
Los conjuntos de datos pueden tener valores perdidos, y esto puede causar problemas para muchos algoritmos de aprendizaje de máquinas.
Como tal, es una buena práctica identificar y reemplazar los valores faltantes para cada columna en sus datos de entrada antes de modelar su tarea de predicción. Esto se llama imputación de datos perdidos, o imputación para abreviar.
Un enfoque popular para la imputación de datos faltantes es utilizar un modelo para predecir los valores faltantes. Esto requiere que se cree un modelo para cada variable de entrada que tenga valores perdidos. Aunque cualquiera de los diferentes modelos puede utilizarse para predecir los valores perdidos, el algoritmo del vecino más cercano (KNN) ha demostrado ser generalmente eficaz, a menudo denominado «imputación del vecino más cercano.”
En este tutorial, descubrirá cómo utilizar las estrategias de imputación del vecino más cercano para los datos que faltan en el aprendizaje automático.
Después de completar este tutorial, lo sabrás:
- Los valores perdidos deben ser marcados con valores NaN y pueden ser reemplazados con los valores estimados del vecino más cercano.
- Cómo cargar un archivo CSV con valores faltantes y marcar los valores faltantes con valores NaN e informar el número y el porcentaje de valores faltantes para cada columna.
- Cómo imputar los valores perdidos con los modelos del vecino más cercano como método de preparación de datos al evaluar los modelos y al ajustar un modelo final para hacer predicciones sobre nuevos datos.
Descubre la limpieza de datos, la selección de características, la transformación de datos, la reducción de la dimensionalidad y mucho más en mi nuevo libro, con 30 tutoriales paso a paso y el código fuente completo en Python.
Empecemos.
- Actualizado Jun/2020: Cambió la columna utilizada para la predicción en los ejemplos.

kNN Imputación por valores perdidos en el aprendizaje automático
Foto de Portengaround, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en tres partes; son:
- k-Imputación del vecino más cercano
- Conjunto de datos sobre cólicos de caballo
- Imputación del vecino más cercano con KNNImputer
- Transformación de datos de KNNImputer
- Evaluación del KNNImputer y del modelo
- KNNImputer y un número diferente de vecinos
- KNNImputer se transforma cuando hace una predicción
k-Imputación del vecino más cercano
Un conjunto de datos puede tener valores perdidos.
Son filas de datos en las que no están presentes uno o más valores o columnas de esa fila. Los valores pueden faltar por completo o pueden estar marcados con un carácter o valor especial, como un signo de interrogación «?“.
Los valores podrían faltar por muchas razones, a menudo específicas del dominio del problema, y podrían incluir razones como la corrupción de las mediciones o la falta de disponibilidad.
La mayoría de los algoritmos de aprendizaje por máquina requieren valores de entrada numéricos, y un valor para cada fila y columna en un conjunto de datos. Por lo tanto, los valores perdidos pueden causar problemas para los algoritmos de aprendizaje automático.
Es común identificar los valores faltantes en un conjunto de datos y reemplazarlos por un valor numérico. Esto se llama imputación de datos, o imputación de datos faltantes.
… los datos que faltan pueden ser imputados. En este caso, podemos usar la información de los predictores del conjunto de entrenamiento para, en esencia, estimar los valores de otros predictores.
– Página 42, Applied Predictive Modeling, 2013.
Un enfoque eficaz para la imputación de datos es utilizar un modelo para predecir los valores que faltan. Se crea un modelo para cada característica que tiene valores perdidos, tomando como valores de entrada de quizás todas las demás características de entrada.
Una técnica popular para la imputación es un modelo de vecindad K-nearest. Una nueva muestra se imputa encontrando las muestras en el conjunto de entrenamiento «más cercano» a ella y promedia estos puntos cercanos para completar el valor.
– Página 42, Applied Predictive Modeling, 2013.
Si las variables de entrada son numéricas, entonces se pueden utilizar modelos de regresión para la predicción, y este caso es bastante común. Se puede utilizar un rango de diferentes modelos, aunque un simple modelo de vecino más cercano (KNN) ha demostrado ser efectivo en los experimentos. El uso de un modelo KNN para predecir o rellenar valores perdidos se conoce como «Imputación del vecino más cercano«o»Imputación KNN.”
Demostramos que el KNNimpute parece proporcionar un método más robusto y sensible para la estimación de valores perdidos […] y KNNimpute superan el método de promedio de filas comúnmente utilizado (además de llenar los valores que faltan con ceros).
– Métodos de estimación de valores perdidos para microarreglos de ADN, 2001.
La configuración de la imputación de KNN a menudo implica la selección de la medida de distancia (por ejemplo, euclidiano) y el número de vecinos contribuyentes para cada predicción, el hiperparámetro k del algoritmo KNN.
Ahora que estamos familiarizados con los métodos del vecino más cercano para la imputación de valores perdidos, echemos un vistazo a un conjunto de datos con valores perdidos.
¿Quieres empezar a preparar los datos?
Toma mi curso intensivo gratuito de 7 días por correo electrónico ahora (con código de muestra).
Haga clic para inscribirse y también para obtener una versión gratuita del curso en formato PDF.
Descargue su minicurso GRATUITO
Conjunto de datos sobre cólicos de caballo
El conjunto de datos del cólico de los caballos describe las características médicas de los caballos con cólico y si vivieron o murieron.
Hay 300 filas y 26 variables de entrada con una variable de salida. Es una tarea de predicción de clasificación binaria que implica predecir 1 si el caballo vivió y 2 si el caballo murió.
Hay muchos campos que podríamos seleccionar para predecir en este conjunto de datos. En este caso, predeciremos si el problema fue quirúrgico o no (índice de la columna 23), convirtiéndolo en un problema de clasificación binaria.
El conjunto de datos tiene muchos valores perdidos para muchas de las columnas donde cada valor perdido se marca con un carácter de signo de interrogación («?»).
A continuación se presenta un ejemplo de filas del conjunto de datos con valores perdidos marcados.
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2 1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2 2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1 1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1 … |
Puedes aprender más sobre el conjunto de datos aquí:
No es necesario descargar el conjunto de datos ya que lo descargaremos automáticamente en los ejemplos trabajados.
Marcar los valores perdidos con un valor de NaN (no un número) en un conjunto de datos cargado usando Python es una buena práctica.
Podemos cargar el conjunto de datos usando la función read_csv() Pandas y especificar los «valores na» para cargar los valores de ‘?’ como faltantes, marcados con un valor NaN.
|
... # Cargar conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’ dataframe = read_csv(url, encabezado=Ninguno, na_valores=‘?’) |
Una vez cargados, podemos revisar los datos cargados para confirmar que los valores de «?» están marcados como NaN.
|
... # Resumir las primeras filas imprimir(dataframe.cabeza()) |
Podemos entonces enumerar cada columna y reportar el número de filas con los valores faltantes para la columna.
|
... # Resumir el número de filas con los valores que faltan para cada columna para i en rango(dataframe.forma[[1]): # contar el número de filas con valores perdidos n_miss = dataframe[[[[i]].isull().suma() perc = n_miss / dataframe.forma[[0] * 100 imprimir(«> %d, Desaparecido: %d (%.1f%%) % (i, n_miss, perc)) |
A continuación se presenta un ejemplo completo de la carga y el resumen del conjunto de datos.
|
# Resumir el conjunto de datos del cólico de los caballos de pandas importación read_csv # Cargar conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’ dataframe = read_csv(url, encabezado=Ninguno, na_valores=‘?’) # Resumir las primeras filas imprimir(dataframe.cabeza()) # Resumir el número de filas con los valores que faltan para cada columna para i en rango(dataframe.forma[[1]): # contar el número de filas con valores perdidos n_miss = dataframe[[[[i]].isull().suma() perc = n_miss / dataframe.forma[[0] * 100 imprimir(«> %d, Desaparecido: %d (%.1f%%) % (i, n_miss, perc)) |
Al ejecutar el ejemplo primero se carga el conjunto de datos y se resumen las cinco primeras filas.
Podemos ver que los valores que faltaban y que estaban marcados con un carácter «?» han sido reemplazados por valores de NaN.
|
0 1 2 3 4 5 6 … 21 22 23 24 25 26 27 0 2.0 1 530101 38.5 66.0 28.0 3.0 … NaN 2.0 2 11300 0 0 2 1 1.0 1 534817 39.2 88.0 20.0 NaN … 2.0 3.0 2 2208 0 0 2 2 2.0 1 530334 38.3 40.0 24.0 1.0 … NaN 1.0 2 0 0 0 1 3 1.0 9 5290409 39.1 164.0 84.0 4.0 … 5.3 2.0 1 2208 0 0 1 4 2.0 1 530255 37.3 104.0 35.0 NaN … NaN 2.0 2 4300 0 0 2 [5 rows x 28 columns] |
A continuación, podemos ver una lista de todas las columnas del conjunto de datos y el número y el porcentaje de los valores que faltan.
Podemos ver que algunas columnas (por ejemplo, los índices de las columnas 1 y 2) no tienen valores perdidos y otras columnas (por ejemplo, los índices de las columnas 15 y 21) tienen muchos o incluso la mayoría de los valores perdidos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
> 0, Desaparecido: 1 (0.3%) > 1, Desaparecido: 0 (0.0%) > 2, Desaparecido: 0 (0.0%) > 3, Desaparecido: 60 (20.0%) > 4, Desaparecido: 24 (8.0%) > 5, Desaparecido: 58 (19.3%) > 6, Desaparecido: 56 (18.7%) > 7, Desaparecido: 69 (23.0%) > 8, Desaparecido: 47 (15.7%) > 9, Desaparecido: 32 (10.7%) > 10, Desaparecido: 55 (18.3%) > 11, Desaparecido: 44 (14.7%) > 12, Desaparecido: 56 (18.7%) > 13, Desaparecido: 104 (34.7%) > 14, Desaparecido: 106 (35.3%) > 15, Desaparecido: 247 (82.3%) > 16, Desaparecido: 102 (34.0%) > 17, Desaparecido: 118 (39.3%) > 18, Desaparecido: 29 (9.7%) > 19, Desaparecido: 33 (11.0%) > 20, Desaparecido: 165 (55.0%) > 21, Desaparecido: 198 (66.0%) > 22, Desaparecido: 1 (0.3%) > 23, Desaparecido: 0 (0.0%) > 24, Desaparecido: 0 (0.0%) > 25, Desaparecido: 0 (0.0%) > 26, Desaparecido: 0 (0.0%) > 27, Desaparecido: 0 (0.0%) |
Ahora que estamos familiarizados con el conjunto de datos del cólico de caballo que tiene valores perdidos, veamos cómo podemos usar la imputación del vecino más cercano.
Imputación del vecino más cercano con KNNImputer
La biblioteca de aprendizaje de la máquina de aprendizaje de ciencias proporciona la clase de KNNImputer que apoya la imputación del vecino más cercano.
En esta sección, exploraremos cómo utilizar eficazmente el KNNImputer clase.
Transformación de datos de KNNImputer
KNNImputer es una transformación de datos que se configura primero en base al método utilizado para estimar los valores que faltan.
La medida de distancia por defecto es una medida de distancia euclidiana que es consciente de NaN, por ejemplo, no incluirá los valores de NaN cuando se calcule la distancia entre los miembros del conjunto de datos de entrenamiento. Esto se establece a través de la función «métrico«argumento».
El número de vecinos está establecido en cinco por defecto y puede ser configurado por el «n_vecinos«argumento».
Por último, la medida de la distancia puede ser ponderada de forma proporcional a la distancia entre instancias (filas), aunque esto se establece en una ponderación uniforme por defecto, controlada a través de la función «pesos«argumento».
|
... # definir imputador imputador = KNNImputer(n_vecinos=5, pesos=«uniforme, métrico=‘nan_euclidiano’) |
Entonces, el imputador se ajusta a un conjunto de datos.
|
... # Encajar en el conjunto de datos imputador.encajar(X) |
Luego, el imputador de ajuste se aplica a un conjunto de datos para crear una copia del conjunto de datos con todos los valores que faltan para cada columna reemplazados por un valor estimado.
|
... # Transformar el conjunto de datos Xtrans = imputador.Transformar(X) |
Podemos demostrar su uso en el conjunto de datos del cólico de caballo y confirmar que funciona resumiendo el número total de valores que faltan en el conjunto de datos antes y después de la transformación.
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# Transformación de imputación knn para el conjunto de datos del cólico de caballo # de numpy importación isan de pandas importación read_csv de sklearn.imputar importación KNNImputer # Cargar conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’ dataframe = read_csv(url, encabezado=Ninguno, na_valores=‘?’) # Dividido en elementos de entrada y salida datos = dataframe.valores ix = [[i para i en rango(datos.forma[[1]) si i != 23] X, y = datos[[:, ix], datos[[:, 23] # Imprimir el total de lo que falta imprimir(«Desaparecido: %d % suma(isan(X).aplanar())) # definir imputador imputador = KNNImputer() # Encajar en el conjunto de datos imputador.encajar(X) # Transformar el conjunto de datos Xtrans = imputador.Transformar(X) # Imprimir el total de lo que falta imprimir(«Desaparecido: %d % suma(isan(Xtrans).aplanar())) |
Al ejecutar el ejemplo primero se carga el conjunto de datos y se reporta el número total de valores faltantes en el conjunto de datos como 1.605.
La transformación está configurada, ajustada y realizada, y el nuevo conjunto de datos resultante no tiene valores perdidos, lo que confirma que se realizó como esperábamos.
Cada valor que faltaba fue reemplazado por un valor estimado por el modelo.
Evaluación del KNNImputer y del modelo
Es una buena práctica evaluar los modelos de aprendizaje de la máquina en un conjunto de datos utilizando la validación cruzada del pliegue k.
Para aplicar correctamente la imputación de datos faltantes del vecino más cercano y evitar la fuga de datos, se requiere que los modelos se calculen para cada columna se calculen en el conjunto de datos de entrenamiento solamente, y luego se apliquen al tren y a los conjuntos de pruebas para cada pliegue del conjunto de datos.
Esto puede lograrse creando una tubería de modelación donde el primer paso es la imputación del vecino más cercano, luego el segundo paso es el modelo. Esto puede lograrse usando la clase de tubería.
Por ejemplo, el Pipeline que se muestra a continuación utiliza un KNNImputer con la estrategia predeterminada, seguida de un modelo de bosque aleatorio.
|
... # Definir la tubería de modelado modelo = RandomForestClassifier() imputador = KNNImputer() tubería = Oleoducto(pasos=[[(‘i’, imputador), (‘m’, modelo)]) |
Podemos evaluar el conjunto de datos imputados y la tubería de modelación forestal aleatoria para el conjunto de datos del cólico de caballo con una validación cruzada repetida 10 veces.
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Evaluar la imputación de knn y el bosque aleatorio para el conjunto de datos del cólico del caballo # de numpy importación significa de numpy importación std de pandas importación read_csv de sklearn.conjunto importación RandomForestClassifier de sklearn.imputar importación KNNImputer de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.tubería importación Oleoducto # Cargar conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’ dataframe = read_csv(url, encabezado=Ninguno, na_valores=‘?’) # Dividido en elementos de entrada y salida datos = dataframe.valores ix = [[i para i en rango(datos.forma[[1]) si i != 23] X, y = datos[[:, ix], datos[[:, 23] # Definir la tubería de modelado modelo = RandomForestClassifier() imputador = KNNImputer() tubería = Oleoducto(pasos=[[(‘i’, imputador), (‘m’, modelo)]) # Definir la evaluación del modelo cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Evaluar el modelo resultados = puntaje_valor_cruzado(tubería, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1, error_score=«aumentar) imprimir(«Precisión media: %.3f (%.3f) % (significa(resultados), std(resultados))) |
Al ejecutar el ejemplo correctamente se aplica la imputación de datos a cada pliegue del procedimiento de validación cruzada.
El oleoducto se evalúa utilizando tres repeticiones de validación cruzada de 10 veces e informa de la precisión de la clasificación media en el conjunto de datos de alrededor del 86,2 por ciento, que es una puntuación razonable.
|
Precisión media: 0,862 (0,059) |
¿Cómo sabemos que usar un número predeterminado de vecinos de cinco es bueno o mejor para este conjunto de datos?
La respuesta es que no.
KNNImputer y un número diferente de vecinos
El hiperparámetro clave para el algoritmo KNN es kque controla el número de vecinos más cercanos que se utilizan para contribuir a una predicción.
Es una buena práctica probar un conjunto de valores diferentes para k.
En el ejemplo que figura a continuación se evalúan los conductos modelo y se comparan los valores impares de k del 1 al 21.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# Comparar las estrategias de imputación de knn para el conjunto de datos del cólico de caballo # de numpy importación significa de numpy importación std de pandas importación read_csv de sklearn.conjunto importación RandomForestClassifier de sklearn.imputar importación KNNImputer de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.tubería importación Oleoducto de matplotlib importación pyplot # Cargar conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’ dataframe = read_csv(url, encabezado=Ninguno, na_valores=‘?’) # Dividido en elementos de entrada y salida datos = dataframe.valores ix = [[i para i en rango(datos.forma[[1]) si i != 23] X, y = datos[[:, ix], datos[[:, 23] # Evaluar cada estrategia en el conjunto de datos resultados = lista() estrategias = [[str(i) para i en [[1,3,5,7,9,15,18,21]] para s en estrategias: # Crear la tubería de modelado tubería = Oleoducto(pasos=[[(‘i’, KNNImputer(n_vecinos=int(s))), (‘m’, RandomForestClassifier())]) # Evaluar el modelo cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(tubería, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) # Almacenar los resultados resultados.anexar(resultados) imprimir(«>%s %.3f (%.3f) % (s, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=estrategias, showmeans=Verdadero) pyplot.mostrar() |
Al ejecutar el ejemplo se evalúa cada k en el conjunto de datos del cólico de caballo usando repetidas validaciones cruzadas.
Sus resultados específicos pueden variar dada la naturaleza estocástica del algoritmo de aprendizaje; considere ejecutar el ejemplo unas cuantas veces.
La exactitud de la clasificación media se informa para el oleoducto con cada k valor utilizado para la imputación.
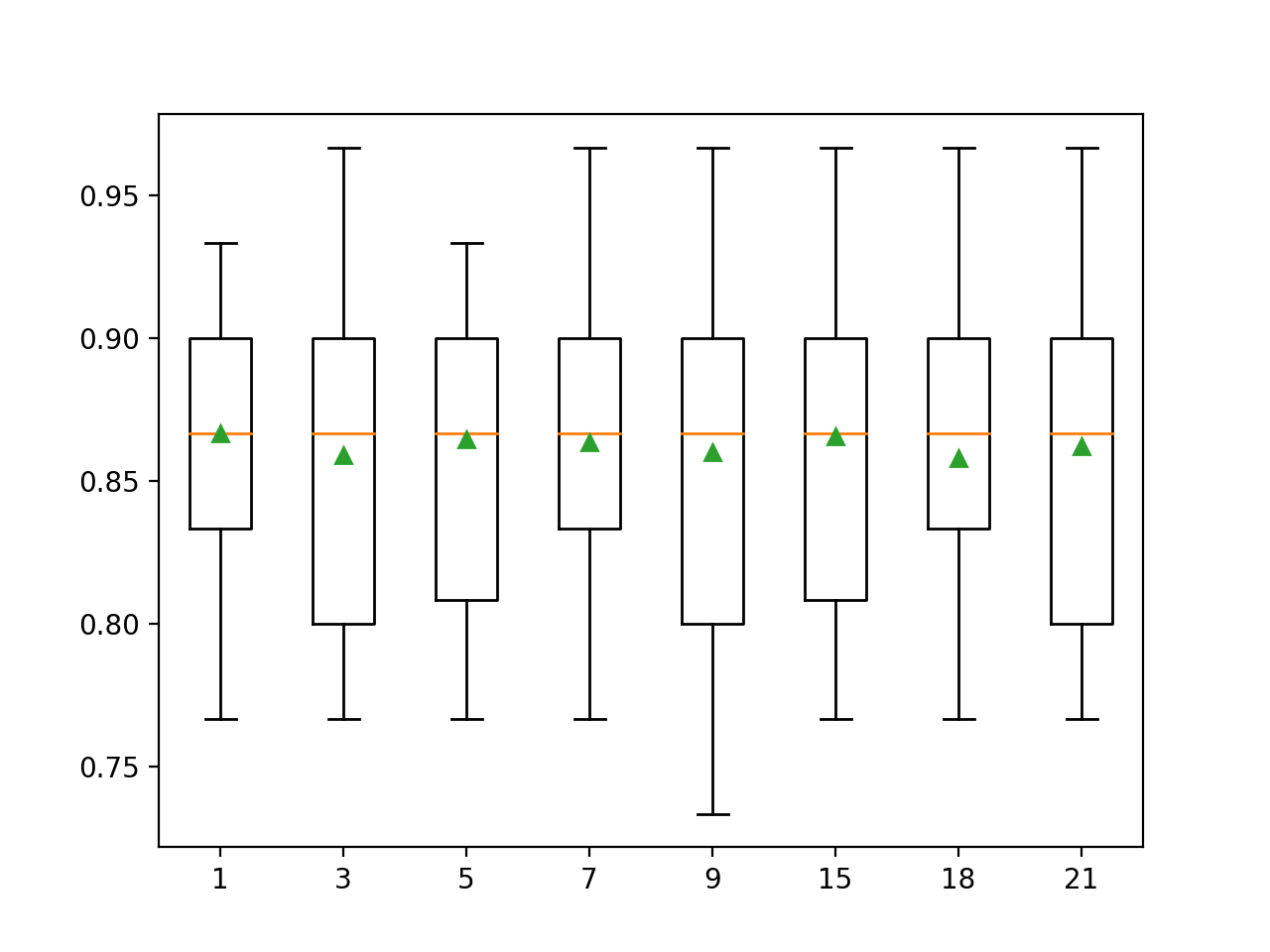
En este caso, podemos ver que valores k más grandes resultan en un modelo de mejor rendimiento, con un k=1 resultando en el mejor rendimiento de alrededor del 86,7 por ciento de precisión.
|
>1 0.867 (0.049) >3 0.859 (0.056) >5 0.864 (0.054) >7 0.863 (0.053) >9 0.860 (0.062) >15 0.866 (0.054) >18 0.858 (0.052) >21 0.862 (0.056) |
Al final del recorrido, se crea un gráfico de caja y bigote para cada conjunto de resultados, lo que permite comparar la distribución de los resultados.
La gráfica sugiere que no hay mucha diferencia en el valor de k al imputar los valores que faltan, con pequeñas fluctuaciones alrededor del rendimiento medio (triángulo verde).
Cuadro de Imputación de Caja y Bigote Número de Vecinos para el Conjunto de Datos del Cólico del Caballo
KNNImputer se transforma cuando hace una predicción
Puede que queramos crear un modelo final de tubería con la imputación del vecino más cercano y un algoritmo de bosque aleatorio, y luego hacer una predicción para los nuevos datos.
Esto puede lograrse definiendo la tubería y ajustándola a todos los datos disponibles, y luego llamando a la predecir() pasando nuevos datos como un argumento.
Es importante que la fila de nuevos datos marque los valores que faltan con el valor NaN.
|
... # Definir nuevos datos fila = [[2, 1, 530101, 38.50, 66, 28, 3, 3, nan, 2, 5, 4, 4, nan, nan, nan, 3, 5, 45.00, 8.40, nan, nan, 2, 11300, 00000, 00000, 2] |
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# Estrategia de imputación knn y predicción para el conjunto de datos del cólico de la manguera # de numpy importación nan de pandas importación read_csv de sklearn.conjunto importación RandomForestClassifier de sklearn.imputar importación KNNImputer de sklearn.tubería importación Oleoducto # Cargar conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’ dataframe = read_csv(url, encabezado=Ninguno, na_valores=‘?’) # Dividido en elementos de entrada y salida datos = dataframe.valores ix = [[i para i en rango(datos.forma[[1]) si i != 23] X, y = datos[[:, ix], datos[[:, 23] # Crear la tubería de modelado tubería = Oleoducto(pasos=[[(‘i’, KNNImputer(n_vecinos=21)), (‘m’, RandomForestClassifier())]) # Encaja con el modelo tubería.encajar(X, y) # Definir nuevos datos fila = [[2, 1, 530101, 38.50, 66, 28, 3, 3, nan, 2, 5, 4, 4, nan, nan, nan, 3, 5, 45.00, 8.40, nan, nan, 2, 11300, 00000, 00000, 2] # hacer una predicción yhat = tubería.predecir([[fila]) # resumir la predicción imprimir(Clase prevista: %d’. % yhat[[0]) |
La ejecución del ejemplo se ajusta a la tubería de modelación en todos los datos disponibles.
Se define una nueva fila de datos con valores perdidos marcados con NaNs y se hace una predicción de clasificación.