

Figura 1: «Aprendizaje interactivo de flotas» (IFL) se refiere a las flotas de robots en la industria y la academia que recurren a los teleoperadores humanos cuando es necesario y aprenden continuamente de ellos con el tiempo.
En los últimos años hemos visto un desarrollo emocionante en robótica e inteligencia artificial: grandes flotas de robots han salido del laboratorio y han entrado en el mundo real. Waymo, por ejemplo, tiene más de 700 autos sin conductor que operan en Phoenix y San Francisco y actualmente se está expandiendo a Los Ángeles. Otras implementaciones industriales de flotas de robots incluyen aplicaciones como el cumplimiento de pedidos de comercio electrónico en Amazon y Ambi Robotics, así como la entrega de alimentos en Nuro y Kiwibot.

Implementaciones comerciales e industriales de flotas de robots: entrega de paquetes (arriba a la izquierda), entrega de alimentos (abajo a la izquierda), cumplimiento de pedidos de comercio electrónico en Ambi Robotics (arriba a la derecha), taxis autónomos en Waymo (abajo a la derecha).
Estos robots utilizan avances recientes en aprendizaje profundo para operar de forma autónoma en entornos no estructurados. Al agrupar los datos de todos los robots de la flota, toda la flota puede aprender de manera eficiente de la experiencia de cada robot individual. Además, debido a los avances en la robótica en la nube, la flota puede descargar datos, memoria y computación (p. ej., entrenamiento de modelos grandes) a la nube a través de Internet. Este enfoque se conoce como «aprendizaje de flotas», un término popularizado por Elon Musk en comunicados de prensa de 2016 sobre el piloto automático de Tesla y utilizado en comunicados de prensa por parte del Instituto de Investigación de Toyota, Wayve AI y otros. Una flota de robots es un análogo moderno de una flota de barcos, donde la palabra flota tiene una etimología que se remonta a flota (‘barco’) y flotan (‘flotador’) en inglés antiguo.
Sin embargo, los enfoques basados en datos, como el aprendizaje de flotas, enfrentan el problema de la «larga cola»: los robots inevitablemente encuentran nuevos escenarios y casos extremos que no están representados en el conjunto de datos. ¡Naturalmente, no podemos esperar que el futuro sea igual al pasado! Entonces, ¿cómo pueden estas empresas de robótica garantizar la suficiente fiabilidad de sus servicios?
Una respuesta es recurrir a humanos remotos a través de Internet, que pueden tomar el control de forma interactiva y «teleoperar» el sistema cuando la política del robot no es confiable durante la ejecución de la tarea. La teleoperación tiene una rica historia en robótica: los primeros robots del mundo fueron teleoperados durante la Segunda Guerra Mundial para manejar materiales radiactivos, y Telegarden fue pionero en el control de robots a través de Internet en 1994. Con el aprendizaje continuo, los datos de teleoperación humana de estas intervenciones pueden mejorar iterativamente la política de robots. y reducir la dependencia de los robots de sus supervisores humanos con el tiempo. En lugar de un salto discreto a la autonomía total del robot, esta estrategia ofrece una alternativa continua que se acerca a la autonomía total a lo largo del tiempo y, al mismo tiempo, permite la confiabilidad en los sistemas robóticos. hoy.
El uso de la teleoperación humana como mecanismo alternativo es cada vez más popular en las empresas de robótica modernas: Waymo lo llama «respuesta de flota», Zoox lo llama “Teleguiado”, y Amazon lo llama “aprendizaje continuo”. El año pasado, una plataforma de software para conducción remota llamada Phantom Auto fue reconocida por la revista Time como uno de sus 10 mejores inventos de 2022. Y apenas el mes pasado, John Deere adquirió SparkAI, una empresa emergente que desarrolla software para resolver casos extremos con humanos en el bucle.

Un teleoperador humano remoto en Phantom Auto, una plataforma de software para permitir la conducción remota a través de Internet.
Sin embargo, a pesar de esta tendencia creciente en la industria, ha habido comparativamente poco enfoque en este tema en la academia. Como resultado, las empresas de robótica han tenido que confiar en soluciones ad hoc para determinar cuándo sus robots deben ceder el control. El análogo más cercano en el mundo académico es el aprendizaje por imitación interactivo (IIL), un paradigma en el que un robot cede el control de forma intermitente a un supervisor humano y aprende de estas intervenciones con el tiempo. Ha habido una serie de algoritmos IIL en los últimos años para el entorno de un solo robot y un solo ser humano, incluidos DAgger y variantes como HG-DAgger, SafeDAgger, EnsembleDAgger y ThriftyDAgger; sin embargo, cuándo y cómo cambiar entre robot y control humano sigue siendo un problema abierto. Esto se entiende aún menos cuando la noción se generaliza a flotas de robots, con múltiples robots y múltiples supervisores humanos.
Formalismo y algoritmos IFL
Con este fin, en un artículo reciente en la Conferencia sobre Aprendizaje de Robots presentamos el paradigma de Aprendizaje interactivo de flotas (IFL), el primer formalismo en la literatura para el aprendizaje interactivo con múltiples robots y múltiples humanos. Como hemos visto que este fenómeno ya ocurre en la industria, ahora podemos usar la frase «aprendizaje interactivo de flotas» como terminología unificada para el aprendizaje de flotas de robots que se basa en el control humano, en lugar de realizar un seguimiento de los nombres de cada solución corporativa individual. (“respuesta de flota”, “TeleGuidance”, etc.). IFL amplía el aprendizaje de robots con cuatro componentes clave:
- Supervisión bajo demanda. Dado que los humanos no pueden monitorear de manera efectiva la ejecución de múltiples robots a la vez y son propensos a la fatiga, la asignación de robots a humanos en IFL está automatizada por alguna política de asignación $omega$. Los robots solicitan la supervisión «a pedido» en lugar de colocar la carga del monitoreo continuo en los humanos.
- Supervisión de flota. La supervisión a pedido permite la asignación efectiva de atención humana limitada a grandes flotas de robots. IFL permite que la cantidad de robots exceda significativamente la cantidad de humanos (por ejemplo, por un factor de 10:1 o más).
- Aprendizaje continuo. Cada robot de la flota puede aprender de sus propios errores, así como de los errores de los otros robots, lo que permite que la cantidad de supervisión humana requerida disminuya con el tiempo.
- La Internet. Gracias a la tecnología de Internet madura y en constante mejora, los supervisores humanos no necesitan estar físicamente presentes. Las redes informáticas modernas permiten la teleoperación remota en tiempo real a grandes distancias.
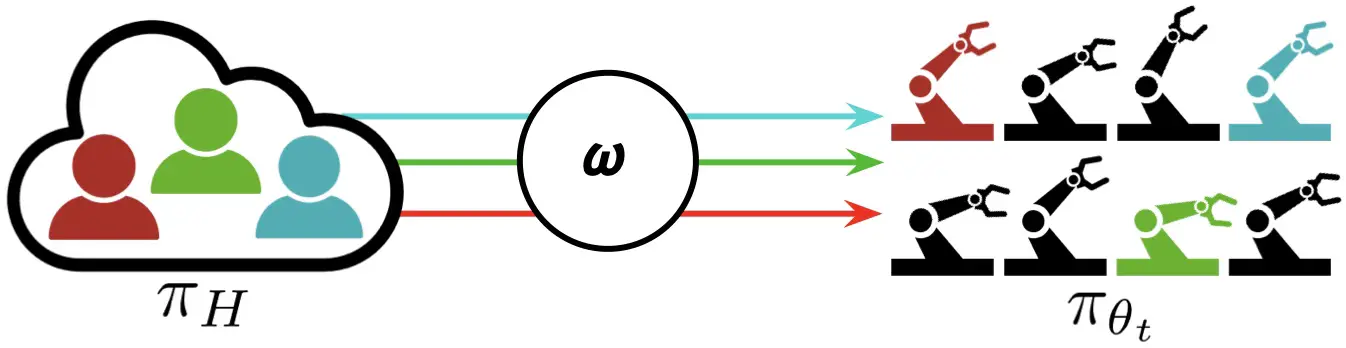
En el paradigma de aprendizaje interactivo de flotas (IFL), se asignan M humanos a los robots que necesitan más ayuda en una flota de N robots (donde N puede ser mucho más grande que M). Los robots comparten la política $pi_{theta_t}$ y aprenden de las intervenciones humanas a lo largo del tiempo.
Suponemos que los robots comparten una política de control común $pi_{theta_t}$ y que los humanos comparten una política de control común $pi_H$. También asumimos que los robots operan en ambientes independientes con estados y espacios de acción idénticos (pero no estados idénticos). A diferencia de un robot enjambre de robots típicamente de bajo costo que se coordinan para lograr un objetivo común en un entorno compartido, un robot flota ejecuta simultáneamente una política compartida en distintos entornos paralelos (por ejemplo, diferentes contenedores en una línea de montaje).
El objetivo de IFL es encontrar una política óptima de asignación de supervisores $omega$, un mapeo de $mathbf{s}^t$ (el estado de todos los robots en el momento t) y la política compartida $pi_{theta_t}$ a una matriz binaria que indica qué humano se asignará a qué robot a la vez t. El objetivo de IFL es una métrica novedosa que llamamos «retorno del esfuerzo humano» (ROHE):
[max_{omega in Omega} mathbb{E}_{tau sim p_{omega, theta_0}(tau)} left[frac{M}{N} cdot frac{sum_{t=0}^T bar{r}( mathbf{s}^t, mathbf{a}^t)}{1+sum_{t=0}^T |omega(mathbf{s}^t, pi_{theta_t}, cdot) |^2 _F} right]]donde el numerador es la recompensa total entre robots y períodos de tiempo y el denominador es la cantidad total de acciones humanas entre robots y períodos de tiempo. Intuitivamente, el ROHE mide el rendimiento de la flota normalizado por la supervisión humana total requerida. Consulte el documento para obtener más detalles matemáticos.
Usando este formalismo, ahora podemos instanciar y comparar algoritmos IFL (es decir, políticas de asignación) de una manera basada en principios. Proponemos una familia de algoritmos IFL llamada Fleet-DAgger, donde el algoritmo de aprendizaje de políticas es un aprendizaje de imitación interactivo y cada algoritmo Fleet-DAgger está parametrizado por una función de prioridad única $hat p: (s, pi_{theta_t}) rightarrow[0infty)$quecadarobotdelaflotautilizaparaasignarseunapuntuacióndeprioridadDemanerasimilaralateoríadelaprogramaciónesmásprobablequelosrobotsdemayorprioridadrecibanatenciónhumanaFleet-DAggereslosuficientementegeneralcomoparamodelarunaampliagamadealgoritmosIFLincluidaslasadaptacionesIFLdealgoritmosIILexistentesdeunsolorobotyunsolohumanocomoEnsembleDAggeryThriftyDAggerTengaencuentasinembargoqueelformalismoIFLnoselimitaaFleet-DAgger:elaprendizajedepolíticaspodríarealizarseconunalgoritmodeaprendizajederefuerzocomoPPOporejemplo[0infty)$thateachrobotinthefleetusestoassignitselfapriorityscoreSimilartoschedulingtheoryhigherpriorityrobotsaremorelikelytoreceivehumanattentionFleet-DAggerisgeneralenoughtomodelawiderangeofIFLalgorithmsincludingIFLadaptationsofexistingsingle-robotsingle-humanIILalgorithmssuchasEnsembleDAggerandThriftyDAggerNotehoweverthattheIFLformalismisn’tlimitedtoFleet-DAgger:policylearningcouldbeperformedwithareinforcementlearningalgorithmlikePPOforinstance
IFL Benchmark y Experimentos
Para determinar cómo asignar mejor la atención humana limitada a grandes flotas de robots, debemos poder evaluar empíricamente y comparar diferentes algoritmos IFL. Con este fin, presentamos IFL Benchmark, un conjunto de herramientas Python de código abierto disponible en Github para facilitar el desarrollo y la evaluación estandarizada de nuevos algoritmos IFL. Ampliamos NVIDIA Isaac Gym, una biblioteca de software altamente optimizada para el aprendizaje de robots acelerado por GPU de extremo a extremo lanzado en 2021, sin el cual la simulación de cientos o miles de robots de aprendizaje sería computacionalmente intratable. Usando IFL Benchmark, llevamos a cabo experimentos de simulación a gran escala con norte = 100 robots, METRO = 10 seres humanos algorítmicos, 5 algoritmos IFL y 3 entornos de control continuo de alta dimensión (Figura 1, izquierda).
También evaluamos algoritmos IFL en una tarea de inserción de bloques basada en imágenes del mundo real con norte = 4 brazos robóticos y METRO = 2 teleoperadores humanos remotos (Figura 1, derecha). Los 4 brazos pertenecen a 2 robots ABB YuMi bimanuales que operan simultáneamente en 2 laboratorios separados aproximadamente 1 kilómetro de distancia, y los humanos remotos en una tercera ubicación física realizan la teleoperación a través de una interfaz de teclado cuando se solicita. Cada robot empuja un cubo hacia una posición objetivo única muestreada aleatoriamente en el espacio de trabajo; los objetivos se generan mediante programación en las observaciones de imágenes aéreas de los robots y se vuelven a muestrear automáticamente cuando se alcanzan los objetivos anteriores. Los resultados de los experimentos físicos sugieren tendencias que son aproximadamente consistentes con las observadas en los entornos de referencia.
Conclusiones y direcciones futuras
Para abordar la brecha entre la teoría y la práctica del aprendizaje de flotas de robots y facilitar la investigación futura, presentamos nuevos formalismos, algoritmos y puntos de referencia para el aprendizaje interactivo de flotas. Dado que IFL no dicta una forma o arquitectura específica para la política de control de robots compartidos, se puede sintetizar de manera flexible con otras direcciones de investigación prometedoras. Por ejemplo, las políticas de difusión, recientemente demostradas para manejar correctamente los datos multimodales, se pueden usar en IFL para permitir políticas heterogéneas de supervisores humanos. Alternativamente, los Transformers condicionados por lenguaje multitarea como RT-1 y PerAct pueden ser «esponjas de datos» efectivas que permiten a los robots de la flota realizar tareas heterogéneas a pesar de compartir una sola política. El aspecto de sistemas de IFL es otra dirección de investigación convincente: los desarrollos recientes en robótica de nube y niebla permiten que las flotas de robots descarguen toda la asignación de supervisores, la capacitación de modelos y la teleoperación colaborativa a servidores centralizados en la nube con una latencia de red mínima.
Si bien la paradoja de Moravec ha impedido hasta ahora que la robótica y la IA incorporada disfruten plenamente del reciente éxito espectacular que han demostrado los Modelos de Lenguaje Grande (LLM) como GPT-4, la «lección amarga» de los LLM es que el aprendizaje supervisado a una escala sin precedentes es lo que finalmente conduce a las propiedades emergentes que observamos. Dado que todavía no tenemos un suministro de datos de control de robots tan abundante como todos los datos de texto e imágenes en Internet, el paradigma IFL ofrece un camino a seguir para ampliar el aprendizaje supervisado de robots y desplegar flotas de robots de manera confiable en el mundo actual.
Esta publicación se basa en el documento «Fleet-DAgger: Interactive Robot Fleet Learning with Scalable Human Supervision» de Ryan Hoque, Lawrence Chen, Satvik Sharma, Karthik Dharmarajan, Brijen Thananjeyan, Pieter Abbeel y Ken Goldberg, presentado en la Conferencia sobre Robots. Learning (CoRL) 2022. Para obtener más detalles, consulte el documento en arXiv, video de presentación de CoRL en YouTube, código base de código abierto en Github, resumen de alto nivel en Twitter y el sitio web del proyecto.
Si desea citar este artículo, utilice el siguiente bibtex:
@article{ifl_blog,
title={Interactive Fleet Learning},
author={Hoque, Ryan},
url={https://bair.berkeley.edu/blog/2023/04/06/ifl/},
journal={Berkeley Artificial Intelligence Research Blog},
year={2023}
}
