




Nuestro método aprende comportamientos complejos entrenando fuera de línea de los datos anteriores.
(demostraciones de expertos, datos de experimentos anteriores, o exploración aleatoria
datos) y luego afinar rápidamente con la interacción en línea.
Los robots entrenados con aprendizaje de refuerzo (RL) tienen el potencial de ser utilizados
a través de una enorme variedad de desafiantes problemas del mundo real. Para aplicar RL a un nuevo
problema, típicamente se configura el entorno, se define una función de recompensa, y
entrenar al robot para resolver la tarea permitiéndole explorar el nuevo entorno
desde el principio. Aunque esto puede funcionar eventualmente, estos métodos de RL «en línea» son
datos hambrientos y repetir este proceso ineficiente de datos para cada nuevo problema
dificulta la aplicación de RL en línea a los problemas de la robótica en el mundo real. ¿Y si
en lugar de repetir la recopilación de datos y el proceso de aprendizaje desde cero
cada vez, fuimos capaces de reutilizar los datos a través de múltiples problemas o experimentos?
Al hacerlo, pudimos reducir en gran medida la carga de la recopilación de datos con cada
nuevo problema que se encuentra. Con cientos o miles de robots
experimentos que se llevan a cabo constantemente, es de crucial importancia diseñar un RL
que puede utilizar eficazmente la gran cantidad de datos ya disponibles
mientras sigue mejorando el comportamiento en nuevas tareas.
El primer paso para hacer avanzar a RL hacia un paradigma impulsado por los datos es considerar
la idea general de la RL fuera de línea (por lotes). RL fuera de línea considera el problema de
aprender políticas óptimas a partir de datos arbitrarios fuera de las políticas, sin más
exploración. Esto es capaz de eliminar el problema de la recolección de datos en RL, y
incorporar datos de fuentes arbitrarias, incluyendo otros robots o
teleoperación. Sin embargo, dependiendo de la calidad de los datos disponibles y de la
problema que se está abordando, a menudo tendremos que aumentar el entrenamiento fuera de línea con
mejora de la línea dirigida. Este entorno de problemas tiene en realidad una
desafíos propios. En esta entrada del blog, discutimos cómo podemos mover a RL de
entrenando desde cero con cada nuevo problema a un paradigma que es capaz de
reutilizar eficazmente los datos anteriores, con cierta capacitación fuera de línea seguida de una capacitación en línea
…afinando.
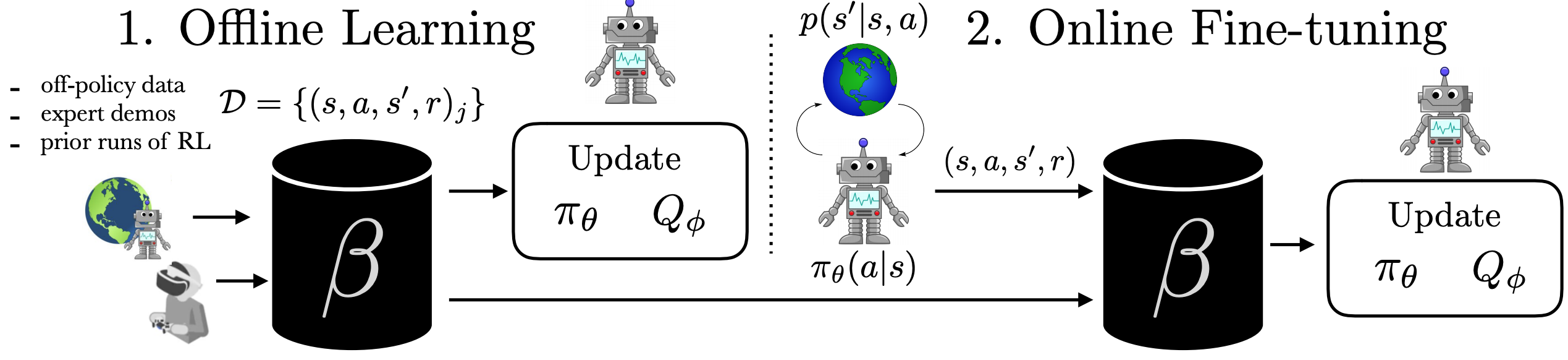
Figura 1: El problema de acelerar la RL en línea con los conjuntos de datos fuera de línea. En
(1), el robot aprende una política completamente de un conjunto de datos fuera de línea. En (2), el
el robot puede interactuar con el mundo y recoger muestras de la política para mejorar
la política más allá de lo que podría aprender fuera de línea.
Analizamos los desafíos en el problema de aprender de los datos fuera de línea y
el posterior ajuste, utilizando el estándar de referencia de la locomoción de HalfCheetah
tarea. Los siguientes experimentos se llevan a cabo con un conjunto de datos previos que consisten en
de 15 demostraciones de una política de expertos y 100 trayectorias subóptimas
muestreado de un clon de comportamiento de estas demostraciones.
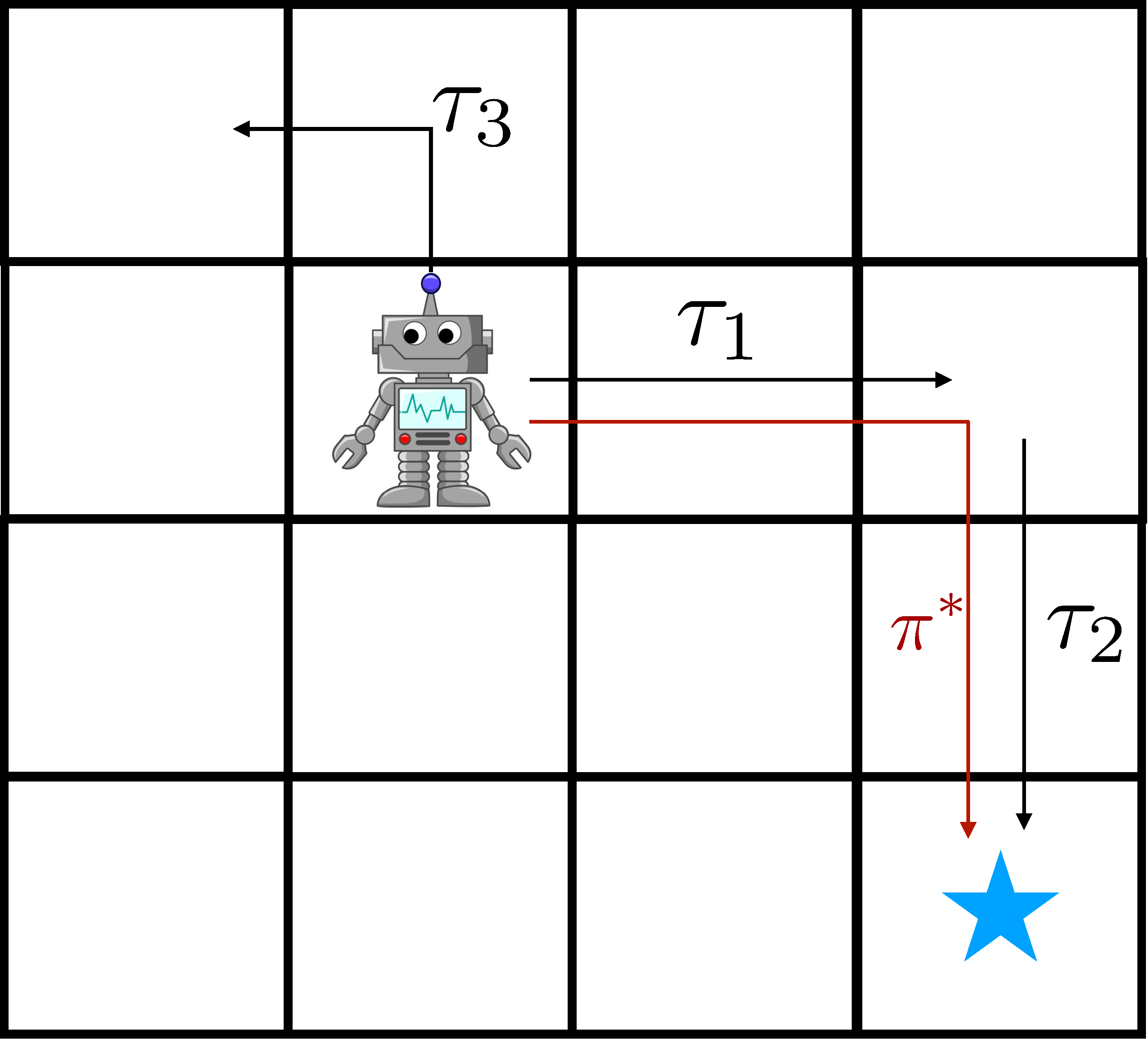

Figura 2: Los métodos con política son lentos de aprender comparados con los que no la tienen.
debido a la capacidad de los métodos fuera de la política de «coser» buenas trayectorias
juntos, ilustrados a la izquierda. Derecha: en la práctica, vemos que la lentitud en línea
mejora usando métodos de política de encendido.
1. Eficiencia de los datos
Una forma sencilla de utilizar los datos anteriores, como las demostraciones para RL, es
pre-entrenar una política con aprendizaje de imitación, y afinarla con la política de RL
algoritmos como AWR o DAPG.
Esto tiene dos inconvenientes. Primero, los datos anteriores pueden no ser óptimos, así que la imitación
el aprendizaje puede ser ineficaz. En segundo lugar, el ajuste de las políticas es ineficiente en cuanto a los datos
ya que no reutiliza los datos anteriores en la etapa RL. Para la robótica del mundo real,
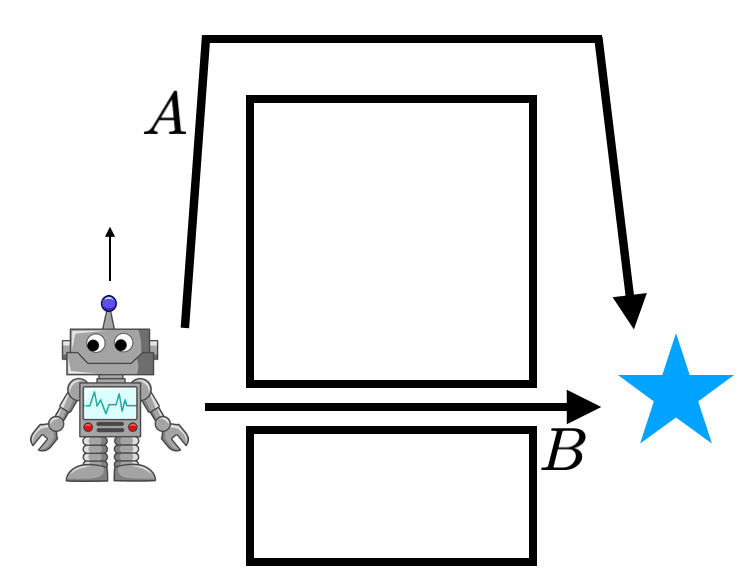
La eficiencia de los datos es vital. Considere el robot de la derecha, tratando de llegar a la
estado de la meta con trayectoria previa $tau_1$ y $tau_2$. Los métodos de la política
no pueden utilizar eficazmente estos datos, pero los algoritmos fuera de la política que hacen dinámicos
la programación puede, al «coser» efectivamente $tau_1$ y $tau_2$ junto con
el uso de una función o modelo de valor. Este efecto se puede ver en el aprendizaje
las curvas de la figura 2, donde los métodos de política de encendido son un orden de magnitud más lento
que los métodos críticos de los actores fuera de la política.
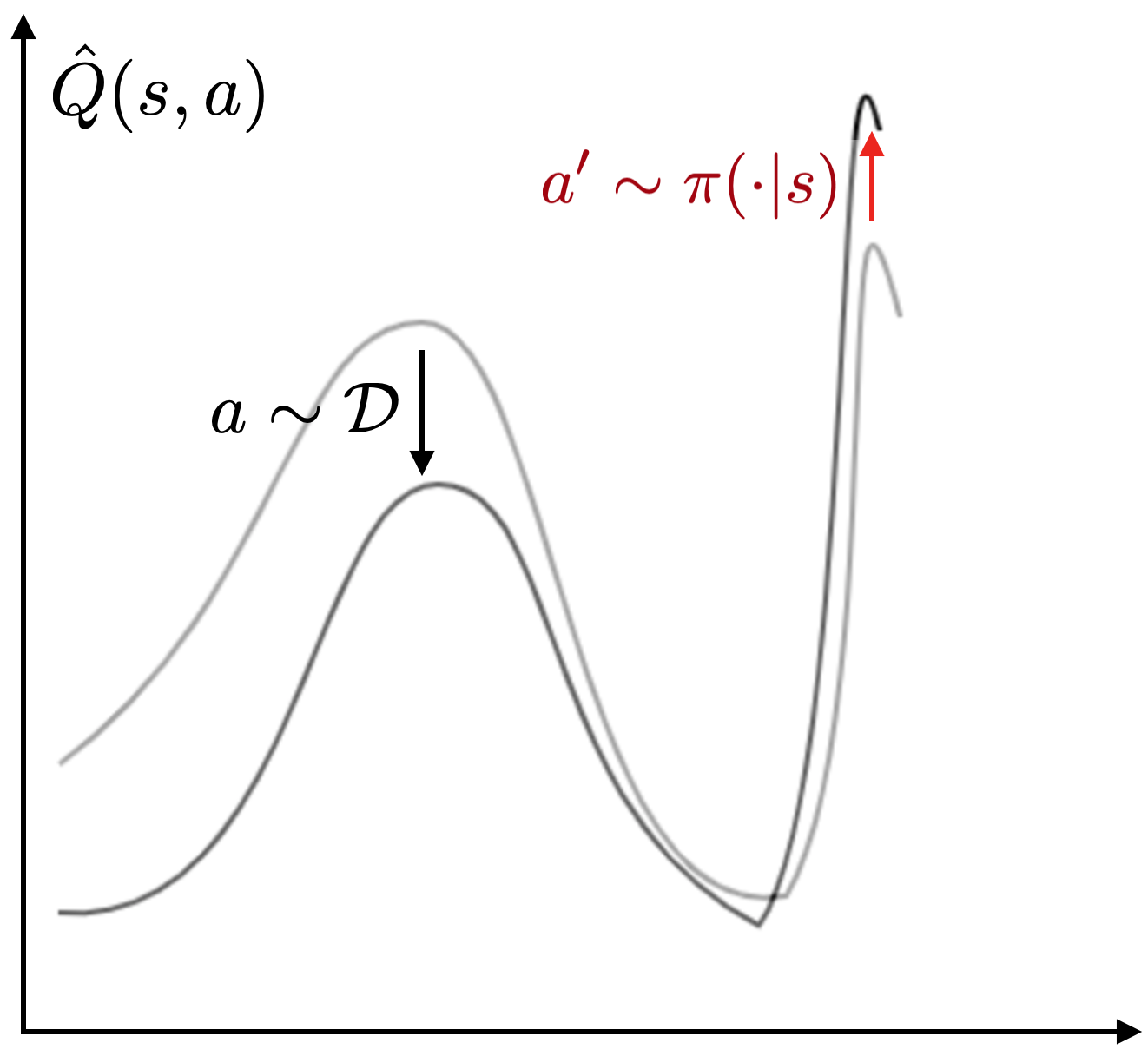
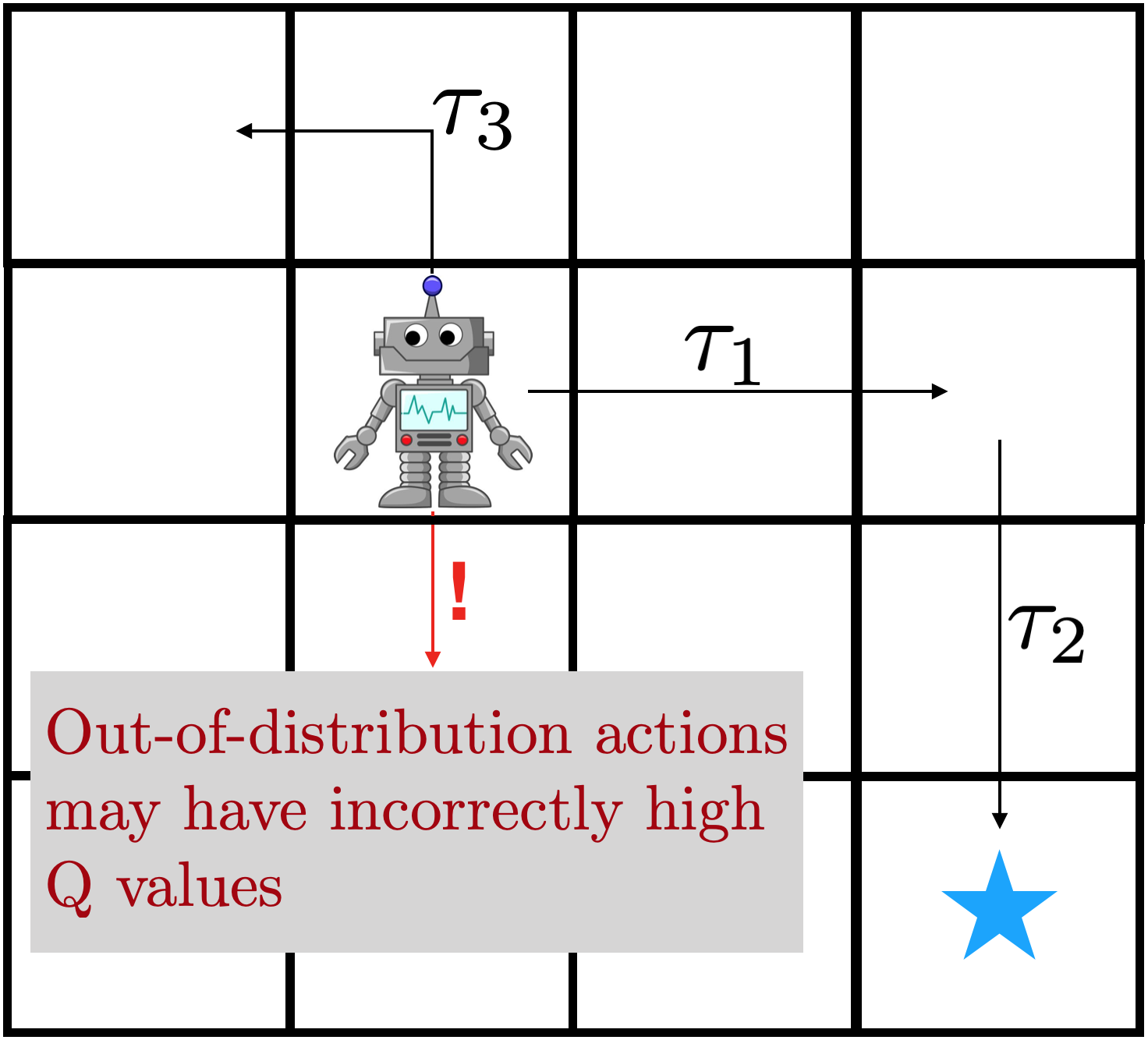
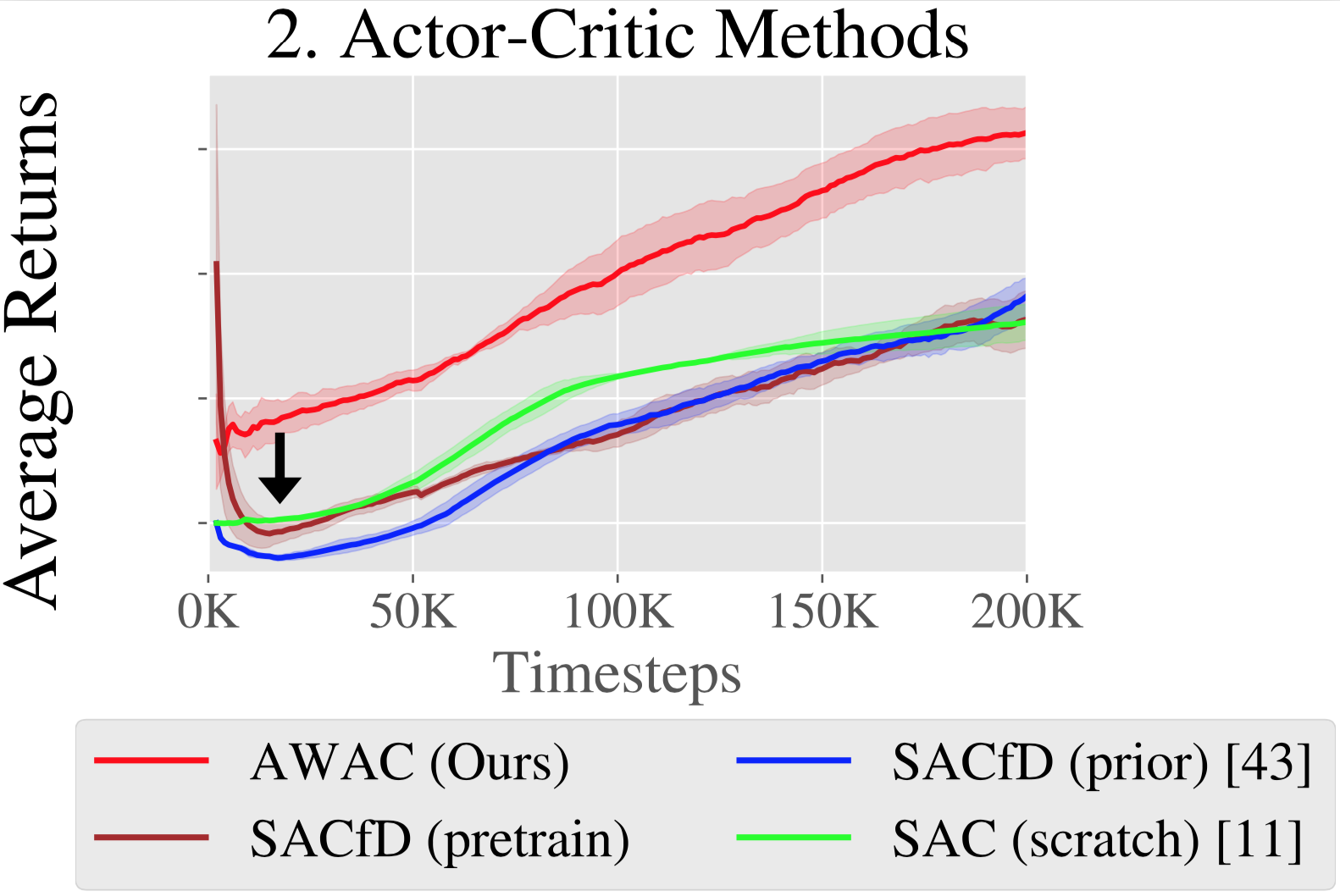
Figura 3: El error de bootstrapping es un problema cuando se usa la RL fuera de la política para
entrenamiento fuera de línea. Izquierda: un valor Q erróneo lejos de los datos es
explotado por la política, lo que resulta en una pobre actualización de la función Q. Medio:
como resultado, el robot puede tomar acciones que están fuera de la distribución. Correcto:
El error de bootstrap causa un pobre preentrenamiento fuera de línea cuando se usa SAC y su
variantes.
2. 2. Error de Bootstrapping
Los métodos críticos con los actores pueden, en principio, aprender eficientemente de los datos fuera de la política mediante
estimando un valor estimado $V(s)$ o una estimación de valor de acción $Q(s, a)$ de futuro
regresa por el Bellman bootstrapping. Sin embargo, cuando el estándar fuera de la política
los métodos de la crítica de actores se aplican a nuestro problema (usamos SAC), se desempeñan mal, como se muestra
en la figura 3: a pesar de tener un conjunto de datos anterior en el buffer de reproducción, estos
Los algoritmos no se benefician significativamente de la capacitación fuera de línea (como se ve en la
comparación entre las líneas SAC(scratch) y SACfD(prior) en la figura 3).
Además, incluso si la política está pre-entrenada por la clonación de comportamiento («SACfD»)
(pre-entrenamiento)») todavía observamos una disminución inicial en el rendimiento.
Este desafío puede atribuirse a un error de bootstrapping fuera de la política
acumulación. Durante el entrenamiento, las estimaciones de Q no serán totalmente exactas,
particularmente en la extrapolación de acciones que no están presentes en los datos. El
La actualización de la política explota los valores Q sobreestimados, haciendo que los valores Q estimados
peor. El problema se ilustra en la figura: los valores Q incorrectos dan como resultado un
actualización incorrecta de los valores de Q del objetivo, lo que puede resultar en que el robot tome una
mala acción.
3. Modelos de comportamiento no estacionario
Algoritmos anteriores de RL fuera de línea como BCQ, BEAR, y BRAC proponen abordar la
cuestión del bootstrapping evitando que la política se aleje demasiado de la
datos. La idea clave es evitar el error de bootstrapping limitando la política
cerca de la «política de comportamiento»: las acciones que están presentes
en el buffer de reproducción. La idea se ilustra en la siguiente figura: por muestreo
acciones de $pi_beta$, evitas explotar valores Q incorrectos lejos de
la distribución de los datos.
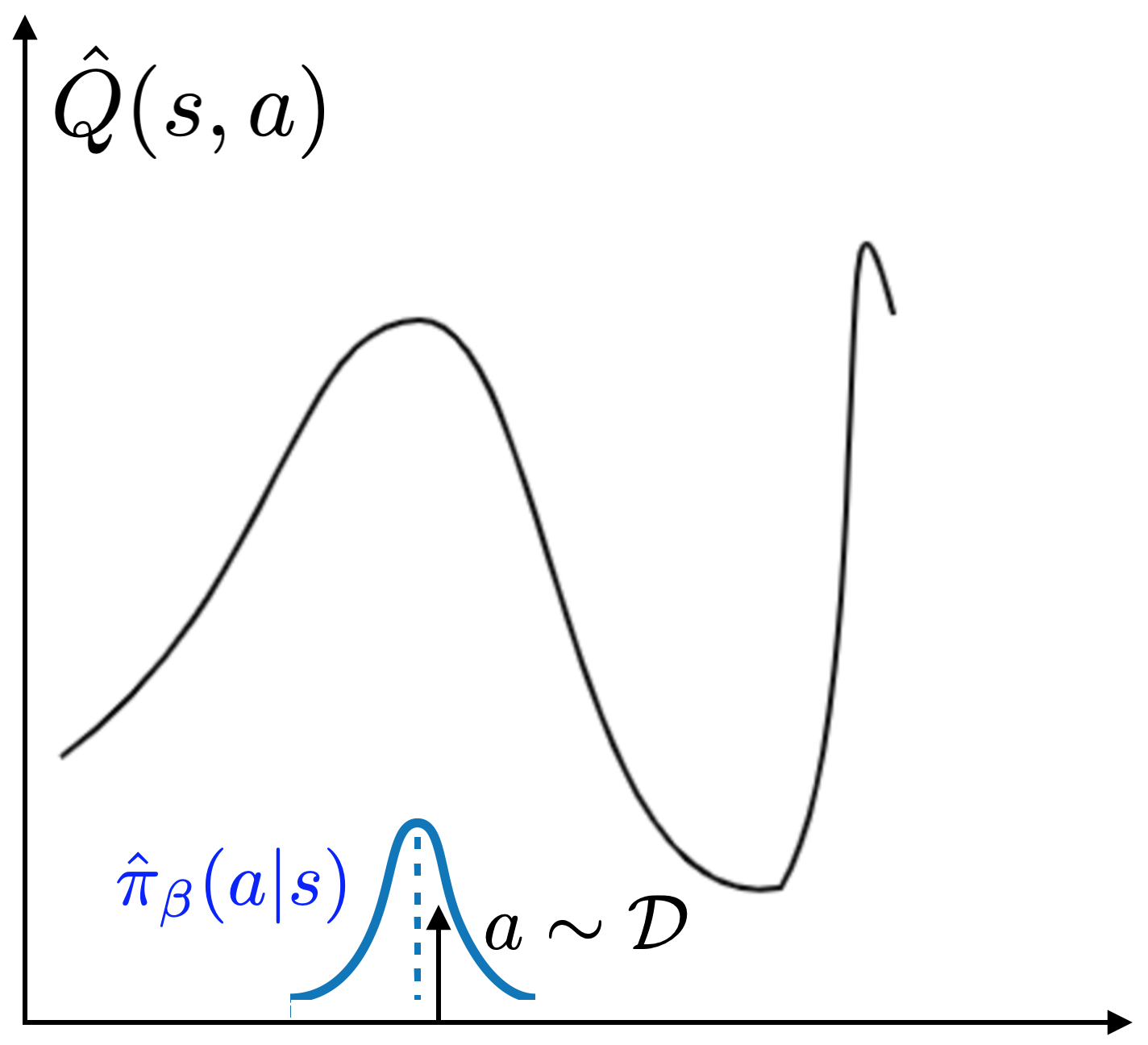
Sin embargo, normalmente no se conoce $pi_beta$, especialmente para los datos fuera de línea, y
debe ser estimada a partir de los datos mismos. Muchos algoritmos RL fuera de línea (BEAR, BCQ,
ABM) encajan explícitamente en un sistema paramétrico
a las muestras de la memoria intermedia de reproducción para la distribución… Después de
formando una estimación $\N-que {i}_beta$, los métodos previos implementan la política
de varias maneras, incluyendo penalizaciones en la actualización de la política (BEAR,
BRAC) o las elecciones de arquitectura para las acciones de muestreo para la formación de políticas (BCQ,
ABM).
Mientras que los algoritmos RL con restricciones funcionan bien fuera de línea, ellos
lucha por mejorar con el ajuste fino, como se muestra en el tercer gráfico de la figura 1.
Vemos que el rendimiento de la RL puramente fuera de línea (en «0K» en la Fig.1) es mucho
mejor que el SAC. Sin embargo, con iteraciones adicionales de ajuste en línea, el
El rendimiento aumenta muy lentamente (como se ve en la pendiente de la curva del OSO en
Fig 1). ¿Qué causa este fenómeno?
El problema está en ajustar un modelo de comportamiento preciso a medida que se recogen los datos en línea
durante el ajuste. En la configuración offline, los modelos de comportamiento sólo deben ser
entrenado una vez, pero en el entorno online, el modelo de comportamiento debe ser actualizado
en línea para rastrear los datos entrantes. Los modelos de densidad de entrenamiento en línea (en el
de «streaming») es un problema de investigación desafiante, que se hace más difícil por
una distribución de comportamiento multimodal potencialmente compleja inducida por la mezcla
de datos en línea y fuera de línea. Con el fin de abordar nuestra configuración de problemas, requerimos
un algoritmo RL fuera de la política que limita la política para evitar la desconexión
inestabilidad y acumulación de errores, pero no es tan conservador como para impedir
de ajuste en línea debido a un modelo de comportamiento imperfecto. Nuestro algoritmo propuesto,
que discutiremos en la siguiente sección, lo logra empleando un
restricción implícita, que no requiere ningún modelo explícito de la
política de comportamiento.
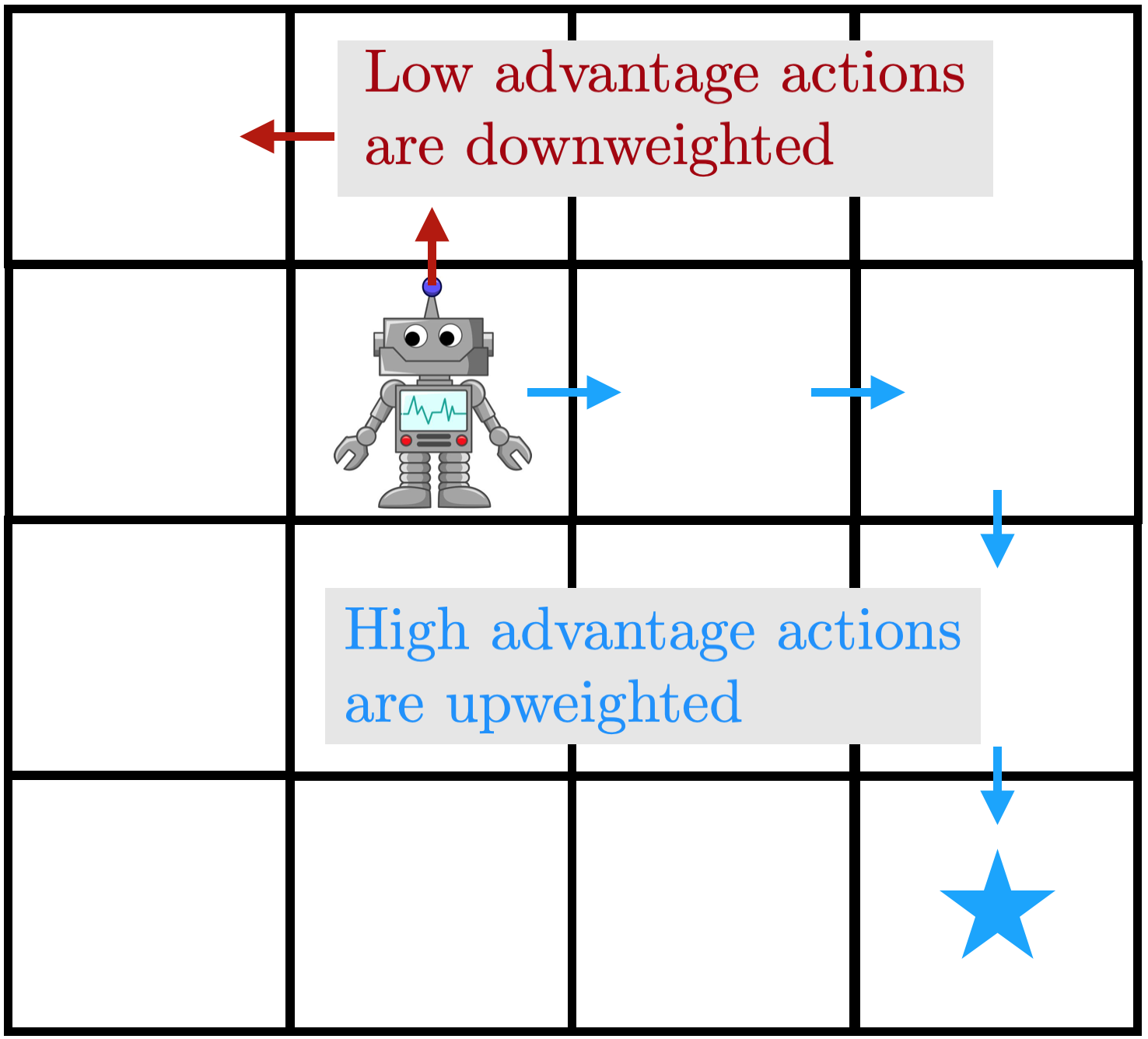

Figura 4: una ilustración de AWAC. Las transiciones de alta ventaja son retrocedidas
con alto peso, mientras que las transiciones de baja ventaja tienen bajo peso. Bien:
pseudocódigo de algoritmo.
Para evitar estos problemas, proponemos un algoritmo extremadamente simple –
crítico de actores con ventaja (AWAC). AWAC evita las trampas en el
sección anterior con decisiones de diseño cuidadosas. Primero, para la eficiencia de los datos, el
El algoritmo entrena a un crítico que está entrenado con programación dinámica. Ahora, ¿cómo
¿podemos usar este crítico para el entrenamiento fuera de línea mientras evitamos el bootstrapping
problema, evitando al mismo tiempo modelar la distribución de los datos, que puede ser
¿Inestable? Para evitar el error de bootstrapping, optimizamos el siguiente problema:
Podemos calcular la solución óptima para esta ecuación y proyectar nuestra política
en él, lo que resulta en la siguiente actualización del actor:
Esto resulta en una actualización intuitiva del actor, que también es muy eficaz en
…la práctica. La actualización se asemeja a la clonación de comportamiento ponderado; si la función Q fuera
…desinformativo, se reduce a la clonación de comportamiento del buffer de reproducción. Pero con un
bien formada estimación de Q, ponderamos la política hacia sólo buenas acciones. Un
La ilustración se da en la figura de arriba: el agente regresa a
acciones de alta ventaja con un gran peso, mientras que casi ignora las de baja ventaja
acciones. Por favor, vea el documento para una derivación y aplicación ampliadas
detalles.
Entonces, ¿qué tan bien funciona esto para abordar nuestras preocupaciones de antes? En
nuestros experimentos, mostramos que podemos aprender difíciles, de alta dimensión, escasos
recompensar los problemas de manipulación diestra de las demostraciones humanas y fuera de la política
datos. Luego evaluamos nuestro método con datos previos subóptimos generados por un
controlador aleatorio. Los resultados de los entornos estándar de referencia de MuJoCo
(HalfCheetah, Walker y Ant) también se incluyen en el documento.
Manipulación diestra


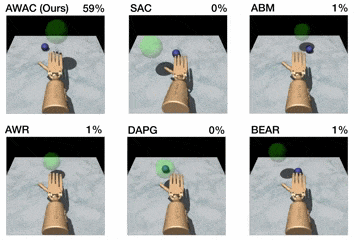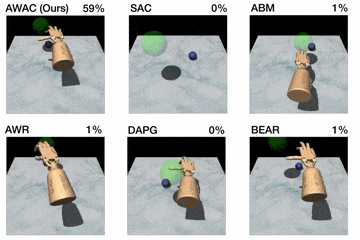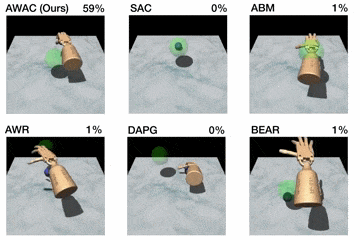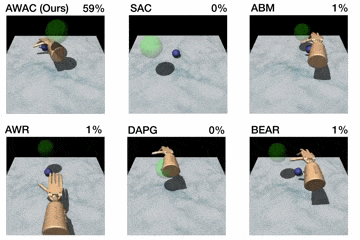
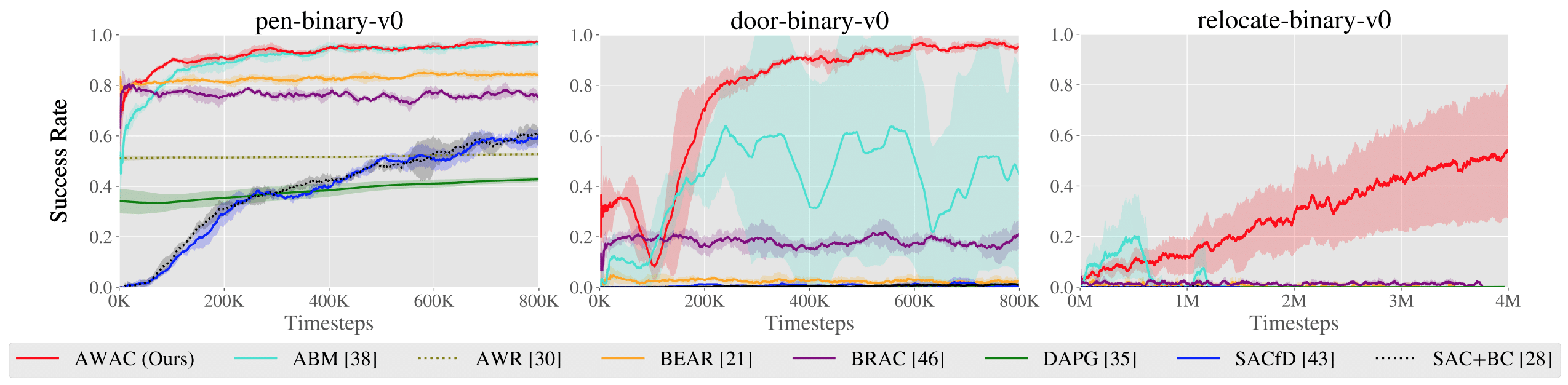
Figura 5. Arriba: rendimiento mostrado para varios métodos después del entrenamiento en línea
(bolígrafo: 200K pasos, puerta: 300K pasos, reubicación: 5M pasos). Abajo: aprendizaje
se muestran las curvas de las tareas de manipulación diestra con escasas recompensas. Paso 0
corresponde al inicio del entrenamiento en línea después del pre-entrenamiento fuera de línea.
Nuestro objetivo es estudiar tareas representativas de las dificultades de los robots del mundo real
aprendizaje, donde el aprendizaje fuera de línea y el ajuste en línea son más relevantes. Uno
tal escenario es el conjunto de tareas de manipulación diestra propuestas por Rajeswaran et al., 2017. Estas
las tareas implican complejas habilidades de manipulación usando una mano de cinco dedos de 28-DoF en
el simulador MuJoCo: rotación en mano de un bolígrafo, abrir una puerta abriendo el cerrojo
la manija, y recoger una esfera y reubicarla en un lugar objetivo.
Estos entornos presentan muchos desafíos: espacios de acción de altas dimensiones,
física de manipulación compleja con muchos contactos intermitentes, y aleatorios
posiciones de mano y objeto. Las funciones de recompensa en estos entornos son
recompensas binarias 0-1 por la finalización de la tarea. Rajeswaran et al. proporcionan 25 humanos
demostraciones para cada tarea, que no son totalmente óptimas pero que resuelven el
tarea. Como este conjunto de datos es muy pequeño, generamos otras 500 trayectorias
de los datos de interacción construyendo una política de comportamiento clónico, y luego
de esta política.
Primero, comparamos nuestro método en las tareas de manipulación diestra descritas
antes contra métodos anteriores para el aprendizaje fuera de la política, el aprendizaje fuera de la línea, y
de las demostraciones. Los resultados se muestran en la figura de arriba.
Nuestro método utiliza los datos anteriores para lograr rápidamente un buen rendimiento, y el
El eficiente componente crítico de nuestro enfoque, fuera de la política, afina mucho
más rápido que el DAPG. Por ejemplo, nuestro método resuelve la tarea del bolígrafo en 120K
pasos de tiempo, el equivalente a sólo 20 minutos de interacción en línea. Mientras que el
las comparaciones y ablaciones de base son capaces de hacer algún progreso en
la tarea del bolígrafo, los algoritmos alternativos de RL fuera de la política y de RL fuera de línea son en gran parte
incapaz de resolver la puerta y reubicar la tarea en el tiempo considerado. Nosotros
encuentran que las decisiones de diseño para usar la estimación crítica fuera de la política permiten a AWAC
para superar significativamente el AWR mientras que el modelo de comportamiento implícito permite
AWAC para superar significativamente a ABM, aunque ABM hace algunos progresos.
Ajuste de los datos de política aleatoria
Una ventaja de usar el RL fuera de la política para el aprendizaje de refuerzo es que podemos
también incorporan datos subóptimos, en lugar de sólo demostraciones. En este
experimento, evaluamos en una mesa simulada el entorno de empuje con un
El robot Sawyer.
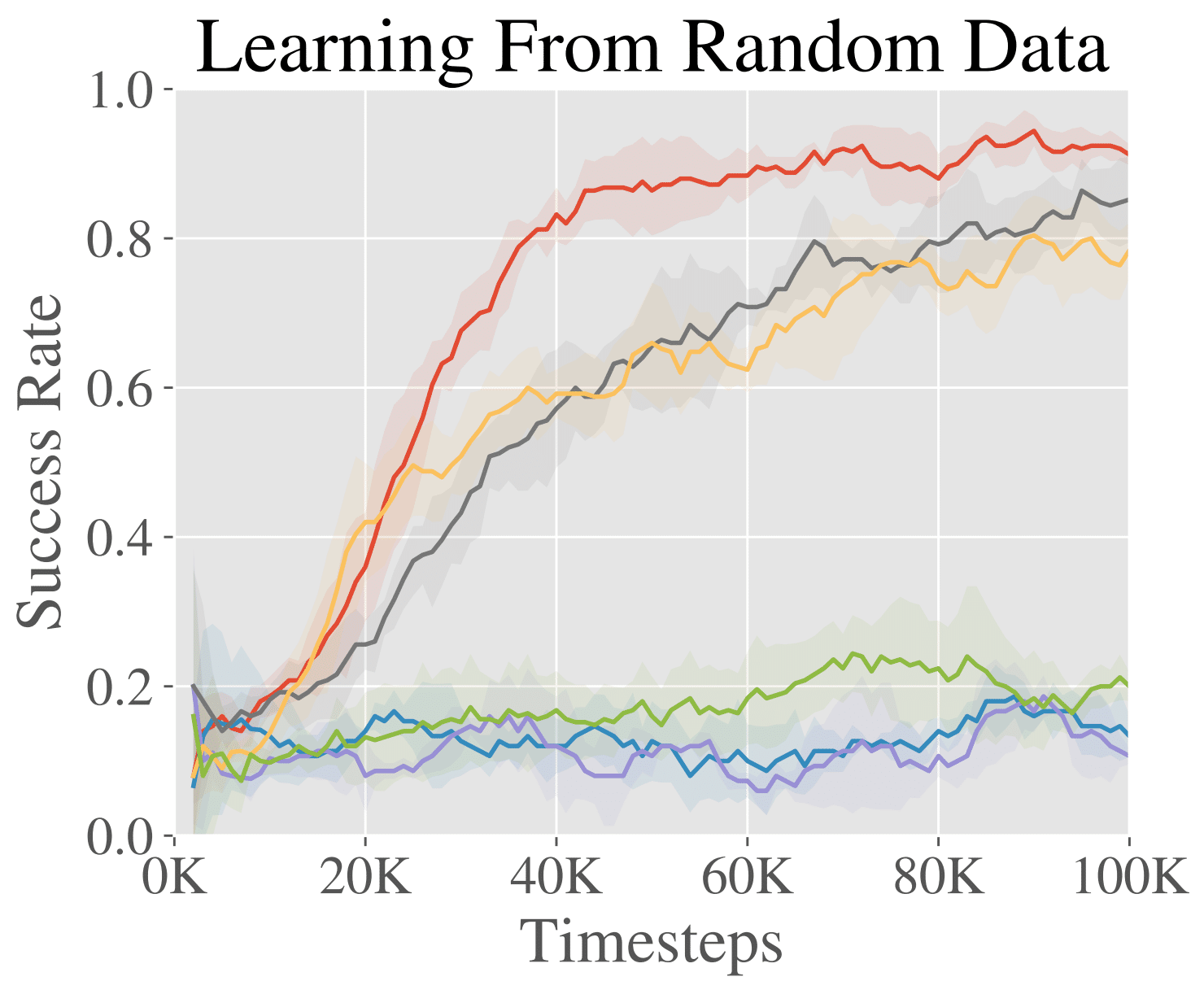
Para estudiar el potencial de aprender de los datos subóptimos, usamos una política fuera de la norma
conjunto de datos de 500 trayectorias generadas por un proceso aleatorio. La tarea es empujar
un objeto a un lugar de destino en un espacio de 40cm x 20cm de meta.
Los resultados se muestran en la figura de la derecha. Vemos que mientras muchos
los métodos comienzan con el mismo rendimiento inicial, el AWAC aprende más rápido en línea
y es realmente capaz de hacer uso del conjunto de datos fuera de línea de manera efectiva, a diferencia de
a algunos métodos que son completamente incapaces de aprender.
El poder usar datos anteriores y afinar rápidamente en nuevos problemas abre
muchas nuevas vías de investigación. Estamos muy entusiasmados con el uso de AWAC para pasar de
el régimen de tareas únicas en RL al régimen de tareas múltiples, con intercambio de datos y
generalización entre las tareas. La fuerza del aprendizaje profundo ha sido su
la capacidad de generalizar en entornos de mundo abierto, que ya hemos visto
transforman los campos de la visión por ordenador y el procesamiento del lenguaje natural. A
lograr el mismo tipo de generalización en la robótica, necesitaremos algoritmos RL
que aprovechan grandes cantidades de datos anteriores. Pero una distinción clave en
la robótica es que la recolección de datos de alta calidad para una tarea es muy difícil –
a menudo tan difícil como resolver la tarea en sí. Esto se opone a, por ejemplo
visión por ordenador, donde los humanos pueden etiquetar los datos. Así, los datos activos
(aprendizaje en línea) será una pieza importante del rompecabezas.
Este trabajo también sugiere una serie de direcciones algorítmicas para avanzar.
Nótese que en este trabajo nos centramos en las distribuciones de acciones no coincidentes entre
…la política y los datos de comportamiento… Cuando se hace fuera de la política
aprendizaje, también hay una distribución de estado marginal desigual entre los
dos. Intuitivamente, considere un problema con dos soluciones A y B, siendo B un
solución de mayor rendimiento y datos fuera de la política que demuestran que se ha proporcionado la solución A.
Incluso si el robot descubre la solución B durante la exploración en línea, el
Los datos fuera de la política siguen consistiendo en su mayoría en datos de la ruta A. Por lo tanto, la función Q
y las actualizaciones de las políticas se calculan sobre los estados encontrados al atravesar el camino A
aunque no se encontrará con estos estados cuando ejecute el óptimo
política. Este problema ha sido estudiado previamente. La contabilidad de ambos
Los tipos de desajuste de distribución probablemente resultarán en mejores algoritmos de RL.
Por último, ya estamos usando el AWAC como una herramienta para acelerar nuestra investigación. Cuando nosotros
para resolver una tarea, no solemos intentar resolverla desde cero con
RL. Primero, podemos teleoperar el robot para confirmar que la tarea es solucionable; luego
podríamos hacer algunos experimentos de política de código duro o de clonación de comportamiento para ver si
métodos sencillos ya pueden resolverlo. Con AWAC, podemos guardar todos los datos en
estos experimentos, así como otros datos experimentales como cuando
hiperparámetro que barre un algoritmo de RL, y lo usa como datos previos para RL.
Una preimpresión del trabajo en el que se basa esta entrada del blog está disponible aquí. El código está ahora incluido en el rlkit. La documentación del código también
contiene enlaces a los datos y entornos que utilizamos. El sitio web del proyecto es
disponible aquí.