
Publicación cruzada de Bounded Regret.
Para comprender las redes neuronales, los investigadores suelen utilizar métricas de similitud para medir qué tan similares o diferentes son dos redes neuronales entre sí. Por ejemplo, se utilizan para comparar transformadores de visión con convnets. [1], para comprender el aprendizaje por transferencia [2]y explicar el éxito de las prácticas de formación estándar para modelos profundos. [3]. A continuación se muestra una visualización de ejemplo que utiliza métricas de similitud; específicamente utilizamos la popular métrica de similitud CKA (introducida en [4]) para comparar dos modelos de transformadores en diferentes capas:
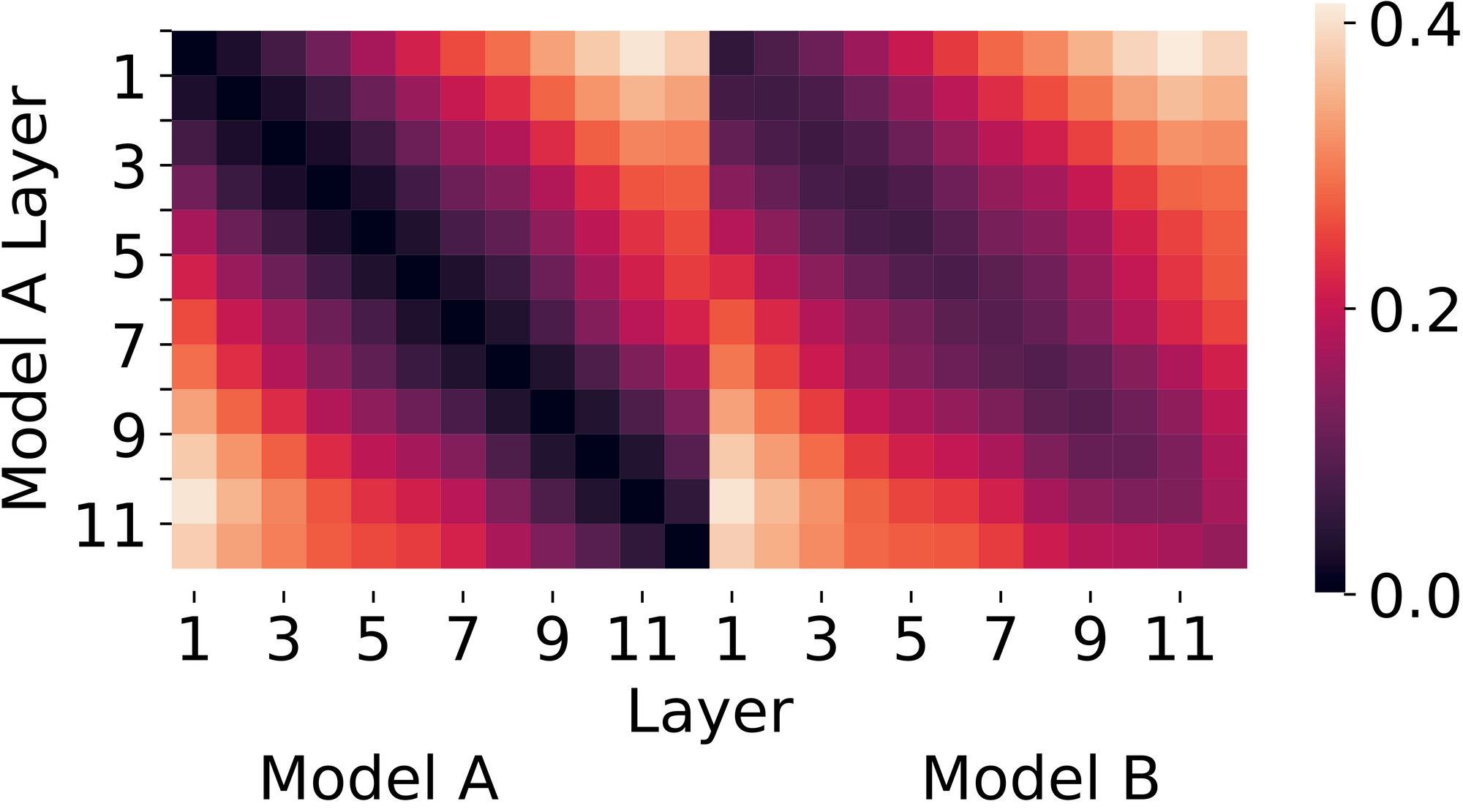
Figura 1. Similitud de CKA (Alineación de núcleo centrada) entre dos redes entrenadas de forma idéntica, excepto por la inicialización aleatoria. Los valores más bajos (colores más oscuros) son más similares. CKA sugiere que las dos redes tienen representaciones similares.
Desafortunadamente, no hay mucho acuerdo sobre qué métrica de similitud particular usar. Aquí está exactamente la misma cifra, pero producida utilizando la métrica de Análisis de correlación canónica (CCA) en lugar de CKA:
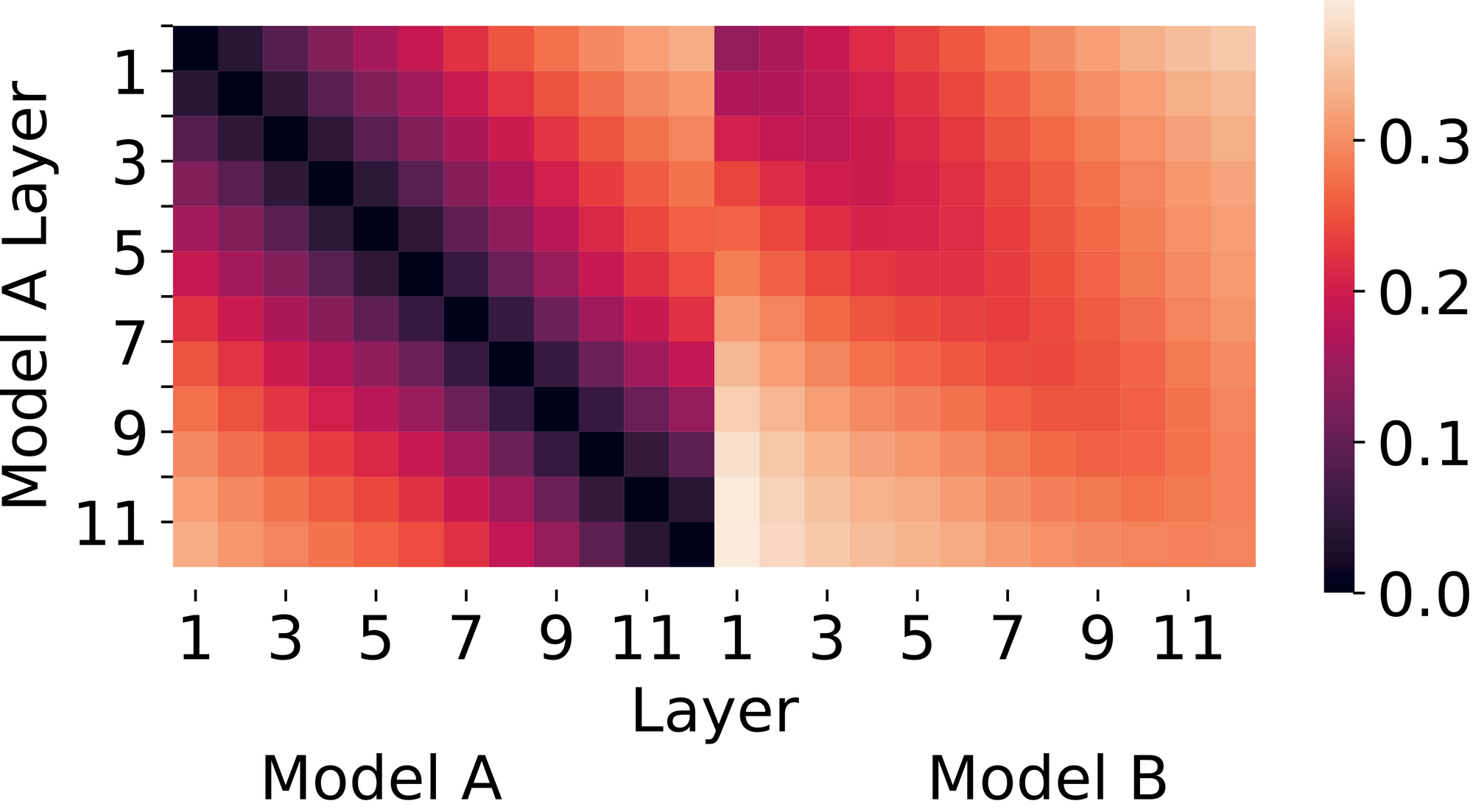
Figura 2. Similitud CCA (Análisis de correlación canónica) entre las mismas dos redes. Las distancias CCA sugieren que las dos redes aprenden representaciones algo diferentes, especialmente en capas posteriores.
En la literatura, los investigadores a menudo proponen nuevas métricas y las justifican basándose en desideratos intuitivos que faltaban en las métricas anteriores. Por ejemplo, Morcos et al. Motivar a CCA argumentando que las métricas de similitud deben ser invariables a las transformaciones lineales invertibles. [5]. Kornblith y col. no están de acuerdo sobre qué invariancias debe tener una métrica de similitud y, en su lugar, argumentan que las métricas deben pasar una prueba intuitiva: dadas dos redes entrenadas con la misma arquitectura pero una inicialización diferente, las capas a la misma profundidad deben ser más similares entre sí, y su métrica propuesta , CKA, rinde mejor en su prueba [4].
Nuestro artículo, Grounding Representation Similarity with Statistical Testing, argumenta en contra de esta práctica. Para empezar, mostramos que eligiendo diferentes pruebas intuitivas, podemos hacer que cualquier método se vea bien. A CKA le va bien en una «prueba de especificidad» similar a la propuesta por Kornblith et al., Pero le va mal en una «prueba de sensibilidad» en la que CCA brilla.
Para ir más allá de las pruebas intuitivas, nuestro artículo proporciona una referencia cuantitativa cuidadosamente diseñada para evaluar métricas de similitud. La idea básica es que una buena métrica de similitud debe correlacionarse con el valor real funcionalidad de una red neuronal, que operacionalizamos como precisión en una tarea. ¿Por qué? Las diferencias de precisión entre los modelos son una señal de que los modelos están procesando los datos de manera diferente, por lo que las representaciones intermedias deben ser diferentes y las métricas de similitud deben notar esto.
Por lo tanto, para un par dado de representaciones de redes neuronales, medimos tanto su (des) similitud como la diferencia entre sus precisiones en alguna tarea. Si están bien correlacionados entre muchos pares de representaciones, tenemos una buena métrica de similitud. Por supuesto, una correlación perfecta con la precisión en una tarea en particular tampoco es lo que esperamos, ya que las métricas deben capturar muchas diferencias importantes entre modelos, no solo una. Una buena métrica de similitud es aquella que generalmente obtiene altas correlaciones entre un par de funcionalidades.
Evaluamos la funcionalidad con una variedad de tareas. Para un ejemplo concreto, una subtarea en nuestro punto de referencia se basa en la observación de que los modelos de lenguaje BERT ajustados con diferentes semillas aleatorias tendrán una precisión de distribución casi idéntica, pero una precisión fuera de distribución muy variable (por ejemplo, de 0 a 60 % en el conjunto de datos HANS [6]). Dados dos modelos robustos, una métrica de similitud debería calificarlos como similares, y dado un modelo robusto y otro no robusto, una métrica debería calificarlos como diferentes. Por lo tanto, tomamos 100 de estos modelos BERT y evaluamos si la (des) similitud entre cada par de representaciones de modelos se correlaciona con su diferencia en la precisión de OOD.
Nuestro punto de referencia se compone de muchas de estas subtareas, donde recopilamos representaciones de modelos que varían a lo largo de ejes, como semillas de entrenamiento o profundidad de capa, y evaluamos las funcionalidades de los modelos. Incluimos las siguientes subtareas:
- Variar semillas y profundidades de capa, y evaluar la funcionalidad a través de sondas lineales (clasificadores lineales entrenados sobre la capa intermedia de un modelo congelado)
- Variación de semillas, profundidades de capa y eliminación de componentes principales, y evaluación de la funcionalidad a través de sondas lineales
- Variar semillas de ajuste fino y evaluar la funcionalidad a través de conjuntos de prueba OOD (descrito arriba)
- Variar semillas de preentrenamiento y ajuste fino y evaluar la funcionalidad a través de conjuntos de prueba OOD
Puede encontrar el código de nuestros puntos de referencia aquí.
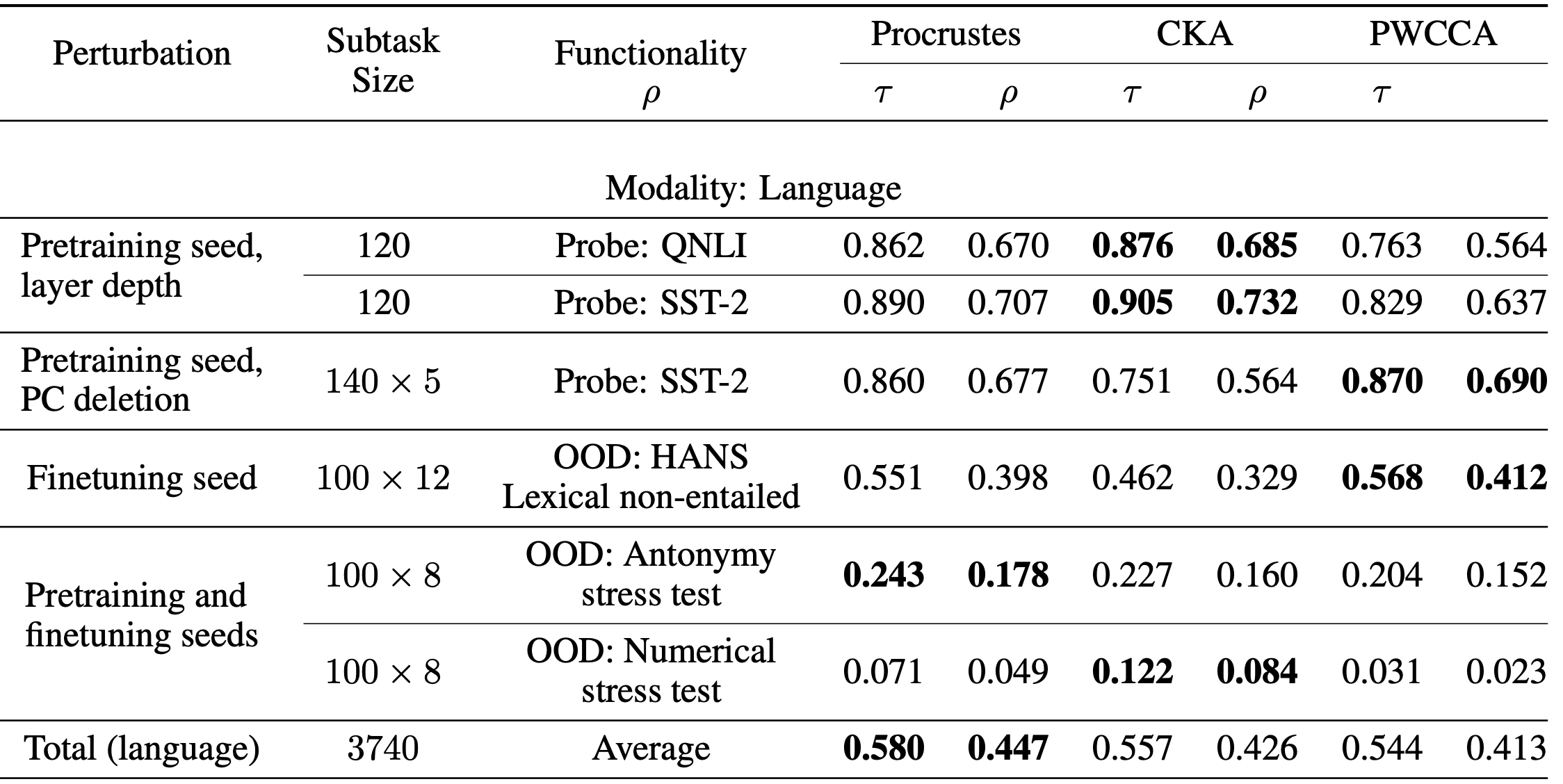
La siguiente tabla muestra nuestros resultados con modelos de lenguaje BERT (los resultados del modelo de visión se pueden encontrar en el documento). Además de las métricas populares de CKA y (PW) CCA, consideramos una línea de base clásica llamada distancia Procrustes. Tanto CKA como PWCCA dominan ciertos puntos de referencia y se quedan atrás en otros, mientras que Procrustes es más consistente y, a menudo, cercano al líder. Además, nuestra última subtarea es un desafío, ya que ninguna medida de similitud logra una alta correlación. Lo presentamos como una tarea desafiante para motivar un mayor progreso en las métricas de similitud.
Al final, nos sorprendió ver a Procrustes hacerlo tan bien, ya que los métodos recientes de CKA y CCA han recibido más atención, y originalmente incluimos a Procrustes como línea de base en aras de la minuciosidad. La construcción de estos puntos de referencia en muchas tareas diferentes fue esencial para destacar a Procrustes como un buen método integral, y sería genial ver la creación de más puntos de referencia que evalúen las capacidades y limitaciones de otras herramientas para comprender e interpretar redes neuronales.
Para obtener más detalles, consulte nuestro documento completo.
Referencias
[1] Raghu, Maithra y col. «¿Los transformadores de visión se ven como redes neuronales convolucionales?» preimpresión de arXiv arXiv: 2108.08810 (2021). [2]Neyshabur, Behnam, Hanie Sedghi y Chiyuan Zhang. «¿Qué se está transfiriendo en el aprendizaje por transferencia?» NeurIPS. 2020. [3] Gotmare, Akhilesh y col. «Una mirada más cercana a la heurística de aprendizaje profundo: reinicios de la tasa de aprendizaje, calentamiento y destilación». Congreso Internacional de Representaciones del Aprendizaje. 2018. [4] Kornblith, Simon y col. «Se revisó la similitud de las representaciones de redes neuronales». Congreso Internacional de Machine Learning. PMLR, 2019. [5] Morcos, Ari S., Maithra Raghu y Samy Bengio. «Información sobre la similitud de representación en redes neuronales con correlación canónica». Actas de la 32ª Conferencia Internacional sobre Sistemas de Procesamiento de Información Neural. 2018. [6] RT McCoy, J. Min y T. Linzen. Berts of a feather no generalize together: Gran variabilidad en la generalización entre modelos con un rendimiento similar del conjunto de pruebas. Actas del tercer taller de BlackboxNLP sobre análisis e interpretación de redes neuronales para PNL, 2020.Esta publicación se basa en el artículo «Grounding Representation Similarity with Statistical Testing», que se presentará en NeurIPS 2021. Puede ver los resultados completos en nuestro artículo y proporcionamos el código para reproducir nuestros experimentos. Agradecemos a Juanky Perdomo y John Miller por sus valiosos comentarios sobre esta publicación de blog.