

Última actualización el 17 de octubre de 2021
Las arquitecturas de codificador-decodificador convencionales para traducción automática codificaban cada frase fuente en un vector de longitud fija, independientemente de su longitud, a partir del cual el decodificador generaría una traducción. Esto hizo que fuera difícil para la red neuronal hacer frente a oraciones largas, lo que esencialmente resultó en un cuello de botella en el rendimiento.
La atención de Bahdanau se propuso para abordar el cuello de botella de rendimiento de las arquitecturas de codificador-decodificador convencionales, logrando mejoras significativas sobre el enfoque convencional.
En este tutorial, descubrirá el mecanismo de atención de Bahdanau para la traducción automática neuronal.
Después de completar este tutorial, sabrá:
- De dónde deriva su nombre la atención de Bahdanau y el desafío al que se enfrenta.
- El papel de los diferentes componentes que forman parte de la arquitectura codificador-decodificador de Bahdanau.
- Las operaciones realizadas por el algoritmo de atención de Bahdanau.
Empecemos.

El mecanismo de atención de Bahdanau
Foto de Sean Oulashin, algunos derechos reservados.
Descripción general del tutorial
Este tutorial se divide en dos partes; son:
- Introducción a la atención de Bahdanau
- La arquitectura de Bahdanau
- El codificador
- El decodificador
- El algoritmo de atención de Bahdanau
Prerrequisitos
Para este tutorial, asumimos que ya está familiarizado con:
Introducción a la atención de Bahdanau
El mecanismo de atención de Bahdanau ha heredado su nombre del primer autor del artículo en el que se publicó.
Sigue el trabajo de Cho et al. (2014) y Sutskever et al. (2014), que también había empleado un marco codificador-decodificador RNN para la traducción automática neuronal, específicamente mediante la codificación de una oración fuente de longitud variable en un vector de longitud fija. Este último luego se decodificaría en una oración de destino de longitud variable.
Bahdanau y col. (2014) argumentan que esta codificación de una entrada de longitud variable en un vector de longitud fija calabazas la información de la oración fuente, independientemente de su longitud, provocando que el rendimiento de un modelo básico de codificador-decodificador se deteriore rápidamente al aumentar la longitud de la oración de entrada. El enfoque que proponen, por otro lado, reemplaza el vector de longitud fija por uno de longitud variable, para mejorar el rendimiento de traducción del modelo básico de codificador-decodificador.
La característica distintiva más importante de este enfoque del codificador-decodificador básico es que no intenta codificar una oración de entrada completa en un solo vector de longitud fija. En cambio, codifica la oración de entrada en una secuencia de vectores y elige un subconjunto de estos vectores de forma adaptativa mientras decodifica la traducción.
– Traducción automática neuronal por aprendizaje conjunto para alinear y traducir, 2014.
La arquitectura de Bahdanau
Los principales componentes que utiliza la arquitectura de codificador-decodificador de Bahdanau son los siguientes:
- $ mathbf {s} _ {t-1} $ es el estado del decodificador oculto en el paso de tiempo anterior, $ t-1 $.
- $ mathbf {c} _t $ es el vector de contexto en el paso de tiempo, $ t $. Se genera de forma única en cada paso del decodificador para generar una palabra objetivo, $ y_t $.
- $ mathbf {h} _i $ es una anotación que captura la información contenida en las palabras que forman la oración de entrada completa, $ {x_1, x_2, dots, x_T } $, con un fuerte enfoque alrededor de la $ i $ -ésima palabra del total de $ T $ palabras.
- $ alpha_ {t, i} $ es un peso valor asignado a cada anotación, $ mathbf {h} _i $, en el paso de tiempo actual, $ t $.
- $ e_ {t, i} $ es un puntaje de atención generado por un modelo de alineación, $ a (.) $, que puntúa qué tan bien coinciden $ mathbf {s} _ {t-1} $ y $ mathbf {h} _i $.
Estos componentes encuentran su uso en diferentes etapas de la arquitectura Bahdanau, que emplea un RNN bidireccional como codificador y un descodificador RNN, con un mecanismo de atención en el medio:
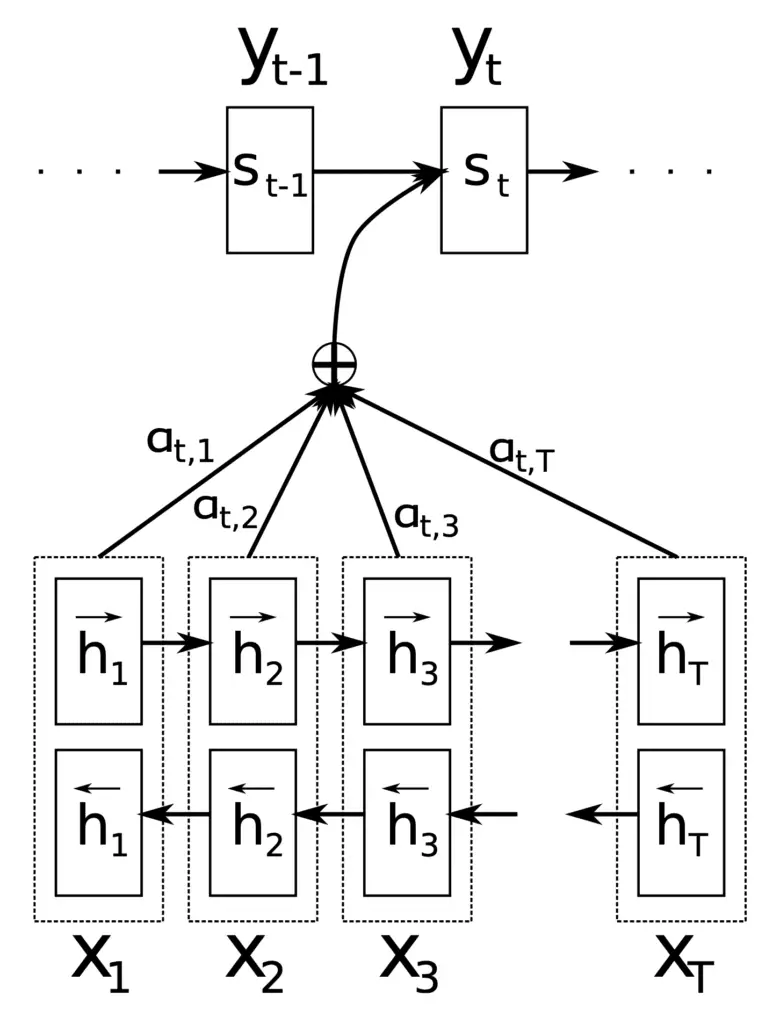
La arquitectura de Bahdanau
Tomado de «Traducción automática neuronal mediante el aprendizaje conjunto para alinear y traducir»
El codificador
La función del codificador es generar una anotación, $ mathbf {h} _i $, para cada palabra, $ x_i $, en una oración de entrada de longitud $ T $ palabras.
Para ello, Bahdanau et al. emplear un RNN bidireccional, que lee la oración de entrada en la dirección hacia adelante para producir un estado oculto hacia adelante, $ overrightarrow { mathbf {h} _i} $, y luego lee la oración de entrada en la dirección inversa para producir un estado oculto hacia atrás , $ overleftarrow { mathbf {h} _i} $. La anotación para una palabra en particular, $ x_i $, concatena los dos estados:
$$ mathbf {h} _i = left[ overrightarrow{mathbf{h}_i^T} ; ; ; overleftarrow{mathbf{h}_i^T} right]^ T $$
La idea detrás de generar cada anotación de esta manera era capturar un resumen de las palabras anteriores y posteriores.
De esta manera, la anotación $ mathbf {h} _i $ contiene los resúmenes tanto de las palabras anteriores como de las siguientes.
– Traducción automática neuronal por aprendizaje conjunto para alinear y traducir, 2014.
Las anotaciones generadas luego se pasan al decodificador para generar el vector de contexto.
El decodificador
El papel del decodificador es producir las palabras de destino enfocándose en la información más relevante contenida en la oración fuente. Para ello, hace uso de un mecanismo de atención.
Cada vez que el modelo propuesto genera una palabra en una traducción, busca (soft-) un conjunto de posiciones en una oración fuente donde se concentra la información más relevante. A continuación, el modelo predice una palabra de destino basándose en los vectores de contexto asociados con estas posiciones de origen y todas las palabras de destino generadas anteriormente.
– Traducción automática neuronal por aprendizaje conjunto para alinear y traducir, 2014.
El decodificador toma cada anotación y la envía a un modelo de alineación, $ a (.) $, Junto con el estado del decodificador oculto anterior, $ mathbf {s} _ {t-1} $. Esto genera una puntuación de atención:
$$ e_ {t, i} = a ( mathbf {s} _ {t-1}, mathbf {h} _i) $$
La función implementada por el modelo de alineación, aquí, combina $ mathbf {s} _ {t-1} $ y $ mathbf {h} _i $ mediante una operación de suma. Por ello, el mecanismo de atención implementado por Bahdanau et al. es referido como atención aditiva.
Esto se puede implementar de dos maneras, ya sea (1) aplicando una matriz de peso, $ mathbf {W} $, sobre los vectores concatenados, $ mathbf {s} _ {t-1} $ y $ mathbf {h } _i $, o (2) aplicando las matrices de peso, $ mathbf {W} _1 $ y $ mathbf {W} _2 $, a $ mathbf {s} _ {t-1} $ y $ mathbf {h} _i $ por separado:
- $$ a ( mathbf {s} _ {t-1}, mathbf {h} _i) = mathbf {v} ^ T tanh ( mathbf {W}[mathbf{h}_i ; ; ; mathbf{s}_{t-1}]) $$
- $$ a ( mathbf {s} _ {t-1}, mathbf {h} _i) = mathbf {v} ^ T tanh ( mathbf {W} _1 mathbf {h} _i + mathbf { W} _2 mathbf {s} _ {t-1}) $$
Aquí, $ mathbf {v} $, es un vector de peso.
El modelo de alineación está parametrizado como una red neuronal de retroalimentación y entrenado conjuntamente con los componentes restantes del sistema.
Posteriormente, se aplica una función softmax a cada puntaje de atención para obtener el valor de ponderación correspondiente:
$$ alpha_ {t, i} = text {softmax} (e_ {t, i}) $$
La aplicación de la función softmax esencialmente normaliza los valores de anotación a un rango entre 0 y 1 y, por lo tanto, los pesos resultantes pueden considerarse como valores de probabilidad. Cada valor de probabilidad (o peso) refleja la importancia de $ mathbf {h} _i $ y $ mathbf {s} _ {t-1} $ en la generación del siguiente estado, $ mathbf {s} _t $, y siguiente salida, $ y_t $.
Intuitivamente, esto implementa un mecanismo de atención en el decodificador. El decodificador decide las partes de la oración fuente a las que prestar atención. Al permitir que el decodificador tenga un mecanismo de atención, liberamos al codificador de la carga de tener que codificar toda la información en la oración fuente en un vector de longitud fija.
– Traducción automática neuronal por aprendizaje conjunto para alinear y traducir, 2014.
A esto le sigue finalmente el cálculo del vector de contexto como una suma ponderada de las anotaciones:
$$ mathbf {c} _t = sum ^ T_ {i = 1} alpha_ {t, i} mathbf {h} _i $$
El algoritmo de atención de Bahdanau
En resumen, el algoritmo de atención propuesto por Bahdanau et al. realiza las siguientes operaciones:
- El codificador genera un conjunto de anotaciones, $ mathbf {h} _i $, a partir de la oración de entrada.
- Estas anotaciones se envían a un modelo de alineación junto con el estado del decodificador oculto anterior. El modelo de alineación utiliza esta información para generar las puntuaciones de atención, $ e_ {t, i} $.
- Se aplica una función softmax a los puntajes de atención, normalizándolos efectivamente en valores de peso, $ alpha_ {t, i} $, en un rango entre 0 y 1.
- Estos pesos junto con las anotaciones calculadas previamente se utilizan para generar un vector de contexto, $ mathbf {c} _t $, a través de una suma ponderada de las anotaciones.
- El vector de contexto se alimenta al decodificador junto con el estado del decodificador oculto anterior y la salida anterior, para calcular la salida final, $ y_t $.
- Los pasos 2 a 6 se repiten hasta el final de la secuencia.
Bahdanau y col. había probado su arquitectura en la tarea de traducción del inglés al francés, y había informado que su modelo superaba significativamente al modelo codificador-decodificador convencional, independientemente de la longitud de la oración.
Hubo varias mejoras con respecto a la atención de Bahdanau que se había propuesto a partir de entonces, como los de Luong et al. (2015), que revisaremos en un tutorial separado.
Otras lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar.
Libros
Documentos
Resumen
En este tutorial, descubrió el mecanismo de atención de Bahdanau para la traducción automática neuronal.
Específicamente, aprendiste:
- De dónde deriva su nombre la atención de Bahdanau y el desafío al que se enfrenta.
- El papel de los diferentes componentes que forman parte de la arquitectura codificador-decodificador de Bahdanau.
- Las operaciones realizadas por el algoritmo de atención de Bahdanau.
¿Tiene usted alguna pregunta?
Haga sus preguntas en los comentarios a continuación y haré todo lo posible para responder.