
Muchas arquitecturas de redes neuronales que subyacen a varios sistemas de inteligencia artificial hoy en día tienen una interesante similitud con las primeras computadoras de hace un siglo.
Así como las primeras computadoras eran circuitos especializados para fines específicos como la resolución de sistemas lineales o el criptoanálisis, también la red neuronal entrenada funciona generalmente como un circuito especializado para realizar una tarea específica, con todos los parámetros acoplados en el mismo ámbito global.
Uno podría naturalmente preguntarse qué se necesitaría para aprendizaje sistemas a escala en complejidad de la misma manera que programado que tienen los sistemas.
Y si la historia de cómo la abstracción permitió a la informática escalar da algún indicio, un posible lugar para empezar sería considerar lo que significa construir complejos sistemas de aprendizaje en múltiples niveles de abstracción, donde cada nivel de aprendizaje es la consecuencia emergente del aprendizaje de la capa inferior.
Este post discute nuestro reciente documento que introduce un marco para la toma de decisiones de la sociedad una perspectiva sobre el aprendizaje de refuerzo a través de la lente de una sociedad auto-organizada de agentes primitivos.
Demostramos la optimización de un mecanismo de incentivo para la ingeniería de la sociedad para optimizar un objetivo colectivo.
Nuestro trabajo también proporciona evidencia sugerente de que el esquema de asignación de créditos locales de la algoritmos de aprendizaje de refuerzo descentralizados que desarrollamos para entrenar a la sociedad facilita una transferencia más eficiente a nuevas tareas.
Niveles de Abstracción en Sistemas Complejos de Aprendizaje
Desde las corporaciones hasta los organismos, muchos sistemas a gran escala en nuestro mundo están compuestos por componentes autónomos individuales más pequeños, cuya función colectiva sirve a un objetivo mayor que el objetivo de cualquier componente individual por sí solo.
Una corporación, por ejemplo, se optimiza para obtener beneficios como si fuera un único superagente cuando en realidad es una sociedad de agentes humanos interesados, cada uno con preocupaciones que pueden tener poco que ver con el beneficio.
Y cada humano es también simplemente una abstracción de órganos, tejidos y células que se adaptan individualmente y toman sus propias decisiones más simples.
Sabes que todo lo que piensas y haces es pensado y hecho por ti. ¿Pero qué es un «tú»? ¿Qué clase de entidades más pequeñas cooperan dentro de tu mente para hacer tu trabajo?
– Marvin Minsky, La Sociedad de la Mente
El núcleo de la construcción de sistemas complejos de aprendizaje en múltiples niveles de abstracción es comprender los mecanismos que unen los niveles consecutivos.
En el contexto del aprendizaje para la toma de decisiones, esto significa definir tres ingredientes:
- A marco por expresar el encapsulamiento de una sociedad de agentes primitivos como un superagente
- Un mecanismo de incentivo que garantiza la solución óptima para el problema de decisión del superagente surge como consecuencia de que los primitivos optimizan sus problemas de decisión individuales
- A algoritmo de aprendizaje para entrenar implícitamente al superagente entrenando directamente a los primitivos
El mecanismo de incentivo es la barrera de abstracción que conecta los problemas de optimización de los agentes primitivos con el problema de optimización de la sociedad como superagente.

La construcción de sistemas complejos de aprendizaje en múltiples niveles de abstracción requiere definir el mecanismo de incentivo que conecta los problemas de optimización a nivel de agente primitivo con el problema de optimización a nivel de la sociedad. El mecanismo de incentivo es la barrera de abstracción que separa a la sociedad como superagente de sus agentes primitivos constituyentes.
Si fuera posible construir el mecanismo de incentivo de manera que el equilibrio de la estrategia dominante de los agentes primitivos coincidiera con la solución óptima para el superagente, entonces la sociedad puede, en teoría, ser fielmente abstraída como un superagente, que podría entonces servir como primitivo para el siguiente nivel de abstracción, y así sucesivamente, construyendo así en un sistema de aprendizaje los niveles cada vez más altos de complejidad que caracterizan a los sistemas programados de la infraestructura de software moderna.
Una perspectiva de economía de mercado sobre el aprendizaje de refuerzo
Como primer paso hacia este objetivo, podemos trabajar hacia atrás: empezar con un agente, imaginar que es un superagente, y estudiar cómo emular el comportamiento óptimo de tal agente a través de una sociedad de agentes aún más primitivos.
Consideramos un escenario restringido que se basa en los marcos existentes que nos son familiares, los procesos de decisión de Markov (MDP).
Normalmente, el objetivo del aprendiz es maximizar el retorno esperado del MDP.
En el aprendizaje de refuerzo profundo, el enfoque que optimiza directamente este objetivo parametriza la política como una función que mapea los estados a las acciones y ajusta los parámetros de la política de acuerdo con el gradiente del objetivo del MDP.
Nos referimos a este enfoque estándar como el marco monolítico de toma de decisiones porque todos los parámetros aprendidos están acoplados globalmente bajo un único objetivo.
El marco monolítico de toma de decisiones considera el aprendizaje de refuerzo desde la perspectiva de un economía de mandoen el que toda la producción – la transformación de los estados pasados $s_t$ en los estados futuros $s_{t+1}$ – y la distribución de la riqueza – la asignación de crédito de las señales de recompensa a los parámetros – derivan directamente de una única autoridad central – el objetivo del MDP.
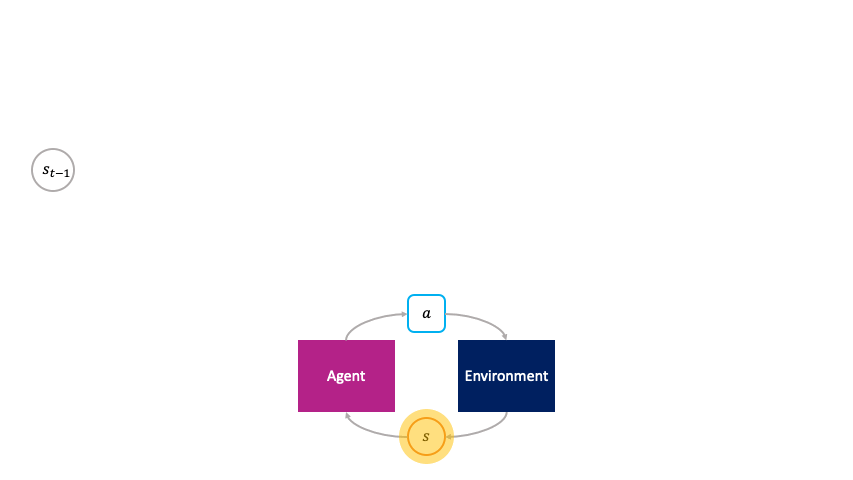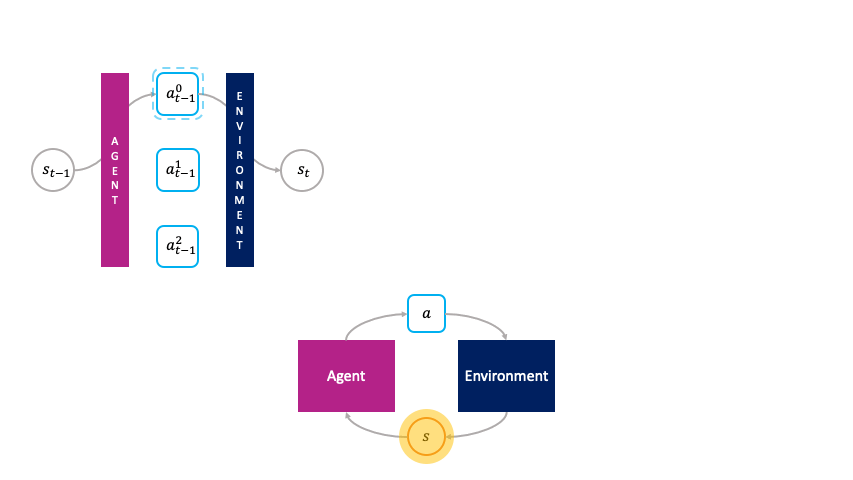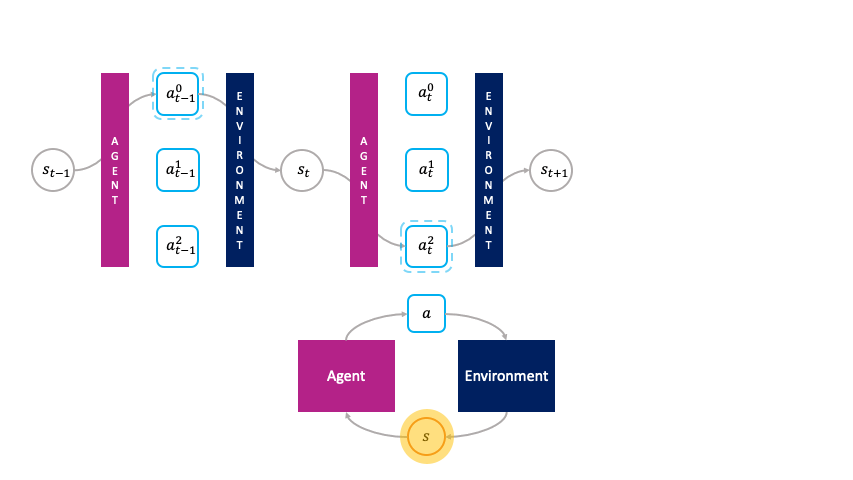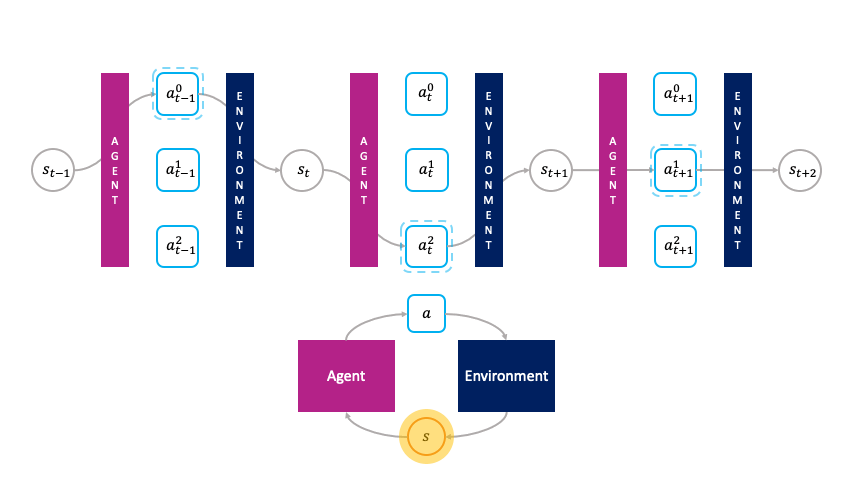
En el marco de la toma de decisiones monolítica, las acciones son elegidas pasivamente por el agente.
Pero como se sugiere en trabajos anteriores que datan de al menos dos décadas, también podemos ver el aprendizaje de refuerzo desde la perspectiva de un economía de mercadoen el que la producción y la distribución de la riqueza se rigen por las transacciones económicas entre acciones que compran y venden estados entre sí.
En lugar de ser elegidos pasivamente por una política global como en el marco monolítico, las acciones son agentes primitivos que eligen activamente ellos mismos cuando activar en el entorno haciendo una oferta en una subasta para transformar el estado $s_t$ al siguiente estado $s_{t+1}$.
Llamamos a esto el la toma de decisiones de la sociedad porque estas acciones forman una sociedad de agentes primitivos que a su vez buscan maximizar su utilidad de subasta en cada estado.
En otras palabras, la sociedad de agentes primitivos forma un superagente que resuelve el MDP como consecuencia de las estrategias de subasta óptimas de los agentes primitivos.
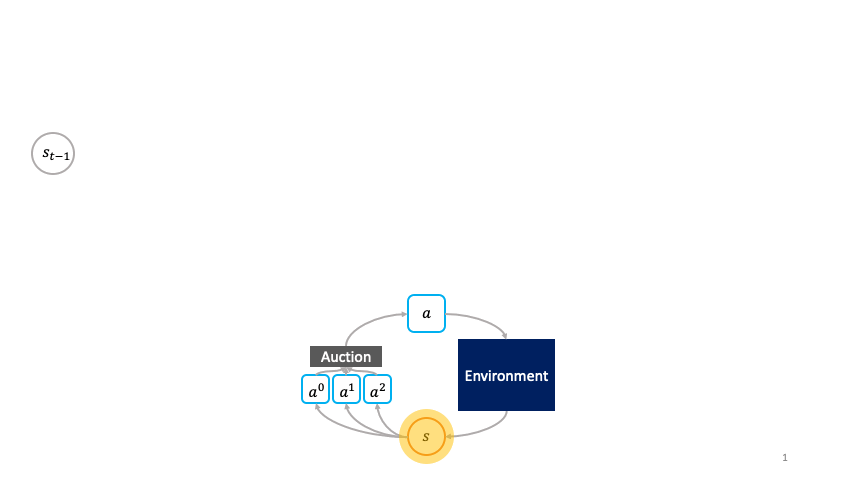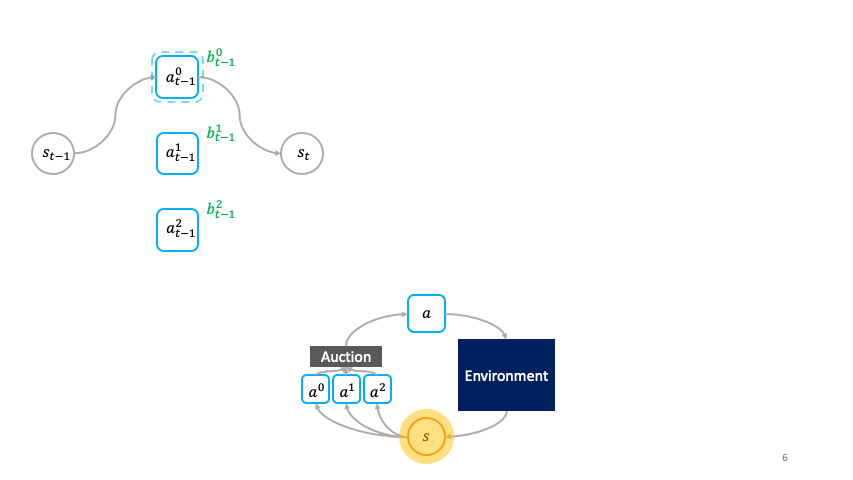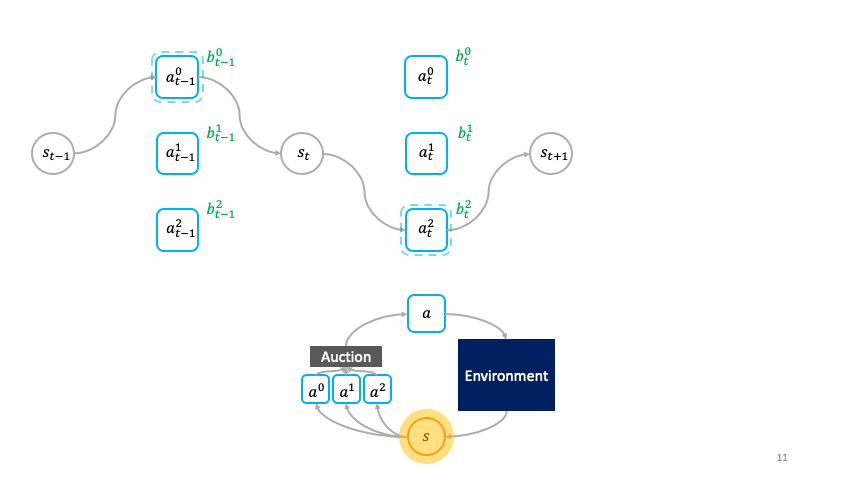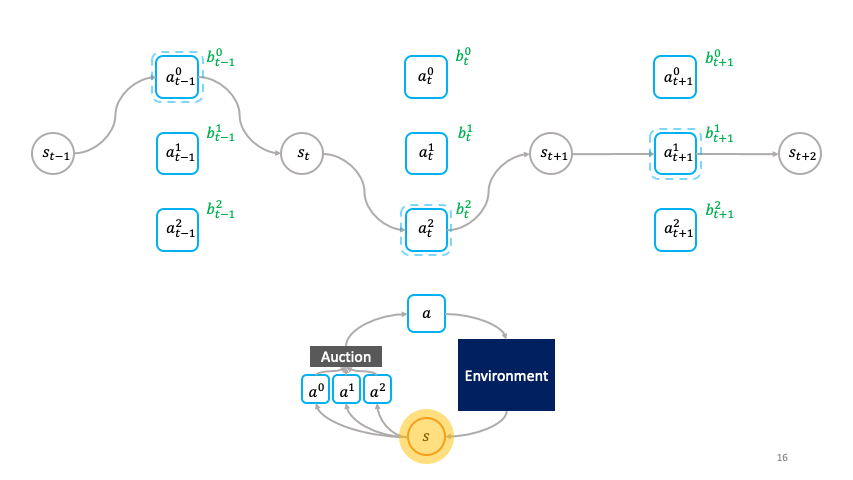
En el marco de la toma de decisiones de la sociedad, las acciones eligen activamente por sí mismas cuándo activarse.
En nuestro trabajo reciente, formalizamos el marco de toma de decisiones de la sociedad y desarrollamos una clase de algoritmos de aprendizaje de refuerzo descentralizados para optimizar el superagente como subproducto de la optimización de las utilidades de subasta de los primitivos.
Mostramos que adaptando la subasta de Vickrey como el mecanismo de subasta e inicializando clones redundantes de cada primitivo se obtiene una sociedad, que llamamos la la sociedad clonada de Vickreycuya estrategia dominante equilibrio de los primitivos optimizando sus utilidades de subasta coincide con la política óptima del superagente que la sociedad representa colectivamente.
En particular, con la siguiente especificación de la utilidad de la subasta, podemos aprovechar la propiedad de veracidad de la subasta de Vickrey para incentivar a los agentes primitivos, que denotaremos por $omega^{1:N}$, para ofertar el valor Q óptimo de su acción correspondiente:
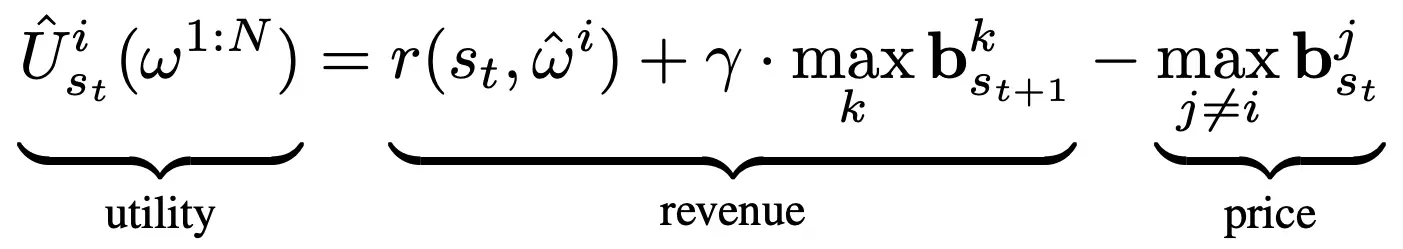
La utilidad para el primitivo con la oferta más alta, que es la que da el ingreso que recibe por la venta de los dólares en la subasta en el siguiente paso temporal menos el precio máximo. mathbf{b}^j_{s_t}$ paga por comprar $s_t$ al ganador de la subasta en el paso de tiempo anterior. Los ingresos son dados por la recompensa ambiental de $r(s_t, ~ -hat {omega}^i)$ más el descuento de la oferta más alta $mathbf{b}^k_{s_t+1}$ en el siguiente paso temporal. De acuerdo con la subasta de Vickrey, el precio es dado por la segunda oferta más alta en el momento actual. La utilidad de los agentes perdedores es de $0$.
Los ingresos que recibe el primitivo ganador por producir $s_{t+1}$ de $s_t$ dependen del precio que el primitivo ganador a $t+1}$ esté dispuesto a ofertar por $s_{t+1}$.
A su vez, el primitivo ganador a $t+1$ vende $s_{t+2}$ al primitivo ganador a $t+2$, y así sucesivamente.
En última instancia, la moneda se basa en la recompensa del medio ambiente.
La riqueza se distribuye en base a lo que los primitivos del futuro deciden pujar por los frutos del trabajo de procesamiento de información realizado por los primitivos del pasado transformando un estado en otro.
Bajo la subasta de Vickrey, la estrategia dominante para cada primitivo es ofertar con veracidad exactamente los ingresos que recibiría.
Con la función de utilidad anterior, la oferta veraz de un primitivo en equilibrio es el valor Q óptimo de su acción correspondiente.
Y como el primitivo con la oferta máxima en la subasta consigue tomar su acción asociada en el medio ambiente, en general la sociedad en equilibrio activa el agente con el mayor valor Q óptimo – la política óptima del súper agente.
Así pues, en el entorno restringido que consideramos, el marco de toma de decisiones de la sociedad, la sociedad clonada de Vickrey y los algoritmos descentralizados de aprendizaje de refuerzo proporcionan respuestas a los tres ingredientes descritos anteriormente para relacionar el problema de aprendizaje del agente primitivo con el problema de aprendizaje de la sociedad.
La toma de decisiones de la sociedad enmarca el aprendizaje de refuerzo estándar desde la perspectiva de los agentes primitivos auto-organizados.
Como discutiremos a continuación, los agentes primitivos no tienen por qué limitarse a acciones literales.
Los agentes pueden ser cualquier cómputo que transforme un estado de uno a otro, incluyendo opciones en semi-MDPs o funciones en gráficos de cómputo dinámico.
Asignación de créditos locales para un aprendizaje y una transferencia más eficientes
Mientras que el aprendizaje en el sistema de economía dirigida de toma de decisiones monolíticas requiere vías de asignación de créditos globales porque todos los parámetros aprendibles están acoplados globalmente, el aprendizaje en el sistema de economía de mercado de toma de decisiones sociales requiere sólo la asignación de créditos que sea local en el espacio y el tiempo porque los primitivos sólo optimizan para su utilidad inmediata en la subasta local sin tener en cuenta el objetivo de aprendizaje global de la sociedad.
De hecho, encontramos pruebas que sugieren que la modularidad inherente al enmarcar el problema de aprendizaje de la sociedad de esta manera ofrece ventajas en la transferencia a nuevas tareas.
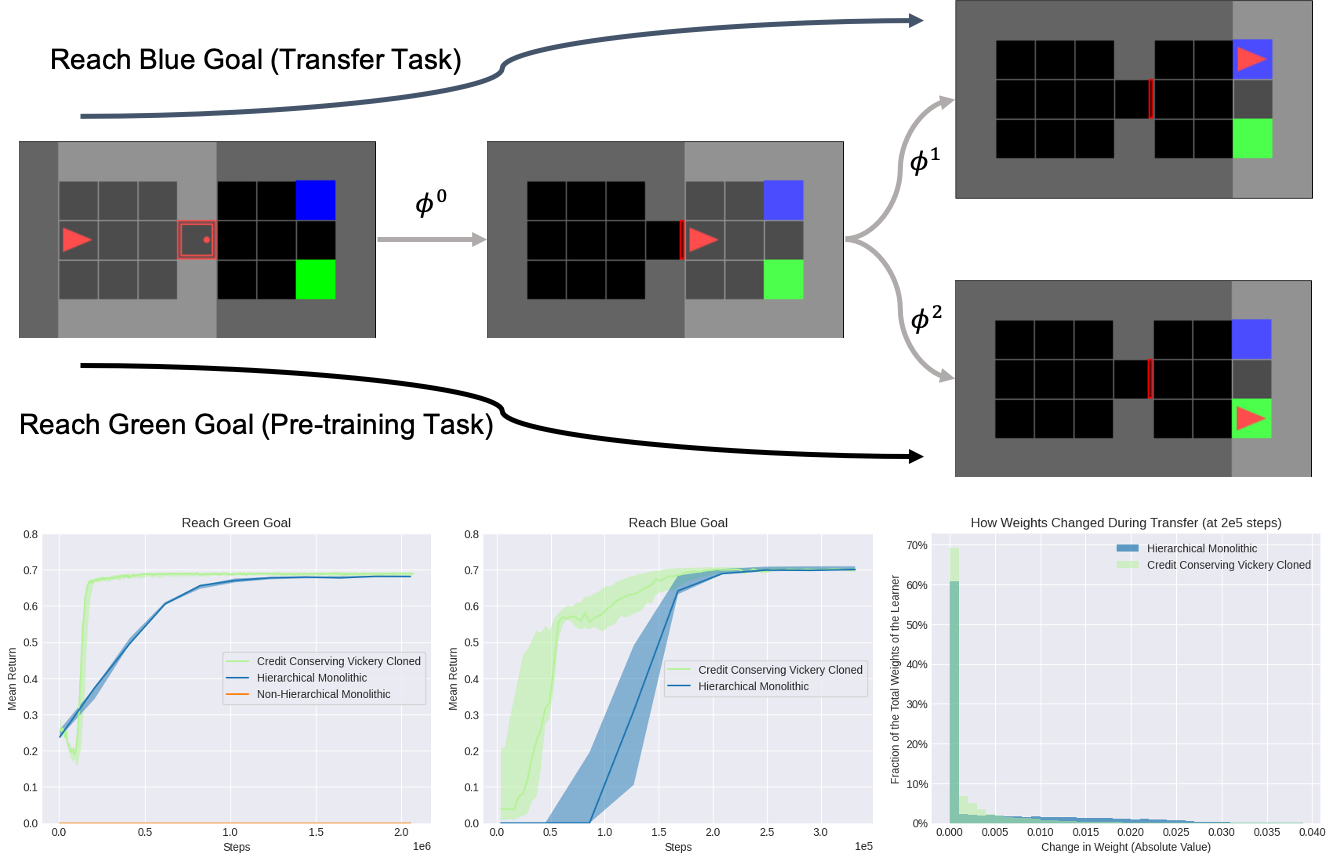
Consideramos la transferencia de la tarea de pre-entrenamiento para alcanzar la meta verde a la tarea de transferencia para alcanzar la meta azul en el ambiente del gimnasio MiniGrid. $phi^0$ representa una opción que abre la puerta roja, $phi^1$ representa una opción que alcanza la meta azul, y $phi^2$ representa una opción que alcanza la meta verde. La primitiva asociada a una opción particular $phi^i$ se activa ejecutando esa opción en el entorno. «Credit Conserving Vickrey Cloned» se refiere a nuestro algoritmo de aprendizaje de refuerzo descentralizado basado en la sociedad, que aprende mucho más eficientemente que tanto una línea base monolítica jerárquica equipada para seleccionar las mismas opciones como una línea base monolítica no jerárquica que sólo selecciona acciones literales.
En particular, observamos que un mayor porcentaje de los pesos de la línea de base monolítica jerárquica se han desplazado durante la transferencia en comparación con nuestro método, lo que sugiere que los pesos de la línea de base monolítica jerárquica están más globalmente acoplados y tal vez, por lo tanto, es más lenta la transferencia.
Solución de problemas por vía analógica
Resolver un problema significa simplemente representarlo para que la solución sea transparente.
– Herbert Simon, La ciencia del diseño: La creación de lo artificial.
La representación de una observación como un ejemplo de lo que es más familiar ha sido un importante tema de estudio en la cognición humana desde la perspectiva de la elaboración de analogías.
Un ejemplo particularmente intuitivo de este fenómeno son las rotaciones mentales estudiadas por Roger Shepard que sugerían que los humanos parecían componer operaciones de rotación mental en su mente para ciertos tipos de reconocimiento de imágenes.
Inspirándonos en estos trabajos anteriores, consideramos una tarea de reconocimiento de imágenes basada en trabajos anteriores en los que definimos cada agente primitivo como representante de una transformación afín diferente.
Utilizando la precisión de clasificación de un clasificador digital MNIST como única señal de recompensa, la sociedad de los primitivos aprende a emular el proceso de creación de analogías mediante la representación iterativa de imágenes desconocidas en otras más familiares que el clasificador sabe clasificar.
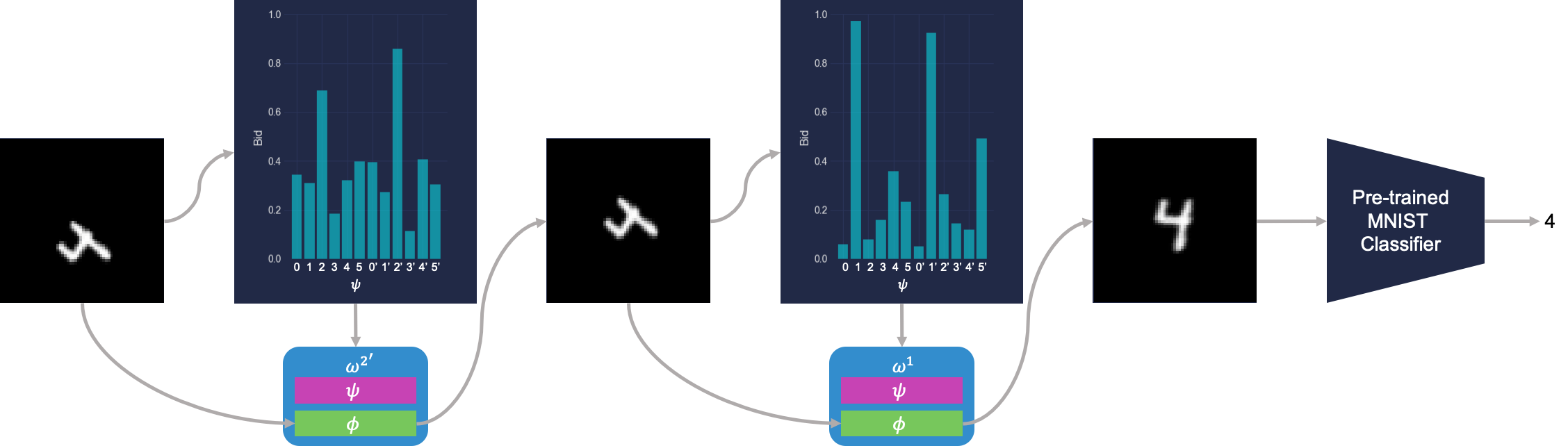
La sociedad aprende a clasificar los dígitos transformados haciendo analogías con la contraparte canónica del dígito. Aquí $omega$ representa un agente primitivo, $psi$ representa la política de oferta de ese agente, y $phi$ representa la transformación afín de ese agente. Esta figura muestra una sociedad con primitivos redundantes, donde los clones se indican con un apóstrofe. Los beneficios de la redundancia para la robustez se discuten en el documento.
Mirando hacia adelante
Modelar la inteligencia en varios niveles de abstracción tiene sus raíces en los primeros cimientos de la IA, y modelar la mente como una sociedad de agentes se remonta a la República de Platón.
En este escenario restringido donde los agentes primitivos buscan maximizar la utilidad en las subastas y la sociedad busca maximizar el retorno en el MDP, tenemos ahora una pequeña pieza del rompecabezas hacia la construcción de complejos sistemas de aprendizaje en múltiples niveles de abstracción.
Quedan muchas más piezas por resolver.
En cierto sentido, estos complejos sistemas de aprendizaje crecen más que se construyen porque cada componente en cada capa de abstracción es aprendizaje.
Pero de la misma manera que la metodología de programación surgió como una disciplina para definir las mejores prácticas para la construcción de sistemas programados complejos, también necesitaremos especificar, construir y probar el andamiaje que guía el crecimiento de los sistemas complejos de aprendizaje.
Este tipo de aprendizaje profundo no sólo es profundo en los niveles de representación, sino también en los niveles de aprendizaje.
Este post está basado en el siguiente documento:
Michael Chang quiere agradecer a Matt Weinberg, Tom Griffiths y Sergey Levine por su orientación en este proyecto, así como a Michael Janner, Anirudh Goyal y Sam Toyer por las discusiones que inspiraron muchas de las ideas escritas aquí.
Referencias
-
- Ilya Sutskever: Meta-aprendizaje y auto-juego de OpenAI | MIT Artificial General Intelligence (AGI). 2018.
- Barbara Liskov, 2007 ACM A.M. Turing Award Lecture «The Power of Abstraction». 2013.
- Inteligencia Social | Blaise Aguera y Arcas | NeurIPS 2019. 2020.
- Minsky, Marvin. La Sociedad de la Mente. 1988.
- Baum, Eric B. Hacia un modelo de mente como una economía de laissez-faire de los idiotas. 1995.
- Schmidhuber, Juergen. Modelos de mercado para el aprendizaje automático – Refuerzo de las economías de aprendizaje.
- Holland, John H. Propiedades de la Brigada de los Cubos. 1985.
- Simon, Herbert A. La ciencia del diseño: Creando lo artificial. 1988.
- Mitchell, Melanie. La analogía como percepción: Un modelo de computadora. 1993.
- Hofstadter, Douglas R. La analogía como el núcleo de la cognición. 2001.
- Shepard, Roger N. y Jacqueline Metzler. Rotación mental de objetos tridimensionales. 1971.
- Chang, Michael B., et al. Composición automática de transformaciones de representación como medio de generalización. 2019.
