
Broadcast Nested Loop une los trabajos emitiendo uno de los conjuntos de datos completos y realizando un bucle anidado para unir los datos. Así que esencialmente cada registro del conjunto de datos 1 se intenta unir con cada registro del conjunto de datos 2.
Como puedes adivinar, el Broadcast Nested Loop no es preferido y podría ser bastante lento. Funciona tanto para las uniones equi como para las no equi y se elige por defecto cuando tienes una unión no equi.
Ejemplo
No cambiamos los valores por defecto para ambos
chispa.sql.unirse a.preferSortMergeJoin y
chispa.sql.autoBroadcastJoinThreshold .
|
scala> chispa.conf.consigue(«chispa.sql.join.preferSortMergeJoin») res0: Cuerda = verdadero scala> chispa.conf.consigue(«spark.sql.autoBroadcastJoinThreshold») res1: Cuerda = 10485760 |
|
scala> val datos1 = Seq(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50) datos1: Seq[[Int] = Lista(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50) scala> val df1 = datos1.toDF(«id1») df1: org.apache.chispa.sql.DataFrame = [[id1: int] scala> val datos2 = Seq(30, 20, 40, 50) datos2: Seq[[Int] = Lista(30, 20, 40, 50) scala> val df2 = datos2.toDF(«id2») df2: org.apache.chispa.sql.DataFrame = [[id2: int] |
Note que aquí estamos tratando de realizar una operación de unión no-equí.
|
scala> val dfJoined = df1.unirse a(df2, $«id1» >= $«id2») dfJoined: org.apache.chispa.sql.DataFrame = [[id1: int, id2: int] |
Cuando vemos el plan que se ejecutará, podemos ver que se utiliza BroadcastNestedLoopJoin.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
scala> dfJoined.queryExecution.executedPlan res2: org.apache.chispa.sql.ejecución.SparkPlan = BroadcastNestedLoopJoin BuildRight, Interior, (id1#3 >= id2#8) :– LocalTableScan [[id1#3] +– BroadcastExchange IdentityBroadcastMode +– LocalTableScan [[id2#8] scala> dfJoined.mostrar +—–+—–+ |id1|id2| +—–+—–+ | 20| 20| | 20| 20| | 30| 30| | 30| 20| | 40| 30| | 40| 20| | 40| 40| | 40| 30| | 40| 20| | 40| 40| | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 50| 30| | 50| 20| | 50| 40| | 50| 50| +—–+—–+ |
Las etapas involucradas en una emisión anidada se unen
La unión del Broadcast Nested Loop no implica una barajadura o un tipo. El conjunto de datos más pequeño de los dos será transmitido a todas las particiones y un bucle anidado se realiza entre los dos conjuntos de datos para realizar la unión. Cada registro del conjunto de datos 1 se intenta unir con cada registro del conjunto de datos 2.
El funcionamiento interno de la emisión anidada del bucle se une
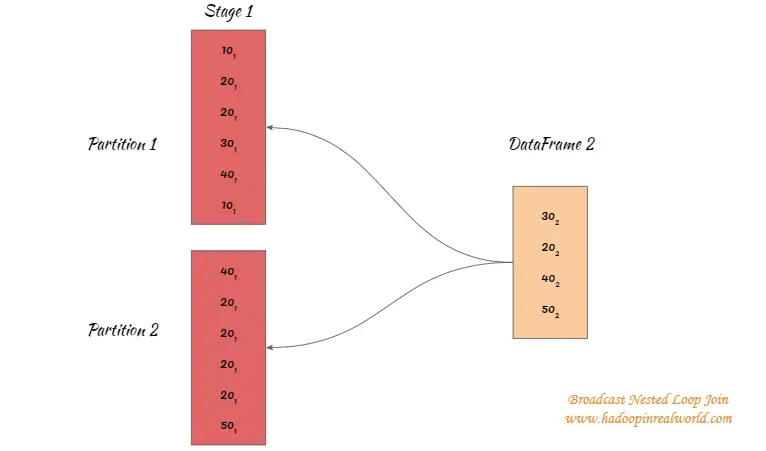
Hay dos fases en una unión de bucle anidado de emisión.
Fase de emisión
- El conjunto de datos más pequeño es transmitido a todos los ejecutores o tareas que procesan el conjunto de datos más grande
- El lado izquierdo se emitirá en una unión exterior derecha.
- El lado derecho en un exterior izquierdo, semi izquierdo, izquierdo anti o unión de existencia será transmitido.
- Cada lado puede ser emitido en una unión interna.
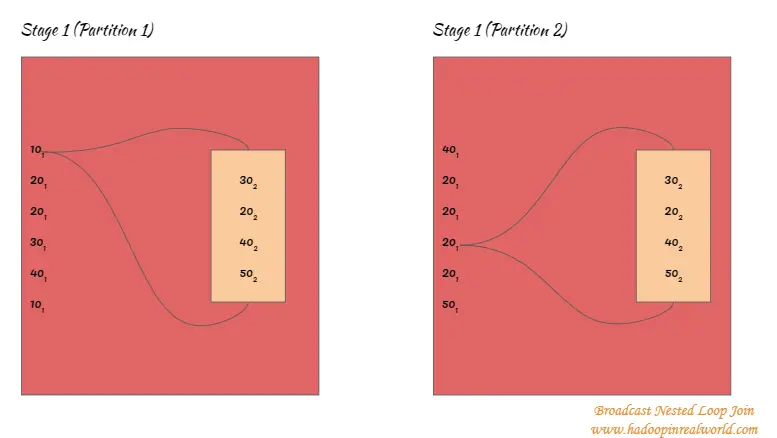
Fase de unión de bucle anidado
- Una vez que el conjunto de datos es transmitido, cada registro de un conjunto de datos se intenta unir con cada registro de otro conjunto de datos en un bucle anidado.
- Como esta unión se utiliza para condiciones no equi, la iteración no puede detenerse tan pronto como se encuentra una unión como en Sort Merge Join. La iteración pasará por todo el conjunto de datos.
- Tengan en cuenta que una especie no está involucrada en esta unión.
¿Cuándo funciona el Broadcast Nested Loop Join?
- Funciona tanto para los equi como para los no equi se une
- Funciona para todos los tipos de unión
cuando la unión del bucle anidado de la transmisión no funciona?
- Esta unión es lenta
- Esta unión no funcionará cuando los dos lados sean lo suficientemente grandes para la transmisión y se puedan ver las excepciones de Out Of Memory.
¿Interesado en aprender sobre Shuffle Hash únete a Spark? – Haz clic aquí.