

Crédito: Artístico
Las redes de adversarios generativos son una especie de algoritmo de inteligencia artificial diseñado para resolver el modelado generativo problema. El objetivo de un modelo generativo es estudiar una colección de ejemplos de capacitación y conocer la distribución de probabilidad que los generó. Las redes generativas adversas (RGA) pueden entonces generar más ejemplos a partir de la distribución de probabilidad estimada. Los modelos generativos basados en el aprendizaje profundo son comunes, pero las RGA se encuentran entre los modelos generativos más exitosos (especialmente en cuanto a su capacidad de generar imágenes realistas de alta resolución). Las GAN se han aplicado con éxito a una amplia variedad de tareas (sobre todo en entornos de investigación), pero siguen presentando desafíos y oportunidades de investigación únicos porque se basan en la teoría de los juegos, mientras que la mayoría de los demás enfoques de la modelización generativa se basan en la optimización.
Volver al principio
1. Introducción
La mayoría de los enfoques actuales para el desarrollo de la inteligencia artificial se basan principalmente en el aprendizaje de la máquina. La forma más utilizada y exitosa de aprendizaje automático hasta la fecha es el aprendizaje supervisado. Los algoritmos de aprendizaje supervisado reciben un conjunto de datos de pares de entradas y salidas de ejemplo. Aprenden a asociar cada entrada con cada salida y así aprenden un mapeo de ejemplos de entrada a salida. Los ejemplos de entrada suelen ser objetos de datos complicados como imágenes, frases en lenguaje natural o formas de onda de audio, mientras que los ejemplos de salida suelen ser relativamente sencillos. El tipo más común de aprendizaje supervisado es la clasificación, en la que la salida es sólo un código entero que identifica una categoría específica (una foto puede reconocerse como procedente de la categoría 0 que contiene gatos, o de la categoría 1 que contiene perros, etc.).
El aprendizaje supervisado suele ser capaz de lograr una precisión mayor que la humana una vez completado el proceso de capacitación, y por lo tanto se ha integrado en muchos productos y servicios. Desafortunadamente, el proceso de aprendizaje en sí mismo todavía está muy lejos de las capacidades humanas. El aprendizaje supervisado, por definición, se basa en que un supervisor humano proporcione un ejemplo de salida para cada ejemplo de entrada. Peor aún, los enfoques existentes del aprendizaje supervisado a menudo requieren millones de ejemplos de capacitación para superar el rendimiento humano, cuando un humano podría aprender a realizar la tarea aceptablemente a partir de un número muy reducido de ejemplos.
Con el fin de reducir tanto la cantidad de supervisión humana necesaria para el aprendizaje como el número de ejemplos necesarios para el aprendizaje, muchos investigadores estudian hoy en día aprendizaje no supervisadoa menudo usando… modelos generativos. En este documento de resumen, describimos un enfoque particular para el aprendizaje no supervisado a través de un modelo generativo llamado redes generativas de adversarios. Revisamos brevemente las aplicaciones de las GAN e identificamos los problemas centrales de investigación relacionados con la convergencia en los juegos necesarios para hacer de las GAN una tecnología fiable.
Volver al principio
2. 2. Modelado generativo
El objetivo del aprendizaje supervisado es relativamente sencillo de especificar, y todos los algoritmos de aprendizaje supervisado tienen esencialmente el mismo objetivo: aprender a asociar con precisión los nuevos ejemplos de entrada con las salidas correctas. Por ejemplo, un algoritmo de reconocimiento de objetos puede asociar una foto de un perro con algún tipo de DOG identificador de categoría.
El aprendizaje no supervisado es una rama menos definida del aprendizaje automático, con muchos algoritmos diferentes de aprendizaje no supervisado que persiguen muchos objetivos diferentes. En términos generales, el objetivo del aprendizaje no supervisado es aprender algo útil examinando un conjunto de datos que contenga ejemplos de entradas no etiquetadas. La agrupación y la reducción de la dimensionalidad son ejemplos comunes de aprendizaje no supervisado.
Otro enfoque para el aprendizaje no supervisado es el modelo generativo. En el modelado generativo, los ejemplos de capacitación x se extraen de una distribución desconocida pdatos(x). El objetivo de un algoritmo de modelado generativo es aprender un pmodelo(x) que se aproxima pdatos(x) lo más cerca posible.
Una forma sencilla de aprender una aproximación de pdatos es escribir explícitamente una función pmodelo(x; θ) controlado por parámetros θ y buscar el valor de los parámetros que hace que pdatos y pmodelo tan similar como sea posible. En particular, el enfoque más popular de la modelación generativa es probablemente estimación de máxima probabilidadque consiste en minimizar la divergencia Kullback-Leibler entre pdatos y pmodelo. El enfoque común de estimar el parámetro medio de una distribución gaussiana tomando la media de un conjunto de observaciones es un ejemplo de estimación de máxima probabilidad. Este enfoque basado en funciones de densidad explícitas se ilustra en la figura 1.
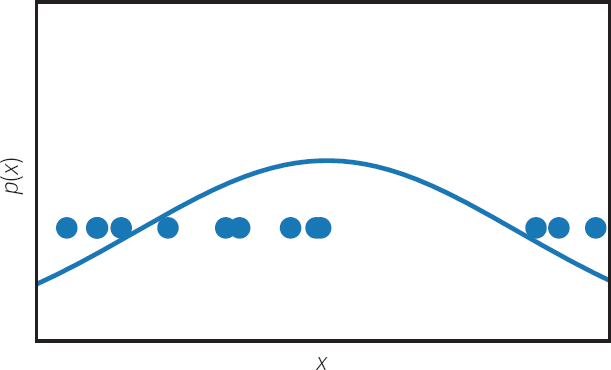
Figura 1. Muchos enfoques de la modelación generativa se basan en estimación de la densidad: observando varios ejemplos de entrenamiento de una variable aleatoria x e inferir una función de densidad p(x) que genera los datos de entrenamiento. Este enfoque se ilustra aquí, con varios puntos de datos en una línea numérica real utilizada para ajustar una función de densidad gaussiana que explica las muestras observadas. En contraste con este enfoque común, los GAN son modelos implícitos que infieren la distribución de probabilidad p(x) sin representar necesariamente la función de densidad de forma explícita.
La modelización de la densidad explícita ha funcionado bien para las estadísticas tradicionales, utilizando formas funcionales sencillas de distribuciones de probabilidad, que suelen aplicarse a un número reducido de variables. Más recientemente, con el auge del aprendizaje automático en general y del aprendizaje profundo en particular, los investigadores se han interesado por modelos de aprendizaje que utilizan formas funcionales relativamente complicadas. Cuando se utiliza una red neuronal profunda para generar datos, la función de densidad correspondiente puede ser computablemente intratable. Tradicionalmente, ha habido dos enfoques dominantes para hacer frente a este problema de intratabilidad: 1) diseñar cuidadosamente el modelo para que tenga una función de densidad manejable (por ejemplo, Frey11) y (2) diseñar un algoritmo de aprendizaje basado en una aproximación computable de una función de densidad intratable (por ejemplo, Kingma y Welling15). Ambos enfoques han demostrado ser difíciles, y para muchas aplicaciones, como la generación de imágenes realistas de alta resolución, los investigadores siguen sin estar satisfechos con los resultados hasta ahora. Esto motiva a seguir investigando para mejorar estos dos caminos, pero también sugiere que un tercer camino podría ser útil.
Además de tomar un punto x como entrada y devolviendo una estimación de la probabilidad de generar ese punto, un modelo generativo puede ser útil si es capaz de generar una muestra de la distribución pmodelo. Esto se ilustra en la figura 2. Muchos modelos que representan una función de densidad también pueden generar muestras de esa función de densidad. En algunos casos, la generación de muestras es muy costosa o sólo se pueden seguir métodos aproximados de generación de muestras.
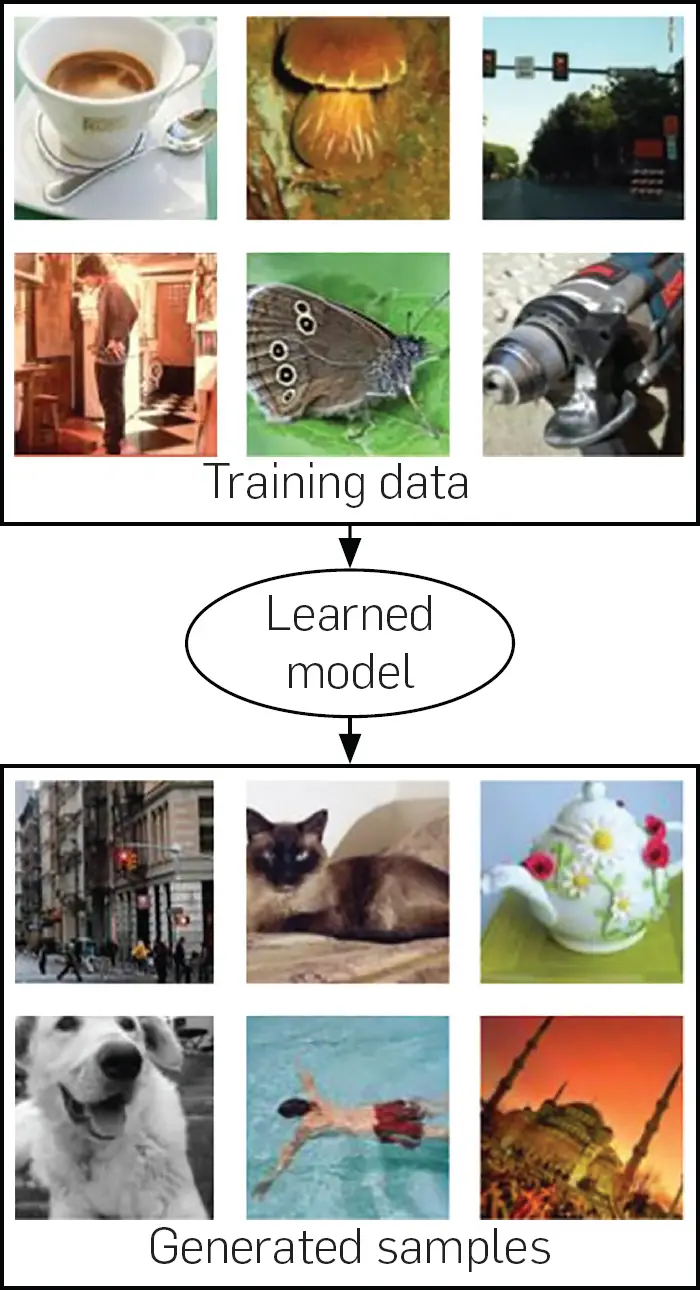
Figura 2. El objetivo de muchos modelos generativos, como se ilustra aquí, es estudiar una colección de ejemplos de capacitación, para luego aprender a generar más ejemplos que provengan de la misma distribución de probabilidad. Los GAN aprenden a hacer esto sin usar una representación explícita de la función de densidad. Una ventaja del marco de la GAN es que puede aplicarse a modelos para los cuales la función de densidad es computablemente intratable. Las muestras que se muestran aquí son todas muestras del conjunto de datos de ImageNet,8 incluyendo las que se llaman «muestras modelo». Utilizamos los datos reales de ImageNet para ilustrar el objetivo que alcanzaría un hipotético modelo perfecto.
Algunos modelos generativos evitan todo el problema de diseñar una función de densidad manejable y aprenden sólo un proceso de generación de muestras manejable. Estos se llaman modelos generativos implícitos. Los GAN entran en esta categoría. Antes de la introducción de las GAN, el modelo generativo implícito profundo de última generación era el red estocástica generativa4 que es capaz de generar aproximadamente muestras a través de un proceso incremental basado en las cadenas de Markov. Las GAN se introdujeron con el fin de crear un modelo generativo implícito profundo que fuera capaz de generar muestras verdaderas a partir de la distribución del modelo en un solo paso de generación, sin necesidad del proceso de generación incremental o de la naturaleza aproximada del muestreo de las cadenas de Markov.
Hoy en día, los enfoques más populares para el modelado generativo son probablemente los GAN, autocodificadores variacionales,15 y redes de creencias totalmente visibles (por ejemplo, Frey11, 26). Ninguno de estos enfoques se basa en las cadenas de Markov, por lo que la razón del interés en las GAN hoy en día no es que hayan tenido éxito en su objetivo original de modelado generativo sin las cadenas de Markov, sino que han logrado generar imágenes de alta calidad y han demostrado ser útiles para varias tareas distintas de la generación directa, como se describe en la Sección 5.
Volver al principio
3. 3. Redes adversas generativas
Las redes de adversarios generativos se basan en un juego, en el sentido de la teoría del juego, entre dos modelos de aprendizaje por máquina, típicamente implementados utilizando redes neuronales.
Una red llamada generador define pmodelo(x) implícitamente. El generador no es necesariamente capaz de evaluar la función de densidad pmodelo. En el caso de algunas variantes de las redes de área amplia, es posible evaluar la función de densidad (cualquier modelo de densidad trazable para el que el muestreo sea trazable y diferenciable podría entrenarse como generador de redes de área amplia, como lo han hecho Danihelka et al.6), pero esto no es necesario. En su lugar, el generador es capaz de extraer muestras de la distribución pmodelo. El generador se define por una distribución previa p(z) sobre un vector z que sirve como entrada a la función del generador G(z; θ(G)) donde θ(G) es un conjunto de parámetros aprendibles que definen la estrategia del generador en el juego. El vector de entrada z puede pensarse como una fuente de aleatoriedad en un sistema por lo demás determinista, análogo a la semilla del generador de números pseudoaleatorios. La distribución anterior p(z) suele ser una distribución relativamente desestructurada, como una distribución gaussiana de alta dimensión o una distribución uniforme en un hipercubo. Muestras z de esta distribución son entonces sólo ruido. El papel principal del generador es aprender la función G(z) que transforma tal ruido desestructurado z en muestras realistas.
El otro jugador en este juego es el discriminador. El discriminador examina las muestras x y devuelve alguna estimación D(x; θ(D)) de si x es real (extraído de la distribución de entrenamiento) o falso (extraído de pmodelo al hacer funcionar el generador). En la formulación original de los GAN, esta estimación consiste en una probabilidad de que la entrada sea real en lugar de falsa, suponiendo que la distribución real y la falsa se muestre con la misma frecuencia. Otras formulaciones (por ejemplo, Arjovsky et al.1), pero en general, a nivel de descripciones verbales e intuitivas, el discriminador trata de predecir si la entrada fue real o falsa.
Cada jugador incurre en un costo: J(G)(θ(G), θ(D)) para el generador y J(D)(θ(G), θ(D)) para el discriminador. Cada jugador intenta minimizar su propio costo. A grandes rasgos, el coste del discriminador le anima a clasificar correctamente los datos como reales o falsos, mientras que el coste del generador le anima a generar muestras que el discriminador clasifica incorrectamente como reales. Son posibles muchas formulaciones específicas diferentes de estos costos y hasta ahora las formulaciones más populares parecen funcionar aproximadamente igual.18 En la versión original de las GAN, J(D) se definió como la probabilidad negativa de registro que el discriminador asigna a las etiquetas real vs. falsa dada la entrada al discriminador. En otras palabras, el discriminador está entrenado como un clasificador binario normal. El trabajo original sobre GANs ofrecía dos versiones del coste del generador. Una versión, hoy en día llamada minimax GAN (M-GAN) definió un costo J(G) = –J(D)…dando un juego de minimáximo que es fácil de analizar teóricamente. M-GAN define el costo del generador cambiando el signo del costo del discriminador; otro enfoque es el GAN no saturado (NS-GAN), para lo cual el costo del generador se define volteando el discriminador etiquetas. En otras palabras, se intenta que el generador minimice la probabilidad de registro negativo que el discriminador asigna al equivocada etiquetas. Esta última ayuda a evitar la saturación del gradiente mientras se entrena al modelo.
Podemos pensar en las GAN como un poco como los falsificadores y la policía: los falsificadores hacen dinero falso mientras que la policía trata de detener a los falsificadores y sigue permitiendo el gasto de dinero legítimo. La competencia entre los falsificadores y la policía lleva a que el dinero falso sea cada vez más realista hasta que finalmente los falsificadores producen falsificaciones perfectas y la policía no puede diferenciar entre el dinero real y el falso. Una complicación de esta analogía es que el generador aprende a través del gradiente del discriminador, como si los falsificadores tuviesen un topo entre la policía informando de los métodos específicos que la policía utiliza para detectar las falsificaciones.
Este proceso se ilustra en la figura 3. La figura 4 muestra una caricatura que da una cierta intuición de cómo funciona el proceso.
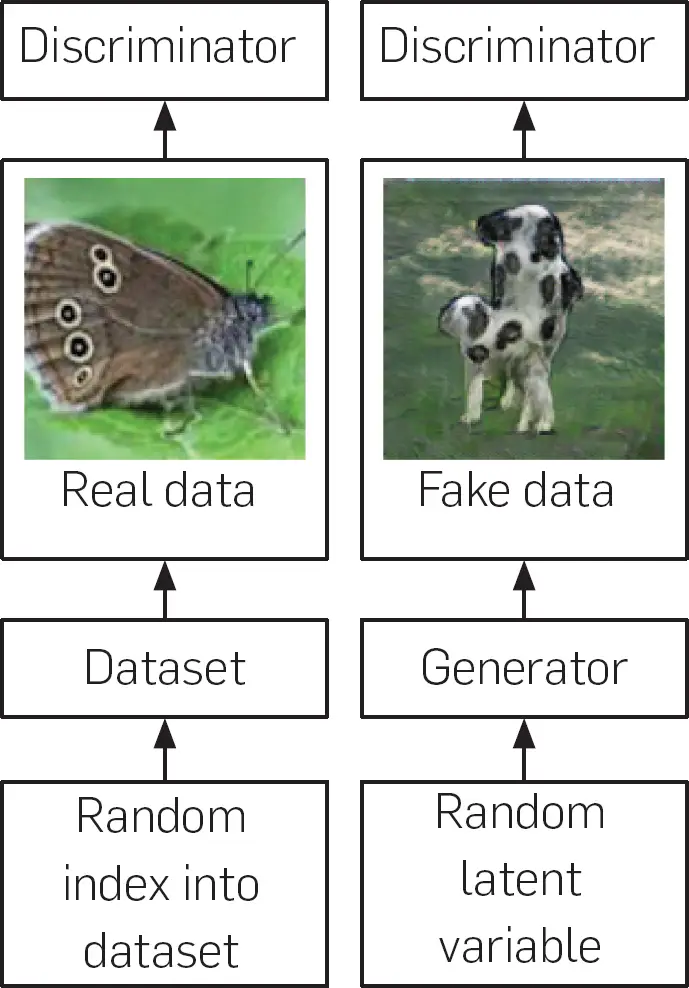
Figura 3. El entrenamiento de las GAN implica el entrenamiento de una red de generadores y una red de discriminadores. El proceso implica tanto datos reales extraídos de un conjunto de datos como datos falsos creados continuamente por el generador a lo largo del proceso de capacitación. El discriminador se entrena como cualquier otro clasificador definido por una red neural profunda. Como se muestra a la izquierda, al discriminador se le muestran los datos del conjunto de entrenamiento. En este caso, el discriminador está entrenado para asignar datos a la clase «real». Como se muestra a la derecha, el proceso de entrenamiento también incluye datos falsos. Los datos falsos se construyen mediante el primer muestreo de un vector aleatorio z a partir de una distribución previa sobre las variables latentes del modelo. El generador se utiliza entonces para producir una muestra x = G(z). La función G es simplemente una función representada por una red neuronal que transforma el azar, no estructurado z vector en datos estructurados, destinados a ser estadísticamente indistinguibles de los datos de entrenamiento. El discriminador clasifica entonces estos datos falsos. El discriminador está entrenado para asignar estos datos a la clase «falsa». El algoritmo de retropropagación permite utilizar los derivados de la salida del discriminador con respecto a la entrada del discriminador para entrenar al generador. El generador está entrenado para engañar al discriminador, en otras palabras, para hacer que el discriminador asigne su entrada a la clase «real». El proceso de formación del discriminador es, por tanto, muy similar al de cualquier otro clasificador binario, con la excepción de que los datos de la clase «falsa» proceden de una distribución que cambia constantemente a medida que el generador aprende y no de una distribución fija. El proceso de aprendizaje para el generador es algo único, porque no se le dan objetivos específicos para su salida, sino que simplemente se le da una recompensa por producir salidas que engañan a su oponente (que cambia constantemente).
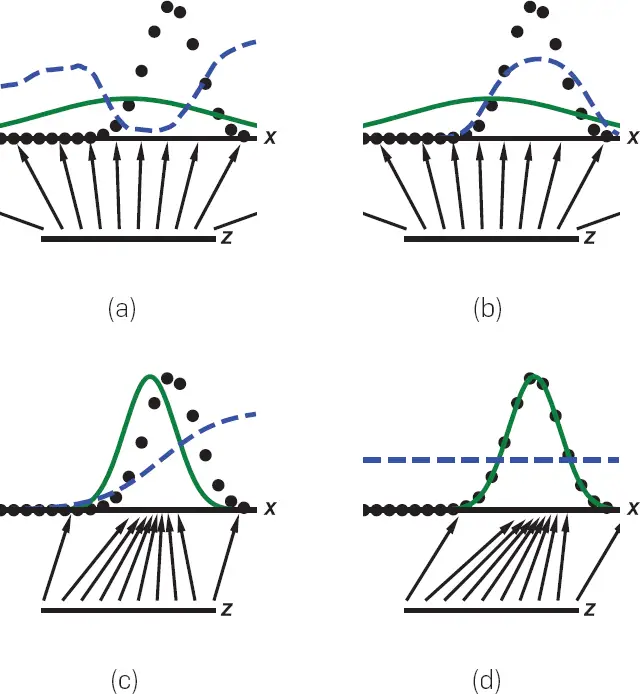
Figura 4. Una ilustración de la intuición básica del proceso de entrenamiento de GAN, ilustrada con el ajuste de una distribución Gaussiana 1-D. En este ejemplo, podemos entender el objetivo del generador como el aprendizaje de una simple escala de la función de distribución acumulativa inversa de la distribución generadora de datos. Las GAN se entrenan actualizando simultáneamente la función discriminadora (D(línea azul, línea discontinua) para que discrimine entre las muestras de la distribución generadora de datos (línea negra, línea punteada) px de los de la distribución generativa pmodelo (verde, línea sólida). La línea horizontal inferior es el dominio desde el cual z se muestrean, en este caso uniformemente. La línea horizontal de arriba forma parte del dominio de x. Las flechas ascendentes muestran cómo la cartografía x = G(z) impone la distribución no uniforme pmodelo en muestras transformadas. G se contrae en regiones de alta densidad y se expande en regiones de baja densidad de pmodelo. a) Considerar un par de redes de adversarios en la inicialización: pmodelo se inicializa a una unidad Gaussiana para este ejemplo mientras que D se define por una red neural profunda iniciada al azar, b) Supongamos que D fueron entrenados para la convergencia mientras G se mantuvieron fijos. En la práctica, ambos se entrenan simultáneamente, pero con el propósito de construir la intuición, vemos que si G se arreglaron, D convergerían en D* 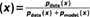 . (c) Ahora supongamos que gradualmente entrenamos a ambos G y D por un tiempo. Las muestras x generada por G flujo en la dirección de aumentar D a fin de llegar a las regiones que tienen más probabilidades de ser clasificadas como datos. Mientras tanto, la estimación de D se actualiza en respuesta a esta actualización en G. d) En el equilibrio de Nash, ningún jugador puede mejorar su rendimiento porque pmodelo = pdatos. El discriminador es incapaz de diferenciar entre las dos distribuciones, es decir, D(x)=½. Esta función constante muestra que todos los puntos tienen la misma probabilidad de provenir de cualquiera de las dos distribuciones. En la práctica, G y D son típicamente optimizados con pasos de gradiente simultáneos, y no es necesario para D para ser óptimo en cada paso como se muestra en esta intuitiva caricatura. Ver Refs. Fedus et al.10 y Nagarajan y Kolter24 para discusiones más realistas del proceso de equilibrio de la GAN.
. (c) Ahora supongamos que gradualmente entrenamos a ambos G y D por un tiempo. Las muestras x generada por G flujo en la dirección de aumentar D a fin de llegar a las regiones que tienen más probabilidades de ser clasificadas como datos. Mientras tanto, la estimación de D se actualiza en respuesta a esta actualización en G. d) En el equilibrio de Nash, ningún jugador puede mejorar su rendimiento porque pmodelo = pdatos. El discriminador es incapaz de diferenciar entre las dos distribuciones, es decir, D(x)=½. Esta función constante muestra que todos los puntos tienen la misma probabilidad de provenir de cualquiera de las dos distribuciones. En la práctica, G y D son típicamente optimizados con pasos de gradiente simultáneos, y no es necesario para D para ser óptimo en cada paso como se muestra en esta intuitiva caricatura. Ver Refs. Fedus et al.10 y Nagarajan y Kolter24 para discusiones más realistas del proceso de equilibrio de la GAN.
La situación no es sencilla de modelar como un problema de optimización porque el costo de cada jugador es una función de los parámetros del otro jugador, pero cada jugador puede controlar sólo sus propios parámetros. Es posible reducir la situación a la optimización, donde el objetivo es minimizar
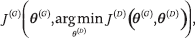
como lo demuestran Metz y otros..,22 pero la operación de argmín es difícil de trabajar de esta manera. El enfoque más popular es considerar esta situación como un juego entre dos jugadores. Gran parte de la literatura de la teoría de juegos se ocupa de juegos que tienen espacios de acción discretos y finitos, pérdidas convexas u otras propiedades que los simplifican. Las redes de área amplia requieren el uso de la teoría de juegos en entornos que aún no están bien explorados, donde los costos no son convexos y las acciones y políticas son continuas y de gran dimensión (independientemente de que consideremos que una acción es la elección de un vector de parámetro específico θ(G) o si consideramos que la acción está generando una muestra x). El objetivo de un algoritmo de aprendizaje de máquina en este contexto es encontrar un equilibrio local de Nash28un punto que es un mínimo local del costo de cada jugador con respecto a los parámetros de ese jugador. Con movimientos locales, ningún jugador puede reducir su costo aún más, asumiendo que los parámetros del otro jugador no cambien.
El algoritmo de entrenamiento más común es simplemente utilizar un optimizador basado en gradientes para tomar repetidamente pasos simultáneos en ambos jugadores, minimizando incrementalmente el costo de cada jugador con respecto a los parámetros de ese jugador.
Al final del proceso de entrenamiento, las GAN suelen ser capaces de producir muestras realistas, incluso para conjuntos de datos muy complicados que contienen imágenes de alta resolución. En la figura 5 se muestra un ejemplo.

Figura 5. Esta imagen es una muestra de una GAN progresiva14 representando a una persona que no existe pero que fue «imaginada» por una GAN después de entrenar en fotos de celebridades.
A un alto nivel, una de las razones por las que el marco de la GAN es exitoso puede ser que implica muy poca aproximación. Muchas otras aproximaciones al modelado generativo deben aproximarse a las funciones de densidad intratables. Los GAN no implican ninguna aproximación a su verdadera tarea subyacente. El único error real es el error estadístico (muestreo de una cantidad finita de datos de capacitación en lugar de medir la verdadera distribución generadora de datos subyacente) y el fracaso del algoritmo de aprendizaje para converger exactamente en los parámetros óptimos. Muchas estrategias de modelización generativa introducirían estas fuentes de error y también otras fuentes de error de aproximación, basadas en las cadenas de Markov, la optimización de los límites del costo real en lugar del costo propiamente dicho, etc.
Es difícil dar una orientación mucho más específica con respecto a los detalles de las GAN, porque las GAN son un área de investigación muy activa y la mayoría de los consejos específicos se desactualizan rápidamente. La figura 6 muestra lo rápido que han progresado las capacidades de las GAN en los años desde su introducción.

Figura 6. Una ilustración de los avances en las capacidades de las GAN en el curso de aproximadamente tres años después de la introducción de las GAN. Las GAN se han vuelto rápidamente más capaces, debido a los cambios en los algoritmos de las GAN, las mejoras en los algoritmos de aprendizaje profundo subyacentes y las mejoras en la infraestructura de software y hardware de aprendizaje profundo subyacentes. Este rápido progreso significa que es inviable que en un solo documento se resuman las capacidades más avanzadas de las GAN o cualquier conjunto específico de mejores prácticas; ambas siguen evolucionando con la suficiente rapidez como para que cualquier estudio exhaustivo quede rápidamente obsoleto. Figura reproducida con permiso de Brundage et al.5 Los resultados individuales son de los árbitros. Goodfellow,13 Karras et al.,14 Liu y Tuzel,17 y Radford y otros.27 respectivamente.
Volver al principio
4. Convergencia de Gans
Los resultados teóricos centrales presentados en el documento original de la GAN13 eran eso:
- en el espacio de las funciones de densidad pmodelo y funciones discriminatorias Dsólo hay un equilibrio local de Nash, donde pmodelo = pdatos.
- si fuera posible optimizar directamente sobre tales funciones de densidad, entonces el algoritmo que consiste en optimizar D a la convergencia en el bucle interior, luego haciendo un pequeño paso de gradiente en pmodelo en el bucle exterior, converge en este equilibrio de Nash.
Sin embargo, el modelo teórico de movimientos locales directamente en el espacio de la función de densidad puede no ser muy relevante para los GAN, ya que se entrenan en la práctica: el uso de movimientos locales en parámetro espacio de la generador entre el conjunto de funciones representables por redes neuronales con un número finito de parámetros, con cada parámetro representado con un número finito de bits.
En muchos modelos teóricos diferentes, es interesante estudiar si existe un equilibrio de Nash,2 si existe algún falso equilibrio de Nash,32 si el algoritmo de aprendizaje converge en un equilibrio de Nash,24 y si lo hace, qué tan rápido.21
En muchos casos de interés práctico, estas cuestiones teóricas están abiertas, y los mejores algoritmos de aprendizaje parecen no converger empíricamente. El trabajo teórico para responder a estas preguntas está en curso, así como el trabajo para diseñar mejores costos, modelos y algoritmos de entrenamiento con mejores propiedades de convergencia.
Volver al principio
5. Otros temas de Gan
Este artículo se centra en un resumen de las principales consideraciones de diseño y propiedades algorítmicas de las GAN.
Muchos otros temas de posible interés no pueden ser considerados aquí debido a la consideración del espacio. En este artículo se discutió el uso de los GAN para aproximarse a una distribución p(x) también se han extendido al entorno condicional23,25 donde generan muestras correspondientes a alguna entrada extrayendo muestras de la distribución condicional p(x | y). Las GAN están relacionadas con la coincidencia de momentos16 y un transporte óptimo.1 Una peculiaridad de las GAN que se hace especialmente evidente a través de su conexión con el MMD y el transporte óptimo es que pueden ser utilizadas para entrenar modelos generativos para los cuales pmodelo tiene apoyo sólo en un colector delgado y puede realmente asignar una probabilidad cero a los datos de entrenamiento. Las GAN luchan por generar datos discretos porque el algoritmo de retropropagación necesita propagar los gradientes del discriminador a través de la salida del generador, pero este problema se está resolviendo gradualmente.9 Como la mayoría de los modelos generativos, los GAN pueden ser usados para llenar los huecos en los datos que faltan.34 Las GAN han demostrado ser muy efectivas para aprender a clasificar datos usando muy pocos ejemplos de entrenamiento etiquetados.29 La evaluación del rendimiento de los modelos generativos, incluidos los GAN, es un área de investigación difícil por sí misma.29,31,32,33 Los GAN pueden ser vistos como una forma de que la máquina aprenda su propia función de costo, en lugar de minimizar una función de costo diseñada a mano. Las GAN pueden verse como una forma de supervisar el aprendizaje de la máquina pidiéndole que produzca cualquier salida que el propio algoritmo de aprendizaje de la máquina reconozca como aceptable, en lugar de pedirle que produzca una salida de ejemplo específica. Así pues, las GAN son excelentes para el aprendizaje en situaciones en las que hay muchas respuestas correctas posibles, como la predicción de los muchos futuros posibles que pueden ocurrir en la generación de vídeo.19 Las GAN y los modelos similares a las GAN pueden utilizarse para aprender a transformar los datos de un dominio en datos de otro dominio, incluso sin ningún par de ejemplos etiquetados de esos dominios (por ejemplo, Zhu et al.35). Por ejemplo, después de estudiar una colección de fotos de cebras y una colección de fotos de caballos, los GAN pueden convertir una foto de un caballo en una foto de una cebra.35 Las GAN se han utilizado en la ciencia para simular experimentos que serían costosos de ejecutar incluso en simuladores de software tradicionales.7 Las GAN pueden ser usadas para crear datos falsos para entrenar a otros modelos de aprendizaje de máquinas, ya sea cuando los datos reales serían difíciles de adquirir30 o cuando habría problemas de privacidad asociados a los datos reales.3 Para la adaptación de los dominios se pueden utilizar modelos similares a las GAN, llamados redes de dominio-adversario.12 Las GAN pueden ser utilizadas para una variedad de efectos de medios digitales interactivos donde el objetivo final es producir imágenes convincentes.35 Los GAN pueden incluso utilizarse para resolver problemas de inferencia variacional utilizados en otros enfoques de modelación generativa.20 Los GAN pueden aprender vectores de incrustación útiles y descubrir conceptos como el género de los rostros humanos sin supervisión.27
Volver al principio
6. Conclusión
Los GAN son una especie de modelo generativo basado en la teoría de los juegos. Han tenido un gran éxito práctico en términos de generación de datos realistas, especialmente imágenes. Actualmente todavía es difícil entrenarlos. Para que las GANs se conviertan en una tecnología más confiable, será necesario diseñar modelos, costos o algoritmos de entrenamiento para los cuales sea posible encontrar buenos equilibrios de Nash de manera consistente y rápida.
Volver al principio
Referencias
1. Arjovsky, M., Chintala, S., Bottou, L. Wasserstein gan. arXiv preprint arXiv:1701.07875 (2017).
2. Arora, S., Ge, R., Liang, Y., Ma, T., Zhang, Y. Generalización y equilibrio en las redes de adversarios generativos (gans). arXiv preprint arXiv:1703.00573 (2017).
3. Beaulieu-Jones, B.K., Wu, Z.S., Williams, C., Greene, C.S. Las redes neuronales profundas generativas que preservan la privacidad apoyan el intercambio de datos clínicos. bioRxiv (2017), 159756.
4. Bengio, Y., Thibodeau-Laufer, E., Alain, G., Yosinski, J. Redes estocásticas generativas profundas entrenables por retropropulsión. En ICML’2014 (2014).
5. Brundage, M., Avin, S., Clark, J., Toner, H., Eckersley, P., Garfinkel, B., Dafoe, A., Scharre, P., Zeitzoff, T., Filar, B., Anderson, H., Roff, H., Allen, G.C., Steinhardt, J., Flynn, C., hÉigeartaigh, S.Ó., Beard, S., Belfield, H., Farquhar, S., Lyle, C., Crootof, R., Evans, O., Page, M., Bryson, J., Yampolskiy, R., Amodei, D. El uso malicioso de la inteligencia artificial: Previsión, prevención y mitigación. ArXiv e-prints (Febrero 2018).
6. Danihelka, I., Lakshminarayanan, B., Uria, B., Wierstra, D., Dayan, P. Comparación de la máxima probabilidad y entrenamiento basado en GAN de nvps reales. arXiv preprint arXiv:1705.05263 (2017).
7. de Oliveira, L., Paganini, M., Nachman, B. Learning particle physics by example: location-aware generative adversarial networks for physics synthesis. Computación y software para Big Science 1 1(2017), 4.
8. Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., Fei-Fei, L. ImageNet: Una base de datos de imágenes jerárquicas a gran escala. En CVPR09 (2009).
9. Fedus, W., Goodfellow, I., Dai, A.M. MaskGAN: Mejor generación de texto rellenando el _____. En Conferencia Internacional sobre Representaciones de Aprendizaje (2018).
10. Fedus, W., Rosca, M., Lakshminarayanan, B., Dai, A.M., Mohamed, S., Goodfellow, I. Muchos caminos hacia el equilibrio: Los GAN no necesitan disminuir una divergencia a cada paso. En Conferencia Internacional sobre Representaciones de Aprendizaje (2018).
11. Frey, B.J. Modelos gráficos para el aprendizaje automático y la comunicación digital. MIT Press, Boston, 1998.
12. Ganin, Y., Lempitsky, V. Adaptación de dominio no supervisada por retropropagación. En Conferencia Internacional sobre Aprendizaje Automático (2015), 1180–1189.
13. Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y. Redes de adversarios generativos. Z. Ghahramani, M. Welling, C. Cortes, N.D. Lawrence, K.Q. Weinberger, eds. Avances en los sistemas de procesamiento de información neuronal 27Curran Associates, Inc., Boston, 2014, 2672-2680.
14. Karras, T., Aila, T., Laine, S., Lehtinen, J. Crecimiento progresivo de las GAN para mejorar la calidad, la estabilidad y la variación. CDR, abs/1710.10196 (2017).
15. Kingma, D.P., Welling, M. Auto-codificación de bayes variables. En Actas de la Conferencia Internacional sobre Aprendizaje de Representaciones (ICLR) (2014).
16. Li, Y., Swersky, K., Zemel, R.S. Redes de emparejamiento de momentos generativos. CDRabs/1502.02761 (2015).
17. Liu, M.-Y., Tuzel, O. Acoplamiento de redes generativas adversas. D.D. Lee, M. Sugiyama, U.V. Luxburg, I. Guyon, R. Garnett, eds. Avances en los sistemas de procesamiento de información neuronal 29Curran Associates, Inc., Boston, 2016, 469-477.
18. Lucic, M., Kurach, K., Michalski, M., Gelly, S., Bousquet, O. ¿Son iguales los GAN creados? Un estudio a gran escala. arXiv preprint arXiv:1711.10337 (2017).
19. Mathieu, M., Couprie, C., LeCun, Y. Profunda predicción de video multi-escala más allá del error cuadrado medio. arXiv preprint arXiv:1511.05440 (2015).
20. Mescheder, L., Nowozin, S., Geiger, A. Adversarial variational bayes: Unificando autocodificadores variacionales y redes generativas adversas. arXiv preprint arXiv:1701.04722 (2017).
21. Mescheder, L., Nowozin, S., Geiger, A. Los números de las gans. En Avances en los sistemas de procesamiento de información neuronal (2017), 1823–1833.
22. Metz, L., Poole, B., Pfau, D., Sohl-Dickstein, J. Redes de adversarios generativos desenrollados. arXiv preprint arXiv:1611.02163 (2016).
23. Mirza, M., Osindero, S. Redes de adversarios generativos condicionales. arXiv preprint arXiv:1411.1784 (2014).
24. Nagarajan, V., Kolter, J.Z. La optimización de la GAN de descenso gradual es estable localmente. I. Guyon, U.V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, R. Garnett, eds. Avances en los sistemas de procesamiento de información neuronal 30Curran Associates, Inc., Boston, 2017, 5585-5595.
25. Odena, A., Olah, C., Shlens, J. Síntesis de imagen condicional con gans clasificadoras auxiliares. arXiv preprint arXiv:1610.09585 (2016).
26. Oord, A. v. d., Li, Y., Babuschkin, I., Simonyan, K., Vinyals, O., Kavukcuoglu, K., Driessche, G. v. d., Lockhart, E., Cobo, L.C., Stimberg, F., et al. Wavenet paralela: Síntesis rápida de alta fidelidad del habla. arXiv preprint arXiv:1711.10433 (2017).
27. Radford, A., Metz, L., Chintala, S. Aprendizaje de representación no supervisado con redes generativas adversas convolutivas profundas. arXiv preprint arXiv:1511.06434 (2015).
28. Ratliff, L.J., Burden, y S.A., Sastry, S.S. Caracterización y cálculo de los equilibrios locales de nash en juegos continuos. En Comunicación, Control y Computación (Allerton), 2013 51st Conferencia anual de Allerton sobre. IEEE, (2013), 917-924.
29. Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X. Técnicas mejoradas para el entrenamiento de gansos. En Avances en los sistemas de procesamiento de información neuronal (2016), 2234–2242.
30. 30. Shrivastava, A., Pfister, T., Tuzel, O., Susskind, J., Wang, W., Webb, R. Aprendiendo de imágenes simuladas y no supervisadas a través de la formación de adversarios.
31. Theis, L., van den Oord, A., Bethge, M. Una nota sobre la evaluación de los modelos generativos. arXiv:1511.01844 (Nov 2015).
32. Unterthiner, T., Nessler, B., Klambauer, G., Heusel, M., Ramsauer, H., Hochreiter, S. Coulomb GANs: Equilibrio óptimo de Nash a través de campos potenciales. arXiv preprint arXiv:1708.08819 (2017).
33. Wu, Y., Burda, Y., Salakhutdinov, R., Grosse, R. Sobre el análisis cuantitativo de los modelos generativos basados en decodificadores. arXiv preprint arXiv:1611.04273 (2016).
34. Yeh, R., Chen, C., Lim, T.Y., Hasegawa-Johnson, M., Do, M.N. Pintura de imágenes semánticas con pérdidas perceptivas y contextuales. arXiv preprint arXiv:1607.07539 (2016).
35. Zhu, J.-Y., Park, T., Isola, P., Efros, A.A. Traducción de imagen a imagen no emparejada usando redes de adversarios consistentes en ciclos. arXiv preprint arXiv:1703.10593 (2017).
Volver al principio
Volver al principio
Notas a pie de página
La versión original de este documento se titula «Generative Adversarial Networks» y fue publicado en Avances en los sistemas de procesamiento de información neuronal 27 (NIPS 2014).
Presentado definitivamente el 5/9/2018.
Los derechos de autor pertenecen a los autores/propietarios. Derechos de publicación licenciados a ACM.
Solicite permiso para publicar en permissions@acm.org
La Biblioteca Digital es publicada por la Asociación de Maquinaria de Computación. Derechos de autor © 2020 ACM, Inc.
No se han encontrado entradas