

En el esfuerzo por satisfacer la creciente demanda de almacenamiento de datos y acomodar la variedad de datos de la manera más eficiente, existe una tendencia creciente a optar por tipos de bases de datos no estándar. Durante años, las bases de datos relacionales han sido la norma. Sin embargo, a medida que cambian los requisitos y bajan los precios del almacenamiento, la gente suele optar por utilizar bases de datos no relacionales.
Las bases de datos en columnas se ajustan a esta descripción. Estas son bases de datos NoSQL creadas para tareas de consultas complejas y altamente analíticas. A diferencia de las bases de datos relacionales, las bases de datos en columnas almacenan sus datos por columnas, en lugar de por filas. Estas columnas se agrupan para formar subgrupos.
Las claves y los nombres de columna de este tipo de base de datos no son fijos. Las columnas dentro de la misma familia de columnas, o grupo de columnas, pueden tener un número diferente de filas y pueden acomodar diferentes tipos de datos y nombres.
Estas bases de datos se utilizan con mayor frecuencia cuando se necesita un modelo de datos grande. Son muy útiles para almacenes de datos, o cuando hay una necesidad de alto rendimiento o manejo de consultas intensivas.
Cómo funcionan las bases de datos orientadas a columnas
Las bases de datos relacionales tienen un esquema establecido y funcionan como tablas de filas y columnas. Las bases de datos de columnas anchas tienen un esquema similar, pero diferente. También tienen filas y columnas. Sin embargo, no están fijos dentro de una tabla, sino que tienen un esquema dinámico. Cada columna se almacena por separado. Si hay columnas similares (relacionadas), se unen en familias de columnas y luego las familias de columnas se almacenan por separado de otras familias de columnas.
La clave de fila es la primera columna de cada familia de columnas y sirve como identificador de una fila. Además, cada columna posterior tiene una clave de columna (nombre). Identifica columnas dentro de filas y, por lo tanto, permite la consulta de las columnas. El valor y la marca de tiempo vienen después de la clave de columna, dejando un rastro de cuándo se ingresaron o modificaron los datos.
El número de columnas pertenecientes a cada fila, o su nombre, puede variar. En otras palabras, no todas las columnas de una familia de columnas y, por lo tanto, una base de datos, tienen el mismo número de filas. De hecho, aunque compartan su nombre, cada columna está contenida en una fila y no se ejecuta en todas las filas.
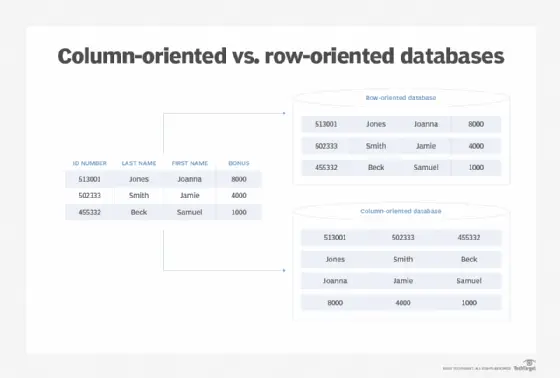
Quienes se han encontrado con bases de datos relacionales saben que cada columna de una base de datos relacional tiene el mismo número de filas, pero sucede que algunos de los campos tienen un valor nulo o parecen estar vacíos. Con bases de datos de columnas anchas, en lugar de estar vacías, estas filas simplemente no existen para una columna en particular.
Las familias de columnas están ubicadas en un espacio de claves. Cada espacio de claves contiene un almacén de datos NoSQL completo y tiene una función o importancia similar a la que tiene un esquema para una base de datos relacional. Sin embargo, como los almacenes de datos NoSQL no tienen una estructura establecida, los espacios de claves representan una base de datos sin esquema que contiene el diseño de un almacén de datos y su propio conjunto de atributos.
Una de las bases de datos en columnas más populares disponibles es MariaDB. Fue creado como una bifurcación de MySQL con la intención de ser robusto y escalable, manejar muchos propósitos diferentes y un gran volumen de consultas. Apache Cassandra es otro ejemplo de una base de datos en columnas que maneja cargas pesadas de datos en numerosos servidores, lo que hace que los datos estén altamente disponibles. Algunos de los otros nombres en esta lista incluyen Apache HBase, Hypertable y Druid especialmente diseñados para análisis. Estas bases de datos admiten determinadas funciones de plataformas como Outbrain, Spotify y Facebook.
Tipos de familias de columnas
- Familia de columnas estándar. Este tipo de familia de columnas es similar a una tabla; contiene un par clave-valor donde la clave es la clave de fila y los valores se almacenan en columnas utilizando sus nombres como identificadores.
- Familia súper columna. Una supercolumna representa una matriz de columnas. Cada supercolumna tiene un nombre y un valor que asigna la supercolumna a varias columnas diferentes. Las supercolumnas relacionadas se unen en una sola fila en familias de supercolumnas. En comparación con una base de datos relacional, esto es como una vista de varias tablas diferentes dentro de una base de datos. Imagine que tiene la vista de las columnas y los valores disponibles para una sola fila, es decir, un identificador único en muchas tablas diferentes, y puede almacenarlos todos en un solo lugar: esa es la familia de supercolumnas.
Ventajas de las bases de datos orientadas a columnas
- Escalabilidad. Esta es una gran ventaja y una de las principales razones por las que este tipo de base de datos se utiliza para almacenar big data. Con la capacidad de distribuirse en cientos de máquinas diferentes según la escala de la base de datos, admite un procesamiento paralelo masivo. Esto significa que puede emplear muchos procesadores para trabajar en el mismo conjunto de cálculos simultáneamente.
- Compresión. No solo son infinitamente escalables, sino que también son buenos para comprimir datos y, por lo tanto, ahorrar almacenamiento.
- Muy receptivo. El tiempo de carga es mínimo y las consultas se realizan rápidamente, lo que se espera dado que están diseñadas para contener big data y ser prácticas para la analítica.
Desventajas de las bases de datos orientadas a columnas
- Procesamiento transaccional en línea. Estas bases de datos no son tan eficientes con el procesamiento transaccional en línea como con el procesamiento analítico en línea. Esto significa que no son muy buenos para actualizar transacciones, pero están diseñados para analizarlas. Es por eso que se pueden encontrar con los datos necesarios para el análisis empresarial con una base de datos relacional que almacena datos en el back-end.
- Carga de datos incremental. Como se mencionó anteriormente, las bases de datos típicamente orientadas a columnas se utilizan para el análisis y son rápidas para recuperar datos, incluso cuando se procesan consultas complejas, ya que se mantienen juntas en columnas. Si bien las cargas de datos incrementales no son imposibles, las bases de datos en columnas no las realizan de la manera más eficiente. En primer lugar, es necesario escanear las columnas para identificar las filas correctas y seguir escaneando para localizar los datos modificados que requieren sobrescritura.
- Consultas específicas de filas. Al igual que las posibles caídas mencionadas anteriormente, todo se reduce al mismo problema, que es usar el tipo correcto de base de datos para los propósitos correctos. Con las consultas específicas de filas, está introduciendo un paso adicional de escanear las columnas para identificar las filas y luego ubicar los datos para recuperar. Se necesita más tiempo para acceder a registros individuales dispersos en varias columnas, en lugar de acceder a registros agrupados en una sola columna. Las consultas frecuentes específicas de filas pueden causar problemas de rendimiento al ralentizar una base de datos orientada a columnas, que está especialmente diseñada para ayudarlo a obtener rápidamente la información requerida, frustrando así su propósito.
Las bases de datos NoSQL están diseñadas principalmente para adaptarse a propósitos específicos y no se espera que funcionen como un tipo general de almacenamiento. Las bases de datos de columnas anchas están orientadas a columnas en lugar de a filas y están destinadas a almacenar y consultar macrodatos. Hay muchas bases de datos diferentes disponibles dentro del tipo y vale la pena explorar sus características mientras busca la solución de almacenamiento de datos más adecuada.