
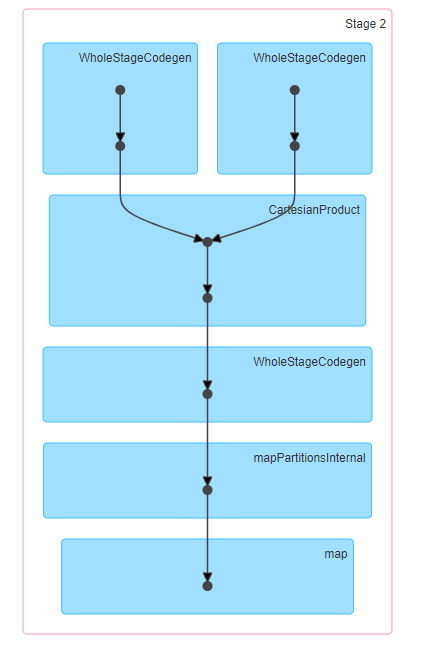
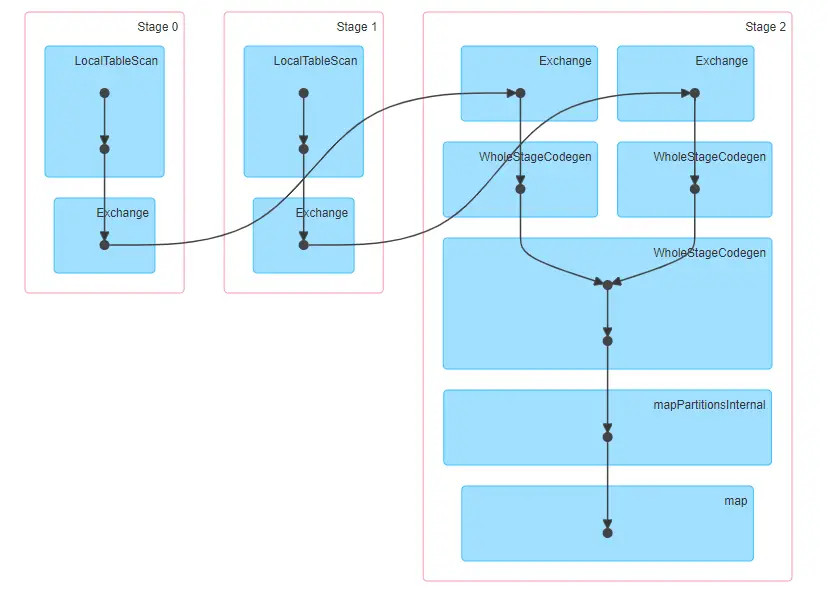
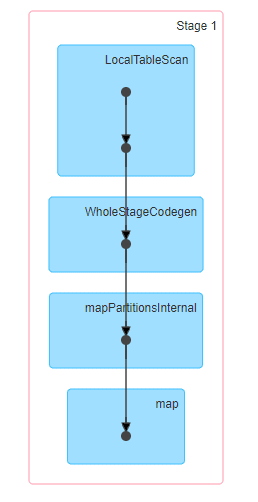
8 de enero de 2021
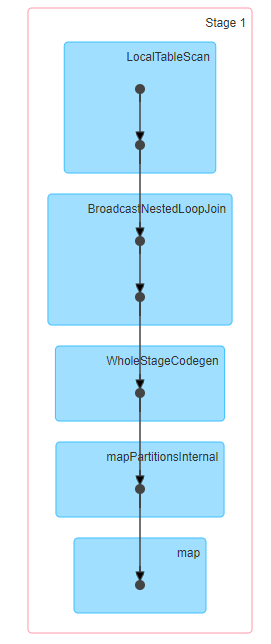
¿Cómo funciona el Broadcast Nested Loop Join en Spark? – Hadoop en el mundo real
1 de enero de 2021
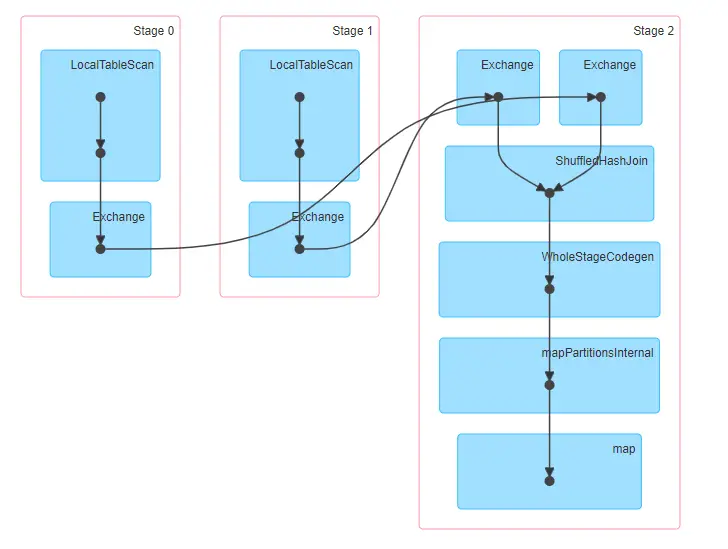
¿Cómo funciona el Shuffle Hash Join en Spark? – Hadoop en el mundo real
22 de julio de 2020
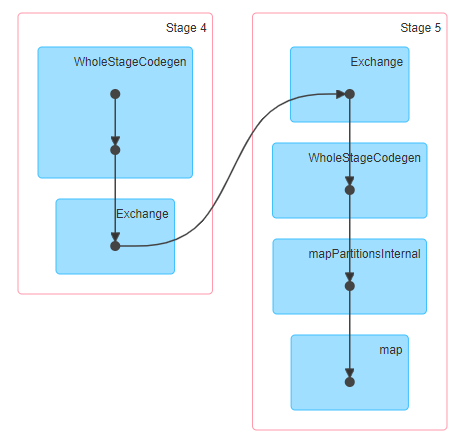
Mejorando el rendimiento en spark usando particiones – Hadoop en el mundo real
22 de julio de 2020

El Hadoop se queda sin gasolina
21 de julio de 2020

Registro del esquema y evolución del esquema en Kafka
20 de julio de 2020
