

En esta columna regular, le traeremos las últimas noticias de la industria centradas en nuestros principales temas de interés: grandes datos, ciencia de los datos, aprendizaje automático, IA y aprendizaje profundo. Nuestra industria se acelera constantemente con nuevos productos y servicios que se anuncian todos los días. Afortunadamente, estamos en estrecho contacto con los proveedores de este vasto ecosistema, por lo que estamos en una posición única para informarle sobre todo lo que es nuevo y emocionante. Nuestra enorme base de datos de la industria está creciendo todo el tiempo, así que manténgase atento a las últimas noticias que describen la tecnología que puede hacer que usted y su organización sean más competitivos.
MariaDB SkySQL añade SQL distribuido para la escalabilidad y la elasticidad en una nueva actualización importante
MariaDB®La Corporación anunció hoy una gran expansión de la base de datos en nube MariaDB SkySQL. Con esta actualización, SkySQL ahora ejecuta la última versión de la plataforma X5 de MariaDB, que más notablemente añadió capacidades de SQL distribuido para la escala global. Con la capacidad de ser desplegado como agrupado o distribuido, MariaDB SkySQL aborda las necesidades específicas de los clientes todo dentro de una potente e indestructible base de datos en nube.
«Construimos MariaDB SkySQL para reducir las complejidades introducidas por las bases de datos en nube de primera generación», dijo Michael Howard, CEO de MariaDB Corporation. «El panorama actual requiere una mezcla de servicios en la nube para hacer un solo trabajo – AWS RDS para transacciones simples, Aurora para la disponibilidad y el rendimiento, Redshift para el almacenamiento de datos en la nube y Google Spanner para SQL distribuido. SkySQL te da todas estas capacidades en una elegante base de datos en la nube que ofrece una experiencia consistente de MariaDB, independientemente de la forma en que se despliegue».
TigerGraph demuestra la escalabilidad para soportar volúmenes de datos masivos, cargas de trabajo complejas y desafíos empresariales del mundo real
TigerGraphla base de datos gráfica escalable para la empresa, anunció los resultados del primer estudio de referencia de gestión de datos gráficos exhaustivos utilizando casi 5 TB de datos en bruto en un grupo de máquinas – y los números de rendimiento demuestran que los gráficos pueden escalar con datos reales, en tiempo real. La empresa utilizó el Linked Data Benchmark Council Social Network Benchmark (LDBC SNB)reconocido como el estándar de referencia para evaluar el rendimiento de la tecnología de gráficos con cargas de trabajo analítico y transaccional intensivas. TigerGraph es el primer proveedor de la industria que informa de los resultados de referencia de LDBC a esta escala. TigerGraph es capaz de ejecutar consultas OLAP de enlace profundo en un gráfico de casi nueve mil millones de vértices (entidades) y más de 60 mil millones de bordes (relaciones), devolviendo los resultados en menos de un minuto.
«Este punto de referencia y estos resultados son significativos, tanto para TigerGraph como para el mercado en general. Aunque TigerGraph tiene múltiples clientes en producción con un tamaño de datos 10 veces mayor y un número de entidades/relaciones, este es el primer informe público de referencia en el que cualquiera puede descargar los datos, hacer consultas y llevar a cabo la referencia. Ningún otro proveedor de bases de datos gráficas o de bases de datos relacionales ha demostrado capacidades analíticas o números de rendimiento equivalentes», dijo el Dr. Yu Xu, CEO y fundador de TigerGraph. «Si había una incertidumbre persistente sobre la capacidad de los gráficos de escalar para acomodar grandes volúmenes de datos en un tiempo récord, estos resultados deberían eliminar esas dudas». El gráfico es el motor que nos permite responder a preguntas de negocios de alto valor con datos reales complejos, en tiempo real, a escala. El trabajo continuo de TigerGraph en la analítica avanzada de gráficos ha sido validado por el reconocimiento del mercado, las aplicaciones innovadoras de los clientes y la continua evolución de los productos, y estos resultados de referencia confirman la posición de la compañía como un claro líder del mercado, teniendo éxito donde otros proveedores han fracasado».
NXP anuncia la expansión de su cartera y capacidades de aprendizaje automático escalable
NXP Semiconductors N.V. (NASDAQ: NXPI) anunció que está mejorando su entorno de desarrollo de aprendizaje de máquinas y su cartera de productos. A través de una inversión, NXP ha establecido una asociación estratégica exclusiva con la empresa canadiense Au-Zone Technologies para ampliar el entorno de desarrollo de software de NXP eIQ™ Machine Learning (ML) con herramientas ML fáciles de usar y ampliar su oferta de motores de inferencia optimizados con silicio para Edge ML.
El DeepView™ ML Tool Suite de Au-Zone aumentará el eIQ con una interfaz gráfica de usuario (GUI) y un flujo de trabajo intuitivos, permitiendo a los desarrolladores de todos los niveles de experiencia importar conjuntos de datos y modelos, entrenar rápidamente y desplegar modelos de NN y cargas de trabajo de ML a través del portafolio de procesamiento de NXP Edge. Para satisfacer los exigentes requisitos de las aplicaciones industriales y de IO de hoy en día, la suite de herramientas eIQ-DeepViewML de NXP proporcionará a los desarrolladores características avanzadas para podar, cuantificar, validar y desplegar modelos de NN públicos o propietarios en los dispositivos NXP. Su capacidad de creación de perfiles a nivel de gráfico, en función de los objetivos, proporcionará a los desarrolladores conocimientos exclusivos en tiempo de ejecución para optimizar las arquitecturas de los modelos NN, los parámetros del sistema y el rendimiento en tiempo de ejecución. Al añadir el motor de inferencia en tiempo de ejecución DeepView de Au-Zone para complementar las tecnologías de inferencia de código abierto en NXP eIQ, los usuarios podrán desplegar y evaluar rápidamente las cargas de trabajo y el rendimiento de ML en los dispositivos NXP con un esfuerzo mínimo. Una característica clave de este motor de inferencia en tiempo de ejecución es que optimiza el uso de la memoria del sistema y el movimiento de datos de forma exclusiva para cada arquitectura SoC.
«Los procesadores de aplicaciones escalables de NXP ofrecen una plataforma de producto eficiente y un amplio ecosistema para que nuestros clientes puedan ofrecer rápidamente sistemas innovadores», dijo Ron Martino, Vicepresidente Senior y Director General de Procesamiento de Borde en NXP Semiconductores. «A través de estas asociaciones tanto con Arm como con Au-Zone, además de los desarrollos tecnológicos dentro de NXP, nuestro objetivo es aumentar continuamente la eficiencia de nuestros procesadores y, al mismo tiempo, aumentar la productividad de nuestros clientes y reducir su tiempo de salida al mercado». La visión de NXP es ayudar a nuestros clientes a lograr un menor costo de propiedad, mantener altos niveles de seguridad con datos críticos, y mantenerse seguros con formas mejoradas de interacción hombre-máquina».
Neo4j anuncia la primera máquina gráfica de aprendizaje para la empresa
Neo4jⓇlíder en tecnología de gráficos, anunció la última versión de Neo4j para la Ciencia de Datos GráficosTMun avance que democratiza las técnicas avanzadas de aprendizaje automático basado en gráficos (ML) aprovechando el aprendizaje profundo y las redes neuronales convolucionales gráficas.
Hasta ahora, pocas compañías fuera de Google y Facebook han tenido la previsión y los recursos de la IA para aprovechar las incrustaciones de gráficos. Esta poderosa e innovadora técnica calcula la forma de la red circundante para cada dato dentro de un gráfico, permitiendo mejores predicciones de aprendizaje de la máquina. Neo4j for Graph Data Science versión 1.4 democratiza estas innovaciones para cambiar la forma en que las empresas hacen predicciones en diversos escenarios, desde la detección de fraudes hasta el seguimiento del viaje de los clientes o pacientes, pasando por el descubrimiento de drogas y la finalización de gráficos de conocimiento.
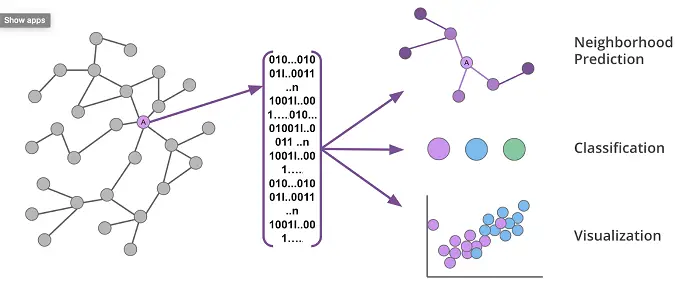
«Estamos encantados de incorporar las técnicas más avanzadas de incrustación de gráficos en un software empresarial fácil de usar», dijo la Dra. Alicia Frame, Directora de Producto Principal y Científica de Datos de Neo4j. «Lo que hemos aportado a la última versión de Neo4j para la Ciencia de los Datos Gráficos democratiza las técnicas del estado de la ciencia, y hace posible que cualquiera pueda utilizar el aprendizaje de las máquinas gráficas. Esto es un cambio de juego para lo que se puede lograr con el análisis predictivo.»
Sisense dota a SDL de datos y conocimientos analíticos para ayudar a impulsar la expansión empresarial mundial
Sisense, una plataforma de análisis líder para constructores, anunció que SDL ha proporcionado a todos los empleados acceso instantáneo a análisis de clientes y proyectos de fácil consumo mediante la plataforma Sisense. Esto ha acelerado la toma de decisiones basada en datos y la capacidad de gestionar proyectos de clientes para SDL, la empresa de lenguaje y contenido inteligente. La capacidad de proporcionar una visibilidad casi en tiempo real de la demanda del cliente de forma holística nunca fue posible antes de que la empresa empezara a utilizar la plataforma Sisense.
«Como una compañía de nuestro tamaño – y alcance global – estamos inundados de datos. A veces puede ser difícil encontrar respuestas simples», dijo Marion Shaw, Directora de Datos y Análisis de SDL. «Estamos realmente encantados con la capacidad de la plataforma Sisense; está mucho más allá de lo que hemos tenido nunca, y su flexibilidad nos ayuda a dar a la empresa las respuestas que necesita». También está en constante evolución, ayudándonos a adelantarnos a las demandas del mercado».
Fluree Open Sources es toda su plataforma de datos Web3
Fluree, líder del mercado en la gestión segura de datos, está liberando su código fuente principal bajo la licencia de código abierto AGPL. Los desarrolladores pueden ahora tirar de Fluree en Github y contribuir a él, construyendo a su vez un nuevo ecosistema de Internet que promueva la seguridad centrada en los datos, la trazabilidad y la interoperabilidad global.
«Con la contratación abierta de nuestra tecnología, rechazamos la práctica del statu quo de encerrar los datos en un formato propietario, y en su lugar solidificamos nuestro compromiso de construir las mejores soluciones de código abierto de su clase para los problemas de gestión de datos modernos», dijo el Co-Director General de Fluree Brain Platz. «Estamos ofreciendo a las empresas un puente desde el bloqueo de los proveedores hacia un futuro de completa propiedad, portabilidad e interoperabilidad de los datos».
Un barista expresivo entiende 1.300 millones de frases del lenguaje de los empleados fuera de la caja, salvando la brecha entre la IA y la semántica del lenguaje humano
Espressive, pionera en inteligencia artificial (IA) para la gestión de servicios empresariales (ESM), anunció que su agente de apoyo virtual basado en IA, Espressive Barista, ahora entiende 1.300 millones de frases en 14 equipos de servicios empresariales importantes y en nueve idiomas. Barista representa un cambio de paradigma en la prestación de autoayuda de los empleados basada en la IA. Impulsado por un avanzado motor de procesamiento de lenguaje natural (PNL) y sofisticadas capacidades de aprendizaje automático, Barista salva la brecha entre la IA y la semántica del lenguaje humano. Espressive también anunció que Barista es el primer agente de apoyo virtual que se integra con los sistemas de Respuesta de Voz Interactiva (IVR) para la gestión de servicios empresariales. La nueva integración reduce las llamadas al servicio de asistencia técnica al ofrecer acceso directo a Barista a los empleados en espera, proporcionando respuestas en tres segundos. Con Barista, las empresas pueden beneficiarse de la mayor desviación de las llamadas del servicio de asistencia, al tiempo que aumentan la adopción de los empleados y la productividad de la fuerza de trabajo.
«Mucha gente se pregunta si la IA realmente entiende lo que lee. Después de todo, no tiene el sentido común de entender el lenguaje humano», dijo Pat Calhoun, fundador y CEO de Espressive. «Creemos que se puede resolver este problema cerrando la brecha entre la IA y la semántica del lenguaje humano con suficientes datos, tecnología sofisticada y talento». Reconocimos que el éxito de Amazon Alexa y Google Home se basa en un alto grado de precisión debido a los millones de consumidores que los usan diariamente, además de un ejército de científicos de datos, lingüistas computacionales, desarrolladores e ingenieros de aprendizaje automático que afinan el motor de la IA entre bastidores». Por lo tanto, diseñamos Barista para replicar ese modelo. Me enorgullece anunciar que hoy en día, Barista entiende más de 1.300 millones de frases empresariales con un alto grado de precisión, y ese número crece diariamente. Por eso nuestros clientes experimentan la mayor desviación de boletos en la industria.»
RudderStack lanza la nube RudderStack – Plataforma de datos de clientes construida para desarrolladores ofrece integraciones clave incluyendo Snowflake y DBT
RudderStack, que proporciona una Plataforma de Datos de Clientes (CDP) diseñada específicamente para los desarrolladores, lanzó la próxima generación de su oferta SaaS – RudderStack Cloud, el producto de datos de clientes más eficiente, asequible y sofisticado para los desarrolladores. Ofreciendo integraciones con plataformas como Snowflake y DBT, RudderStack Cloud resuelve el problema del silo de datos permitiendo a los ingenieros de datos unificar sus datos y añadir la funcionalidad CDP en la parte superior de su propio almacén.
Los CDP tradicionales han tratado de resolver el problema de la recopilación y activación de datos, pero lamentablemente la mayoría de ellos lo empeoran creando más silos de datos y lagunas de integración. Los ingenieros de datos a menudo se encuentran atascados en el medio, aprovechando sólo parcialmente el poder de herramientas como Snowflake y DBT porque otros componentes de la pila no se integran con su mayor flujo de datos. RudderStack pone a los desarrolladores, sus herramientas preferidas y las arquitecturas modernas al frente y en el centro, ayudando a los ingenieros de datos y a sus compañías a descubrir nuevas y poderosas oportunidades en la forma en que conectan estos sistemas críticos y los ponen a trabajar en toda la organización.
«Es hora de un nuevo enfoque en la forma en que las compañías arquitecturan sus pilas de datos de clientes y cómo los CDPs encajan en el conjunto de herramientas, y eso es exactamente lo que estamos construyendo en RudderStack», dijo Soumyadeb Mitra, CEO de RudderStack. «Al permitir a los desarrolladores convertir su almacén en un CDP, estamos eliminando los silos de datos, resolviendo las preocupaciones de seguridad, y haciendo que los datos más ricos posibles estén más ampliamente disponibles en toda la organización».
Los datos del tesoro proporcionan análisis de cambio de juego para las marcas con el lanzamiento de Treasure Insights
Treasure Data™ introdujo nuevas capacidades de productos para su Plataforma de Datos de Clientes (CDP) que proporcionan análisis de cambio de juego a las marcas. Treasure Data anunció 15 nuevas integraciones, con lo que el número total de conectores en su red asciende a más de 170. Por último, con este lanzamiento Treasure Data también lanzó un SDK (kit de desarrollo de software) en la tienda que proporciona a los minoristas una visión completa y unificada del viaje de los compradores.
«Los datos del tesoro permiten a las empresas construir conocimientos a la velocidad de las decisiones de los clientes», dijo Rob Parrish, Vicepresidente de Producto, Datos del Tesoro. «Respaldados por nuestras capacidades de administración de datos de clientes líderes en la industria, Treasure Data continúa construyendo su solución integral para acelerar aún más el tiempo de obtención de valor para nuestros clientes».
Informatica anuncia capacidades avanzadas de gestión de datos de cloud computing para ayudar a las empresas a transformarse rápidamente en el cloud
Informatica, el líder en gestión de datos en nube para empresas, anunció nuevas capacidades avanzadas diseñadas para ayudar a los clientes a convertirse rápidamente en los primeros en utilizar la nube en esta pandemia mundial. IDC predice un crecimiento continuo de dos dígitos en la transformación digital de la infraestructura en 2020 durante la pandemia, a medida que las empresas invierten cada vez más en la nube para acelerar sus esfuerzos de transformación digital. Informatica ha estado a la vanguardia de la gestión de datos de cloud computing empresarial, innovando continuamente para ayudar a sus clientes a tener éxito en la era Cloud-AI.
«La innovación centrada en el cliente con un pulso en el sector es lo que impulsa el liderazgo de mercado de Informatica en la gestión de datos en nube para la empresa», afirmó Jitesh Ghai, vicepresidente senior y director general de gestión de datos de Informatica. «Hemos realizado importantes inversiones a escala empresarial, nativas del cloud y potenciadas por la IA en la innovación de productos y plataformas, como se muestra en nuestro liderazgo en el Cuadrante Mágico de Gartner en las cinco categorías clave de la gestión de datos». A medida que las empresas se transforman utilizando el análisis en la nube para seguir siendo competitivas en medio de una pandemia global, Informatica está bien posicionada para ayudarles a tener éxito en la era de la nube y la IA».
GoSpotCheck se basa en la nube de Google para el seguimiento de la actividad en tiempo real de algunas de las marcas más grandes del mundo
GoSpotCheck, la empresa de software que está reimaginando cómo funciona la fuerza laboral del mañana, anunció que ha integrado Looker, la plataforma de inteligencia empresarial (BI) y análisis de Google Cloud, para crear una plataforma para construir experiencias de datos personalizadas que aceleren los resultados empresariales para sus clientes.
GoSpotCheck (GSC) es una plataforma móvil de gestión de tareas que conecta a los trabajadores de primera línea con los objetivos y directivas de la empresa, crea una visión compartida del campo y ayuda a los líderes a tomar mejores decisiones, más rápidamente. Al desplegar Looker, GSC fue capaz de crear 225 experiencias de datos personalizados que encajan perfectamente en los flujos de trabajo existentes para entregar datos en tiempo real en el punto de necesidad, y reducir el tiempo total necesario para construir informes en un 70%. Hoy en día, GSC entrega las experiencias un 95% más rápido a cientos de sus principales clientes empresariales en todo el mundo, incluyendo Dole, Fruit of the Loom, Save A Lot, y Under Armour.
«Muchos de nuestros clientes operan en ecosistemas complejos donde tienen mucho que hacer, y con Looker nos aseguramos de que los datos no sean una de las cosas de las que tengan que preocuparse. Proporcionamos la cantidad adecuada de datos a diferentes niveles de usuarios en la empresa y los visualizamos de la forma en que quieren consumirlos en función de su papel u objetivos empresariales. El hecho de poder proporcionar la información correcta a estas diferentes capas de interesados proporciona un valor increíble a nuestros clientes y una seria ventaja competitiva», dijo Jeff Wrona, Vicepresidente de Implementaciones Estratégicas de GSC.
Kespry colabora con Microsoft para ofrecer el análisis de percepción de Kespry para buscar y analizar intuitivamente datos visuales y geoespaciales complejos
Kespry, un proveedor líder de soluciones de búsqueda y análisis visual, anunció la disponibilidad de Kespry Perception Analytics. La solución está diseñada para casos de uso industrial que requieren un análisis exhaustivo de datos visuales complejos, incluyendo el seguimiento del estado de los activos y la identificación de anomalías que afectan al negocio. Kespry Perception Analytics se integra verticalmente como una solución ISV para Microsoft Dynamics 365 y Power Platform.
En el corazón de Kespry Perception Analytics se encuentra un gráfico de conocimiento que mapea con precisión toda la biblioteca de datos visuales de una empresa, incluyendo los archivos de medios y la producción fotogramétrica, por tipos de activos físicos, su ubicación geográfica específica y los tipos y tiempos de los problemas identificados. La plataforma proporciona un conjunto de herramientas completo para ingerir e indexar los datos, así como para aprovechar el Azure machine learning (ML) de Microsoft para generar conocimientos sobre los datos. Lo que diferencia a Kespry Perception Analytics es su búsqueda intuitiva y sus capacidades analíticas que permiten a los equipos de fiabilidad y mantenimiento consultar los datos sin ningún conocimiento de codificación. Ofrece cuadros de mando interactivos y herramientas de visualización de datos para analizar la salud de los activos de toda la empresa.
«Kespry Perception Analytics ofrece una visión empresarial sin precedentes y resuelve los principales problemas de las empresas industriales que han luchado por obtener un valor significativo de los datos visuales de manera oportuna», dijo George Mathew, CEO de Kespry. «Proporciona a las empresas una visión más completa del estado de los activos que depender sólo de los datos de telemetría». Está diseñado con una interfaz simple para ayudar a los usuarios a navegar intuitivamente a través de análisis complejos con facilidad».
Privacera Platform 4.0 automatiza el ciclo de vida de la gestión de datos de la empresa
Privacera, un líder en gobernanza y seguridad de datos en la nube fundado por los creadores de Apache Ranger™, anunció la disponibilidad general de la versión 4.0 de la Plataforma Privacera, una solución de gobernanza y seguridad de datos empresariales para el aprendizaje automático y las cargas de trabajo analítico en la nube pública. Impulsadas por la creciente demanda de los clientes, las nuevas características de Privacera 4.0 incluyen: flujos de trabajo de acceso para una incorporación más rápida y un acceso personalizado a los datos; descubrimiento ampliado para el etiquetado de datos sin fisuras en infraestructuras complejas; y una pasarela de cifrado para capacidades de cifrado y descifrado automatizados.
«Para que las empresas puedan maximizar realmente el valor de sus datos, deben asegurarse de que saben exactamente dónde se encuentran sus datos sensibles y quién tiene acceso a ellos, lo que puede ser un proceso muy lento y manual para muchos», dijo Srikanth Venkat, Vicepresidente de Producto de Privacera. «Privacera 4.0 es una respuesta directa a esta necesidad, y hemos hecho mejoras significativas para proporcionar a nuestros clientes la experiencia más fluida posible. Hemos hecho que todo el ciclo de vida del gobierno esté completamente automatizado para nuestros clientes, asegurando que estén protegidos incluso en las infraestructuras más complejas».
Los clientes de Data Analytics valoran la elección y la simplicidad; el nuevo precio flexible de la nube de Teradata proporciona ambas cosas
Reconociendo que las cargas de trabajo de análisis de datos, los patrones de uso y las tasas de utilización pueden variar ampliamente en una organización, Teradata (NYSE: TDC), la compañía de plataforma de análisis de datos en la nube, anunció opciones flexibles de precios de la nube para facilitar el crecimiento de las empresas y beneficiarse del análisis de datos en la nube. De acuerdo con el objetivo de Teradata de proporcionar a sus clientes simplicidad y elección, la compañía ahora ofrece dos modelos flexibles de precios en la nube: Mezcla y Consumo. El modelo Blended Pricing es el más adecuado para un alto uso y proporciona lo último en previsibilidad de facturación, al tiempo que ofrece el menor coste a escala. El modelo de precios de consumo es una opción asequible, de pago por uso, que se adapta mejor a las consultas ad hoc y a las cargas de trabajo con un uso típico o desconocido, y que ofrece transparencia en los costos para facilitar la devolución de cargos por parte de los departamentos. Con una amplia disponibilidad de ambos modelos, las empresas pueden esperar de Teradata más opciones, menor riesgo, mayor eficiencia y mayor transparencia. Estas opciones son cruciales en el impredecible mercado actual, en el que las tecnologías, las cadenas de suministro y las expectativas de los clientes pueden cambiar bruscamente, dejando a las empresas con inversiones en análisis de datos varadas si su software no proporciona suficiente flexibilidad para evolucionar a medida que cambian las necesidades.
«Si el año 2020 nos ha enseñado algo, es que el cambio se produce rápidamente, y el hecho de tener opciones de precios en la nube simples y flexibles da a los clientes la libertad necesaria para optimizar sus inversiones en análisis de datos», dijo Hillary Ashton, Jefe de Producto de Teradata. «Los diferentes casos de uso analítico tienen patrones de utilización muy diferentes en diferentes puntos en el tiempo, lo que significa que tener opciones en los modelos de precios permite a Teradata ofrecer el mejor para cada escenario del cliente, desde un pequeño sistema de descubrimiento ad hoc hasta un gran entorno analítico de producción».
Cyxtera trae una innovadora computación AI/ML como un servicio ofrecido al mercado federal
Cyxtera, líder mundial en servicios de colocación e interconexión de centros de datos, anunció la disponibilidad de su emblemática computación de Inteligencia Artificial/Aprendizaje por Máquina (AI/ML) como una oferta de servicio para las agencias gubernamentales que necesitan una infraestructura de vanguardia para alimentar las cargas de trabajo de la AI. Esta oferta, la primera del mercado, aprovecha el sistema A100 de NVIDIA DGX™ y se suministrará a través de la plataforma de intercambio de servicios federales de Cyxtera, certificada como FedRAMP Ready at the High Impact Level, desde los centros de datos de alta seguridad de la compañía en el norte de Virginia y Dallas-Fort Worth.
La disponibilidad de la computación AI/ML de Cyxtera como solución de servicio proporciona a los organismos gubernamentales, así como a sus contratistas y subcontratistas, un mayor rendimiento, agilidad y un rápido despliegue de la infraestructura para apoyar las cargas de trabajo de la IA. La oferta también elimina la necesidad de realizar importantes desembolsos de capital y de prolongar los ciclos de aprovisionamiento que normalmente se requieren para los sistemas y la infraestructura de apoyo diseñados para satisfacer las necesidades de los proyectos gubernamentales relacionados con la IA.
«Llevar la potencia del cálculo AI/ML de NVIDIA, potenciado por la DGX, como una oferta de servicio al mercado gubernamental mejora aún más la capacidad de Cyxtera para ofrecer un sólido conjunto de opciones de infraestructura segura y de vanguardia para satisfacer las cambiantes necesidades de nuestros clientes del gobierno federal», dijo Leo Taddeo, Presidente del Grupo Federal de Cyxtera y Director de Seguridad de la Información de Cyxtera. «Con el estatus FedRAMP Ready de Cyxtera en el Nivel de Alto Impacto para la infraestructura bajo demanda y las soluciones de interconexión construidas para datos sensibles del gobierno federal, nuestro equipo es capaz de proporcionar a los clientes del sector público una solución de vanguardia alineada con la prioridad ‘Cloud Smart’ del gobierno federal en los esfuerzos de modernización de TI».
Couchbase avanza en la innovación informática con el lanzamiento de Couchbase Lite y Sync Gateway 2.8
Couchbase, el creador de la base de datos NoSQL multi-nube a borde, anunció la versión 2.8 de Couchbase Lite y Couchbase Sync Gateway para aplicaciones de computación móvil y borde. Disponible ahora, el lanzamiento da a las organizaciones el poder de aprovechar al máximo una arquitectura de nube distribuida, creando aplicaciones siempre activas y rápidas que garantizan el tiempo de actividad empresarial incluso en un entorno informático desconectado.
«Empresas de todo tipo continúan explorando lo que la computación de punta tiene para ofrecer, y estamos comenzando a acercarnos al punto en el que alcanza su máximo potencial», dijo Ravi Mayuram, Vicepresidente Senior de Ingeniería y CTO de Couchbase. «Al hacer que las aplicaciones dependan cada vez menos de la sincronización con un servidor central, estamos dando a las empresas las herramientas que necesitan para aprovechar al máximo el borde. Independientemente de su entorno, las empresas pueden realizar sin problemas nuevas implementaciones de borde cuando y como sean necesarias y aprovechar las capacidades mejoradas de transferencia de datos que hacen que las aplicaciones de borde sean más inteligentes que nunca».
El aprendizaje automático llega a la base de datos de código abierto de MariaDB con integración de MindsDB
MindsDB, la capa de IA de código abierto para las bases de datos existentes, anunció su integración oficial con la base de datos relacional de código abierto ampliamente utilizada, MariaDB Community Server. Esta integración satisface una demanda de larga data de los usuarios de la base de datos de poder aportar capacidades de aprendizaje automático a la base de datos y democratizar el uso de la LD. MindsDB ayuda a aplicar los modelos de aprendizaje automático directamente en la base de datos proporcionando una capa de IA que permite a los usuarios de la base de datos desplegar modelos de aprendizaje automático de última generación utilizando consultas SQL estándar. El uso de las tablas de IA ayuda a los usuarios de la base de datos a aprovechar los datos de predicción dentro de la base de datos para proyectos de aprendizaje automático más fáciles y efectivos.
«Como MindsDB se propone democratizar el aprendizaje de la máquina, estamos entusiasmados por ofrecer capacidades de ML a la comunidad de MariaDB», dijo el cofundador de MindsDB, Adam Carrigan. «MariaDB comparte nuestra visión y entiende que poner las herramientas de aprendizaje automático en manos de los usuarios que mejor conocen sus datos es la forma más efectiva de resolver sus problemas».
Nexla lanza Nexsets para reimaginar los DataOps y conducir el autoservicio
Nexla, un tejido de datos convergentes, anunció el lanzamiento de Nexsets, una tecnología innovadora que hace que las operaciones de datos sean colaborativas y permite a los equipos de datos enriquecer, asegurar, compartir y validar datos fácilmente. La plataforma de Nexla aplica una inteligencia continua en los datos para automatizar las tareas de ingeniería que consumen mucho tiempo. El resultado es una nueva forma de impulsar la integración y transformación de datos en autoservicio. Con el lanzamiento de Nexsets, ahora los usuarios de negocios tienen acceso a vistas de datos curados que facilitan la conexión de datos con cualquier aplicación con un mínimo de soporte de ingeniería.
Los entornos de datos son cada vez más complejos y trabajar con datos de sistemas dispares es un desafío. Sin embargo, la integración de datos, la creación y gestión de API, el mantenimiento de la seguridad y la transformación y preparación de datos para una amplia variedad de sistemas y aplicaciones, todas estas actividades suponen una enorme carga para los recursos de ingeniería. Como resultado, los ingenieros de datos luchan por satisfacer las necesidades de los usuarios empresariales y, a su vez, los usuarios empresariales luchan por aprovechar los datos para hacer avanzar el negocio.
Upsolver crea la primera casa de lagos de nubes realmente abierta, libera los conectores de ingestión nativa a Redshift y Snowflake
Upsolver, proveedor de un motor de casa de lago de nubes, anunció el lanzamiento de conectores de ingestión nativos para Amazon Redshift y Snowflake (NYSE: SNOW), creando la primera casa de lago de nubes realmente abierta. Usando la plataforma de Upsolver, las empresas pueden ahora cambiar fácilmente entre los almacenes de datos y los motores de consulta del lago de datos, a través de múltiples proveedores.
Si bien los almacenes de datos son excelentes para la inteligencia comercial, no pueden atender todas las necesidades de procesamiento de datos de las empresas modernas, como la transmisión de datos, la búsqueda de texto y el aprendizaje por máquina. Y aunque los lagos de datos son una forma rentable de almacenar grandes cantidades de datos, son complejos de gestionar y requieren una costosa experiencia de ingeniería (en las instalaciones y en la nube). El motor de la casa del lago de datos de Upsolver permite a las organizaciones lograr ahora las ventajas de costo y flexibilidad de un lago de datos combinado con la facilidad de uso de un almacén de datos.
«Soluciones como Redshift y Snowflake son increíbles para hacer valiosos los datos, pero una base de datos no puede resolver todos los casos de uso», dijo Ori Rafael CEO de Upsolver. «Las organizaciones deben ser capaces de aprovechar múltiples motores de base de datos y cambiar fácilmente entre ellos de acuerdo a su caso de uso, habilidades internas y restricciones de costos. Esta es la visión de la casa del lago de nubes abierta y Upsolver es el motor que la impulsa».
Micro Focus introduce una nueva capacidad de análisis de datos para manejar AIOps de pila completa
Micro Focus (LSE: MCRO; NYSE: MFGP) anunció el lanzamiento de su lago de datos ITOM «Collect Once Store Once» (COSO), utilizando una plataforma de datos de acceso abierto construida sobre Vertica para manejar AIOps de pila completa en el amplio conjunto de soluciones de monitorización y automatización de Micro Focus. COSO es ahora una parte integrada del puente de operaciones de Micro Focus, la gestión de operaciones de red y la automatización del centro de datos. Este enfoque para proporcionar un espectro completo de informes y conocimientos a través de la monitorización de múltiples dominios, la gestión y el cumplimiento de parches sólo está disponible en Micro Focus.
«La diversidad de datos disponibles para las operaciones de TI hoy en día hace que sea un reto resolver problemas complejos a través de servicios de TI multi-nube y en las instalaciones», dijo Tom Goguen, Jefe de Producto de Micro Focus. «COSO ofrece ahora una capacidad única de recogida y almacenamiento construida sobre la potente plataforma de análisis de datos de alta velocidad de Vertica. Combine COSO con nuestras herramientas de descubrimiento, supervisión, automatización de procesos y gestión de parches de primera clase, y podrá disponer hoy mismo de AIOps de pila completa para identificar la causa raíz y restaurar el servicio más rápido que nunca».
O’Reilly lanza una nueva y poderosa herramienta para aprender en el flujo de trabajo:
O’Reilly responde
O’Reilly, la fuente de aprendizaje basado en la perspicacia sobre tecnología y negocios, anunció el lanzamiento de O’Reilly Answers, un motor avanzado de procesamiento de lenguaje natural (PNL) que ofrece respuestas rápidas y contextualmente relevantes a preguntas técnicas desafiantes planteadas por los usuarios a través del aprendizaje en línea de O’Reilly. Con una integración en Slack con un solo clic, O’Reilly Answers ayuda a los usuarios a aprender y a descubrir el contenido que hace avanzar los negocios.
Aprovechando las técnicas avanzadas de aprendizaje por máquina, el motor de búsqueda de O’Reilly Answers ofrece resúmenes y fragmentos relevantes de la biblioteca de O’Reilly de contenido experto en miles de títulos de O’Reilly, apuntando a los usuarios directamente sólo a los recursos más aplicables y eliminando el ruido. Para fomentar un descubrimiento más profundo, la función permite a los usuarios profundizar en piezas de contenido completo de los títulos referenciados. Para mejorar aún más la productividad, todas las funciones de O’Reilly Answers están disponibles a través de una sencilla integración de Slack.
«Más de la mitad de todo el uso de O’Reilly es aprendizaje no lineal – encontrar soluciones rápidas que se pueden aplicar rápidamente al trabajo. Tomarse el tiempo necesario para buscar recursos puede significar la diferencia entre dar el siguiente paso o estancarse en un proyecto», dijo Laura Baldwin, Presidenta de O’Reilly Media. «A medida que nos acercamos al nuevo ritmo de cambio organizativo, O’Reilly Answers ayuda a salvar la brecha entre el aprendizaje y el conocimiento, eliminando la necesidad de largas sesiones de formación y ayudando a los usuarios a volver al trabajo con las herramientas que necesitan para hacer el trabajo».
Suscríbete al boletín de noticias gratuito de InsideBIGDATA.