
Los investigadores de la Escuela de Informática Efi Arazi del Centro Interdisciplinario de Herzliya (IDC Herzliya) en Israel han creado un prototipo de software que permite incluso a los novatos producir un montaje de vídeo con sólo teclear unas pocas frases que describen el tipo de producción que quieren.
El sistema funciona mediante la interconexión de programas informáticos de inteligencia artificial (IA) que han sido entrenados para reconocer y comprender el significado de los términos de búsqueda de palabras clave con una biblioteca de videoclips etiquetados con esos términos de búsqueda. «La herramienta busca automáticamente las tomas candidatas que coincidan semánticamente con las de un depósito de vídeo, y luego utiliza un método de optimización para ensamblar el montaje de vídeo cortando y reordenando las tomas automáticamente», dice Ariel Shamir, decano de la Escuela de Informática Efi Arazi.
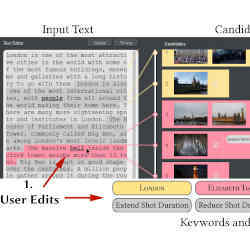
Por ejemplo, si escribes «Londres es una de las ciudades más atractivas del mundo, con algunos de los edificios, museos y galerías más famosos, con una larga historia que los acompaña», el software generará automáticamente un montaje de vídeo con esos elementos visuales específicos de Londres.
Reelaborar el vídeo es simplemente una cuestión de hacer un cambio o dos en la información textual que se escribe en el software. Añade «salas de conciertos» a la descripción de Londres que aparece arriba, por ejemplo, y el software añadirá secuencias de vídeo de las salas de conciertos de Londres.
Daniel Cohen-Or, un profesor especializado en gráficos y visualización por ordenador de la Universidad de Tel Aviv, se cuenta entre los impresionados. «El software explota el hecho de que la edición de texto es una tarea mucho más simple para los humanos, y convierte inteligentemente la edición de texto en edición de video.»
Por supuesto, el éxito del sistema depende en parte de la capacidad de anticipar el tipo de frases descriptivas que un usuario puede introducir en el software. El sistema funciona muy bien si se abastece de todo tipo de material de vídeo que represente a Londres en todo su esplendor, y luego se libera a un usuario que esté interesado en hacer vídeos con temática londinense. Sin embargo, el sistema estaría muerto en el agua si estuviera equipado con el mismo material de Londres, y luego se le pide que cree un montaje de vídeo que represente las vías neuronales del cerebro.
«Nuestra técnica funciona mejor en textos narrativos con temas específicos y asume que el usuario quiere crear un video, como videos de instrucciones o videos de viaje», dice Miao Wang, miembro del equipo de investigación y profesor asistente de la Universidad Beihang de China, especializado en gráficos por computadora y realidad virtual. «Asumimos además que un repositorio de video relacionado con el tema – que contenga suficiente diversidad – está disponible, recogido de recursos en línea o de álbumes personales».
Las videotecas para el uso del sistema deben prepararse anotando cuidadosamente cada videoclip antes de su uso, ya sea manual o automáticamente, según Wang. Los vídeos extraídos de YouTube y otros sitios similares, por ejemplo, son etiquetados automáticamente por el sistema con las mismas palabras clave que utiliza un buscador para encontrar esos vídeos en línea, dice.
Además, una vez dentro del sistema, algunos vídeos son etiquetados además por «detectores de objetos pre-entrenados» en el software del sistema, que buscan objetos reconocibles y luego los etiquetan en consecuencia. Un videoclip de «Parliament Square» en Londres, por ejemplo, también podría ser etiquetado por un detector de objetos pretratados con el descriptor de «perro», en caso de que un segmento de un videoclip de ese lugar tenga un perro.
Los usuarios también pueden anotar manualmente los videos que serán usados por el sistema para asegurar que aspectos específicos de la filmación de video se puedan buscar, según Wang.
El costo de toda esa anotación depende en parte del número de videoclips que se añadan a la videoteca; más clips requieren más anotaciones. Pero el mayor factor que influye en el costo es el número de videoclips que se pueden etiquetar automáticamente, frente al número de clips que necesitan ser etiquetados manualmente.
«Para las anotaciones automáticas, el costo es insignificante», dice Wang. «En nuestros experimentos, sólo una biblioteca fue etiquetada manualmente, y etiquetar todas las tomas, con una duración total combinada de tres horas y 20 minutos, le llevó al usuario unos 32 minutos.»
El sistema difiere de los experimentos de software relacionados en que permite que un montaje de vídeo se renderice con mucha más especificidad, según James Tompkin, un profesor asistente de la Universidad de Brown que se especializa en computación visual. «Los sistemas de edición de vídeo existentes para ayudar a los usuarios ocasionales se han centrado a menudo en la síntesis», dice Tompkin, «pero las técnicas no tenían suficiente comprensión visual para lograr una amplia adopción».
Según Ivan Laptev, investigador principal del Instituto Nacional de Investigación en Ciencia y Tecnología Digitales de Francia, «la búsqueda de vídeo por texto sigue teniendo grandes limitaciones. Mientras que encontrar objetos se hace fácil, las escenas con arreglos espaciales y temporales particulares son todavía muy difíciles de buscar». Como resultado, Laptev dijo, «La posibilidad de tener un video apropiado que coincida con una búsqueda de texto arbitraria será muy pequeña, incluso para bases de datos de video muy grandes».
Antoine Miech, estudiante de doctorado en el Instituto Nacional de Investigación en Ciencias Digitales de Francia, especializado en visión por computador, está de acuerdo en que «el rendimiento de este tipo de software depende realmente de los datos de entrenamiento en los que fue entrenado, por un lado, y también de la videoteca en la que se está buscando». Si tienes ambos a gran escala, creo que este tipo de software puede tener éxito comercial».
Dice Wang, «Nuestro método permite a los investigadores incorporar algoritmos de comparación visual-semántica más avanzados», en el futuro. «Esto puede conducir a un mejor rendimiento y a un mayor apoyo de los tipos de texto y vídeo.»