

Última actualización el 23 de agosto de 2022
Una vez que ajusta un modelo de red neuronal de aprendizaje profundo, debe evaluar su rendimiento en un conjunto de datos de prueba.
Esto es fundamental, ya que el rendimiento informado le permite elegir entre modelos candidatos y comunicar a las partes interesadas qué tan bueno es el modelo para resolver el problema.
El modelo de API de aprendizaje profundo de Keras es muy limitado en cuanto a las métricas que puede usar para informar el rendimiento del modelo.
Me hacen preguntas frecuentes, como:
¿Cómo puedo calcular la precisión y la recuperación de mi modelo?
Y:
¿Cómo puedo calcular la puntuación F1 o la matriz de confusión para mi modelo?
En este tutorial, descubrirá cómo calcular métricas para evaluar su modelo de red neuronal de aprendizaje profundo con un ejemplo paso a paso.
Después de completar este tutorial, sabrás:
- Cómo usar la API de métricas de scikit-learn para evaluar un modelo de aprendizaje profundo.
- Cómo hacer predicciones tanto de clase como de probabilidad con un modelo final requerido por la API scikit-learn.
- Cómo calcular la precisión, recuperación, puntaje F1, ROC AUC y más con la API scikit-learn para un modelo.
Pon en marcha tu proyecto con mi nuevo libro Aprendizaje profundo con Python, que incluye tutoriales paso a paso y el Código fuente de Python archivos para todos los ejemplos.
Empecemos.
- mar/2019: Primera publicación
- Actualización Ene/2020: API actualizada para Keras 2.3 y TensorFlow 2.0.
Cómo calcular precisión, recuperación, F1 y más para modelos de aprendizaje profundo
Foto de John, algunos derechos reservados.
Descripción general del tutorial
Este tutorial se divide en tres partes; están:
- Problema de clasificación binaria
- Modelo de perceptrón multicapa
- Cómo calcular las métricas del modelo
Problema de clasificación binaria
Usaremos un problema de clasificación binaria estándar como base para este tutorial, llamado «dos círculos» problema.
Se llama el problema de los dos círculos porque el problema se compone de puntos que, cuando se grafican, muestran dos círculos concéntricos, uno para cada clase. Como tal, este es un ejemplo de un problema de clasificación binaria. El problema tiene dos entradas que pueden interpretarse como coordenadas x e y en un gráfico. Cada punto pertenece al círculo interior o exterior.
La función make_circles() en la biblioteca scikit-learn le permite generar ejemplos del problema de los dos círculos. Los «n_muestrasEl argumento ” le permite especificar el número de muestras a generar, divididas equitativamente entre las dos clases. Los «ruidoEl argumento ” le permite especificar cuánto ruido estadístico aleatorio se agrega a las entradas o coordenadas de cada punto, lo que hace que la tarea de clasificación sea más desafiante. Los «estado_aleatorioEl argumento especifica la semilla para el generador de números pseudoaleatorios, lo que garantiza que se generen las mismas muestras cada vez que se ejecuta el código.
El siguiente ejemplo genera 1000 muestras, con 0,1 de ruido estadístico y una semilla de 1.
# generate 2d classification dataset
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
Una vez generado, podemos crear un gráfico del conjunto de datos para tener una idea de cuán desafiante es la tarea de clasificación.
El siguiente ejemplo genera muestras y las traza, coloreando cada punto según la clase, donde los puntos que pertenecen a la clase 0 (círculo exterior) se colorean de azul y los puntos que pertenecen a la clase 1 (círculo interior) se colorean de naranja.
# Example of generating samples from the two circle problem
from sklearn.datasets import make_circles
from matplotlib import pyplot
from numpy import where
# generate 2d classification dataset
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
# scatter plot, dots colored by class value
for i in range(2):
samples_ix = where(y == i)
pyplot.scatter(X[samples_ix, 0], X[samples_ix, 1])
pyplot.show()
Ejecutar el ejemplo genera el conjunto de datos y traza los puntos en un gráfico, mostrando claramente dos círculos concéntricos para los puntos que pertenecen a la clase 0 y la clase 1.
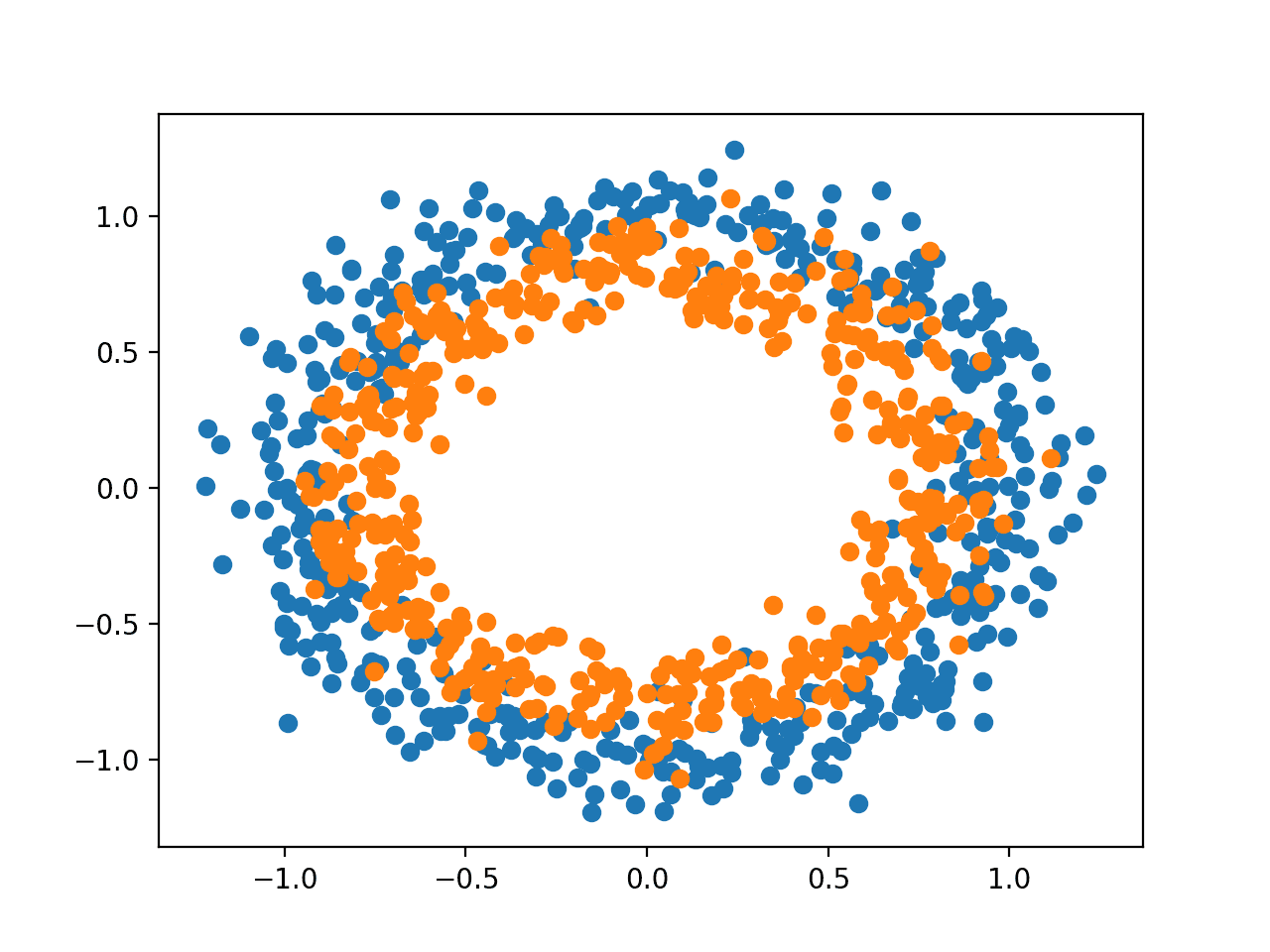
Diagrama de dispersión de muestras del problema de los dos círculos
Modelo de perceptrón multicapa
Desarrollaremos un modelo de perceptrón multicapa, o MLP, para abordar el problema de clasificación binaria.
Este modelo no está optimizado para el problema, pero es hábil (mejor que aleatorio).
Después de generar las muestras para el conjunto de datos, las dividiremos en dos partes iguales: una para entrenar el modelo y otra para evaluar el modelo entrenado.
# split into train and test
n_test = 500
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
A continuación, podemos definir nuestro modelo MLP. El modelo es simple, espera 2 variables de entrada del conjunto de datos, una sola capa oculta con 100 nodos y una función de activación de ReLU, luego una capa de salida con un solo nodo y una función de activación sigmoidea.
El modelo predecirá un valor entre 0 y 1 que se interpretará en cuanto a si el ejemplo de entrada pertenece a la clase 0 o a la clase 1.
# define model
model = Sequential()
model.add(Dense(100, input_shape=(2,), activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
El modelo se ajustará usando la función de pérdida de entropía cruzada binaria y usaremos la versión eficiente de Adam del descenso de gradiente estocástico. El modelo también monitoreará la métrica de precisión de clasificación.
# compile model
model.compile(loss=»binary_crossentropy», optimizer=»adam», metrics=[‘accuracy’])
Ajustaremos el modelo para 300 épocas de entrenamiento con el tamaño de lote predeterminado de 32 muestras y evaluaremos el rendimiento del modelo al final de cada época de entrenamiento en el conjunto de datos de prueba.
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=300, verbose=0)
Al final del entrenamiento, evaluaremos el modelo final una vez más en los conjuntos de datos de entrenamiento y prueba e informaremos la precisión de la clasificación.
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
Finalmente, el rendimiento del modelo en el tren y los conjuntos de prueba registrados durante el entrenamiento se graficarán mediante un gráfico de líneas, uno para cada pérdida y precisión de clasificación.
# plot loss during training
pyplot.subplot(211)
pyplot.title(‘Loss’)
pyplot.plot(history.history[‘loss’], label=»train»)
pyplot.plot(history.history[‘val_loss’], label=»test»)
pyplot.legend()
# plot accuracy during training
pyplot.subplot(212)
pyplot.title(‘Accuracy’)
pyplot.plot(history.history[‘accuracy’], label=»train»)
pyplot.plot(history.history[‘val_accuracy’], label=»test»)
pyplot.legend()
pyplot.show()
Uniendo todos estos elementos, la lista completa de códigos de entrenamiento y evaluación de un MLP en el problema de los dos círculos se enumera a continuación.
# multilayer perceptron model for the two circles problem
from sklearn.datasets import make_circles
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
# generate dataset
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
# split into train and test
n_test = 500
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
# define model
model = Sequential()
model.add(Dense(100, input_shape=(2,), activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
# compile model
model.compile(loss=»binary_crossentropy», optimizer=»adam», metrics=[‘accuracy’])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=300, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print(‘Train: %.3f, Test: %.3f’ % (train_acc, test_acc))
# plot loss during training
pyplot.subplot(211)
pyplot.title(‘Loss’)
pyplot.plot(history.history[‘loss’], label=»train»)
pyplot.plot(history.history[‘val_loss’], label=»test»)
pyplot.legend()
# plot accuracy during training
pyplot.subplot(212)
pyplot.title(‘Accuracy’)
pyplot.plot(history.history[‘accuracy’], label=»train»)
pyplot.plot(history.history[‘val_accuracy’], label=»test»)
pyplot.legend()
pyplot.show()
Ejecutar el ejemplo ajusta el modelo muy rápidamente en la CPU (no se requiere GPU).
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o procedimiento de evaluación, o diferencias en la precisión numérica. Considere ejecutar el ejemplo varias veces y compare el resultado promedio.
Se evalúa el modelo, informando la precisión de clasificación en el tren y conjuntos de prueba de alrededor del 83% y 85% respectivamente.
Train: 0.838, Test: 0.850
Se crea una figura que muestra dos gráficos de líneas: uno para las curvas de aprendizaje de la pérdida en el tren y los conjuntos de prueba y otro para la clasificación en el tren y los conjuntos de prueba.
Los gráficos sugieren que el modelo se ajusta bien al problema.
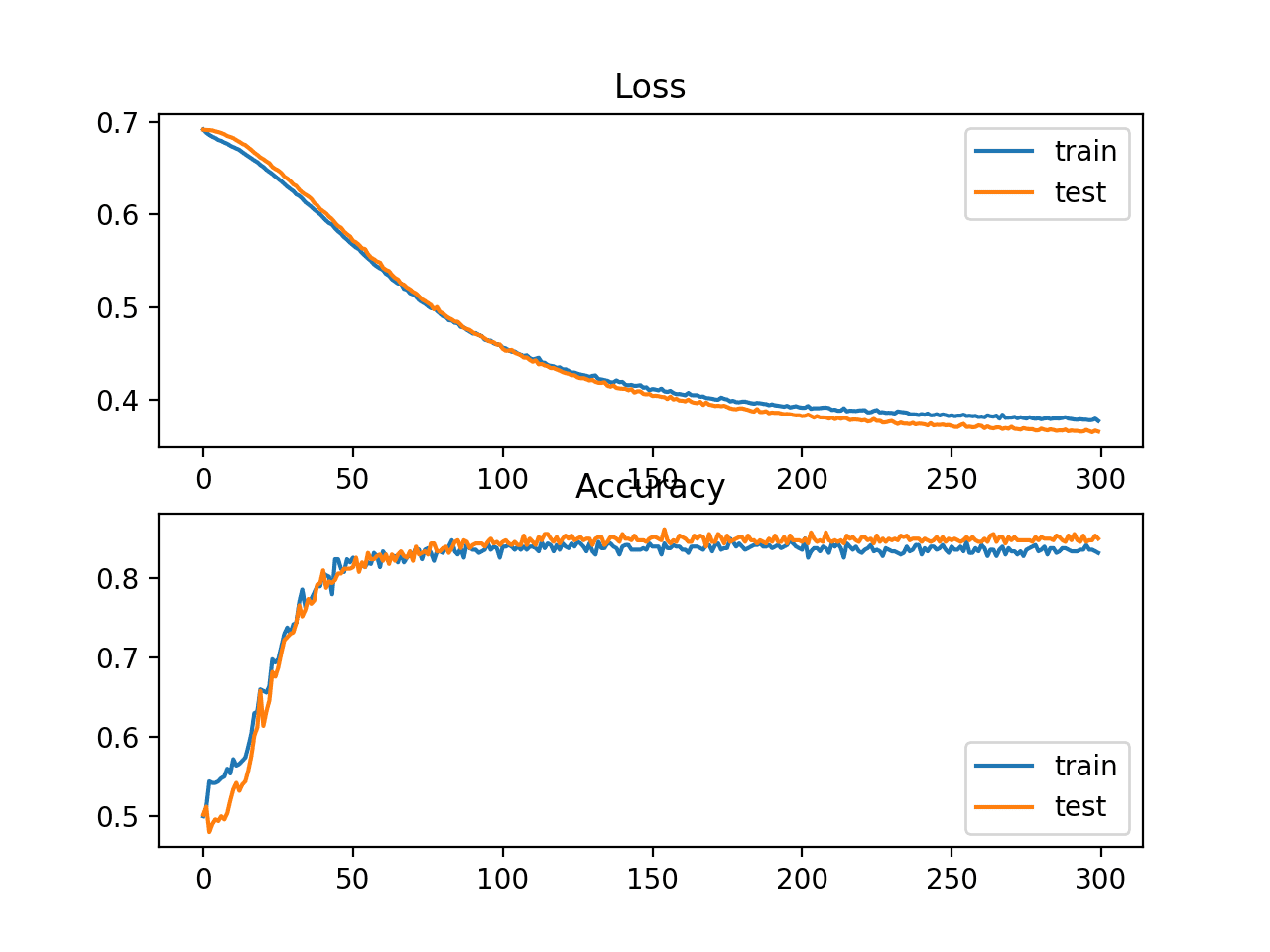
Gráfico de líneas que muestra las curvas de aprendizaje de pérdida y precisión del MLP en el problema de los dos círculos durante el entrenamiento
Cómo calcular las métricas del modelo
Tal vez necesite evaluar su modelo de red neuronal de aprendizaje profundo utilizando métricas adicionales que no son compatibles con la API de métricas de Keras.
La API de métricas de Keras es limitada y es posible que desee calcular métricas como precisión, recuperación, F1 y más.
Un enfoque para calcular nuevas métricas es implementarlas usted mismo en la API de Keras y hacer que Keras las calcule durante el entrenamiento y la evaluación del modelo.
Para obtener ayuda con este enfoque, consulte el tutorial:
- Cómo usar métricas para el aprendizaje profundo con Keras en Python
Esto puede ser técnicamente desafiante.
Una alternativa mucho más simple es usar su modelo final para hacer una predicción para el conjunto de datos de prueba, luego calcular cualquier métrica que desee usando la API de métricas de scikit-learn.
Tres métricas, además de la precisión de la clasificación, que comúnmente se requieren para un modelo de red neuronal en un problema de clasificación binaria son:
- Precisión
- Recuerdo
- Puntuación F1
En esta sección, calcularemos estas tres métricas, así como la precisión de la clasificación mediante la API de métricas de scikit-learn, y también calcularemos tres métricas adicionales que son menos comunes pero que pueden ser útiles. Están:
- Kappa de Cohen
- ABC de la República de China
- Matriz de confusión.
Esta no es una lista completa de métricas para modelos de clasificación compatibles con scikit-learn; sin embargo, el cálculo de estas métricas le mostrará cómo calcular las métricas que pueda necesitar mediante la API de scikit-learn.
Para obtener una lista completa de las métricas admitidas, consulte:
- sklearn.metrics: API de métricas
- Guía de métricas de clasificación
El ejemplo de esta sección calculará métricas para un modelo MLP, pero el mismo código para calcular métricas se puede usar para otros modelos, como RNN y CNN.
Podemos usar el mismo código de las secciones anteriores para preparar el conjunto de datos, así como para definir y ajustar el modelo. Para simplificar el ejemplo, pondremos el código de estos pasos en una función simple.
Primero, podemos definir una función llamada obtener datos() que generará el conjunto de datos y lo dividirá en conjuntos de entrenamiento y prueba.
# generate and prepare the dataset
def get_data():
# generate dataset
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
# split into train and test
n_test = 500
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
return trainX, trainy, testX, testy
A continuación, definiremos una función llamada obtener_modelo() que definirá el modelo MLP y lo ajustará al conjunto de datos de entrenamiento.
# define and fit the model
def get_model(trainX, trainy):
# define model
model = Sequential()
model.add(Dense(100, input_shape=(2,), activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
# compile model
model.compile(loss=»binary_crossentropy», optimizer=»adam», metrics=[‘accuracy’])
# fit model
model.fit(trainX, trainy, epochs=300, verbose=0)
return model
Entonces podemos llamar al obtener datos() función para preparar el conjunto de datos y el obtener_modelo() Función para ajustar y devolver el modelo.
# generate data
trainX, trainy, testX, testy = get_data()
# fit model
model = get_model(trainX, trainy)
Ahora que tenemos un ajuste de modelo en el conjunto de datos de entrenamiento, podemos evaluarlo usando métricas de la API de métricas de scikit-learn.
Primero, debemos usar el modelo para hacer predicciones. La mayoría de las funciones métricas requieren una comparación entre los valores de clase reales (p. ej. irascible) y los valores de clase predichos (yhat_classes). Podemos predecir los valores de clase directamente con nuestro modelo usando el predecir_clases() función en el modelo.
Algunas métricas, como ROC AUC, requieren una predicción de las probabilidades de clase (yhat_probs). Estos se pueden recuperar llamando al predecir() función en el modelo.
Para obtener más ayuda con la realización de predicciones utilizando un modelo de Keras, consulte la publicación:
- Cómo hacer predicciones con Keras
Podemos hacer las predicciones de clase y probabilidad con el modelo.
# predict probabilities for test set
yhat_probs = model.predict(testX, verbose=0)
# predict crisp classes for test set
yhat_classes = model.predict_classes(testX, verbose=0)
Las predicciones se devuelven en una matriz bidimensional, con una fila para cada ejemplo en el conjunto de datos de prueba y una columna para la predicción.
La API de métricas de scikit-learn espera una matriz 1D de valores reales y predichos para la comparación, por lo tanto, debemos reducir las matrices de predicción 2D a matrices 1D.
# reduce to 1d array
yhat_probs = yhat_probs[:, 0]
yhat_classes = yhat_classes[:, 0]
Ahora estamos listos para calcular métricas para nuestro modelo de red neuronal de aprendizaje profundo. Podemos comenzar calculando la precisión de la clasificación, la precisión, el recuerdo y las puntuaciones de F1.
# accuracy: (tp + tn) / (p + n)
accuracy = accuracy_score(testy, yhat_classes)
print(‘Accuracy: %f’ % accuracy)
# precision tp / (tp + fp)
precision = precision_score(testy, yhat_classes)
print(‘Precision: %f’ % precision)
# recall: tp / (tp + fn)
recall = recall_score(testy, yhat_classes)
print(‘Recall: %f’ % recall)
# f1: 2 tp / (2 tp + fp + fn)
f1 = f1_score(testy, yhat_classes)
print(‘F1 score: %f’ % f1)
Tenga en cuenta que calcular una métrica es tan simple como elegir la métrica que nos interesa y llamar a la función pasando los valores de clase verdaderos (irascible) y los valores de clase predichos (yhat_classes).
También podemos calcular algunas métricas adicionales, como el kappa de Cohen, ROC AUC y la matriz de confusión.
Observe que el ROC AUC requiere las probabilidades de clase pronosticadas (yhat_probs) como argumento en lugar de las clases previstas (yhat_classes).
# kappa
kappa = cohen_kappa_score(testy, yhat_classes)
print(‘Cohens kappa: %f’ % kappa)
# ROC AUC
auc = roc_auc_score(testy, yhat_probs)
print(‘ROC AUC: %f’ % auc)
# confusion matrix
matrix = confusion_matrix(testy, yhat_classes)
print(matrix)
Ahora que sabemos cómo calcular las métricas para una red neuronal de aprendizaje profundo mediante la API scikit-learn, podemos unir todos estos elementos en un ejemplo completo, que se enumera a continuación.
# demonstration of calculating metrics for a neural network model using sklearn
from sklearn.datasets import make_circles
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import cohen_kappa_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import confusion_matrix
from keras.models import Sequential
from keras.layers import Dense
# generate and prepare the dataset
def get_data():
# generate dataset
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
# split into train and test
n_test = 500
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
return trainX, trainy, testX, testy
# define and fit the model
def get_model(trainX, trainy):
# define model
model = Sequential()
model.add(Dense(100, input_shape=(2,), activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
# compile model
model.compile(loss=»binary_crossentropy», optimizer=»adam», metrics=[‘accuracy’])
# fit model
model.fit(trainX, trainy, epochs=300, verbose=0)
return model
# generate data
trainX, trainy, testX, testy = get_data()
# fit model
model = get_model(trainX, trainy)
# predict probabilities for test set
yhat_probs = model.predict(testX, verbose=0)
# predict crisp classes for test set
yhat_classes = model.predict_classes(testX, verbose=0)
# reduce to 1d array
yhat_probs = yhat_probs[:, 0]
yhat_classes = yhat_classes[:, 0]
# accuracy: (tp + tn) / (p + n)
accuracy = accuracy_score(testy, yhat_classes)
print(‘Accuracy: %f’ % accuracy)
# precision tp / (tp + fp)
precision = precision_score(testy, yhat_classes)
print(‘Precision: %f’ % precision)
# recall: tp / (tp + fn)
recall = recall_score(testy, yhat_classes)
print(‘Recall: %f’ % recall)
# f1: 2 tp / (2 tp + fp + fn)
f1 = f1_score(testy, yhat_classes)
print(‘F1 score: %f’ % f1)
# kappa
kappa = cohen_kappa_score(testy, yhat_classes)
print(‘Cohens kappa: %f’ % kappa)
# ROC AUC
auc = roc_auc_score(testy, yhat_probs)
print(‘ROC AUC: %f’ % auc)
# confusion matrix
matrix = confusion_matrix(testy, yhat_classes)
print(matrix)
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o procedimiento de evaluación, o diferencias en la precisión numérica. Considere ejecutar el ejemplo varias veces y compare el resultado promedio.
Ejecutar el ejemplo prepara el conjunto de datos, ajusta el modelo, luego calcula e informa las métricas para el modelo evaluado en el conjunto de datos de prueba.
Accuracy: 0.842000
Precision: 0.836576
Recall: 0.853175
F1 score: 0.844794
Cohens kappa: 0.683929
ROC AUC: 0.923739
[[206 42]
[ 37 215]]
Si necesita ayuda para interpretar una métrica dada, tal vez comience con la «Guía de métricas de clasificación» en la documentación de la API de scikit-learn: Guía de métricas de clasificación
Además, consulte la página de Wikipedia para conocer su métrica; por ejemplo: Precisión y recuperación, Wikipedia.
Otras lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar más.
Publicaciones
- Cómo usar métricas para el aprendizaje profundo con Keras en Python
- Cómo generar conjuntos de datos de prueba en Python con scikit-learn
- Cómo hacer predicciones con Keras
API
- sklearn.metrics: API de métricas
- Guía de métricas de clasificación
- API de métricas de Keras
- API sklearn.datasets.make_circles
Artículos
- Evaluación de clasificadores binarios, Wikipedia.
- Matriz de confusión, Wikipedia.
- Precisión y memoria, Wikipedia.
Resumen
En este tutorial, descubrió cómo calcular métricas para evaluar su modelo de red neuronal de aprendizaje profundo con un ejemplo paso a paso.
Específicamente, aprendiste:
- Cómo usar la API de métricas de scikit-learn para evaluar un modelo de aprendizaje profundo.
- Cómo hacer predicciones tanto de clase como de probabilidad con un modelo final requerido por la API scikit-learn.
- Cómo calcular la precisión, recuperación, puntaje F1, ROC, AUC y más con la API scikit-learn para un modelo.
¿Tiene usted alguna pregunta?
Haga sus preguntas en los comentarios a continuación y haré todo lo posible para responder.
La publicación Cómo calcular la precisión, recuperación, F1 y más para los modelos de aprendizaje profundo apareció primero en Machine Learning Mastery.