
Selección del clasificador dinámico es un tipo de algoritmo de aprendizaje en conjunto para el modelado predictivo de clasificación.
La técnica consiste en ajustar varios modelos de aprendizaje de máquinas en el conjunto de datos de capacitación, y luego seleccionar el modelo que se espera que funcione mejor al hacer una predicción, basándose en los detalles específicos del ejemplo que se va a predecir.
Esto puede lograrse utilizando un modelo de vecino más cercano para ubicar ejemplos en el conjunto de datos de entrenamiento que estén más cerca del nuevo ejemplo a predecir, evaluando todos los modelos en la piscina de este vecindario y utilizando el modelo que mejor se desempeñe en el vecindario para hacer una predicción para el nuevo ejemplo.
Como tal, la selección del clasificador dinámico a menudo puede funcionar mejor que cualquier modelo individual del conjunto y proporciona una alternativa para promediar las predicciones de múltiples modelos, como es el caso de otros algoritmos de conjunto.
En este tutorial, descubrirá cómo desarrollar conjuntos de selección de clasificadores dinámicos en Python.
Después de completar este tutorial, lo sabrás:
- Los algoritmos de selección de clasificadores dinámicos eligen uno de entre muchos modelos para hacer una predicción para cada nuevo ejemplo.
- Cómo desarrollar y evaluar modelos de selección de clasificadores dinámicos para tareas de clasificación utilizando el API de aprendizaje científico.
- Cómo explorar el efecto de los hiperparámetros del modelo de selección de clasificadores dinámicos en la precisión de la clasificación.
Empecemos.

Cómo desarrollar la selección de clasificadores dinámicos en Python
Foto de Jean y Fred, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en tres partes; son:
- Selección del clasificador dinámico
- Selección de clasificadores dinámicos con Scikit-Learn
- DCS con precisión local global (OLA)
- DCS con precisión de clase local (LCA)
- Sintonización de hiperparámetros para el DCS
- Explorar k en k-Vecino más cercano
- Explorar los algoritmos para el pool de clasificaciones
Selección del clasificador dinámico
Sistemas de clasificación múltiple se refiere a un campo de algoritmos de aprendizaje de máquinas que utilizan múltiples modelos para abordar los problemas de modelado predictivo de la clasificación.
Esto incluye técnicas familiares como las técnicas de códigos de corrección de errores de uno contra uno, uno contra todos y de salida. También incluye técnicas más generales que seleccionan un modelo a utilizar dinámicamente para cada nuevo ejemplo que requiera una predicción.
Actualmente se utilizan varios enfoques para construir un SCV […] Uno de los enfoques más prometedores del SCV es la Selección Dinámica (SD), en la que los clasificadores de base se seleccionan sobre la marcha, de acuerdo con cada nueva muestra a clasificar.
– Selección del clasificador dinámico: Avances recientes y perspectivas, 2018.
Para más información sobre estos tipos de sistemas de clasificación múltiple, vea el tutorial:
Estos métodos son generalmente conocidos por el nombre de: Selección de Clasificador Dinámico, o DCS para abreviar.
- Selección del clasificador dinámico: Algoritmos que eligen uno de entre muchos modelos entrenados para hacer una predicción basada en los detalles específicos de la entrada.
Dado que en el DCS se utilizan múltiples modelos, se considera un tipo de técnica de aprendizaje en conjunto.
Los algoritmos de selección de clasificadores dinámicos generalmente implican la partición del espacio de características de entrada de alguna manera y la asignación de modelos específicos que se encargan de hacer predicciones para cada partición. Hay una variedad de diferentes algoritmos de DCS y los esfuerzos de investigación se centran principalmente en cómo evaluar y asignar clasificadores a regiones específicas del espacio de entrada.
Después de entrenar a varios alumnos individuales, el DCS selecciona dinámicamente un alumno para cada instancia de prueba. […] El DCS hace predicciones usando un solo alumno.
– Página 93, Métodos de ensamblaje: Fundamentos y algoritmos, 2012.
Un enfoque temprano y popular consiste en ajustar primero un conjunto pequeño y diverso de modelos de clasificación en el conjunto de datos de entrenamiento. Cuando se requiere una predicción, primero se utiliza un algoritmo de vecino más cercano (kNN) para encontrar los k ejemplos más similares del conjunto de datos de entrenamiento que coinciden con el ejemplo. Cada clasificador de ajuste previo en el modelo se evalúa entonces en el vecino de k ejemplos de entrenamiento y se selecciona el clasificador que mejor se desempeña para hacer una predicción para el nuevo ejemplo.
Este enfoque se conoce como «Selección del clasificador dinámico Precisión local» o DCS-LA para abreviar y fue descrito por Kevin Woods, et al. en su trabajo de 1997 titulado «Combinación de múltiples clasificadores usando estimaciones de precisión local».
La idea básica es estimar la exactitud de cada clasificador en la región local del espacio de características que rodea a una muestra de prueba desconocida, y luego utilizar la decisión del clasificador más exacto localmente.
– Combinación de múltiples clasificadores utilizando estimaciones de exactitud local, 1997.
Los autores describen dos enfoques para seleccionar un modelo de clasificador único para hacer una predicción para un ejemplo de entrada dado, son:
- Precisión local…a menudo llamado LA o Precisión Local Global (OLA).
- Precisión de clase…a menudo llamado CA o Precisión de Clase Local (LCA).
Precisión local (OLA) implica la evaluación de la precisión de la clasificación de cada modelo en el vecindario de los ejemplos de entrenamiento de k. El modelo que mejor se desempeña en este vecindario es entonces seleccionado para hacer una predicción para el nuevo ejemplo.
La OLA de cada clasificador se calcula como el porcentaje del reconocimiento correcto de las muestras en la región local.
– Selección dinámica de clasificadores. Una revisión exhaustiva, 2014.
Precisión de clase (LCA) implica utilizar cada modelo para hacer una predicción para el nuevo ejemplo y anotar la clase que se predijo. Luego, se evalúa la precisión de cada modelo en los ejemplos de entrenamiento vecinos a k y se selecciona el modelo que tiene la mejor habilidad para la clase que predijo en el nuevo ejemplo y se devuelve su predicción.
La ECV se estima para cada clasificador de base como el porcentaje de clasificaciones correctas dentro de la región local, pero considerando sólo aquellos ejemplos en los que el clasificador ha dado la misma clase que la que da para el patrón desconocido.
– Selección dinámica de clasificadores. Una revisión exhaustiva, 2014.
En ambos casos, si todos los modelos de ajuste hacen la misma predicción para un nuevo ejemplo de entrada, entonces la predicción se devuelve directamente.
Ahora que estamos familiarizados con el DCS y el algoritmo DCS-LA, veamos cómo podemos usarlo en nuestros propios proyectos de modelado predictivo de clasificación.
Selección de clasificadores dinámicos con Scikit-Learn
La Biblioteca de Selección de Conjunto Dinámico o DESlib para abreviar es una biblioteca de código abierto de Python que proporciona una implementación de muchos algoritmos diferentes de selección de clasificadores dinámicos.
DESlib es una biblioteca de aprendizaje de conjuntos fácil de usar, centrada en la aplicación de las técnicas más avanzadas de clasificación dinámica y selección de conjuntos.
Primero, podemos instalar la biblioteca DESlib usando el administrador de paquetes pip.
Una vez instalada, podemos confirmar que la biblioteca se instaló correctamente y está lista para ser usada cargando la biblioteca e imprimiendo la versión instalada.
|
# Verificar la versión de Deslib importación deslib imprimir(deslib.La versión…) |
Ejecutando el script se imprimirá tu versión de la biblioteca DESlib que has instalado.
Tu versión debería ser la misma o más alta. Si no, debe actualizar su versión de la biblioteca DESlib.
El DESlib proporciona una implementación del algoritmo DCS-LA con cada técnica de selección de clasificadores a través de las clases OLA y LCA respectivamente.
Cada clase puede utilizarse como un modelo de aprendizaje científico directamente, lo que permite utilizar directamente el conjunto completo de la preparación de datos de aprendizaje científico, los conductos de modelización y las técnicas de evaluación del modelo.
Ambas clases utilizan un algoritmo de vecino k-nearest para seleccionar el vecino con un valor por defecto de k=7.
Se utiliza un conjunto de árboles de decisión de agregación de bootstrap (embolsado) como el conjunto de modelos de clasificación considerados para cada clasificación que se hace por defecto, aunque esto puede cambiarse estableciendo «clasificadores_de_piscina«a una lista de modelos.
Podemos usar la función make_classification() para crear un problema de clasificación binaria sintética con 10.000 ejemplos y 20 características de entrada.
|
# Conjunto de datos de clasificación binaria sintética de sklearn.conjuntos de datos importación hacer_clasificación # Definir el conjunto de datos X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # resumir el conjunto de datos imprimir(X.forma, y.forma) |
Ejecutando el ejemplo se crea el conjunto de datos y se resume la forma de los componentes de entrada y salida.
Ahora que estamos familiarizados con la API DESlib, veamos cómo usar cada algoritmo DCS-LA.
DCS con precisión local global (OLA)
Podemos evaluar un modelo DCS-LA usando la precisión local general en el conjunto de datos sintéticos.
En este caso, usaremos hiperparámetros de modelos por defecto, incluyendo árboles de decisión empaquetados como el conjunto de modelos clasificadores y un k=7 para la selección del vecindario local al hacer una predicción.
Evaluaremos el modelo usando la validación cruzada estratificada k-pliegue repetida con tres repeticiones y 10 pliegues. Informaremos la media y la desviación estándar de la precisión del modelo en todas las repeticiones y pliegues.
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Evaluar la selección del clasificador dinámico DCS-LA con la precisión local global de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de deslib.dcs.ola importación OLA # Definir el conjunto de datos X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Definir el modelo modelo = OLA() # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) # Informe de rendimiento imprimir(«Precisión media: %.3f (%.3f) % (significa(n_puntuaciones), std(n_puntuaciones))) |
La ejecución del ejemplo informa de la precisión de la media y la desviación estándar del modelo.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el DCS-LA con OLA e hiperparámetros por defecto alcanza una precisión de clasificación de alrededor del 88,3 por ciento.
|
Precisión media: 0,883 (0,012) |
También podemos usar el modelo DCS-LA con OLA como modelo final y hacer predicciones para la clasificación.
Primero, el modelo se ajusta a todos los datos disponibles, luego el predecir() se puede llamar a la función para hacer predicciones sobre nuevos datos.
El siguiente ejemplo lo demuestra en nuestro conjunto de datos de clasificación binaria.
|
# Hacer una predicción con el DCS-LA usando la precisión local general de sklearn.conjuntos de datos importación make_classification de deslib.dcs.ola importación OLA # Definir el conjunto de datos X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Definir el modelo modelo = OLA() # Encajar el modelo en todo el conjunto de datos modelo.encajar(X, y) # hacer una sola predicción fila = [[0.2929949,–4.21223056,–1.288332,–2.17849815,–0.64527665,2.58097719,0.28422388,–7.1827928,–1.91211104,2.73729512,0.81395695,3.96973717,–2.66939799,3.34692332,4.19791821,0.99990998,–0.30201875,–4.43170633,–2.82646737,0.44916808] yhat = modelo.predecir([[fila]) imprimir(Clase prevista: %d’. % yhat[[0]) |
La ejecución del ejemplo se ajusta al modelo DCS-LA con OLA en todo el conjunto de datos y luego se utiliza para hacer una predicción en una nueva fila de datos, como podríamos hacer al utilizar el modelo en una aplicación.
Ahora que estamos familiarizados con el uso del DCS-LA con OLA, veamos el método LCA.
DCS con precisión de clase local (LCA)
Podemos evaluar un modelo DCS-LA usando la precisión de clase local en el conjunto de datos sintéticos.
En este caso, usaremos hiperparámetros de modelos por defecto, incluyendo árboles de decisión empaquetados como el conjunto de modelos clasificadores y un k=7 para la selección del vecindario local al hacer una predicción.
Evaluaremos el modelo usando la validación cruzada estratificada k-pliegue repetida con tres repeticiones y 10 pliegues. Informaremos la media y la desviación estándar de la precisión del modelo en todas las repeticiones y pliegues.
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Evaluar la selección del clasificador dinámico DCS-LA usando la precisión de la clase local de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de deslib.dcs.lca importación LCA # Definir el conjunto de datos X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Definir el modelo modelo = LCA() # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Evaluar el modelo n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) # Informe de rendimiento imprimir(«Precisión media: %.3f (%.3f) % (significa(n_puntuaciones), std(n_puntuaciones))) |
La ejecución del ejemplo informa de la precisión de la media y la desviación estándar del modelo.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el DCS-LA con LCA e hiperparámetros por defecto alcanza una precisión de clasificación de alrededor del 92,2 por ciento.
|
Precisión media: 0,922 (0,007) |
También podemos usar el modelo DCS-LA con LCA como modelo final y hacer predicciones para la clasificación.
Primero, el modelo se ajusta a todos los datos disponibles, luego el predecir() se puede llamar a la función para hacer predicciones sobre nuevos datos.
El siguiente ejemplo lo demuestra en nuestro conjunto de datos de clasificación binaria.
|
# Hacer una predicción con el DCS-LA usando la precisión de la clase local de sklearn.conjuntos de datos importación make_classification de deslib.dcs.lca importación LCA # Definir el conjunto de datos X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Definir el modelo modelo = LCA() # Encajar el modelo en todo el conjunto de datos modelo.encajar(X, y) # hacer una sola predicción fila = [[0.2929949,–4.21223056,–1.288332,–2.17849815,–0.64527665,2.58097719,0.28422388,–7.1827928,–1.91211104,2.73729512,0.81395695,3.96973717,–2.66939799,3.34692332,4.19791821,0.99990998,–0.30201875,–4.43170633,–2.82646737,0.44916808] yhat = modelo.predecir([[fila]) imprimir(Clase prevista: %d’. % yhat[[0]) |
La ejecución del ejemplo se ajusta al modelo DCS-LA con LCA en todo el conjunto de datos y luego se utiliza para hacer una predicción en una nueva fila de datos, como podríamos hacer al utilizar el modelo en una aplicación.
Ahora que estamos familiarizados con el uso de la API de scikit-learn para evaluar y usar los modelos DCS-LA, veamos la configuración del modelo.
Sintonización de hiperparámetros para el DCS
En esta sección, examinaremos más de cerca algunos de los hiperparámetros que debería considerar para ajustar el modelo DCS-LA y su efecto en el rendimiento del modelo.
Hay muchos hiperparámetros que podemos mirar para el DCS-LA, aunque en este caso, miraremos el valor de k en el modelo del vecino más cercano usado en la evaluación local de los modelos, y cómo usar un conjunto personalizado de clasificadores.
Usaremos el DCS-LA con OLA como base para estos experimentos, aunque la elección del método específico es arbitraria.
Explorar k en k-Vecino más cercano
La configuración del algoritmo del vecino más cercano es crítica para el modelo DCS-LA ya que define el alcance del vecindario en el que cada clasificador es considerado para la selección.
El k controla el tamaño del vecindario y es importante fijarlo en un valor apropiado para su conjunto de datos, específicamente la densidad de las muestras en el espacio de las características. Un valor demasiado pequeño significará que los ejemplos relevantes del conjunto de datos pueden ser excluidos del vecindario, mientras que los valores demasiado grandes pueden significar que la señal está siendo lavada por demasiados ejemplos.
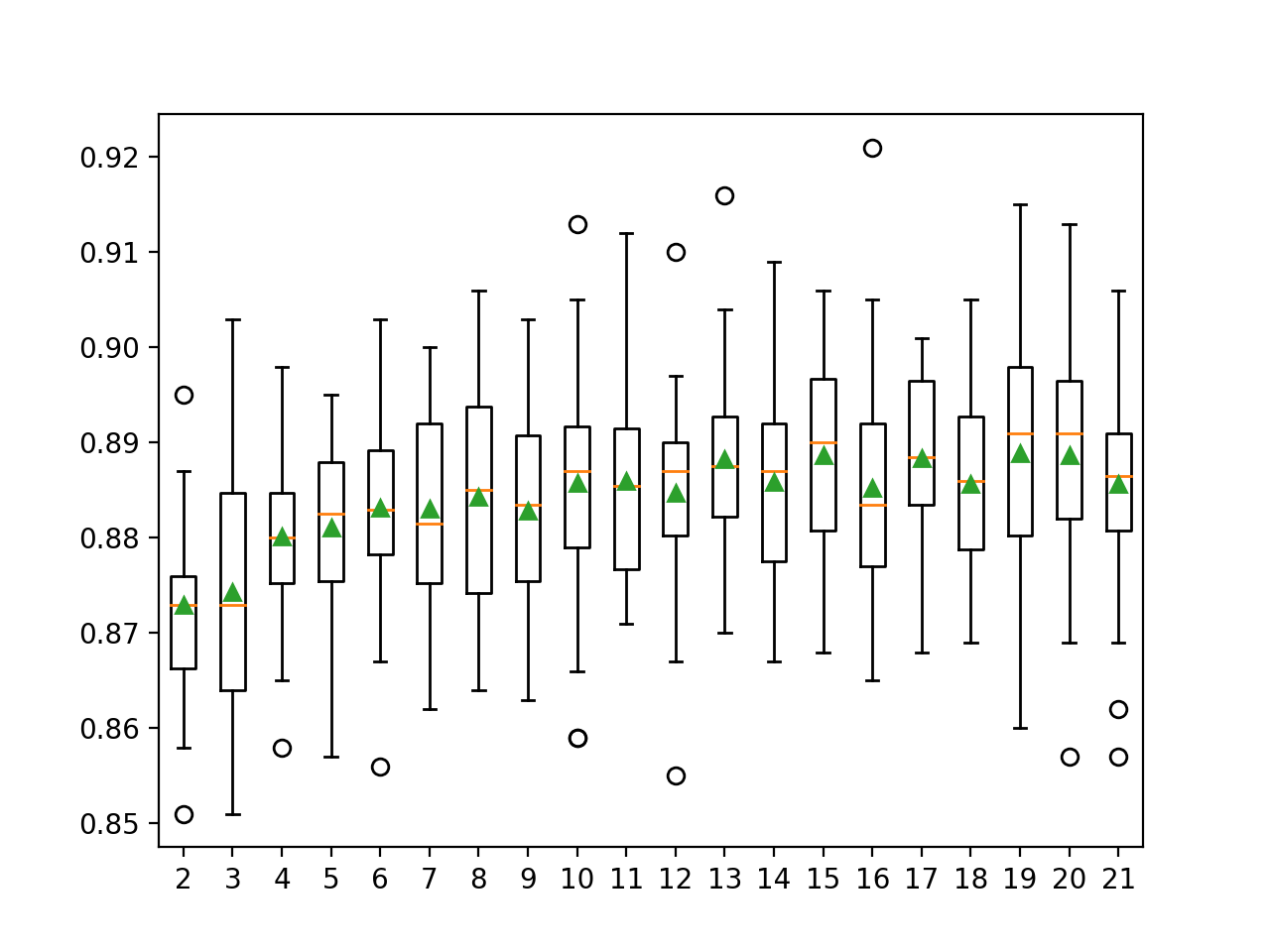
En el ejemplo que figura a continuación se explora la precisión de la clasificación del DCS-LA con OLA con valores k de 2 a 21.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# Explorar k en knn para DCS-LA con una precisión local total de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de deslib.dcs.ola importación OLA de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() para n en rango(2,22): modelos[[str(n)] = OLA(k=n) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
Ejecutando el ejemplo primero reporta la precisión media para cada tamaño de vecindario configurado.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que la precisión aumenta con el tamaño del vecindario, quizás hasta k=13 o k=14, donde parece nivelarse.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
>2 0.873 (0.009) >3 0.874 (0.013) >4 0.880 (0.009) >5 0.881 (0.009) >6 0.883 (0.010) >7 0.883 (0.011) >8 0.884 (0.012) >9 0.883 (0.010) >10 0.886 (0.012) >11 0.886 (0.011) >12 0.885 (0.010) >13 0.888 (0.010) >14 0.886 (0.009) >15 0.889 (0.010) >16 0.885 (0.012) >17 0.888 (0.009) >18 0.886 (0.010) >19 0.889 (0.012) >20 0.889 (0.011) >21 0.886 (0.011) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada tamaño de vecindario configurado.
Podemos ver la tendencia general de aumentar el rendimiento del modelo y el valor k antes de llegar a una meseta.
Gráficos de caja y bigote de las distribuciones de precisión para los valores k en DCS-LA con OLA
Explorar los algoritmos para el pool de clasificaciones
La elección de los algoritmos utilizados en la piscina para el DCS-LA es otro importante hiperparámetro.
Por defecto, se utilizan árboles de decisión empaquetados, ya que ha demostrado ser un enfoque eficaz en una serie de tareas de clasificación. No obstante, se puede considerar la posibilidad de utilizar un conjunto personalizado de clasificadores.
Esto requiere primero definir una lista de modelos de clasificadores para usar y ajustar cada uno en el conjunto de datos de entrenamiento. Lamentablemente, esto significa que los métodos de evaluación del modelo de validación cruzada automática de k-fold en scikit-learn no pueden utilizarse en este caso. En su lugar, utilizaremos una división de prueba de entrenamiento para que podamos ajustar el conjunto de clasificadores manualmente en el conjunto de datos de entrenamiento.
La lista de clasificadores de ajuste puede entonces especificarse a la clase OLA (o LCA) a través de la «clasificadores_de_piscina«argumento». En este caso, usaremos un pool que incluye regresión logística, un árbol de decisiones y un clasificador Bayes ingenuo.
El ejemplo completo de la evaluación del DCS-LA con OLA y un conjunto personalizado de clasificadores en el conjunto de datos sintéticos se enumera a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# Evaluar el DCS-LA usando OLA con un conjunto personalizado de algoritmos de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación prueba_de_trenes_split de sklearn.métrica importación accuracy_score de deslib.dcs.ola importación OLA de sklearn.modelo_lineal importación LogisticRegression de sklearn.árbol importación DecisionTreeClassifier de sklearn.naive_bayes importación GaussianNB X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Dividir el conjunto de datos en trenes y conjuntos de pruebas X_tren, X_test, y_tren, y_test = prueba_de_trenes_split(X, y, tamaño_de_prueba=0.5, estado_aleatorio=1) # Definir los clasificadores para usar en la piscina clasificadores = [[ LogisticRegression(), DecisionTreeClassifier(), GaussianNB()] # Encajar cada clasificador en el set de entrenamiento para c en clasificadores: c.encajar(X_tren, y_tren) # Definir el modelo DCS-LA modelo = OLA(clasificadores_de_piscina=clasificadores) # Encaja con el modelo modelo.encajar(X_tren, y_tren) # hacer predicciones en el conjunto de pruebas yhat = modelo.predecir(X_test) # Evaluar las predicciones puntuación = accuracy_score(y_test, yhat) imprimir(Precisión: %.3f’. % (puntuación)) |
Ejecutando el ejemplo primero se informa de la precisión media para el modelo con el conjunto personalizado de clasificadores.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el modelo alcanzó una precisión de alrededor del 91,2 por ciento.
Para adoptar el modelo de DCS, debe funcionar mejor que cualquier otro modelo de contribución. De lo contrario, simplemente usaríamos el modelo contributivo que funciona mejor en su lugar.
Podemos comprobarlo evaluando el rendimiento de cada clasificador contribuyente en el conjunto de pruebas.
|
... # Evaluar los modelos de contribución para c en clasificadores: yhat = c.predecir(X_test) puntuación = accuracy_score(y_test, yhat) imprimir(«>%s: %.3f % (c.La clase….__nombre__, puntuación)) |
A continuación figura el ejemplo actualizado del DCS-LA con un conjunto personalizado de clasificadores que también se evalúan independientemente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# Evaluar el DCS-LA usando OLA con un conjunto personalizado de algoritmos de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación prueba_de_trenes_split de sklearn.métrica importación accuracy_score de deslib.dcs.ola importación OLA de sklearn.modelo_lineal importación LogisticRegression de sklearn.árbol importación DecisionTreeClassifier de sklearn.naive_bayes importación GaussianNB # Definir el conjunto de datos X, y = make_classification(n_muestras=10000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Dividir el conjunto de datos en trenes y conjuntos de pruebas X_tren, X_test, y_tren, y_test = prueba_de_trenes_split(X, y, tamaño_de_prueba=0.5, estado_aleatorio=1) # Definir los clasificadores para usar en la piscina clasificadores = [[ LogisticRegression(), DecisionTreeClassifier(), GaussianNB()] # Encajar cada clasificador en el set de entrenamiento para c en clasificadores: c.encajar(X_tren, y_tren) # Definir el modelo DCS-LA modelo = OLA(clasificadores_de_piscina=clasificadores) # Encaja con el modelo modelo.encajar(X_tren, y_tren) # hacer predicciones en el conjunto de pruebas yhat = modelo.predecir(X_test) # Evaluar las predicciones puntuación = accuracy_score(y_test, yhat) imprimir(Precisión: %.3f’. % (puntuación)) # Evaluar los modelos de contribución para c en clasificadores: yhat = c.predecir(X_test) puntuación = accuracy_score(y_test, yhat) imprimir(«>%s: %.3f % (c.La clase….__nombre__, puntuación)) |
Al ejecutar el ejemplo primero se informa de la precisión media del modelo con el conjunto de clasificadores personalizados y la precisión de cada modelo contribuyente.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que de nuevo, el DCS-LA alcanza una precisión de alrededor del 91,3 por ciento, que es mejor que cualquier modelo que contribuya.
|
Precisión: 0,913 >Regresión logística: 0.878 > Clasificador de Árbol de Decisión: 0.884 >GaussianNB: 0.873 |
Más lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar en él.
Tutoriales relacionados
Documentos
Libros
APIs
Resumen
En este tutorial, descubriste cómo desarrollar conjuntos de selección de clasificadores dinámicos en Python.
Específicamente, aprendiste:
- Los algoritmos de selección de clasificadores dinámicos eligen uno de entre muchos modelos para hacer una predicción para cada nuevo ejemplo.
- Cómo desarrollar y evaluar modelos de selección de clasificadores dinámicos para tareas de clasificación utilizando el API de aprendizaje científico.
- Cómo explorar el efecto de los hiperparámetros del modelo de selección de clasificadores dinámicos en la precisión de la clasificación.
¿Tiene alguna pregunta?
Haga sus preguntas en los comentarios de abajo y haré lo posible por responder.