
La visualización de datos proporciona una visión de la distribución y las relaciones entre las variables de un conjunto de datos.
Esta información puede ser útil para seleccionar las técnicas de preparación de datos que se aplicarán antes de la modelización y los tipos de algoritmos que pueden ser más adecuados para los datos.
Seaborn es una biblioteca de visualización de datos para Python que se ejecuta sobre la popular biblioteca de visualización de datos Matplotlib, aunque proporciona una interfaz sencilla y gráficos de mejor aspecto estético.
En este tutorial, descubrirá una suave introducción a la visualización de datos de Seaborn para el aprendizaje de la máquina.
Después de completar este tutorial, lo sabrás:
- Cómo resumir la distribución de las variables utilizando gráficos de barras, histogramas y diagramas de cajas y bigotes.
- Cómo resumir las relaciones utilizando gráficos de líneas y gráficos de dispersión.
- Cómo comparar la distribución y las relaciones de las variables para diferentes valores de clase en la misma trama.
Empecemos.

Cómo utilizar la visualización de datos de Seaborn para el aprendizaje automático
Foto de Martin Pettitt, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en seis partes; son:
- Biblioteca de Visualización de Datos de Seaborn
- Gráficas de líneas
- Gráficos de barras
- Gráficos de Histograma
- Parcelas de cajas y bigotes
- Parcelas de dispersión
Biblioteca de Visualización de Datos de Seaborn
La biblioteca principal para Python se llama Matplotlib.
Seaborn es una librería de gráficos que ofrece una interfaz más sencilla, con valores por defecto sensatos para los gráficos necesarios para el aprendizaje de la máquina, y lo más importante, los gráficos son estéticamente más atractivos que los de Matplotlib.
Seaborn requiere que Matplotlib se instale primero.
Puedes instalar Matplotlib directamente usando pip, de la siguiente manera:
|
sudo pip instalar matplotlib |
Una vez instalado, puede confirmar que la biblioteca puede ser cargada y utilizada imprimiendo el número de versión, de la siguiente manera:
|
# matplotlib importación matplotlib imprimir(‘matplotlib: %s’ % matplotlib.La versión…) |
Ejecutando el ejemplo se imprime la versión actual de la biblioteca Matplotlib.
A continuación, se puede instalar la biblioteca de Seaborn, también usando pip:
Una vez instalado, también podemos confirmar que la biblioteca puede ser cargada y utilizada imprimiendo el número de versión, como sigue:
|
# Seaborn importación Seaborn imprimir(«Seaborn: %s % Seaborn.La versión…) |
Ejecutando el ejemplo se imprime la versión actual de la biblioteca de Seaborn.
Para crear las parcelas de Seaborn, debe importar la biblioteca de Seaborn y llamar a las funciones para crear las parcelas.
Es importante que las funciones de trazado de Seaborn esperen que los datos se proporcionen en forma de Pandas DataFrames. Esto significa que si estás cargando tus datos desde archivos CSV, debes usar funciones de Pandas como read_csv() para cargar tus datos como un DataFrame. Al trazar, las columnas se pueden especificar a través del nombre del DataFrame o el índice de la columna.
Para mostrar la trama, puedes llamar a la función show() en la biblioteca Matplotlib.
|
... # mostrar la trama pyplot.mostrar() |
Alternativamente, los gráficos pueden ser guardados en un archivo, como un archivo de imagen con formato PNG. La función savefig() Matplotlib puede ser usada para guardar imágenes.
|
... # Salvar la trama pyplot.savefig(‘mi_imagen.png’) |
Ahora que tenemos instalado el Seaborn, veamos algunas tramas comunes que podemos necesitar cuando trabajamos con datos de aprendizaje de máquinas.
Gráficas de líneas
Se suele utilizar un gráfico lineal para presentar las observaciones recogidas a intervalos regulares.
El eje x representa el intervalo regular, como el tiempo. El eje y muestra las observaciones, ordenadas por el eje x y conectadas por una línea.
Se puede crear un diagrama de líneas en Seaborn llamando a la función lineplot() y pasando los datos del eje x para el intervalo regular, y del eje y para las observaciones.
Podemos demostrar un trazado de líneas usando un conjunto de datos de series temporales de ventas mensuales de coches.
El conjunto de datos tiene dos columnas: “Mes«y»Ventas.” El mes se usará como el eje x y las ventas se graficarán en el eje y.
|
... # Crear un trazado de líneas lineplot(x=«Mes»…, y=«Ventas»…, datos=dataset) |
A continuación se muestra el ejemplo completo.
|
# Gráfica de líneas de un conjunto de datos de series de tiempo de pandas importación read_csv de Seaborn importación lineplot de matplotlib importación pyplot # Cargar el conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv’ dataset = read_csv(url, encabezado=0) # Crear un trazado de líneas lineplot(x=«Mes»…, y=«Ventas»…, datos=dataset) # mostrar la trama pyplot.mostrar() |
Al ejecutar el ejemplo primero se carga el conjunto de datos de la serie de tiempo y se crea un gráfico lineal de los datos, que muestra claramente una tendencia y una estacionalidad en los datos de ventas.
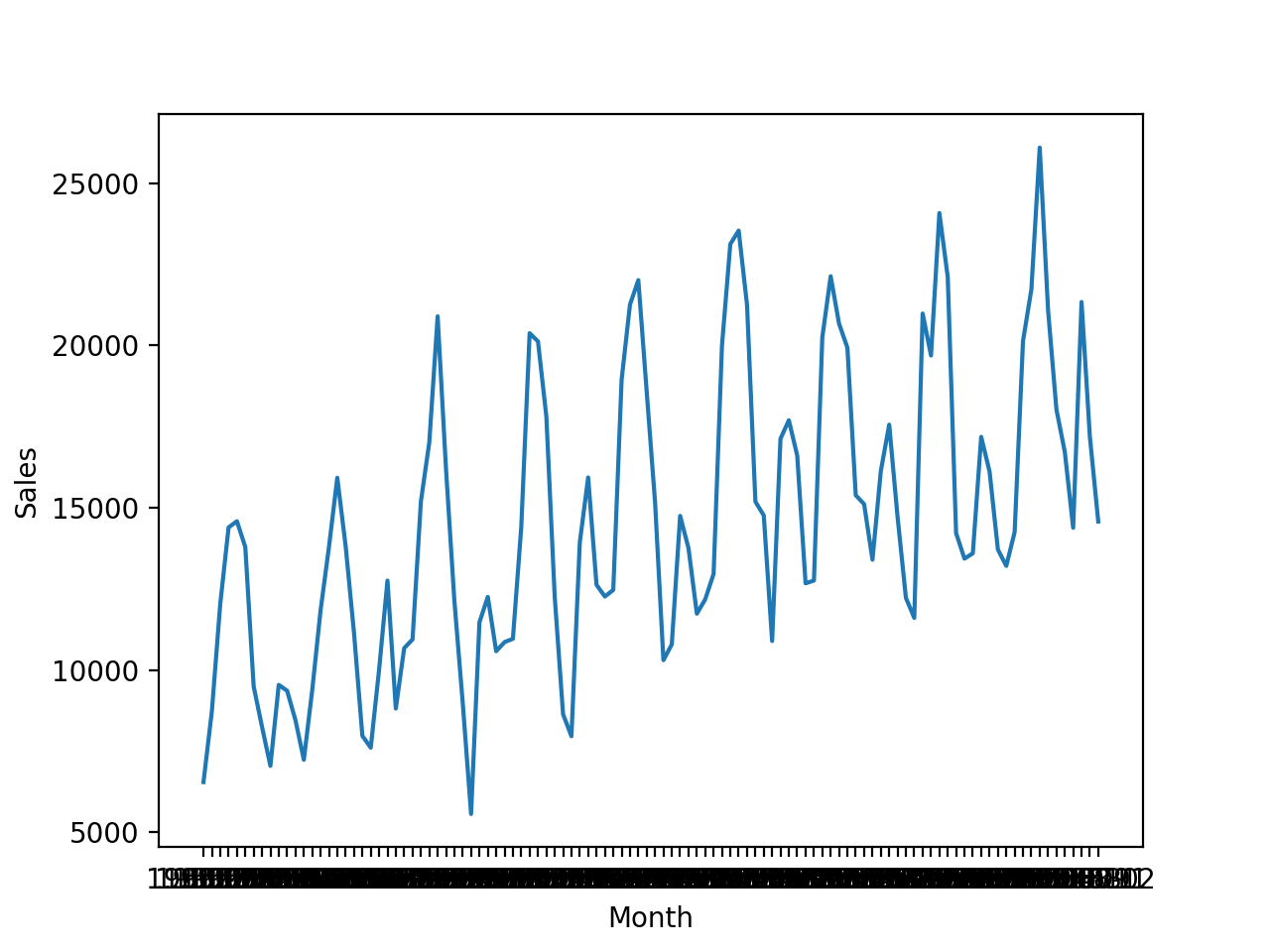
Gráfica de líneas de un conjunto de datos de series temporales
Para más grandes ejemplos de tramas de líneas con Seaborn, ver: Visualización de relaciones estadísticas.
Gráficos de barras
Se suele utilizar un gráfico de barras para presentar las cantidades relativas de múltiples categorías.
El eje X representa las categorías que están espaciadas uniformemente. El eje y representa la cantidad para cada categoría y se dibuja como una barra desde la línea de base hasta el nivel apropiado en el eje y.
Se puede crear un gráfico de barras en Seaborn llamando a la función countplot() y pasando los datos.
Demostraremos un gráfico de barras con una variable del conjunto de datos de clasificación del cáncer de mama que está compuesto por variables de entrada categóricas.
Sólo trazaremos una variable, en este caso, la primera variable que es el rango de edad.
|
... # Crear un trazado de líneas countplot(x=0, datos=dataset) |
A continuación se muestra el ejemplo completo.
|
# Gráfico de barras de una variable categórica de pandas importación read_csv de Seaborn importación countplot de matplotlib importación pyplot # Cargar el conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv’ dataset = read_csv(url, encabezado=Ninguno) # Crear un gráfico de barras countplot(x=0, datos=dataset) # mostrar la trama pyplot.mostrar() |
Al ejecutar el ejemplo primero se carga el conjunto de datos sobre el cáncer de mama y se crea un gráfico de barras de los datos, que muestra cada grupo de edad y el número de individuos (muestras) que entran en el grupo de alcance.
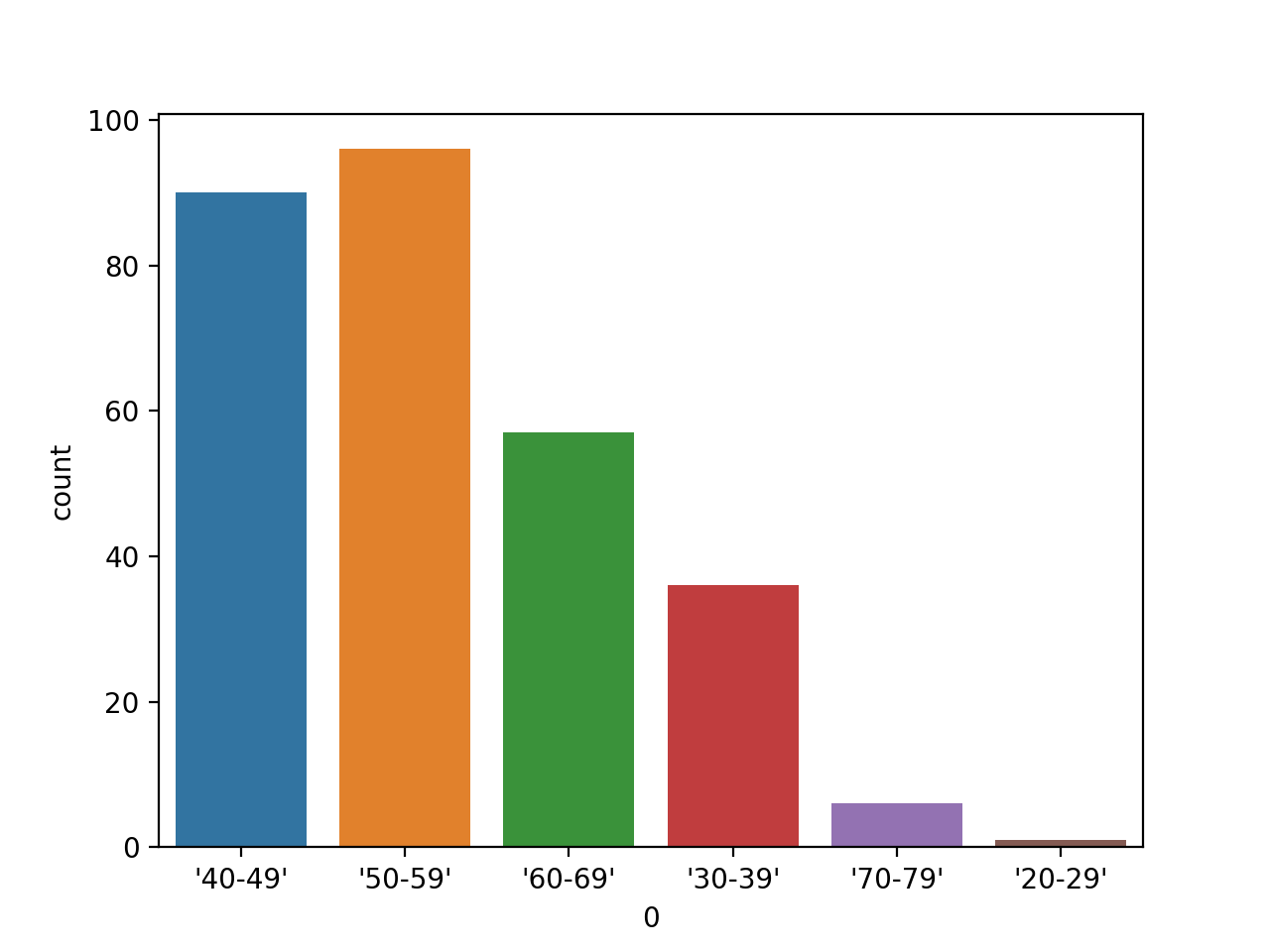
Gráfico de barras de la variable categórica del rango de edad
También podríamos querer trazar los recuentos de cada categoría para una variable, como la primera variable, contra la etiqueta de la clase.
Esto puede lograrse utilizando el countplot() y especificando la variable de clase (índice de la columna 9) mediante la función «hue«argumento», como sigue:
|
... # Crear un gráfico de barras countplot(x=0, hue=9, datos=dataset) |
A continuación se muestra el ejemplo completo.
|
# Gráfico de barras de una variable categórica contra una variable de clase de pandas importación read_csv de Seaborn importación countplot de matplotlib importación pyplot # Cargar el conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv’ dataset = read_csv(url, encabezado=Ninguno) # Crear un gráfico de barras countplot(x=0, hue=9, datos=dataset) # mostrar la trama pyplot.mostrar() |
Al ejecutar el ejemplo primero se carga el conjunto de datos sobre el cáncer de mama y se crea un gráfico de barras de los datos, que muestra cada grupo de edad y el número de individuos (muestras) que entran dentro de cada grupo separados por las dos etiquetas de clase del conjunto de datos.
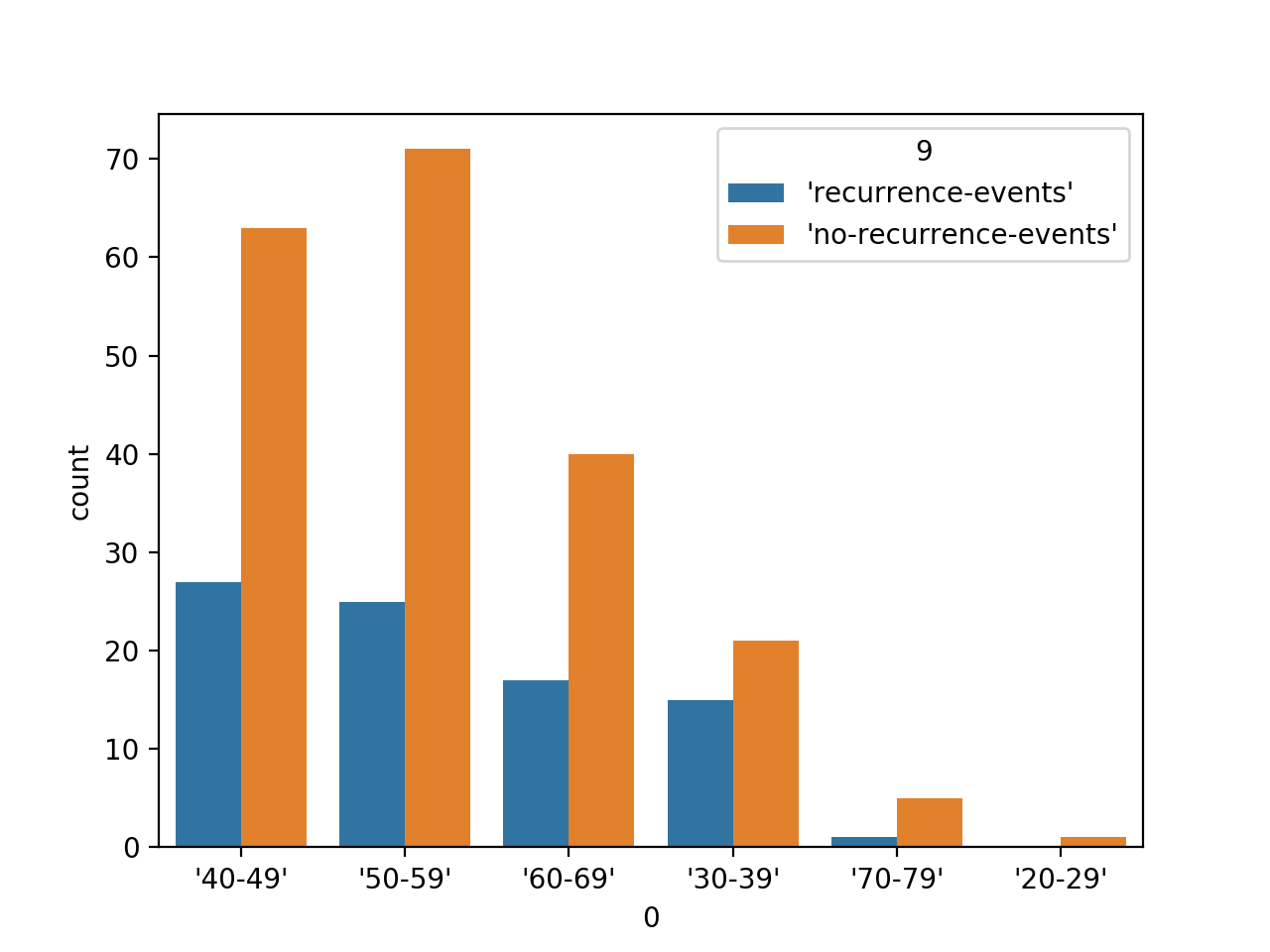
Gráfico de barras del rango de edad Variable categórica por etiqueta de clase
Para más ejemplos de gráficos de barras con Seaborn, ver: Gráficos con datos categóricos.
Gráficos de Histograma
Por lo general, se utiliza una gráfica de histograma para resumir la distribución de una muestra de datos numéricos.
El eje x representa los contenedores o intervalos discretos para las observaciones. Por ejemplo, las observaciones con valores entre 1 y 10 pueden dividirse en cinco compartimentos, los valores [1,2] se asignaría al primer contenedor, [3,4] se asignaría al segundo recipiente, y así sucesivamente.
El eje y representa la frecuencia o recuento del número de observaciones en el conjunto de datos que pertenecen a cada bin.
Esencialmente, una muestra de datos se transforma en un gráfico de barras en el que cada categoría en el eje x representa un intervalo de valores de observación.
Se puede crear un histograma en Seaborn llamando a la función distplot() y pasando la variable.
Demostraremos un diagrama de caja con una variable numérica del conjunto de datos de la clasificación de la diabetes. Sólo trazaremos una variable, en este caso, la primera variable, que es el número de veces que una paciente estuvo embarazada.
|
... # Crear un gráfico de histograma distplot(dataset[[[[0]]) |
A continuación se muestra el ejemplo completo.
|
# Gráfica de histograma de una variable numérica de pandas importación read_csv de Seaborn importación distplot de matplotlib importación pyplot # Cargar el conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv’ dataset = read_csv(url, encabezado=Ninguno) # Crear un gráfico de histograma distplot(dataset[[[[0]]) # mostrar la trama pyplot.mostrar() |
Al ejecutar el ejemplo primero se carga el conjunto de datos de la diabetes y se crea una gráfica de histograma de la variable, mostrando la distribución de los valores con un corte duro a cero.
El gráfico muestra tanto el histograma (recuento de recipientes) como una estimación suave de la función de densidad de probabilidad.
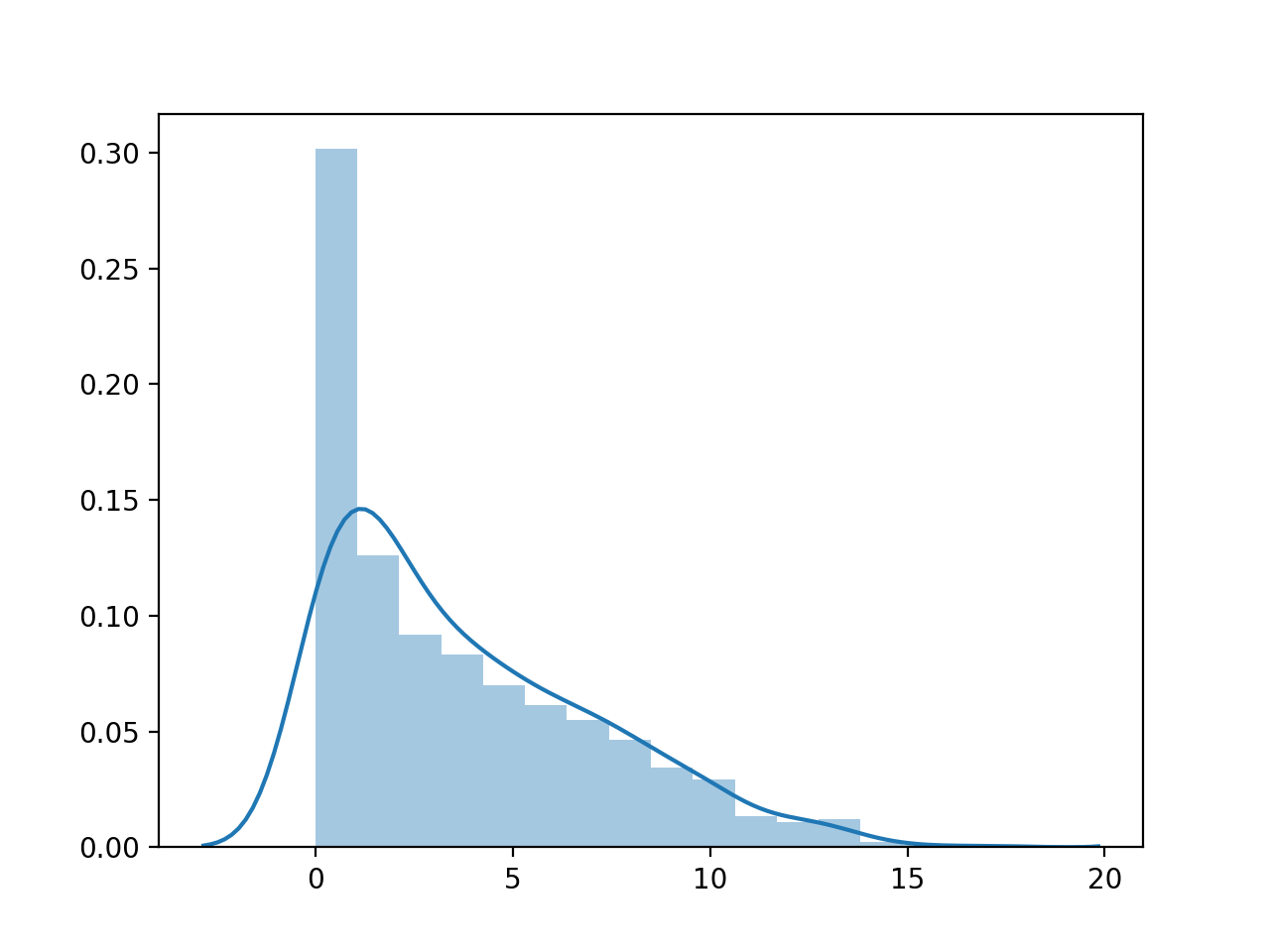
Histograma de la variable numérica del número de veces que está embarazada
Para más grandes ejemplos de tramas de histogramas con Seaborn, ver: Visualizar la distribución de un conjunto de datos.
Parcelas de cajas y bigotes
Para resumir la distribución de una muestra de datos se suele utilizar un gráfico de caja y bigote, o boxplot para abreviar.
El eje x se utiliza para representar la muestra de datos, donde se pueden dibujar múltiples boxplots uno al lado del otro en el eje x si se desea.
El eje y representa los valores de observación. Se dibuja un recuadro para resumir el 50 por ciento medio del conjunto de datos, comenzando en la observación en el percentil 25 y terminando en el percentil 75. Esto se llama rango intercuartil, o IQR. La mediana, o 50º percentil, se dibuja con una línea.
Se dibujan líneas llamadas bigotes que se extienden desde ambos extremos del cuadro, calculadas como (1,5 * IQR) para demostrar el rango esperado de valores sensibles en la distribución. Las observaciones fuera de los bigotes pueden ser atípicas y se dibujan con pequeños círculos.
Se puede crear un boxplot en Seaborn llamando a la función boxplot() y pasando los datos.
Demostraremos un diagrama de caja con una variable numérica del conjunto de datos de la clasificación de la diabetes. Sólo trazaremos una variable, en este caso, la primera variable, que es el número de veces que una paciente estuvo embarazada.
|
... # Crear una trama de caja y bigote Boxplot(x=0, datos=dataset) |
A continuación se muestra el ejemplo completo.
|
# Gráfica de caja y bigote de una variable numérica de pandas importación read_csv de Seaborn importación Boxplot de matplotlib importación pyplot # Cargar el conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv’ dataset = read_csv(url, encabezado=Ninguno) # Crear una trama de caja y bigote Boxplot(x=0, datos=dataset) # mostrar la trama pyplot.mostrar() |
Al ejecutar el ejemplo primero se carga el conjunto de datos de la diabetes y se crea un gráfico de caja de la primera variable de entrada, que muestra la distribución del número de veces que los pacientes estuvieron embarazados.
Podemos ver la mediana justo por encima de 2,5 veces, algunos valores atípicos alrededor de 15 veces (¡wow!).
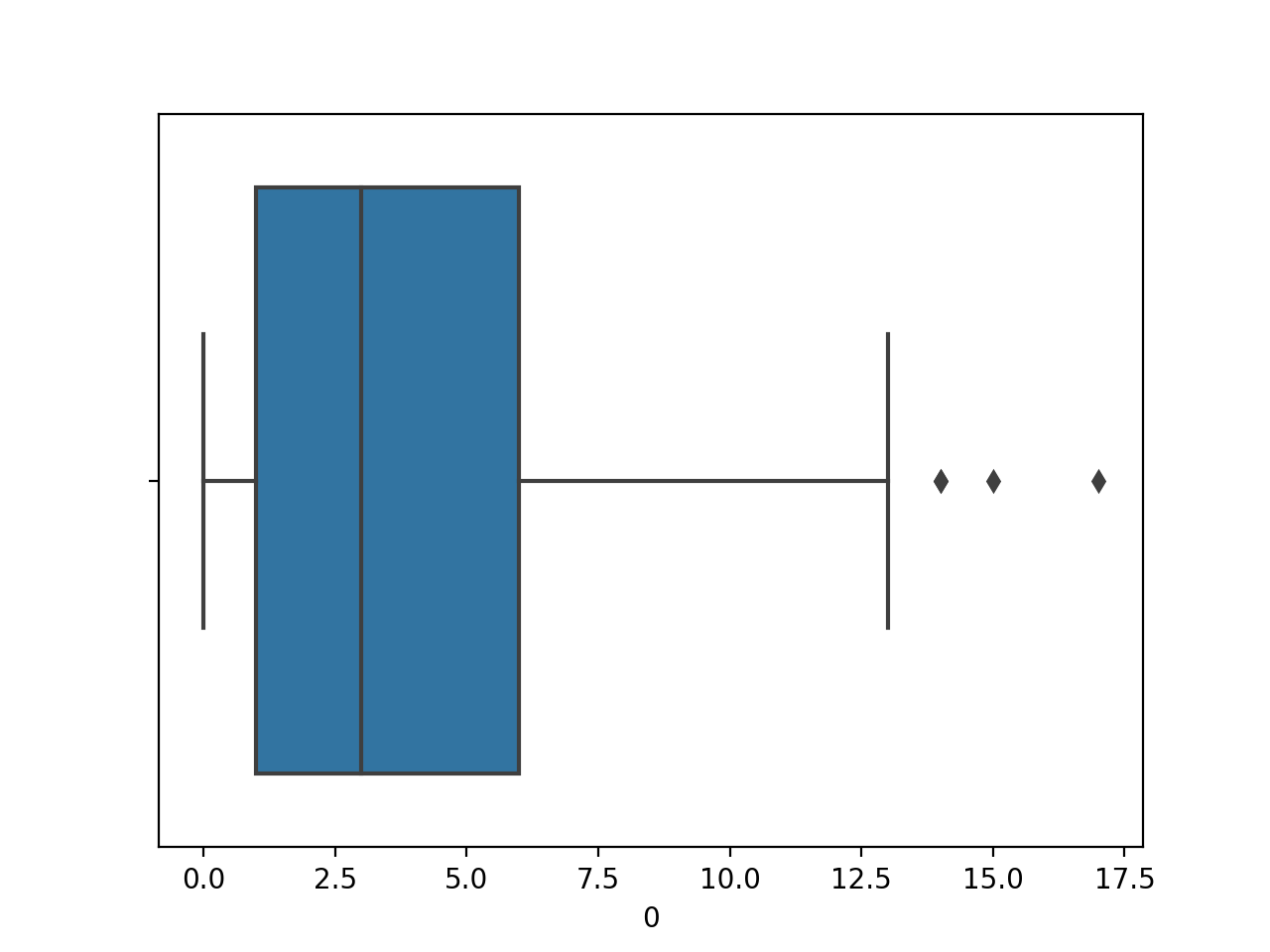
Cuadro y diagrama de bigote de la variable numérica del número de veces que está embarazada
También podríamos querer graficar la distribución de la variable numérica para cada valor de una variable categórica, como la primera variable, contra la etiqueta de la clase.
Esto puede lograrse llamando al boxplot() y pasando la variable de clase como el eje x y la variable numérica como el eje y.
|
... # Crear una trama de caja y bigote Boxplot(x=8, y=0, datos=dataset) |
A continuación se muestra el ejemplo completo.
|
# Gráfica de caja y bigote de una variable numérica vs. etiqueta de clase de pandas importación read_csv de Seaborn importación Boxplot de matplotlib importación pyplot # Cargar el conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv’ dataset = read_csv(url, encabezado=Ninguno) # Crear una trama de caja y bigote Boxplot(x=8, y=0, datos=dataset) # mostrar la trama pyplot.mostrar() |
Al ejecutar el ejemplo primero se carga el conjunto de datos de la diabetes y se crea un cuadro de los datos, mostrando la distribución del número de veces que se ha embarazado como una variable numérica para las etiquetas de dos clases.
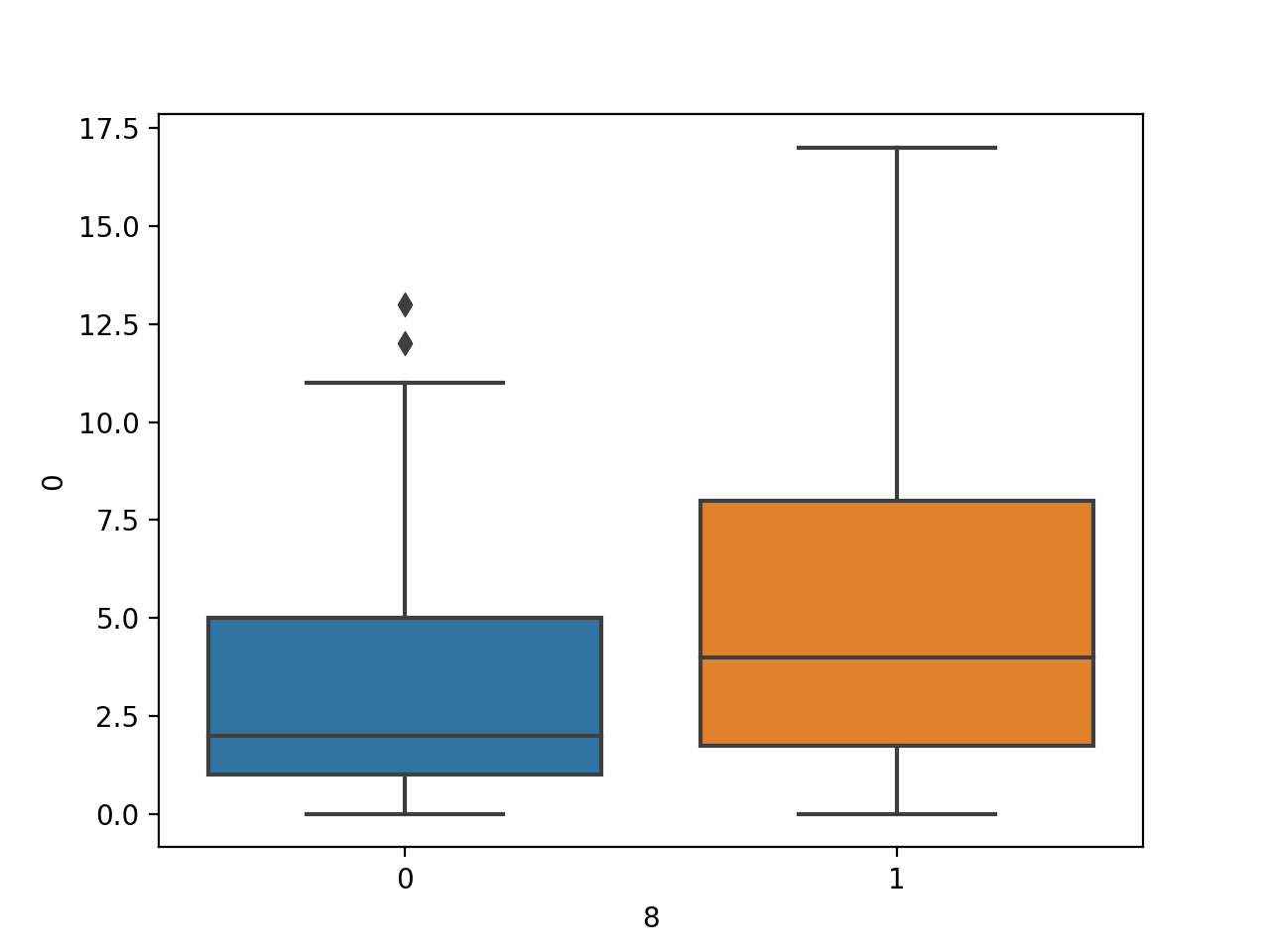
Cuadro y diagrama de bigote del número de veces que está embarazada Variable numérica por etiqueta de clase
Parcelas de dispersión
Por lo general se utiliza un gráfico de dispersión, o diagrama de dispersión, para resumir la relación entre dos muestras de datos emparejadas.
Las muestras de datos emparejados significan que se registraron dos medidas para una observación determinada, como el peso y la altura de una persona.
El eje x representa los valores de observación para la primera muestra, y el eje y representa los valores de observación para la segunda muestra. Cada punto de la gráfica representa una única observación.
Se puede crear un gráfico de dispersión en Seaborn llamando a la función scatterplot() y pasando las dos variables numéricas.
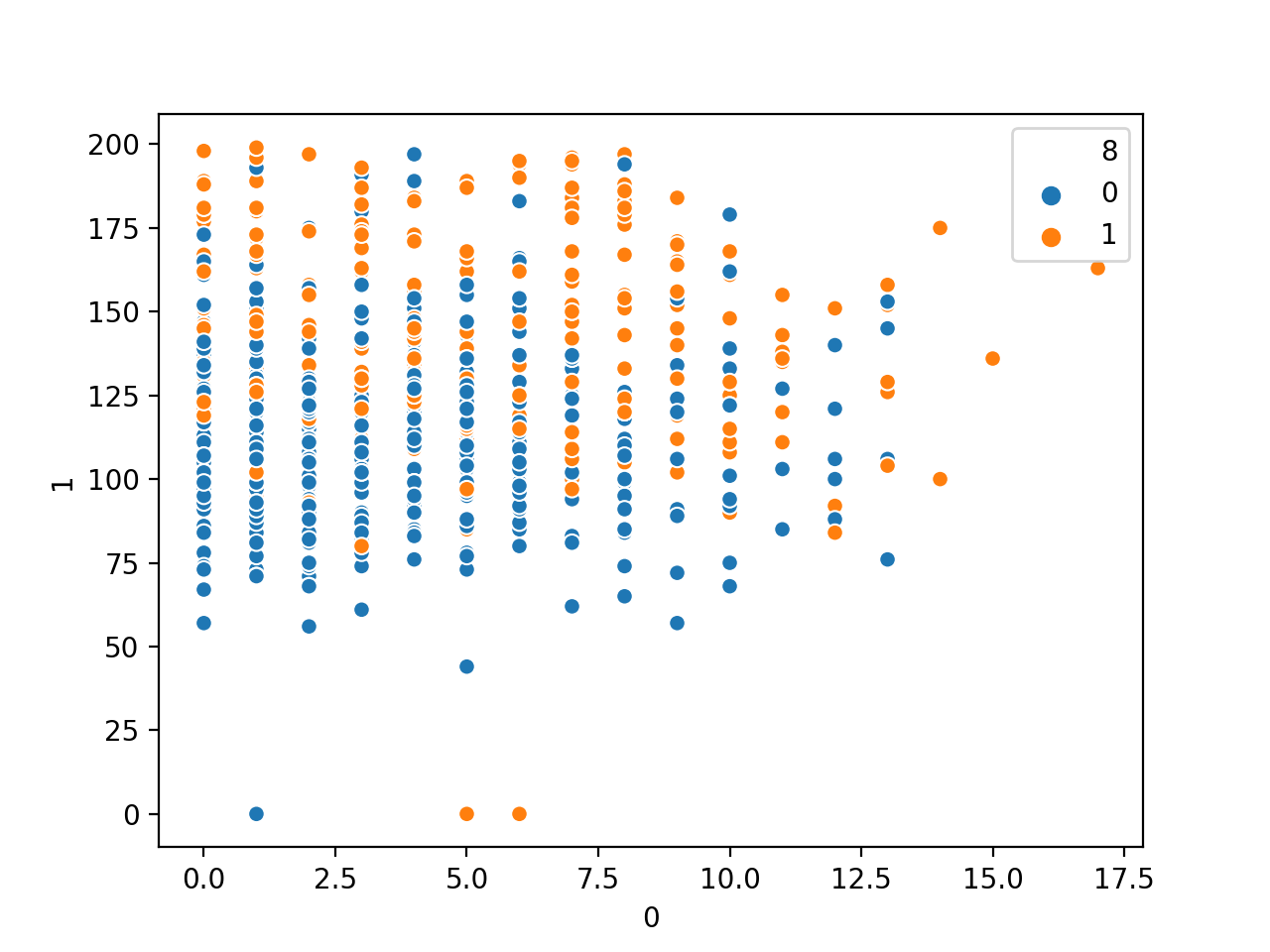
Demostraremos un diagrama de dispersión con dos variables numéricas del conjunto de datos de clasificación de la diabetes. Trazaremos la primera frente a la segunda variable, en este caso, la primera variable, que es el número de veces que una paciente estuvo embarazada, y la segunda es la concentración de glucosa en plasma después de una prueba oral de tolerancia a la glucosa de dos horas (más detalles de las variables aquí).
|
... # Crear una trama de dispersión gráfico de dispersión(x=0, y=1, datos=dataset) |
A continuación se muestra el ejemplo completo.
|
# Gráfica de dispersión de dos variables numéricas de pandas importación read_csv de Seaborn importación gráfico de dispersión de matplotlib importación pyplot # Cargar el conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv’ dataset = read_csv(url, encabezado=Ninguno) # Crear una trama de dispersión gráfico de dispersión(x=0, y=1, datos=dataset) # mostrar la trama pyplot.mostrar() |
Ejecutando el ejemplo primero se carga el conjunto de datos de la diabetes y se crea un gráfico de dispersión de las dos primeras variables de entrada.
Podemos ver una relación algo uniforme entre las dos variables.
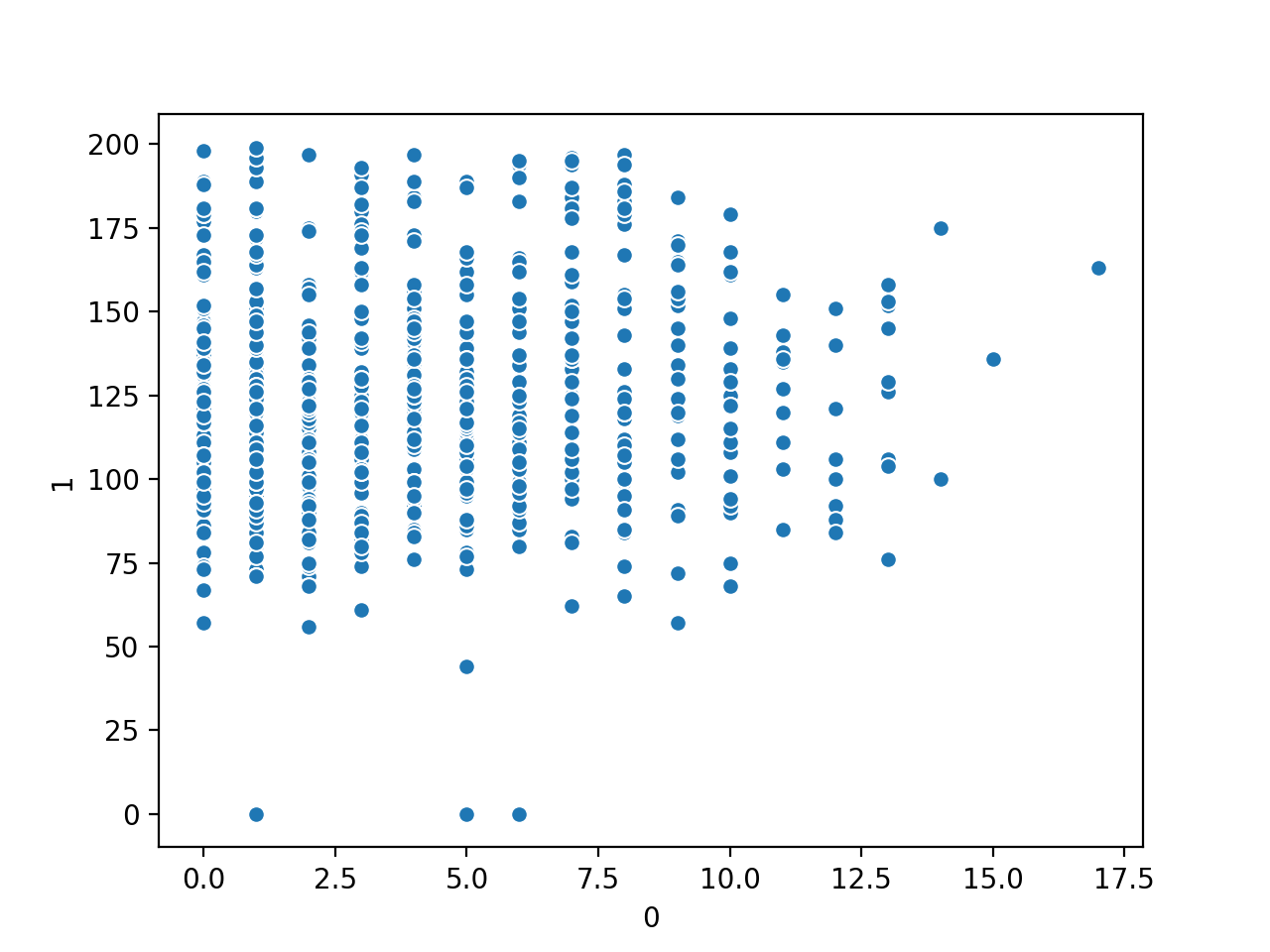
Gráfica de dispersión del número de veces que se está embarazada vs. las variables numéricas de la glucosa en el plasma
También podríamos querer graficar la relación para el par de variables numéricas contra la etiqueta de la clase.
Esto puede lograrse utilizando la función scatterplot() y especificando la variable de clase (índice de la columna 8) mediante la función «hue«argumento», como sigue:
|
... # Crear una trama de dispersión gráfico de dispersión(x=0, y=1, hue=8, datos=dataset) |
A continuación se muestra el ejemplo completo.
|
# Gráfica de dispersión de dos variables numéricas vs. etiqueta de clase de pandas importación read_csv de Seaborn importación gráfico de dispersión de matplotlib importación pyplot # Cargar el conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv’ dataset = read_csv(url, encabezado=Ninguno) # Crear una trama de dispersión gráfico de dispersión(x=0, y=1, hue=8, datos=dataset) # mostrar la trama pyplot.mostrar() |
Al ejecutar el ejemplo primero se carga el conjunto de datos de la diabetes y se crea un gráfico de dispersión de las dos primeras variables frente a la etiqueta de la clase.
Gráfica de dispersión del número de veces que está embarazada vs. la glucosa en el plasma Variables numéricas por etiqueta de clase
