En este post veremos cómo implementar un pipeline de procesamiento por lotes moviendo datos desde el almacenamiento en la nube de Google a Google Big Query usando el flujo de datos en la nube.
Cloud Dataflow es un servicio de procesamiento de datos totalmente gestionado en la plataforma de Google Cloud. Apache Beam SDK nos permite desarrollar tanto BATCH como STREAM de procesamiento de tuberías. Programamos nuestro flujo ETL/ELT y Beam nos permite ejecutarlos en Cloud Dataflow usando Dataflow Runner.
En este post, codificaremos la tubería en Apache Bean y la ejecutaremos en Google Data Flow.
El código de este puesto se puede encontrar aquí.
Dataflow vs Apache Beam
La mayoría de las veces, la gente se confunde en la comprensión de lo que es el Rayo Apache y lo que es el Flujo de Datos en la Nube. Para entender cómo se escribe una tubería, es muy importante entender cuál es la diferencia entre los dos.
Apache Beam es un marco de trabajo de código abierto para crear tuberías de procesamiento de datos (tanto de BATCH como de STREAM). La tubería es luego ejecutada por uno de los back-ends de procesamiento distribuido soportados por Beam, que incluyen Apache Apex, Apache Flink, Apache Spark, y Google Cloud Dataflow.
¿Interesado en entrar en Big Data? Echa un vistazo a nuestro curso de Desarrollador Hadoop en el Mundo Real para conocer interesantes casos de uso y proyectos del mundo real como el que estás leyendo.
Beneficios del flujo de datos en la nube
- Autoescalado horizontal de los nodos trabajadores
- Servicio totalmente gestionado
- Vigilar el oleoducto en cualquier momento de su ejecución
- Procesamiento fiable y coherente
¿Qué es el almacenamiento en la nube de Google?
Google Cloud Storage es un servicio para almacenar tus objetos. Un objeto es una pieza inmutable de datos que consiste en un archivo de cualquier formato. Los objetos se almacenan en contenedores llamados cubos. Todos los cubos están asociados a un proyecto. Puedes comparar Cubos de GCS con Cubos de S3 del Amazonas.
¿Qué es una gran pregunta?
Big Query es una solución de almacenamiento de datos altamente escalable y rentable en la plataforma de la nube de Google.
Beneficios de la gran consulta
- Analizar los petabytes de datos utilizando consultas ANSI SQL.
- Acceder a los datos y compartir conocimientos con facilidad
- Una plataforma más segura que se adapta a sus necesidades
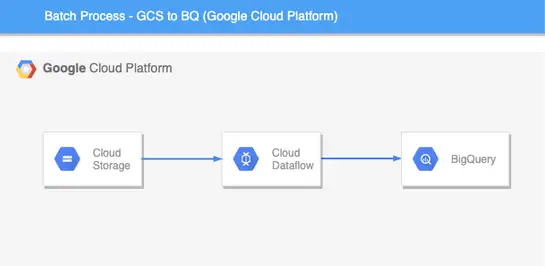
Procesamiento por lotes desde el almacenamiento en la nube de Google a Big Query
Diseño de arquitectura
Así es como se verá el flujo de la tubería. Aquí, la fuente es el cubo de almacenamiento de Google Cloud y el fregadero es Big Query. Big Query es un almacén de datos que se ofrece en la plataforma de Google Cloud.
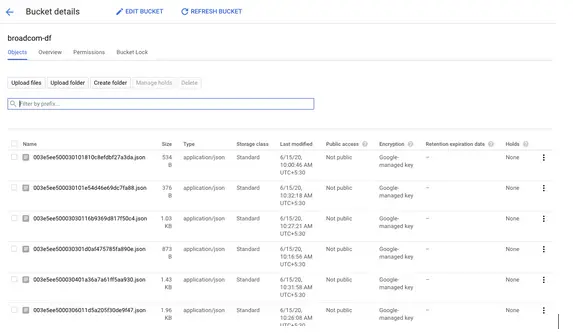
Como pueden ver en la captura de pantalla anterior, así es como se verán los datos en el cubo de almacenamiento de Google Cloud. Tenemos datos en forma de archivos JSON que empujaremos en la Gran Consulta.
Iniciar y configurar la tubería
El primer paso es configurar la configuración del oleoducto. Tenemos que establecer qué tipo de máquina usará el oleoducto, en qué región disponible, el oleoducto se ejecutará y así sucesivamente.
Podemos programar nuestro oleoducto en JAVA o Python. Primero, tenemos que configurar el objeto Dataflow Pipeline Options donde definiremos la configuración de nuestro pipeline.
Hemos usado Direct Runner para ejecutar y probar el oleoducto localmente.
|
opciones.setRunner(DirectRunner.clase); |
Una vez que lo probemos localmente, podremos reemplazar a Direct Runner con Dataflow Runner. Eso es todo lo que necesitamos para desplegar nuestro oleoducto en la nube de flujo de datos.
|
opciones.setRunner(DataflowRunner.clase); |
Aparte de esto, también necesitamos pasar otras configuraciones al oleoducto como ID del proyecto, número máximo de nodos de trabajadores, ubicación temporal, ubicación de la puesta en escena, tipo de máquina de trabajadores, región donde nuestro oleoducto será desplegado, etc.
Crear una tubería
Después de pasar todas las configuraciones al objeto de las Opciones de Tubería de Flujo de Datos, entonces crearemos nuestro objeto de Tubería.
Consulte el siguiente fragmento para verlo más de cerca.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
público clase StorageToBQBatchPipeline { público estática vacío principal(Cuerda[[] args) { /* * Inicializar las configuraciones del oleoducto */ DataflowPipelineOptions opciones = PipelineOptionsFactory .como(DataflowPipelineOptions.clase); opciones.setRunner(DirectRunner.clase); opciones.setProject(«»); opciones.setStreaming(verdadero); opciones.setTempLocation(«»); opciones.setStagingLocation(«»); opciones.setRegión(«»); opciones.setMaxNumWorkers(1); opciones.setWorkerMachineType(«n1-estándar-1»); Oleoducto tubería = Oleoducto.crear(opciones); |
Procesamiento de datos de la fuente (Google Cloud Storage)
Aquí, la fuente de lectura de los datos es Google Cloud Storage Buckets, Una vez que creamos el objeto pipeline.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
/* * Leer archivos de los cubos de GCS */ PCollection datos = tubería .aplicar(FileIO.partido().filepattern(«gs://dump_*»)) .aplicar(FileIO.readMatches()); /* * Crear Tuple Tag para procesar los registros pasados así como los fallidos mientras se analizan en las funciones ParDo */ final TupleTag<KV<Cuerda, Cuerda>> mapSuccessTag = nuevo TupleTag<KV<Cuerda, Cuerda>>() { privado estática final largo serialVersionUID = 1L; }; final TupleTag<KV<Cuerda, Cuerda>> mapFailedTag = nuevo TupleTag<KV<Cuerda, Cuerda>>() { privado estática final largo serialVersionUID = 1L; }; PCollectionTuple mapTupleObj = datos.aplicar(ParDo.de(nuevo MapTransformation(mapSuccessTag, mapFailedTag)) .conOutputTags(mapSuccessTag, TupleTagList.de(mapFailedTag))); PCollection<KV<Cuerda, Cuerda>> mapa = mapTupleObj.consigue(mapSuccessTag).setCoder(KvCoder.de(StringUtf8Coder.de(), StringUtf8Coder.de())); |
|
FileIO.partido().filepattern(«gs://dump_*») |
FileIO es el conector que está incorporado en el Apache Beam SDK que te permite leer archivos de GCS.
Hemos utilizado las funciones ParDo para convertir primero los objetos File IO en Key Value pair Objects como se puede ver a continuación.
Usando etiquetas tuples, nos aseguraremos de procesar sólo los resultados correctos al siguiente paso. Los registros fallidos se procesarán por separado usando etiquetas tuple fallidas si nos enfrentamos a algún tipo de excepción durante el procesamiento de los registros.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
/* * Convertir el archivo en un objeto KV */ privado estática clase MapTransformation se extiende DoFn<FileIO.ReadableFile,KV<Cuerda, Cuerda>> { estática final largo serialVersionUID = 1L; TupleTag<KV<Cuerda, Cuerda>> successTag; TupleTag<KV<Cuerda, Cuerda>> failTag; público MapTransformation(TupleTag<KV<Cuerda, Cuerda>> successTag, TupleTag<KV<Cuerda, Cuerda>> failTag) { este.successTag = successTag; este.failTag = failTag; } @ProcessElement público vacío processElement(ProcessContext c) { FileIO.ReadableFile f = c.elemento(); Cuerda fileName = f.getMetadata().resourceId().toString(); Cuerda fileData = nulo; pruebe { fileData = f.leer completamente ASUTF8String(); c.salida(successTag,KV.de(fileName, fileData)); } Atrapa a (Excepción e) { c.salida(failTag, KV.de(e.getMessage(), fileName)); } } } |
Empujando los datos al destino (Gran consulta de Google)
En este paso, limpiaremos cada par de Valor Clave y podremos hacer cualquier tipo de transformación según el caso de uso o requerimiento. En este caso, estamos empujando directamente los registros a la Gran Consulta.
¿Interesado en entrar en Big Data? Revisa nuestro curso de Spark Developer In Real World para conocer interesantes casos de uso y proyectos del mundo real como el que estás leyendo.
Antes de empujar los registros en BQ, tendremos que convertir primero los pares de valores clave en objetos de la fila de la tabla de la gran consulta.
Vea el fragmento de abajo para eso.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
/* * Convertir KV en Table Row */ privado estática clase TableRowTransformation se extiende DoFn<KV<Cuerda, Cuerda>, TableRow> { estática final largo serialVersionUID = 1L; TupleTag successTag; TupleTag failTag; público TableRowTransformation(TupleTag successTag, TupleTag failTag) { este.successTag = successTag; este.failTag = failTag; } @ProcessElement público vacío processElement(ProcessContext c) { pruebe { KV<Cuerda, Cuerda> kvObj = c.elemento(); TableRow tableRow = nuevo TableRow(); tableRow.set(kvObj.getKey(), kvObj.getValue()); c.salida(successTag,tableRow); } Atrapa a (Excepción e) { TableRow tableRow = nuevo TableRow(); c.salida(failTag, tableRow); } } } |
Una vez que convertimos los objetos en objetos de la fila de la tabla, usando el conector incorporado Big Query en Apache Beam SDK, puedes introducir los registros en la tabla.
Como podemos ver, tenemos un montón de opciones en el conector BQ. Tenemos que pasar el nombre de la tabla, donde se guardarán los registros.
|
/* * Empujar los registros a BQ. */ rowObj.aplicar(BigQueryIO.writeTableRows() .a(«options.getOutputTable()») .ignoreUnknownValues() .conWriteDisposition(BigQueryIO.Escriba.WriteDisposition.WRITE_APPEND) .conCreateDisposition(BigQueryIO.Escriba.CreateDisposition.CREATE_IF_NEED));
tubería.dirigir().waitUntilFinish(); |
Una vez que el oleoducto se despliega, podemos ver los detalles del monitoreo en el lado derecho. Como pueden ver en las imágenes siguientes, la configuración que hemos pasado en el oleoducto es visible allí.
Como Dataflow es una oferta gestionada por la plataforma de Google Cloud, podemos definir el algoritmo de auto-escalado así como la tubería.
La sección de monitoreo nos permitirá saber cuántas máquinas de trabajo están actualmente en uso, cuál será la utilización de la CPU del oleoducto y así sucesivamente.