

Si Nvidia y AMD se relamen pensando en todas las GPU que pueden vender a Microsoft para respaldar sus enormes aspiraciones en IA generativa, particularmente cuando se trata del modelo de lenguaje grande OpenAI GPT que es la pieza central de todo el software futuro de la compañía. y servicios, es mejor que lo piensen de nuevo.
Hemos estado diciendo desde el comienzo de esta explosión de IA generativa que si la inferencia requiere el mismo hardware para ejecutarse que el entrenamiento, entonces no se puede producir. Nadie, ni siquiera los hiperescaladores adinerados y los constructores de la nube, pueden permitirse esto.
Es por eso que Microsoft, en colaboración con investigadores de la Universidad de Washington, ha preparado algo llamado Chiplet Cloud, que en teoría al menos parece que puede vencer a una GPU Nvidia «Ampere» A100 (y en menor medida). hasta una GPU H100 «Hopper») y un acelerador Google TPUv4 que ejecuta el modelo GPT-3 175B de Microsoft y el modelo PaLM 540B de Google cuando se trata de inferencia.
La arquitectura Chiplet Cloud se acaba de divulgar en un artículo basado en una investigación encabezada por Shuaiwen Leon Song, quien fue científico sénior y líder técnico en el Laboratorio Nacional del Noroeste del Pacífico, así como miembro de la facultad que trabaja en futuras arquitecturas de sistemas en la Universidad de Sydney y la Universidad de Washington antes de unirse a Microsoft en enero de este año como científico principal sénior para administrar conjuntamente su equipo de aprendizaje profundo FPGA Brainwave y ejecutar sus optimizaciones de aprendizaje profundo DeepSpeed para el marco PyTorch, que son parte de la colección AI at Scale de Microsoft Research de proyectos
No por nada – y lo decimos en serio como verás Estos son los proyectos que fueron superados por GPT, lo que obligó a Microsoft a desembolsar una inversión de $ 10 mil millones en OpenAI aproximadamente al mismo tiempo que Leon Song se unía a Microsoft. Hasta la fecha, Microsoft le ha dado a OpenAI $ 13 mil millones en inversiones, gran parte de los cuales se gastarán para entrenar y ejecutar modelos GPT en la nube Azure de Microsoft.
Si tuviéramos que resumir la arquitectura de Chiplet Cloud en una oración, lo que tenemos que hacer, sería esta: Tome un motor matemático de matriz cargado de SRAM, masivamente paralelo y a escala de oblea como el diseñado por Cerebras Systems, sosténgalo. en el aire perfectamente nivelado, déjelo caer en el piso frente a usted y luego levante los pequeños rectángulos perfectos y únalos todos nuevamente en un sistema. O más precisamente, en lugar de hacer unidades matemáticas de matriz a escala de obleas con SRAM, haga muchas unidades pequeñas que tengan un costo individual muy bajo y un rendimiento muy alto (lo que también reduce ese costo), y luego vuelva a unirlas usando interconexiones muy rápidas.
El enfoque es similar a la diferencia entre lo que IBM estaba haciendo con su línea BlueGene de sistemas masivamente paralelos, como el BlueGene/Q instalado en el Laboratorio Nacional Lawrence Livermore, y lo que hizo con el hierro pesado GPU en la supercomputadora «Summit» en Laboratorio Nacional de Oak Ridge. BlueGene, muy parecido a los sistemas «K» y «Fugaku» en RIKEN Lab en Japón, a la larga podría haber sido siempre el enfoque correcto, solo que necesitaríamos diferentes procesadores ajustados para el entrenamiento de IA y los cálculos de HPC y para la inferencia de IA.
Hemos estado hablando sobre el enorme costo de construir sistemas para ejecutar modelos de IA generativos basados en transformadores en las últimas semanas, y el artículo de Chiplet Cloud hace un buen trabajo al explicar por qué Amazon Web Services, Meta Platforms y Google han estado tratando de encontrar maneras de hacer sus propios chips para hacer que la inferencia de IA sea menos costosa.
“Servir modelos de lenguaje grande basados en transformadores generativos en hardware básico, como GPU, ya está chocando con un muro de escalabilidad”, escribieron los investigadores, que incluyen a Michael Taylor, Huwan Peng, Scott Davidson y Richard Shi en la Universidad de Washington. “El rendimiento de GPT-3 de última generación en GPU es de 18 tokens/seg por A100. ChatGPT y la promesa de integrar modelos de idiomas grandes en varias tecnologías existentes (p. ej., búsqueda web) cuestionan la escalabilidad y la rentabilidad de los modelos de idiomas grandes. Por ejemplo, la Búsqueda de Google procesa más de 99 000 consultas por segundo. Si GPT-3 está integrado en cada consulta, y suponiendo que cada consulta genera 500 tokens, Google necesita 340 750 servidores Nvidia DGX (2 726 000 GPU A100) para mantenerse al día. El costo de estas GPU supera los $ 40 mil millones solo en gastos de capital. El consumo de energía también será enorme. Suponiendo una utilización del 50 por ciento, la potencia promedio sería de más de 1 gigavatio, que es energía suficiente para alimentar 750 000 hogares”.
El problema con la GPU, cualquier GPU, no solo las creadas por Nvidia, es que son dispositivos de propósito general y, por lo tanto, deben tener muchos tipos diferentes de cómputo para satisfacer todos sus casos de uso. Sabes que esto es cierto porque si no fuera así, las GPU Nvidia solo tendrían procesadores Tensor Core y no motores vectoriales también. E incluso con un dispositivo como el TPU de Google, que es esencialmente solo un procesador Tensor Core, el tamaño y la complejidad del dispositivo, con sus pilas de memoria HBM, hace que sea muy costoso entregarlo incluso si lo hace, al menos según las comparaciones de Microsoft. ofrecen un costo total de propiedad (TCO) mucho mejor que una GPU Nvidia A100. Como esto:
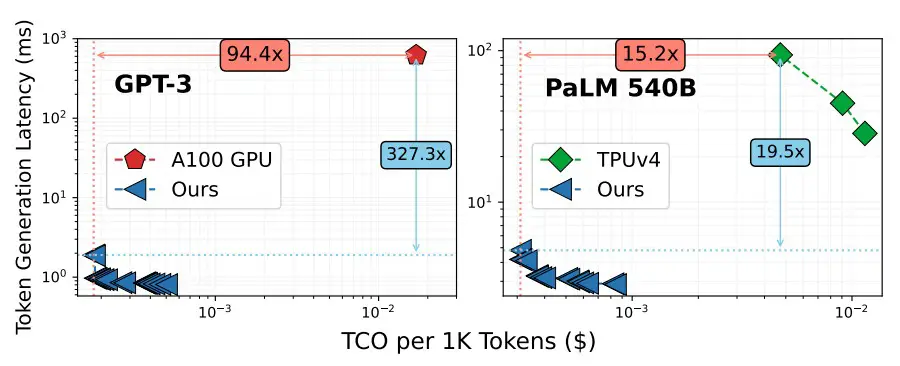
Nota: este documento de Chiplet Cloud obtiene precios para la capacidad A100 en Lamba GPU Cloud y los precios de TPUv4 provienen de Google Cloud, por supuesto.
Y aquí están los datos subyacentes a los puntos de datos de referencia elegidos en el gráfico anterior, que es fascinante:
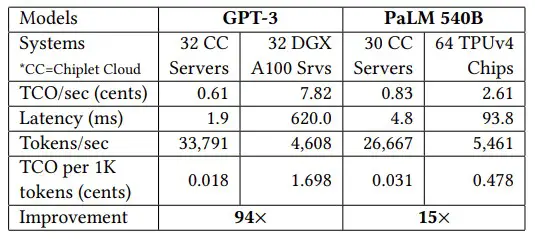
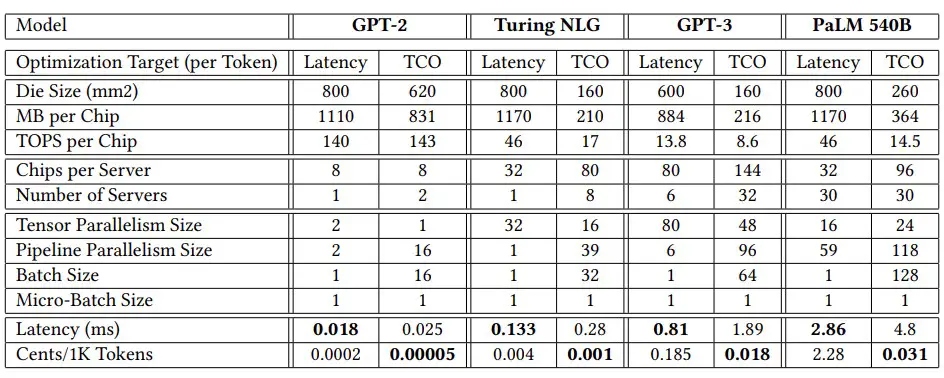
En el modelo GPT-3 con 175 mil millones de parámetros, los dispositivos Chiplet Cloud simulados tuvieron una impresionante reducción de 94,4X en el costo por cada 1000 tokens procesados para la inferencia y una reducción absolutamente sorprendente de 327,3X en la latencia de generación de tokens en comparación con la GPU A100 de Nvidia. Incluso si el rendimiento del H100 es 3,2 veces mayor que el del A100 (que compara el rendimiento de INT8 en el A100 con el FP8 en todo el H100), no tenemos motivos para creer que la latencia será muy diferente incluso con la memoria HBM3 que nosotros un 50 por ciento más rápido. E incluso si lo fuera, el H100 cuesta aproximadamente el doble en la calle de lo que cuesta un A100 en este momento. El H100 estaría abajo ya la izquierda del A100 en el gráfico de arriba, sin duda, pero tiene una brecha muy grande que cerrar.
El cambio a un motor matemático de matriz de estilo de núcleo de tensor con memoria HBM ayuda hasta cierto punto, como muestra el lado derecho del gráfico anterior que muestra el motor de cómputo TPUv4, e incluso con un modelo PaLM mucho más grande con 540 mil millones de parámetros. La Chiplet Cloud teórica de Microsoft muestra una reducción de 15,2X en el costo por cada 1000 tokens generados en ejecución de inferencia y una reducción de 19,5X en la latencia.
En ambos casos, Microsoft está optimizando para obtener un bajo costo por token y pagarlo con una latencia razonable. Y claramente con la arquitectura Chiplet Cloud puede reducir la latencia un poco más si los clientes están dispuestos a pagar un costo proporcionalmente mayor por esas inferencias.
Nos encanta este gráfico, que muestra por qué los hiperescaladores y los creadores de la nube están pensando en ASIC personalizados para la inferencia de IA, especialmente cuando los LLM necesitan tanto ancho de banda de cómputo y memoria para hacer la inferencia:
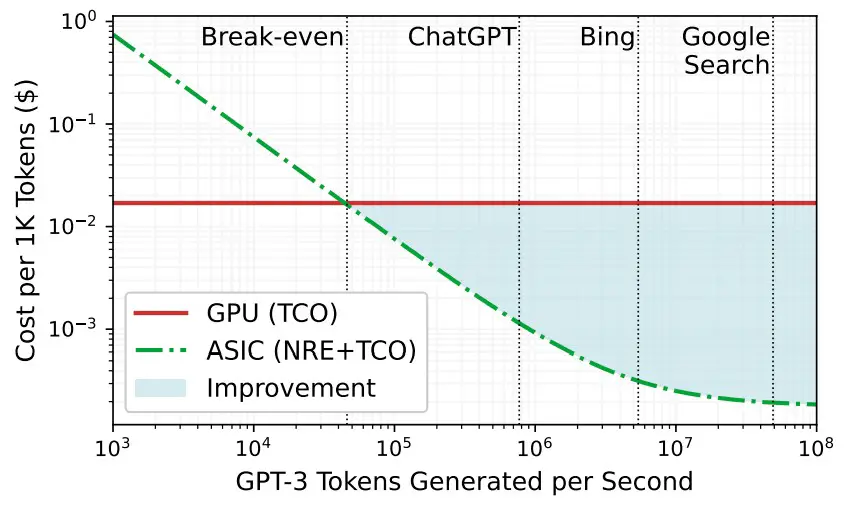
Cuanto más denso sea el trabajo de la IA, mejor será la mejora de costos para usar un ASIC en comparación con el uso de una GPU y, por cierto, este gráfico también sugiere que Microsoft sabe que la búsqueda de Google es mucho más intensiva que la búsqueda de Bing y también de menor costo. (Hmmmmm. . . . No descarte a Bard todavía). El punto de equilibrio entre la GPU y el ASIC personalizado es de alrededor de 46 000 tokens por segundo. Este rendimiento se basó en el propio motor DeepSpeed-Inference de Microsoft que se ejecuta en Lamba GPU Cloud a un costo de $ 1.10 por hora por GPU contra una ejecución de DeepSpeed-Inference en un acelerador Chiplet Cloud simulado.
Al diseñar su Chiplet Cloud, Microsoft y los investigadores de la Universidad de Washington llegaron a algunas conclusiones.
Primero, el costo de producir el chip es una gran parte del costo total de propiedad total de cualquier motor de cómputo.
Según nuestras estimaciones, las GPU representan el 98 % de la capacidad de cómputo y probablemente el 75 % del costo de una supercomputadora HPC/IA moderna. Microsoft calcula que el costo de fabricar un acelerador para la inferencia LLM es de alrededor de $35 millones por un chip grabado en un proceso de 7 nanómetros, que incluye el costo de las herramientas CAD, las licencias de IP, las máscaras, el empaque BGA, los diseños de servidores y la mano de obra. Frente a una inversión potencial de 40.000 millones de dólares, esto es una tontería. Esto es polvo de maní.
Esto significa que no puede usar motores de cómputo que rompan la retícula si desea reducir los costos. Microsoft et al dijeron en el documento que para procesos de 7 nanómetros de Taiwan Semiconductor Manufacturing Co, con una densidad de defectos de 0,1 por cm2el precio unitario de un 750 mm2 el chip es el doble que el de 150 mm2 chip.
En segundo lugar, la inferencia es tanto un problema de ancho de banda de memoria como computacional.
Para aclarar el punto, desafortunadamente al usar un modelo GPT-2 más antiguo y una GPU Nvidia «Volta» V100 igualmente más antigua, la mayoría de los kernels GPT-2 tenían una intensidad operativa baja, lo que significa que no necesitaban muchos fracasos después de todo, y eran limitados. por los 900 GB/seg del ancho de banda HBM2. Además, Microsoft calculó que se necesitarían 85 000 GB/seg (casi dos órdenes de magnitud más de ancho de banda) para impulsar los 112 teraflops de potencia informática en la GPU V100 para ejecutar GPT-2 de manera eficiente.
Y dado esto, el secreto de Chiplet Cloud es exactamente lo que Cerebras Systems, GraphCore y SambaNova Systems ya descubrieron: Obtener los parámetros del modelo y sus resultados de procesamiento intermedio de valor clave que se reciclan para acelerar los modelos generativos en SRAM lo más cerca posible. los motores de matriz matemática como sea posible. La brecha es enorme aquí entre DRAM y HBM:
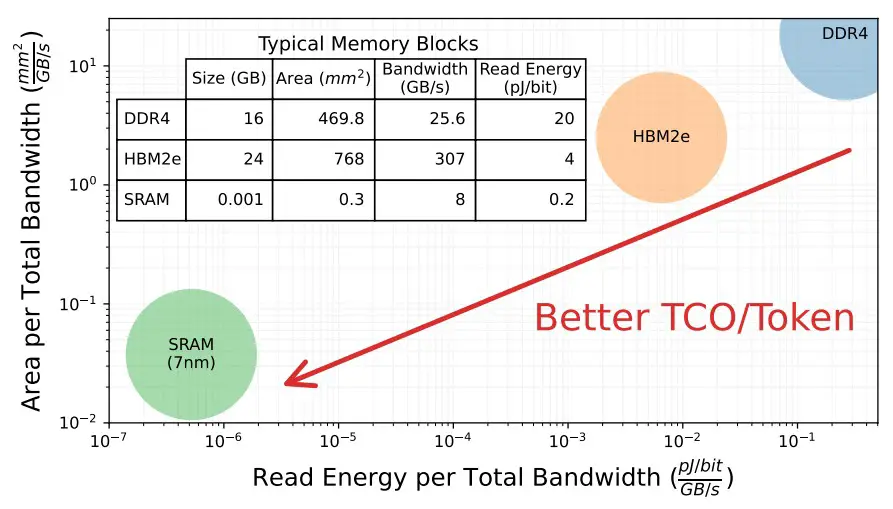
Así que SRAM parece ser una obviedad aquí.
La otra cosa es que Microsoft necesita una forma de mitigar los costos de los paquetes para los diseños de chiplets, así como limitar la comunicación entre chips, lo que aumenta la latencia de inferencia y disminuye el rendimiento. Microsoft utiliza un chiplet como paquete y realiza la integración a nivel de placa, no a nivel de socket, y utiliza estrategias de mapeo de paralelismo de tubería y tensor para reducir la comunicación entre nodos en las placas de Chiplet Cloud. Y cada chiplet tiene suficiente SRAM para contener los parámetros del modelo y la memoria caché KV para todas las unidades computacionales. En efecto, tiene un caché distribuido masivamente que luego es masticado por chiplets individuales a medida que hacen sus propias inferencias únicas.
La Chiplet Cloud propuesta se ve así:
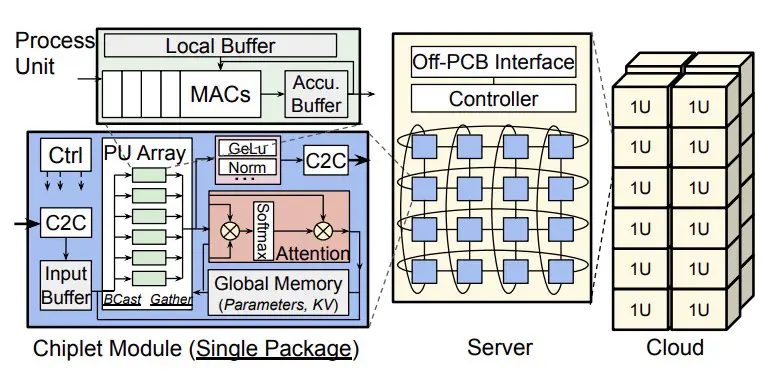
Y no tiene interposición de silicio o integración de sustrato orgánico que aumente el costo y la complejidad y que reduzca el rendimiento a nivel de paquete, lo que también es un problema con estos dispositivos grandes, gordos y maravillosos como GPU y TPU. La placa de chiplet conecta un montón de chiplets en un toroide 2D mediante circuitos impresos, que según Microsoft es lo suficientemente flexible como para adaptarse a diferentes asignaciones de los dispositivos. (Esto es similar a lo que Meta Platforms estaba haciendo en las placas de circuito para sus sistemas de aceleración de GPU usando la conmutación PCI-Express como interconexión). La placa de circuito tiene un controlador FPGA y cada chiplet tiene un enlace full-duplex que funciona a 25 GB. /seg con 80 mm de alcance usando señalización de referencia terrestre. Otros tipos de interconexiones podrían unir los nodos según sea necesario, dice Microsoft.
Microsoft dice que diferentes modelos requerirían diferentes capacidades de memoria y cómputo de chiplet para diferentes modelos y para si están optimizados para latencia o TCO. Lo cual es muy interesante por cierto:
La lección aquí es que una talla nunca sirve para todos. Puede tener algo que tenga un propósito más general, pero siempre paga con menor eficiencia. Los creadores de la nube necesitan dispositivos generales porque nunca saben qué ejecutará la gente, a menos que solo tengan la intención de vender servicios contra una pila de software propietario, en cuyo caso pueden optimizar como locos y ofrecer la mejor relación precio/rendimiento y quedarse con parte del dinero sobrante. lo que solo sucede si no optimizan en exceso, como ganancias.
¿No sería divertido que Microsoft vendiera Google Chiplet Clouds optimizado para ejecutar PaLM 540B? ¿O le robó a los clientes de TPU de Google Cloud con un Chiplet Cloud personalizado adaptado a PaLM 540B?
No estamos seguros de cuánto de esta Chiplet Cloud es aún teoría, o si se está implementando, o si ya ha estado funcionando por un tiempo. No importa cuál sea el caso, Microsoft gastó algo de dinero en investigación y ahora tiene una moneda de cambio contra Nvidia y AMD, y ahora algunos de ustedes que siempre han querido una startup podrían usar este conocimiento para crear un clon de lo que Microsoft tiene. sugirió. Groq hizo eso con la TPU, y el capital de riesgo de la IA parece estar todavía relativamente disponible. ¿Por qué no?

Presentando aspectos destacados, análisis e historias de la semana directamente de nosotros a su bandeja de entrada sin nada en el medio.
Suscríbase ahora