entrenamiento, de hecho perfectamente, explicó Andrea Montanari, profesora Robert y Barbara Kleist en la Escuela de Ingeniería y profesora en los departamentos de ingeniería eléctrica, estadística y matemáticas de la Universidad de Stanford. El entrenamiento, que generalmente comienza con un conjunto aleatorio de parámetros y luego los ajusta repetidamente para que coincidan mejor con los datos de entrenamiento, se establecerá en soluciones dentro de esta variedad cerca del punto de inicialización. «De alguna manera estos tienen la propiedad, una simplicidad especial, que los hace generalizar bien», dijo. «Esto depende de la inicialización».
Sin embargo, las métricas cuantitativas de generalización son un desafío, advierte Gintare Karolina Dziugaite de Google Brain en Toronto, y existen límites sobre lo que debemos esperar de las «explicaciones» para ello. Una medida obvia es el rendimiento de un modelo entrenado cuando se enfrenta a datos retenidos. «Será bastante preciso, pero desde la perspectiva de la explicación, es esencialmente silencioso», dijo. Las teorías generales, por el contrario, no dependen de los detalles de los datos, pero «a estas alturas se reconoce que tales teorías no pueden explicar el aprendizaje profundo en la práctica». dijo Dziugaite. «Cualquier teoría satisfactoria de la generalización debe estar entre esos dos regímenes».
Dziugaite también señaló que memorizar el conjunto de entrenamiento, como lo hace el sobreajuste, en realidad podría ser útil en algunas situaciones, como cuando un conjunto de datos incluye pequeñas subpoblaciones. Una herramienta que parece generalizar bien en promedio podría pasar por alto ejemplos subrepresentados, como personas de piel oscura en los datos de reconocimiento facial.
Boaz Barak, profesor de informática en la Universidad de Harvard, considera que la generalización es solo un aspecto del poder de las redes neuronales. «Si desea hablar sobre la generalización de una manera matemáticamente bien definida, debe pensar en la situación en la que tiene alguna distribución sobre la población y obtiene muestras de esa distribución», dijo. «Así no es como funcionan las cosas» para conjuntos de datos del mundo real.
Una buena generalización, en promedio, tampoco aborda el problema de la «fragilidad», en el que las redes neuronales a veces cometen errores inexplicables y atroces en respuesta a entradas novedosas. Sin embargo, «todavía estamos lejos de tener una forma de solucionar ese problema con principios», dijo Montanari.
Volver arriba
Máquinas de núcleo
El «descubrimiento más importante de Belkin fue que [the overparameterized regime] es realmente general», dijo Montanari. «No se limita a las redes neuronales». Como resultado, «la gente comenzó a observar este fenómeno en modelos más simples».
Belkin, por ejemplo, ha defendido las venerables máquinas kernel tanto por su poder explicativo como práctico. Cuando se utilizan como clasificadores binarios, las máquinas kernel buscan en un espacio de características de muy alta dimensión superficies simples que separan dos grupos de puntos de datos que se entremezclan cuando se proyectan en menos dimensiones. Para realizar esta separación, explotan un «truco del núcleo» matemático que calcula las distancias entre pares de puntos en el espacio de alta dimensión sin necesidad de calcular sus coordenadas reales.
Las máquinas kernel incluyen máquinas de vectores de soporte, que se exploraron ampliamente para el aprendizaje automático antes del reciente ascenso del aprendizaje profundo. «En cierto sentido, es un modelo más simple», dijo Belkin. «Si ni siquiera puedes entender lo que está pasando con ellos, entonces no puedes entender las redes neuronales».
Además, Belkin ha llegado a creer que las máquinas kernel ya pueden contener las características más importantes del aprendizaje profundo. «No quiero decir que los núcleos puedan explicar todo lo relacionado con las redes neuronales», dijo, «pero creo que tal vez las cosas interesantes sobre las redes neuronales ahora se puedan representar mediante núcleos».
En algunos casos limitantes, la conexión se puede hacer matemáticamente precisa. Un límite importante es cuando una red neuronal tiene capas de «ancho» infinito (en contraste con la «profundidad», la cantidad de capas, que le da su nombre al aprendizaje profundo). Hace tiempo que se sabe que redes tan amplias, cuando se inicializan aleatoriamente, pueden describirse como un proceso gaussiano, que es un tipo de kernel.
La conexión persiste durante el entrenamiento, como se muestra en una presentación de NeurIPS de 2018 muy citada por Arthur Jacot, un estudiante graduado en la École Polytechnique Fédérale de Lausanne de Suiza, y sus colegas. «Aproximamos el modelo no lineal de las redes neuronales a un modelo lineal local», dijo. Este Neural Tangent Kernel, o NTK, determina con precisión cómo evoluciona la solución durante el entrenamiento.
Para redes infinitamente anchas, los autores demostraron que el NTK no depende de los datos de entrenamiento y no cambia durante el entrenamiento. Jacot dijo que todavía están examinando otras condiciones para que una red neuronal esté en este «régimen NTK», incluida una gran variación en los parámetros iniciales.
«Me comprometí más con el tema del kernel después de este artículo de NTK», dijo Belkin, «porque esencialmente mostraron que las redes neuronales amplias son solo kernels», lo que hace que la generalización sea más fácil de modelar.
Volver arriba
Aprendizaje de características
Sin embargo, los kernels no hacen todo automáticamente. «La principal diferencia entre las máquinas kernel y las redes neuronales es que las redes neuronales aprenden las características de los datos», dijo Barak. «Aprender de los datos es una característica importante del éxito del aprendizaje profundo, por lo que, en ese sentido, si necesita explicarlo, debe ir más allá de los núcleos». Optimizar el reconocimiento de características podría incluso empujar a los diseñadores de redes neuronales a evitar el régimen NTK, sugirió, «porque de lo contrario pueden degenerar en núcleos».
«Es muy fácil encontrar ejemplos en los que las redes neuronales funcionen bien y ningún método kernel funcione bien», dijo Montanari. Sospecha que el éxito práctico de las redes neuronales «probablemente se debe a una mezcla» de la parte lineal, que está incorporada en los núcleos, con el aprendizaje de funciones, que no lo está.
Por su parte, Belkin tiene la esperanza, aunque no la certeza, de que los núcleos puedan hacerlo todo, incluida la identificación de funciones. «Hay resultados matemáticos que muestran que las redes neuronales pueden calcular ciertas cosas que los núcleos no pueden, dijo, pero «eso en realidad no me muestra que las redes neuronales reales en la práctica calculan esas cosas».
«No siempre es cierto que las redes neuronales estén cerca de los métodos del núcleo», reconoció Jacot. Aún así, enfatizó que el NTK aún se puede definir y describir la evolución de la red incluso fuera del régimen NTK, lo que facilita el análisis de lo que están haciendo las redes. «Con NTK realmente puedes comparar diferentes arquitecturas» para ver si son sensibles a características particulares», dijo. «Esa ya es información muy importante».
Las redes neuronales convolucionales han demostrado ser poderosas en el reconocimiento de imágenes, por ejemplo, en parte porque sus conexiones internas las hacen insensibles al desplazamiento de un objeto. «Aunque estas no son funciones aprendidas, siguen siendo bastante complejas y resultan de la arquitectura de la red», dijo Jacot. «El simple hecho de tener este tipo de funciones conduce a una gran mejora en el rendimiento» cuando se integran en los métodos del kernel».
Sin embargo, para otras tareas, las características que identifican las redes neuronales pueden ser difíciles de reconocer para los diseñadores. Para tales tareas, sugirió Barak, un enfoque «sería una especie de fusión de redes neuronales y núcleos, en el sentido de que existe el núcleo correcto para los datos, y las redes neuronales resultan ser un buen algoritmo para aprender con éxito ese núcleo. » Además, «Tenemos alguna evidencia de características universales que dependen de los datos, no de ningún algoritmo en particular que esté usando para aprenderlo. Si tuviéramos una mejor comprensión de eso, entonces tal vez la generalización saldría de ese lado». .»
 Otras lecturas
Otras lecturas
Belkin, M., Hsu, D., Ma, S. y Mandal, S.
Reconciliando la práctica moderna de aprendizaje automático y la compensación clásica de sesgo-varianza, proc. Nat. Academia ciencia 11615849 (2019), https://bit.ly/3EgkBYb
Belkin, m.
Encajar sin miedo: notables fenómenos matemáticos del aprendizaje profundo a través del prisma de la interpolación, Acta Numérica, 30203 (2021), https://bit.ly/3GUJvhq.
Jacot, A., Gabriel, F. y Hongler, C.
Núcleo tangente neuronal: convergencia y generalización en redes neuronales, 32Dakota del Norte Conferencia sobre Sistemas de Procesamiento de Información Neural (NeurIPS 2018), https://bit.ly/32bQmo0
Volver arriba
Autor
don monroe es un escritor de ciencia y tecnología con sede en Boston, MA, EE. UU.
©2022 ACM 0001-0782/22/6
Se otorga permiso para hacer copias digitales o impresas de parte o la totalidad de este trabajo para uso personal o en el aula sin cargo, siempre que las copias no se hagan o distribuyan con fines de lucro o ventaja comercial y que las copias lleven este aviso y la cita completa en la primera página. Deben respetarse los derechos de autor de los componentes de este trabajo que no pertenezcan a ACM. Se permite hacer resúmenes con crédito. Para copiar de otro modo, volver a publicar, publicar en servidores o redistribuir a listas, se requiere un permiso y/o tarifa específicos previos. Solicite permiso para publicar a permisos@acm.org o envíe un fax al (212) 869-0481.
La Biblioteca digital es una publicación de la Association for Computing Machinery. Derechos de autor © 2022 ACM, Inc.
entradas no encontradas