
El pronóstico de las series cronológicas puede ser difícil, ya que hay muchos métodos diferentes que se pueden utilizar y muchos hiperparámetros diferentes para cada método.
La biblioteca del Profeta es una biblioteca de código abierto diseñada para hacer pronósticos de conjuntos de datos de series temporales univariadas. Es fácil de usar y está diseñada para encontrar automáticamente un buen conjunto de hiperparámetros para el modelo en un esfuerzo por hacer pronósticos hábiles para datos con tendencias y estructura estacional por defecto.
En este tutorial, descubrirá cómo utilizar la biblioteca de Facebook Profeta para la previsión de series temporales.
Después de completar este tutorial, lo sabrás:
- Prophet es una biblioteca de código abierto desarrollada por Facebook y diseñada para el pronóstico automático de datos de series de tiempo univariadas.
- Cómo encajar los modelos de Prophet y usarlos para hacer pronósticos dentro y fuera de la muestra.
- Cómo evaluar un modelo de Profeta en un conjunto de datos de retención.
Empecemos.

Previsión de la serie de tiempo con el profeta en Python
Foto de Rinaldo Wurglitsch, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en tres partes; son:
- Biblioteca de Previsión de Profeta
- Conjunto de datos de ventas de coches
- Cargar y resumir el conjunto de datos
- Conjunto de datos de carga y de parcela
- Previsión de ventas de coches con Prophet
- Modelo de Profeta en forma
- Haga un pronóstico en la muestra
- Haga un pronóstico fuera de la muestra
- Modelo de previsión de evaluación manual
Biblioteca de Previsión de Profeta
Profeta, o «Profeta de Facebookes una biblioteca de código abierto para el pronóstico de series temporales univariadas (una variable) desarrollada por Facebook.
Prophet implementa lo que ellos llaman un modelo aditivo de predicción de series de tiempo, y la implementación apoya las tendencias, la estacionalidad y los días festivos.
Implementa un procedimiento para pronosticar datos de series temporales basado en un modelo aditivo en el que las tendencias no lineales se ajustan a la estacionalidad anual, semanal y diaria, además de los efectos de las vacaciones
– Paquete ‘profeta’, 2019.
Está diseñado para ser fácil y completamente automático, por ejemplo, apuntarlo a una serie temporal y obtener un pronóstico. Como tal, está destinado a uso interno de la empresa, como la previsión de ventas, capacidad, etc.
Para una gran visión general de Prophet y sus capacidades, ver el post:
La biblioteca proporciona dos interfaces, incluyendo R y Python. Nos centraremos en la interfaz de Python en este tutorial.
El primer paso es instalar la biblioteca del Profeta usando Pip, de la siguiente manera:
|
sudo pip instalar fbprophet |
A continuación, podemos confirmar que la biblioteca se instaló correctamente.
Para ello, podemos importar la biblioteca e imprimir el número de versión en Python. El ejemplo completo se muestra a continuación.
|
# Verificar la versión del profeta importación fbprophet # imprimir el número de versión imprimir(‘Profeta %s’ % fbprophet.La versión…) |
Ejecutando el ejemplo se imprime la versión instalada de Prophet.
Deberías tener la misma versión o una más alta.
Ahora que tenemos Prophet instalado, seleccionemos un conjunto de datos que podamos usar para explorar usando la biblioteca.
Conjunto de datos de ventas de coches
Usaremos el conjunto de datos mensuales de ventas de coches.
Se trata de un conjunto de datos estándar de series temporales univariadas que contiene tanto una tendencia como una estacionalidad. El conjunto de datos tiene 108 meses de datos y un pronóstico de persistencia ingenuo puede lograr un error absoluto medio de alrededor de 3.235 ventas, proporcionando un límite de error inferior.
No hay necesidad de descargar el conjunto de datos ya que lo descargaremos automáticamente como parte de cada ejemplo.
Cargar y resumir el conjunto de datos
Primero, carguemos y resumamos el conjunto de datos.
Prophet requiere que los datos estén en los DataFrames de Pandas. Por lo tanto, cargaremos y resumiremos los datos usando Pandas.
Podemos cargar los datos directamente desde la URL llamando a la función de Pandas read_csv(), luego resumir la forma (número de filas y columnas) de los datos y ver las primeras filas de datos.
El ejemplo completo figura a continuación.
|
# Cargar el conjunto de datos de ventas de coches de pandas importación lea_csv # Cargar datos camino = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv’ df = read_csv(camino, encabezado=0) # Resumir la forma imprimir(df.forma) # mostrar las primeras filas imprimir(df.cabeza()) |
En el ejemplo se informa primero del número de filas y columnas y luego se enumeran las cinco primeras filas de datos.
Podemos ver que, como esperábamos, hay 108 meses de datos y dos columnas. La primera columna es la fecha y la segunda es el número de ventas.
Obsérvese que la primera columna de la salida es un índice de filas y no forma parte del conjunto de datos, sino que es una útil herramienta que Pandas utiliza para ordenar las filas.
|
(108, 2) Ventas del mes 0 1960-01 6550 1 1960-02 8728 2 1960-03 12026 3 1960-04 14395 4 1960-05 14587 |
Conjunto de datos de carga y de parcela
Un conjunto de datos de series temporales no tiene sentido para nosotros hasta que lo trazamos.
Trazar una serie temporal nos ayuda a ver si hay una tendencia, un ciclo estacional, valores atípicos y más. Nos da una idea de los datos.
Podemos trazar los datos fácilmente en Pandas llamando al plot() en el DataFrame.
El ejemplo completo figura a continuación.
|
# Cargar y trazar el conjunto de datos de ventas de coches de pandas importación read_csv de matplotlib importación pyplot # Cargar datos camino = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv’ df = read_csv(camino, encabezado=0) # trazar la serie de tiempo df.parcela() pyplot.mostrar() |
Ejecutando el ejemplo se crea una trama de la serie de tiempo.
Podemos ver claramente la tendencia de las ventas a lo largo del tiempo y un patrón estacional mensual de las ventas. Estos son patrones que esperamos que el modelo de pronóstico tenga en cuenta.
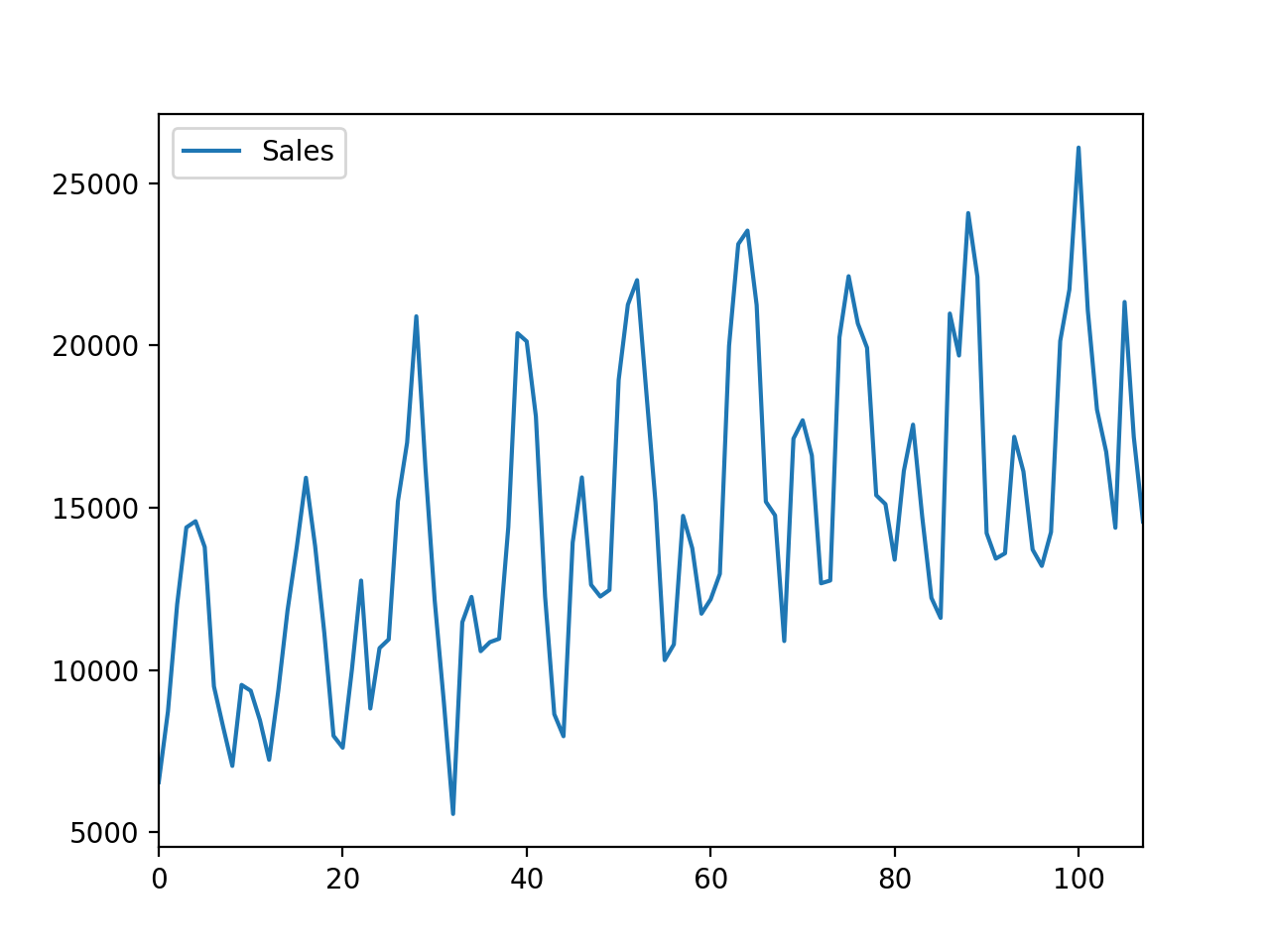
Parcela de la línea de datos de ventas de coches
Ahora que estamos familiarizados con el conjunto de datos, exploremos cómo podemos usar la biblioteca del Profeta para hacer pronósticos.
Previsión de ventas de coches con Prophet
En esta sección, exploraremos el uso del Profeta para pronosticar el conjunto de datos de las ventas de coches.
Empecemos por ajustar un modelo en el conjunto de datos
Modelo de Profeta en forma
Para usar a Prophet para hacer pronósticos, primero, un Profeta. se define y configura el objeto, luego se ajusta al conjunto de datos llamando al fit() y pasar los datos.
El Profeta. El objeto toma argumentos para configurar el tipo de modelo que desea, como el tipo de crecimiento, el tipo de estacionalidad, y más. Por defecto, el modelo trabajará duro para calcular casi todo automáticamente.
El fit() La función toma una DataFrame de datos de series de tiempo. El DataFrame debe tener un formato específico. La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre de »La primera columna debe tener el nombre deds…y contienen las fechas y horas. La segunda columna debe tener el nombrey…y contienen las observaciones.
Esto significa que cambiamos los nombres de las columnas en el conjunto de datos. También requiere que la primera columna se convierta en objetos de fecha y hora, si no lo son ya (por ejemplo, esto puede ser bajado como parte de la carga del conjunto de datos con los argumentos correctos para read_csv).
Por ejemplo, podemos modificar nuestro conjunto de datos de ventas de coches cargados para tener esta estructura esperada, de la siguiente manera:
|
... # Preparar los nombres de las columnas esperadas df.columnas = [[«ds, ‘y’] df[[«ds]= hasta_la_fecha(df[[«ds]) |
El ejemplo completo de la adaptación de un modelo de Profeta en el conjunto de datos de ventas de coches se enumera a continuación.
|
# Modelo de profeta encajado en el conjunto de datos de ventas de coches de pandas importación read_csv de pandas importación hasta_la_fecha de fbprophet importación Profeta # Cargar datos camino = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv’ df = read_csv(camino, encabezado=0) # Preparar los nombres de las columnas esperadas df.columnas = [[«ds, ‘y’] df[[«ds]= hasta_la_fecha(df[[«ds]) # Definir el modelo modelo = Profeta() # Encaja con el modelo modelo.encajar(df) |
Ejecutando el ejemplo se carga el conjunto de datos, se prepara el DataFrame en el formato esperado y se ajusta a un modelo de Profeta.
De forma predeterminada, la biblioteca proporciona una gran cantidad de salida verbosa durante el proceso de ajuste. Creo que es una mala idea en general ya que entrena a los desarrolladores para ignorar la salida.
No obstante, el resultado resume lo que ocurrió durante el proceso de ajuste del modelo, específicamente los procesos de optimización que se llevaron a cabo.
|
INFO:fbprophet:Desactivando la estacionalidad semanal. Corre profeta con weekly_seasonality=True para anular esto. INFO:fbprophet:Desactivando la estacionalidad diaria. Corre profeta con daily_seasonality=True para anular esto. Probabilidad conjunta logarítmica inicial = -4,39613 Iter log prob ||||||||| alfa alfa0 # evals Notas 99 270.121 0.00413718 75.7289 1 1 120 Iter log prob ||||||||| alfa alfa0 # evals Notas 179 270.265 0.00019681 84.1622 2.169e-06 0.001 273 LS fallado, restablecimiento de Hessian 199 270.283 1.38947e-05 87.8642 0.3402 1 299 Iter log prob ||||||||| alfa alfa0 # evals Notas 240 270.296 1.6343e-05 89.9117 1.953e-07 0.001 381 LS fallado, restablecimiento de Hessian 299 270.3 4.73573e-08 74.9719 0.3914 1 455 Iter log prob ||||||||| alfa alfa0 # evals Notas 300 270.3 8.25604e-09 74.4478 0.3522 0.3522 456 La optimización terminó normalmente: Convergencia detectada: el cambio absoluto del parámetro estaba por debajo de la tolerancia |
No reproduciré esta salida en las secciones siguientes cuando encajemos el modelo.
A continuación, hagamos un pronóstico.
Haga un pronóstico en la muestra
Puede ser útil hacer un pronóstico sobre los datos históricos.
Es decir, podemos hacer un pronóstico sobre los datos utilizados como entrada para entrenar el modelo. Idealmente, el modelo ha visto los datos antes y haría una predicción perfecta.
Sin embargo, no es así, ya que el modelo trata de generalizar en todos los casos en los datos.
Esto se llama hacer un pronóstico en la muestra (en la muestra del juego de entrenamiento) y revisar los resultados puede dar una idea de lo bueno que es el modelo. Es decir, lo bien que aprendió los datos de entrenamiento.
Se hace un pronóstico llamando al predecir() y pasar una función DataFrame que contiene una columna llamada ‘dsy filas con fechas y horas para todos los intervalos a predecir.
Hay muchas maneras de crear esto…Previsión” DataFrame. En este caso, haremos un bucle sobre un año de fechas, por ejemplo, los últimos 12 meses en el conjunto de datos, y crearemos una cadena para cada mes. Luego convertiremos la lista de fechas en un DataFrame y convertir los valores de la cadena en objetos de fecha y hora.
|
... # Definir el período para el que queremos una predicción futuro = lista() para i en rango(1, 13): fecha = ‘1968-%02d’ % i futuro.anexar([[fecha]) futuro = DataFrame(futuro) futuro.columnas = [[«ds] futuro[[«ds]= hasta_la_fecha(futuro[[«ds]) |
Este DataFrame puede entonces proporcionarse a la predecir() para calcular un pronóstico.
El resultado de la función predict() es una DataFrame que contiene muchas columnas. Tal vez las columnas más importantes son la fecha y la hora de la previsión (‘ds«), el valor pronosticado (‘yhaty los límites inferior y superior del valor predicho (‘yhat_lowery…yhat_upper…que proporcionan la incertidumbre del pronóstico.
Por ejemplo, podemos imprimir las primeras predicciones de la siguiente manera:
|
... # resumir el pronóstico imprimir(Previsión[[[[«ds, «yhat, ‘yhat_lower’, ‘yhat_upper’]].cabeza()) |
Prophet también proporciona una herramienta incorporada para visualizar la predicción en el contexto del conjunto de datos de entrenamiento.
Esto puede lograrse llamando al plot() función en el modelo y pasándole un resultado DataFrame. Creará un gráfico del conjunto de datos de entrenamiento y superpondrá la predicción con los límites superior e inferior de las fechas de pronóstico.
|
... imprimir(Previsión[[[[«ds, «yhat, ‘yhat_lower’, ‘yhat_upper’]].cabeza()) # Previsión de la trama modelo.parcela(Previsión) pyplot.mostrar() |
A continuación se presenta un ejemplo completo de cómo hacer una previsión dentro de la muestra.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# Hacer un pronóstico de la muestra de pandas importación read_csv de pandas importación hasta_la_fecha de pandas importación DataFrame de fbprophet importación Profeta de matplotlib importación pyplot # Cargar datos camino = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv’ df = read_csv(camino, encabezado=0) # Preparar los nombres de las columnas esperadas df.columnas = [[«ds, ‘y’] df[[«ds]= hasta_la_fecha(df[[«ds]) # Definir el modelo modelo = Profeta() # Encaja con el modelo modelo.encajar(df) # Definir el período para el que queremos una predicción futuro = lista() para i en rango(1, 13): fecha = ‘1968-%02d’ % i futuro.anexar([[fecha]) futuro = DataFrame(futuro) futuro.columnas = [[«ds] futuro[[«ds]= hasta_la_fecha(futuro[[«ds]) # Usar el modelo para hacer un pronóstico Previsión = modelo.predecir(futuro) # resumir el pronóstico imprimir(Previsión[[[[«ds, «yhat, ‘yhat_lower’, ‘yhat_upper’]].cabeza()) # Previsión de la trama modelo.parcela(Previsión) pyplot.mostrar() |
Ejecutando el ejemplo se pronostican los últimos 12 meses del conjunto de datos.
Los primeros cinco meses de la predicción se reportan y podemos ver que los valores no son muy diferentes de los valores reales de venta en el conjunto de datos.
|
ds yhat yhat_lower yhat_upper 0 1968-01-01 14364.866157 12816.266184 15956.555409 1 1968-02-01 14940.687225 13299.473640 16463.811658 2 1968-03-01 20858.282598 19439.403787 22345.747821 3 1968-04-01 22893.610396 21417.399440 24454.642588 4 1968-05-01 24212.079727 22667.146433 25816.191457 |
A continuación, se crea una trama. Podemos ver que los datos de entrenamiento se representan como puntos negros y el pronóstico es una línea azul con límites superiores e inferiores en un área sombreada en azul.
Podemos ver que los 12 meses pronosticados coinciden con las observaciones reales, especialmente cuando se tienen en cuenta los límites.
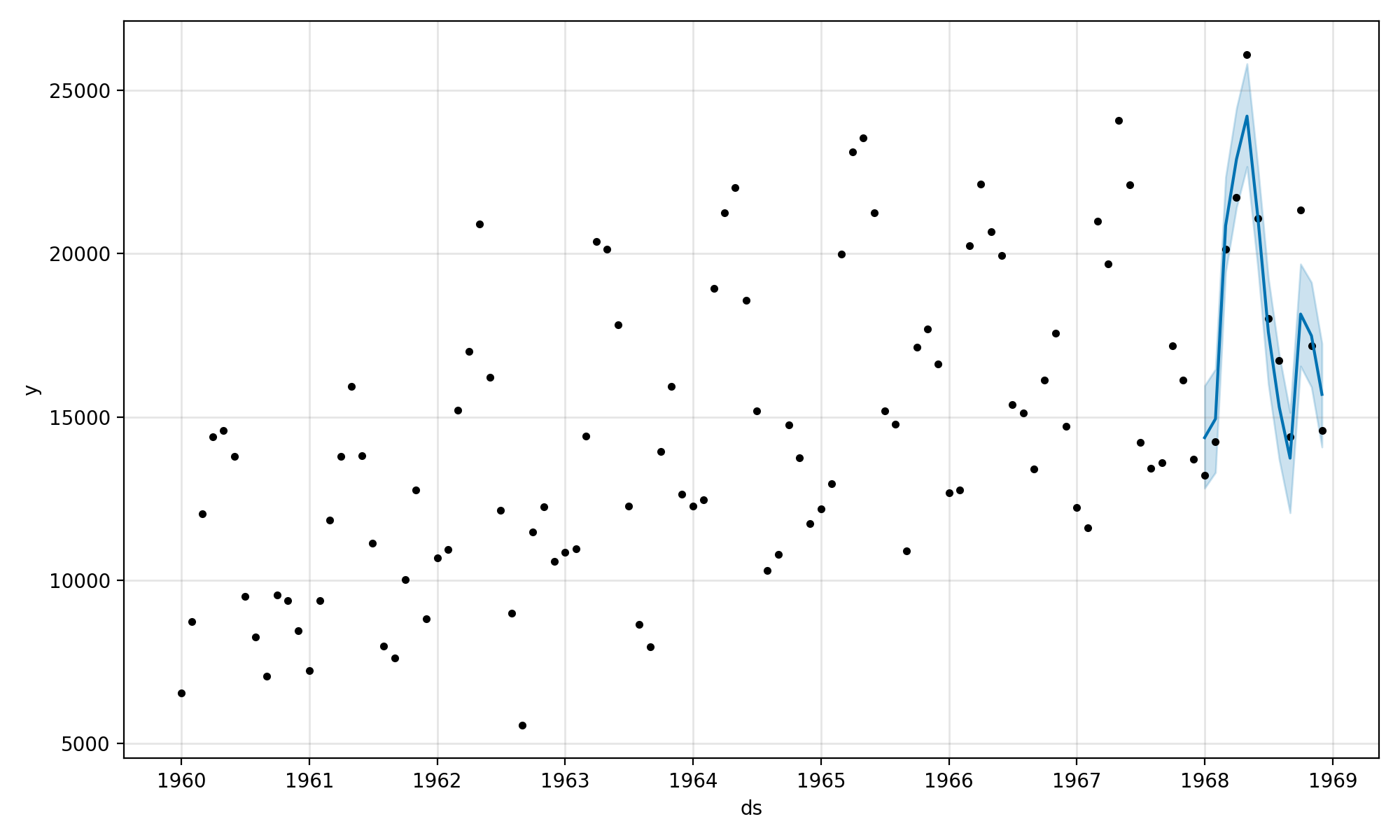
Gráfica de series de tiempo y pronóstico en la muestra con el profeta
Haga un pronóstico fuera de la muestra
En la práctica, realmente queremos un modelo de pronóstico para hacer una predicción más allá de los datos de entrenamiento.
Esto se llama un pronóstico fuera de muestra.
Podemos lograrlo de la misma manera que una previsión dentro de la muestra y simplemente especificar un período de previsión diferente.
En este caso, un período más allá del final del conjunto de datos de entrenamiento, a partir de 1969-01.
|
... # Definir el período para el que queremos una predicción futuro = lista() para i en rango(1, 13): fecha = ‘1969-%02d’ % i futuro.anexar([[fecha]) futuro = DataFrame(futuro) futuro.columnas = [[«ds] futuro[[«ds]= hasta_la_fecha(futuro[[«ds]) |
A continuación se muestra el ejemplo completo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# hacer un pronóstico fuera de muestra de pandas importación read_csv de pandas importación hasta_la_fecha de pandas importación DataFrame de fbprophet importación Profeta de matplotlib importación pyplot # Cargar datos camino = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv’ df = read_csv(camino, encabezado=0) # Preparar los nombres de las columnas esperadas df.columnas = [[«ds, ‘y’] df[[«ds]= hasta_la_fecha(df[[«ds]) # Definir el modelo modelo = Profeta() # Encaja con el modelo modelo.encajar(df) # Definir el período para el que queremos una predicción futuro = lista() para i en rango(1, 13): fecha = ‘1969-%02d’ % i futuro.anexar([[fecha]) futuro = DataFrame(futuro) futuro.columnas = [[«ds] futuro[[«ds]= hasta_la_fecha(futuro[[«ds]) # Usar el modelo para hacer un pronóstico Previsión = modelo.predecir(futuro) # resumir el pronóstico imprimir(Previsión[[[[«ds, «yhat, ‘yhat_lower’, ‘yhat_upper’]].cabeza()) # Previsión de la trama modelo.parcela(Previsión) pyplot.mostrar() |
Ejecutando el ejemplo se hace un pronóstico fuera de muestra para los datos de ventas de automóviles.
Las primeras cinco filas del pronóstico están impresas, aunque es difícil tener una idea de si son sensatas o no.
|
ds yhat yhat_lower yhat_upper 0 1969-01-01 15406.401318 13751.534121 16789.969780 1 1969-02-01 16165.737458 14486.887740 17634.953132 2 1969-03-01 21384.120631 19738.950363 22926.857539 3 1969-04-01 23512.464086 21939.204670 25105.341478 4 1969-05-01 25026.039276 23544.081762 26718.820580 |
Se crea una trama para ayudarnos a evaluar la predicción en el contexto de los datos de entrenamiento.
El nuevo pronóstico de un año parece sensato, al menos a simple vista.
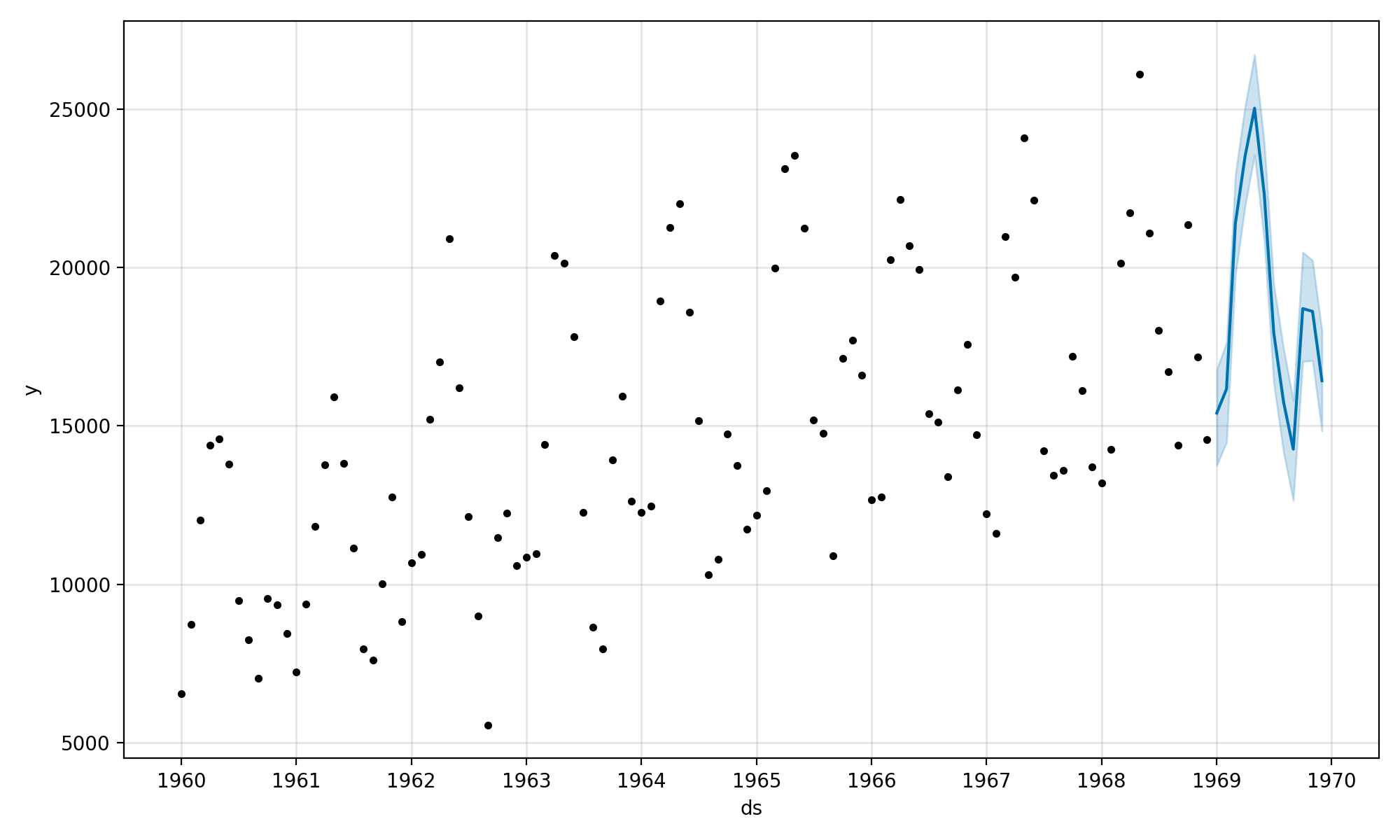
Gráfica de series de tiempo y pronóstico fuera de muestra con el profeta
Modelo de previsión de evaluación manual
Es fundamental desarrollar una estimación objetiva del rendimiento de un modelo de previsión.
Esto puede lograrse reteniendo algunos datos del modelo, como los últimos 12 meses. Luego, ajustando el modelo a la primera porción de los datos, usándolo para hacer predicciones sobre la porción retenida, y calculando una medida de error, como el error absoluto medio a través de las predicciones. Por ejemplo, una predicción simulada fuera de la muestra.
La puntuación da una estimación de lo bien que podríamos esperar que el modelo funcionara en promedio al hacer un pronóstico fuera de la muestra.
Podemos hacer esto con los datos de las muestras creando un nuevo DataFrame para el entrenamiento con los últimos 12 meses quitados.
|
... # Crear un conjunto de datos de prueba, eliminar los últimos 12 meses tren = df.dejar caer(df.índice[[–12:]) imprimir(tren.cola()) |
Entonces se puede hacer un pronóstico sobre los últimos 12 meses de fecha-hora.
Podemos entonces recuperar los valores de pronóstico y los valores esperados del conjunto de datos original y calcular una métrica de error absoluto medio utilizando la biblioteca scikit-learn.
|
... # Calcular el MAE entre los valores esperados y los previstos para diciembre y_verdad = df[[‘y’][[–12:].valores y_pred = Previsión[[«yhat].valores mae = error_absoluto_medio(y_verdad, y_pred) imprimir(MAE: %.3f % mae) |
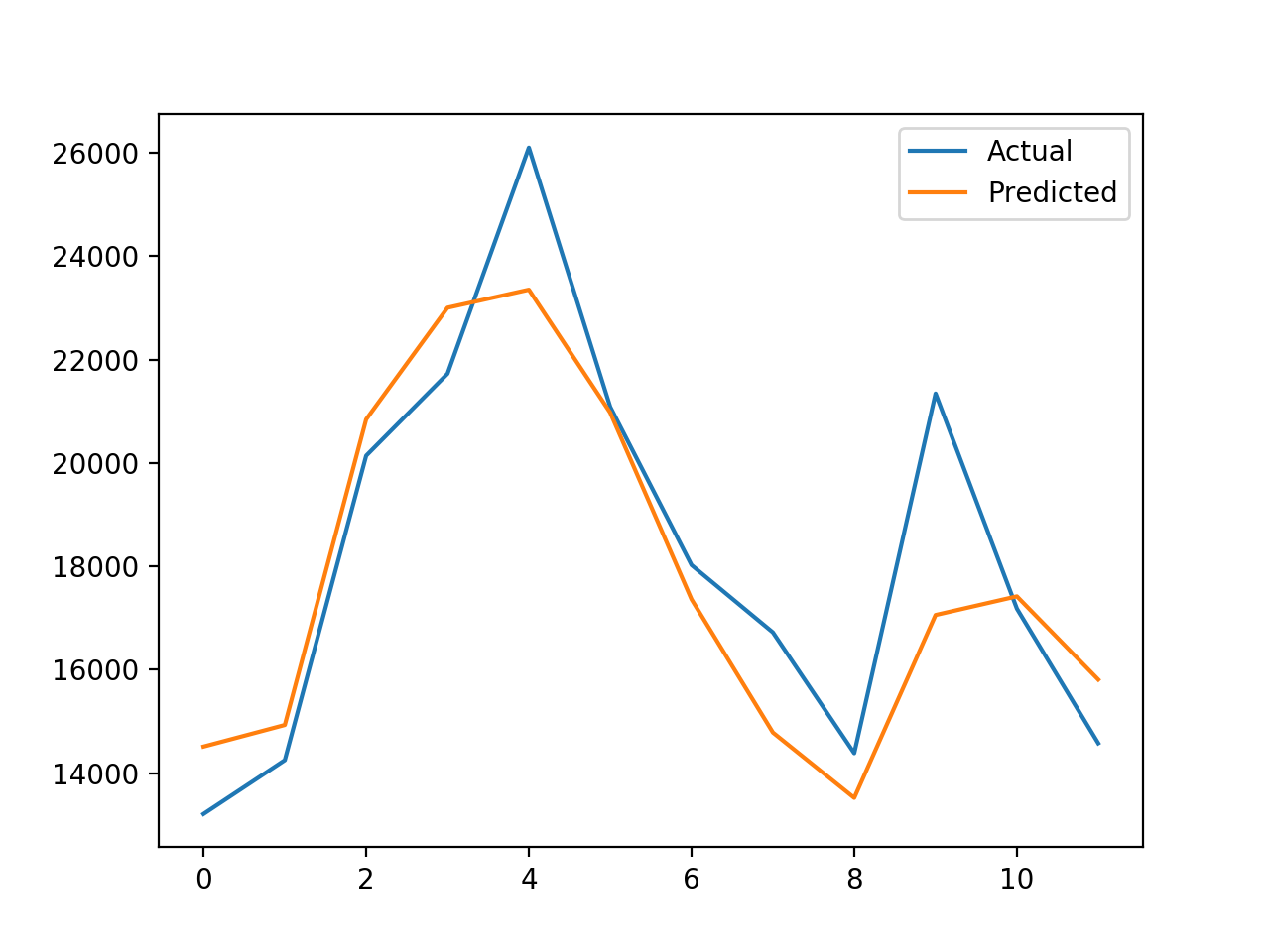
También puede ser útil trazar los valores esperados frente a los pronosticados para ver cómo la predicción fuera de la muestra coincide con los valores conocidos.
|
... # trama esperada vs. real pyplot.parcela(y_verdad, etiqueta=«Actual) pyplot.parcela(y_pred, etiqueta=«Predicho) pyplot.leyenda() pyplot.mostrar() |
Relacionando todo esto, el siguiente ejemplo demuestra cómo evaluar un modelo de Profeta en un conjunto de datos de retención.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# Evaluar el modelo de predicción de la serie de tiempo del profeta en el conjunto de datos de hold out de pandas importación read_csv de pandas importación hasta_la_fecha de pandas importación DataFrame de fbprophet importación Profeta de sklearn.métrica importación error_absoluto_medio de matplotlib importación pyplot # Cargar datos camino = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv’ df = read_csv(camino, encabezado=0) # Preparar los nombres de las columnas esperadas df.columnas = [[«ds, ‘y’] df[[«ds]= hasta_la_fecha(df[[«ds]) # Crear un conjunto de datos de prueba, eliminar los últimos 12 meses tren = df.dejar caer(df.índice[[–12:]) imprimir(tren.cola()) # Definir el modelo modelo = Profeta() # Encaja con el modelo modelo.encajar(tren) # Definir el período para el que queremos una predicción futuro = lista() para i en rango(1, 13): fecha = ‘1968-%02d’ % i futuro.anexar([[fecha]) futuro = DataFrame(futuro) futuro.columnas = [[«ds] futuro[[«ds] = hasta_la_fecha(futuro[[«ds]) # Usar el modelo para hacer un pronóstico Previsión = modelo.predecir(futuro) # Calcular el MAE entre los valores esperados y los previstos para diciembre y_verdad = df[[‘y’][[–12:].valores y_pred = Previsión[[«yhat].valores mae = error_absoluto_medio(y_verdad, y_pred) imprimir(MAE: %.3f % mae) # trama esperada vs. real pyplot.parcela(y_verdad, etiqueta=«Actual) pyplot.parcela(y_pred, etiqueta=«Predicho) pyplot.leyenda() pyplot.mostrar() |
Ejecutando el ejemplo primero se reportan las últimas filas del conjunto de datos de entrenamiento.
Confirma que el entrenamiento termina en el último mes de 1967 y que 1968 se utilizará como conjunto de datos de retención.
|
ds y 91 1967-08-01 13434 92 1967-09-01 13598 93 1967-10-01 17187 94 1967-11-01 16119 95 1967-12-01 13713 |
A continuación, se calcula un error absoluto medio para el período de previsión.
En este caso podemos ver que el error es de aproximadamente 1.336 ventas, lo que es mucho más bajo (mejor) que un modelo de persistencia ingenuo que logra un error de 3.235 ventas en el mismo período.
Finalmente, se crea un gráfico que compara los valores reales con los previstos. En este caso, podemos ver que el pronóstico es un buen ajuste. El modelo tiene una habilidad y un pronóstico que parece sensato.
Parcela de valores reales vs. Predichos para los últimos 12 meses de ventas de coches
La biblioteca del Profeta también proporciona herramientas para evaluar automáticamente los modelos y trazar los resultados, aunque esas herramientas no parecen funcionar bien con datos de más de un día de resolución.