

Los datos de atención médica tienen un gran potencial para mejorar la medicina, pero extraerlos no es fácil. Para llegar al oro, Truveta construyó un gran modelo impulsado por IA para analizar textos médicos de más de 20,000 clínicas y 700 hospitales.
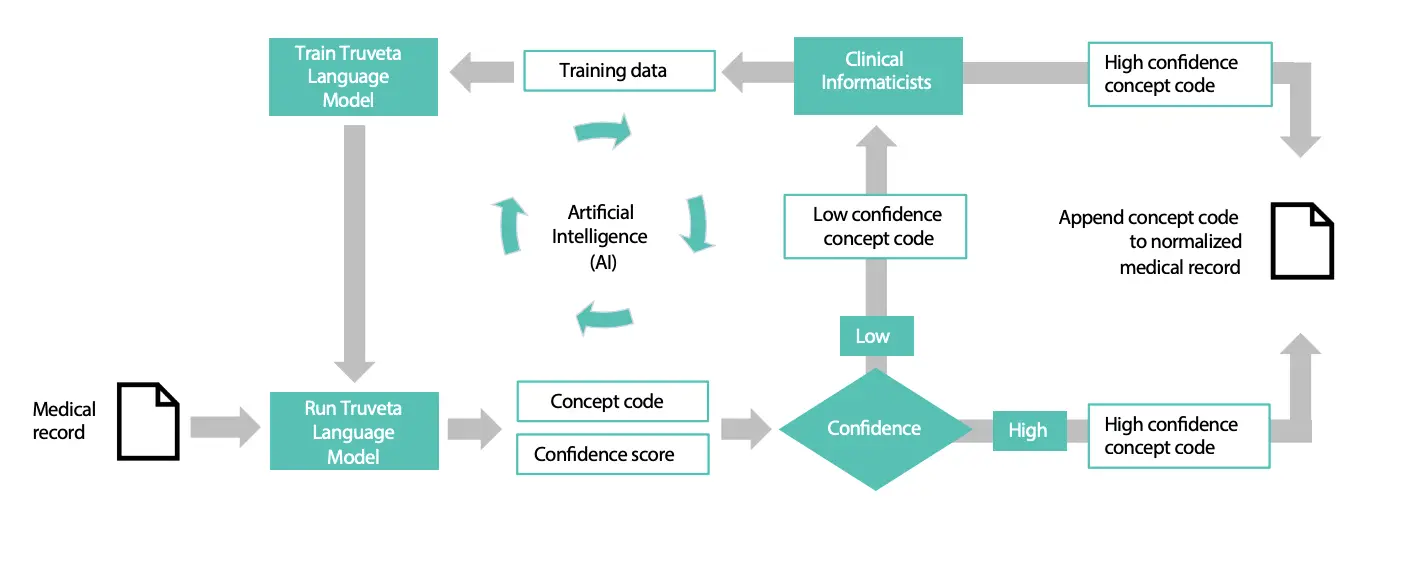
El modelo de Truveta está diseñado para extraer diagnósticos de pacientes, medicamentos, resultados de laboratorio y otros datos de fuentes como notas médicas y reclamaciones de seguros: texto desordenado y sin estructura lleno de abreviaturas, jerga y faltas de ortografía. El modelo realiza estas tareas con más del 90% de precisión, dice la compañía.
La startup de tecnología de atención médica del área de Seattle presentó el modelo de lenguaje Truveta en una publicación preliminar reciente y brindó más información esta semana en un libro blanco y una publicación de blog.
El modelo se entrena con grandes cantidades de textos médicos de los 28 socios del sistema de salud de la empresa, lo que representa el 16 % de la atención al paciente en los EE. UU. La empresa también actualiza sus conjuntos de datos a diario.
“La cantidad de datos que procesamos todos los días y ponemos a disposición de los investigadores de manera oportuna lo convierte en un problema de datos muy complejo y realmente grande”, dijo Jay Nanduri, director de tecnología de Truveta, en una entrevista con GeekWire.
Los clientes de salud y ciencias de la vida de Truveta estudian eventos como reacciones adversas a medicamentos o frecuencia de convulsiones del paciente. Los investigadores del cáncer podrían usar la plataforma para señalar la progresión de la enfermedad y la necesidad de un cambio en el tratamiento.
El modelo «normaliza» los datos desordenados, de modo que textos como «COVID-19 agudo» y «COVID19 _ infección aguda» significan lo mismo. Y puede lograrlo a escala: Truveta tiene acceso a 3100 millones de encuentros con pacientes y 2400 millones de pedidos de medicamentos debido a sus relaciones con los principales sistemas de salud.
El modelo de Truveta es distinto de GPT-4, el modelo de lenguaje grande «generativo» de OpenAI respaldado por Microsoft, que produce contenido instantáneamente basado en indicaciones. Los usos de salud propuestos de GPT-4 incluyen diagnósticos de apoyo, resúmenes de conversaciones médico-paciente y sugerencias de lenguaje de cabecera para los médicos.
La capacitación especializada de Truveta en conjuntos de datos médicos va más allá de GPT-4, que fue capacitado en una amplia gama de información abierta en Internet, dijo Myerson. También se sabe que GPT-4 «alucina» las respuestas falsas a las consultas, señaló.
GPT-4 puede parecer «un doctor en ácido», dijo Myerson. «Las imprecisiones de GPT-4 son un problema real».
Pero GPT-4 está a punto de volverse más inteligente. La subsidiaria de Microsoft, Nuance, ya está incorporando GPT-4 en un sistema de toma de notas médicas basado en datos médicos, y presentará una versión preliminar de la aplicación este verano.
Microsoft también es inversionista de Truveta y se asocia con la startup para presentar nuevos clientes a la plataforma y otros esfuerzos.
Las empresas emergentes están comenzando a incluir GPT-4 en sus ofertas. Nanduri ve a las empresas alimentando GPT-4 con sus propios conjuntos de datos para usos personalizados. Truveta, por el contrario, comercializa su plataforma como fuente de datos.
Truveta se asocia con otras empresas que crean aplicaciones sobre su sistema. Los usuarios pueden crear herramientas generativas o extractivas aprovechando los datos de Truveta, así como herramientas «discriminatorias», como modelos para predecir el cáncer. “Estamos habilitando los tres tipos de aplicaciones”, dijo Nanduri.
Los colaboradores de Truveta incluyen a Pfizer, que aprovecha la plataforma para monitorear la seguridad de las vacunas y terapias contra el COVID-19; y la empresa de Seattle Alpine Immune Sciences, que recurrió a Truveta para vincular a los pacientes con un ensayo clínico. El otoño pasado, Truveta también presentó Truveta Studio, una interfaz de datos de pacientes en tiempo real.
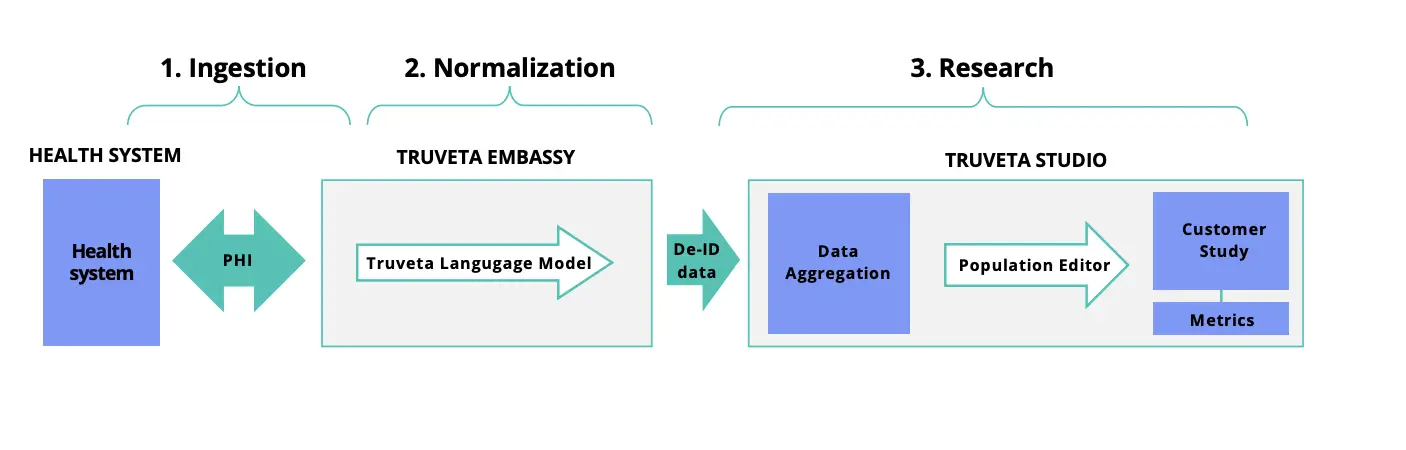
El modelo de lenguaje Truveta se construyó y entrenó durante más de dos años, comenzando con una opción de código abierto, un punto de partida común. El modelo funciona en sincronía con otros dos esfuerzos tecnológicos de la empresa: garantizar que la información sea privada y anónima; y estandarizar los datos, que están fragmentados en múltiples sistemas de salud.
Reunir esos sistemas de salud bajo un mismo techo ha sido una visión importante para Truveta desde su fundación en 2020, con Providence y otros tres sistemas médicos a bordo. La compañía recaudó $95 millones en 2021 y continúa agregando nuevos sistemas de salud a su red.
Myerson, un exejecutivo de Microsoft, ve paralelos entre el modelo de lenguaje Truveta y BloombergGPT, un gran modelo de lenguaje construido desde cero por la compañía de servicios financieros, anunciado en marzo. Bloomberg entrenó el modelo con grandes cantidades de información financiera, de forma similar a cómo el modelo de Truveta se entrena con montones de datos médicos.
“El mundo de la salud necesita un modelo preciso, y para obtener un modelo preciso, necesita los datos correctos para entrenar”, dijo Myerson.
