

Última actualización el 29 de octubre de 2022
A medida que aprendimos qué es un Transformador y cómo podemos entrenar el modelo de Transformador, notamos que es una gran herramienta para hacer que una computadora entienda el lenguaje humano. Sin embargo, el Transformer se diseñó originalmente como un modelo para traducir un idioma a otro. Si lo reutilizamos para una tarea diferente, probablemente necesitemos volver a entrenar todo el modelo desde cero. Dado que el tiempo que lleva entrenar un modelo de Transformer es enorme, nos gustaría tener una solución que nos permita reutilizar fácilmente el Transformer entrenado para muchas tareas diferentes. BERT es uno de esos modelos. Es una extensión de la parte del codificador de un Transformador.
En este tutorial, aprenderá qué es BERT y descubrirá lo que puede hacer.
Después de completar este tutorial, sabrás:
- ¿Qué es un codificador bidireccional? Representaciones del transformador (BERT)
- Cómo se puede reutilizar un modelo BERT para diferentes propósitos
- Cómo puede usar un modelo BERT preentrenado
Empecemos.
Una breve introducción a BERT
Foto de Samet Erköseoğlu, algunos derechos reservados.
Descripción general del tutorial
Este tutorial se divide en cuatro partes; están:
- Del modelo de transformador al BERT
- ¿Qué puede hacer BERT?
- Uso del modelo BERT preentrenado para resúmenes
- Uso del modelo BERT preentrenado para preguntas y respuestas
requisitos previos
Para este tutorial, asumimos que ya está familiarizado con:
Del modelo de transformador al BERT
En el modelo de transformador, el codificador y el decodificador están conectados para hacer un modelo seq2seq para que pueda realizar una traducción, como del inglés al alemán, como vio antes. Recuerda que la ecuación de la atención dice:
$$text{atención}(Q,K,V) = text{softmax}Big(frac{QK^top}{sqrt{d_k}}Big)V$$
Pero cada uno de los $Q$, $K$ y $V$ anteriores es un vector incorporado transformado por una matriz de peso en el modelo de transformador. Entrenar un modelo de transformador significa encontrar estas matrices de peso. Una vez que se aprenden las matrices de peso, el transformador se convierte en un modelo de lenguaje, lo que significa que representa una forma de entender el lenguaje que usaste para entrenarlo.
La estructura codificador-decodificador de la arquitectura Transformer
Tomado de “La atención es todo lo que necesitas“
Un transformador tiene partes de codificador y decodificador. Como su nombre lo indica, el codificador transforma oraciones y párrafos en un formato interno (una matriz numérica) que comprende el contexto, mientras que el decodificador hace lo contrario. La combinación del codificador y el decodificador permite que un transformador realice tareas seq2seq, como la traducción. Si saca la parte del codificador del transformador, puede decirle algo sobre el contexto, lo que puede hacer algo interesante.
La Representación de codificador bidireccional de Transformer (BERT) aprovecha el modelo de atención para obtener una comprensión más profunda del contexto del idioma. BERT es una pila de muchos bloques codificadores. El texto de entrada se separa en tokens como en el modelo de transformador, y cada token se transformará en un vector a la salida de BERT.
¿Qué puede hacer BERT?
Un modelo BERT se entrena usando el modelo de lenguaje enmascarado (MLM) y predicción de la siguiente frase (NSP) simultáneamente.
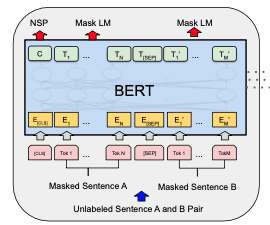
modelo BERT
Cada muestra de entrenamiento para BERT es un par de oraciones de un documento. Las dos oraciones pueden ser consecutivas en el documento o no. Habrá una [CLS] token antepuesto a la primera oración (para representar el clase) y un [SEP] ficha añadida a cada oración (como un separador). Luego, las dos oraciones se concatenarán como una secuencia de tokens para convertirse en una muestra de entrenamiento. Un pequeño porcentaje de los tokens en la muestra de entrenamiento es enmascarado con una ficha especial [MASK] o reemplazado con una ficha aleatoria.
Antes de que se introduzca en el modelo BERT, los tokens en la muestra de entrenamiento se transformarán en vectores incrustados, con las codificaciones posicionales agregadas, y en particular para BERT, con incrustaciones de segmento agregado también para marcar si el token es de la primera o la segunda oración.
Cada token de entrada al modelo BERT producirá un vector de salida. En un modelo BERT bien entrenado, esperamos:
- la salida correspondiente al token enmascarado puede revelar cuál era el token original
- salida correspondiente a la
[CLS]token al principio puede revelar si las dos oraciones son consecutivas en el documento
Entonces, los pesos entrenados en el modelo BERT pueden entender bien el contexto del idioma.
Una vez que tenga un modelo BERT de este tipo, puede usarlo para muchos tareas posteriores. Por ejemplo, al agregar una capa de clasificación adecuada encima de un codificador e ingresar solo una oración al modelo en lugar de un par, puede tomar el token de clase [CLS] como entrada para la clasificación de sentimientos. Funciona porque la salida del token de clase está entrenada para agregar la atención de toda la entrada.
Otro ejemplo es tomar una pregunta como la primera oración y el texto (por ejemplo, un párrafo) como la segunda oración, luego el token de salida de la segunda oración puede marcar la posición donde descansa la respuesta a la pregunta. Funciona porque la salida de cada token revela información sobre ese token en el contexto de toda la entrada.
Uso del modelo BERT preentrenado para resúmenes
Un modelo de transformador toma mucho tiempo para entrenar desde cero. El modelo BERT tardaría aún más. Pero el propósito de BERT es crear un modelo que pueda reutilizarse para muchas tareas diferentes.
Hay modelos BERT pre-entrenados que puede usar fácilmente. A continuación, verá algunos casos de uso. El texto utilizado en el siguiente ejemplo es de:
Teóricamente, un modelo BERT es un codificador que asigna cada token de entrada a un vector de salida, que se puede extender a una secuencia de tokens de longitud infinita. En la práctica, existen limitaciones impuestas en la implementación de otros componentes que limitan el tamaño de entrada. En su mayoría, unos pocos cientos de tokens deberían funcionar, ya que no todas las implementaciones pueden tomar miles de tokens de una sola vez. Puede guardar el artículo completo en article.txt (una copia está disponible aquí). En caso de que su modelo necesite un texto más pequeño, puede usar solo algunos párrafos.
Primero, exploremos la tarea para resumir. Usando BERT, la idea es extracto algunas oraciones del texto original que representan el texto completo. Puede ver que esta tarea es similar a la predicción de la siguiente oración, en la que si se le da una oración y el texto, desea clasificar si están relacionados.
Para hacer eso, necesitas usar el módulo de Python bert-extractive-summarizer
|
pip install bert-extractive-summarizer |
Es un envoltorio para algunos modelos Hugging Face para proporcionar la canalización de tareas de resumen. Hugging Face es una plataforma que te permite publicar modelos de aprendizaje automático, principalmente en tareas de PNL.
Una vez que haya instalado bert-extractive-summarizerproducir un resumen es solo unas pocas líneas de código:
|
de resumen importar resumidor texto = abierto(«artículo.txt»).leer() modelo = resumidor(‘destilbert-base-sin carcasa’) resultado = modelo(texto, num_frases=3) impresión(resultado) |
Esto da la salida:
|
En medio de la agitación política de la salida de la Primera Ministra británica Liz Truss gobierno de corta duración, el Banco de Inglaterra se ha encontrado en el fuego cruzado fiscal-financiero. Cualquier gobierno que venga después, es vital que el BOE aprenda las lecciones adecuadas. Según un comunicado del Vicegobernador del BOE para Estabilidad Financiera, Jon Cunliffe, el MPC fue simplemente «informado de la emisiones en el mercado de gilt e informadas con antelación a la operación, incluida su justificación de estabilidad financiera y el carácter temporal y específico naturaleza de las compras.” |
¡Ese es el código completo! Detrás de escena, se usó spaCy en algunos preprocesamientos y Hugging Face se usó para lanzar el modelo. El modelo utilizado se denominó distilbert-base-uncased. DistilBERT es un modelo BERT simplificado que puede ejecutarse más rápido y usar menos memoria. El modelo es «sin mayúsculas», lo que significa que las mayúsculas o minúsculas en el texto de entrada se consideran iguales una vez que se transforman en vectores de incrustación.
La salida del modelo de resumen es una cadena. como especificaste num_sentences=3 al invocar el modelo, el resumen son tres oraciones seleccionadas del texto. Este enfoque se llama el resumen extractivo. La alternativa es un resumen abstracto, en el que el resumen se genera en lugar de extraerse del texto. Esto necesitaría un modelo diferente al BERT.
Uso del modelo BERT preentrenado para preguntas y respuestas
El otro ejemplo del uso de BERT es hacer coincidir las preguntas con las respuestas. Le darás tanto la pregunta como el texto al modelo y buscarás la salida del principio. y el final de la respuesta del texto.
Un ejemplo rápido sería solo unas pocas líneas de código de la siguiente manera, reutilizando el mismo texto de ejemplo que en el ejemplo anterior:
|
de transformadores importar tubería texto = abierto(«artículo.txt»).leer() pregunta = «¿Qué está haciendo BOE?» respondiendo = tubería(«pregunta-respuesta», modelo=‘distilbert-base-sin carcasa-destilado-escuadrón’) resultado = respondiendo(pregunta=pregunta, contexto=texto) impresión(resultado) |
Aquí, Hugging Face se usa directamente. Si ha instalado el módulo utilizado en el ejemplo anterior, el módulo Hugging Face Python es una dependencia que ya instaló. De lo contrario, es posible que deba instalarlo con pip:
Y para usar realmente un modelo Hugging Face, deberías tener ambas cosas PyTorch y TensorFlow también instalados:
|
pip instalar antorcha tensorflow |
El resultado del código anterior es un diccionario de Python, de la siguiente manera:
|
{‘puntaje’: 0.42369240522384644, ‘inicio’: 1261, ‘fin’: 1344, ‘respuesta’: ‘para mantener o restablecer la liquidez del mercado en mercados financieros de importancia sistémica’} |
Aquí es donde puede encontrar la respuesta (que es una oración del texto de entrada), así como la posición inicial y final en el orden de token de donde proviene esta respuesta. La puntuación puede considerarse como la puntuación de confianza del modelo de que la respuesta podría ajustarse a la pregunta.
Detrás de escena, lo que hizo el modelo fue generar un puntaje de probabilidad para el mejor comienzo en el texto que responde la pregunta, así como el texto para el mejor final. Luego, la respuesta se extrae encontrando la ubicación de las probabilidades más altas.
Otras lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar más.
Documentos
Resumen
En este tutorial, descubrió qué es BERT y cómo usar un modelo BERT previamente entrenado.
Específicamente, aprendiste:
- Cómo se crea BERT como una extensión de los modelos Transformer
- Cómo usar modelos BERT pre-entrenados para resúmenes extractivos y respuesta a preguntas