
Ética
El presente estudio fue un diseño de cohorte prospectivo aprobado por el Comité de Ética en Investigación de la Universidad Allameh Tabataba’i con ID: IR.ATU.REC.1399.038. Los sujetos dieron su consentimiento informado por escrito para participar en el estudio y toda la investigación se llevó a cabo de acuerdo con las instrucciones pertinentes. Para proteger la privacidad de estos datos clínicos, se han tenido en cuenta todos los principios éticos de los derechos de los pacientes y no se mencionaron los nombres de los participantes.
Participantes del estudio
Se incluyeron en el estudio un total de 1224 pacientes de los hospitales Ayatollah Kashani, Milad y Khatam al-Anbia (Teherán, Irán) en el período 2019-2021. Los criterios de inclusión comprendieron el rango de edad de 35 a 85 años, con factores de riesgo clínico relacionados con la osteoporosis. El tamaño de la muestra utilizando el software G-Power con un tamaño del efecto de 0,15, potencia de prueba de 0,89 y valor de error de 0,05 fue de 368 participantes. Para mayor seguridad en este estudio, el tamaño de la muestra se aumentó a 1224 participantes. Los pacientes se separaron en grupos de mujeres (n = 754) y hombres (n = 470).
Mediciones de puntuación T de resultados
Se utilizó una absorciometría de rayos X de energía dual (QDR 4500; Hologic, Bedford, MA, EE. UU.) para medir la puntuación T y la DMO en el cuello femoral, la columna lumbar (L1-L4) y el fémur total. El aspecto más importante de la interpretación DXA es estimar el riesgo de un paciente de desarrollar una fractura relacionada con la osteoporosis. La información DXA incluye la DMO, el puntaje T y el puntaje Z. Un puntaje T indica el número de desviaciones estándar por debajo o por encima del promedio de DMO, expresado en gramos por centímetro cuadrado. Este valor de DMO se compara con la DMO de una población de adultos jóvenes del mismo sexo y varias desviaciones estándar (SD) cerca de cada uno de estos valores. La diferencia entre la masa de la población de adultos jóvenes del mismo sexo y la masa ósea actual del paciente examinado se denomina T-score.22. Según la Organización Mundial de la Salud (OMS), se diagnostica sano o normal cuando el T-score es superior a −1,0 DE, osteopenia cuando el T-score está entre −1,5 y −2,5 y osteoporosis cuando el T-score es superior a −1,0 DE. la puntuación es superior a − 2,5 DE23.
Selección de características y evaluación de covariables
El presente estudio fue un diseño de cohorte prospectivo. En este estudio, mediante la revisión de artículos similares y consultas con un médico especialista, y la distribución y recopilación de cuestionarios relevantes de los sujetos, se prepararon los factores clínicos más significativos de la osteoporosis. Además, en una revisión de libros y artículos relevantes, se extrajeron factores clínicos relacionados con la osteoporosis.24. Finalmente, se seleccionaron 19 características de entrada para mujeres y 17 características de entrada para hombres (excluyendo la menopausia y la edad menopáusica) como entrada de los algoritmos.
Las características de entrada aplicadas a los algoritmos incluyeron: edad, altura, peso, índice de masa corporal (IMC), curvatura de la columna vertebral, antecedentes familiares de osteoporosis, consumo de vitamina D, actividad física, dolor de espalda, fractura ósea, enfermedad paratiroidea, antecedentes de fumar y niveles séricos de calcio, fósforo, vitamina D y fosfatasa alcalina (ALP). 0 y 1 se usaron para preguntas con respuestas sí y no (0 significa no, 1 significa sí). Se utilizó un cuestionario para diagnosticar la enfermedad paratiroidea. Se consideró antecedentes familiares de osteoporosis cuando al menos un familiar de primer grado fue diagnosticado con osteoporosis. Se utilizó un cuestionario de actividad física para evaluar el nivel de actividad física de los sujetos. Fumar se clasificó como «nunca» y «ahora». Para las mujeres, también se consideraron el estado de la menopausia y la edad de la menopausia. Para el análisis, el conjunto de datos en formato Excel se transfirió a Python versión 3.10 (Python Software Foundation, Wilmington, DE, EE. UU.).
Los sujetos debían cumplir con los siguientes criterios: tener entre 35 y 85 años de edad, sexo masculino/femenino, IMC de 18 a 40, T-score de 2 a −3, ausencia de enfermedad metabólica, artritis reumatoide y cáncer de huesos, no tomar corticosteroides ni hacer ejercicio regularmente en el último año. Los sujetos también tenían que demostrar que no tenían ninguna enfermedad secundaria, antecedentes de cirugía o lesión, ni ningún problema físico. La Tabla 1 muestra la descripción de las características del conjunto de datos.
Análisis de datos para predecir personas sanas, osteopenia, osteoporosis y proponer protocolos deportivos
Los algoritmos candidatos en este estudio incluyeron DT, RF, KNN, SVM, GB, ET, AB y ANN. Debido a las diferencias en las características de entrada, las características iniciales y la prevalencia de predicciones positivas, los modelos se entrenaron por separado en hombres y mujeres. Se aplicaron conjuntos de datos experimentales a diferentes modelos para obtener probabilidades predictivas de osteopenia, osteoporosis y probabilidad o ausencia de enfermedad en cada uno. modelo, y de acuerdo con la edad y el estado de salud en ambos grupos de hombres y mujeres que utilizan los métodos de IA y para proporcionar un protocolo deportivo adecuado. Para ello, todos los protocolos de terapia deportiva recogidos en artículos científicos y clasificados en función de diversos parámetros efectivos (como la edad, el sexo y el estado de salud). Finalmente, para predecir y prescribir el tipo de ejercicio, se entrenaron algoritmos apropiados.
El modelo se entrenó prediciendo tres grupos, que incluían sano, osteopenia y osteoporosis. Durante el proceso de entrenamiento, el objetivo fue predecir el modelo multivariado (1, 2, 3). En el proceso de prueba, los resultados de predicción se marcaron con «1» para el grupo sano, «2 y 3» para los grupos de osteopenia y osteoporosis, respectivamente. Para clasificar los deportes, se presentaron varias variables binarias (1, 2, 3, 4, 5, 6, 7, 8, 9) que se muestran por separado para hombres y mujeres en las Tablas 4 y 5.
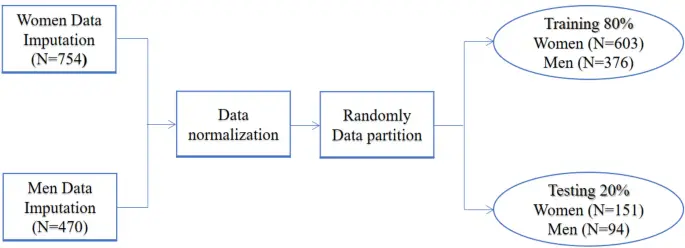
Los conjuntos de datos separados para hombres y mujeres se dividieron en conjuntos de datos de entrenamiento y prueba con una división de 80:20. Durante cada sección de entrenamiento de modelos, usó un conjunto de datos de prueba del 20 % para experimentar el rendimiento de los modelos. Se analizaron los datos y se identificó el algoritmo con mejor rendimiento. Esto resultó en 376 hombres en capacitación y 94 hombres en pruebas de conjuntos de datos, y 603 mujeres en capacitación y 151 mujeres en pruebas de conjuntos de datos. La Figura 1 ilustra el procesamiento de datos en el presente estudio.
DT es la representación denotativa de un proceso de toma de decisiones. DT en AI se usa para llegar a conclusiones basadas en los datos disponibles de decisiones tomadas en el pasado25. El bosque aleatorio (RF) se compone de una gran cantidad de árboles de decisión individuales que actúan como una colección. Cada árbol único en el bosque aleatorio publica una predicción de clase, que utiliza una submuestra aleatoria y un subconjunto aleatorio de las funciones disponibles para cada decisión de división.25. El algoritmo KNN usa ‘similitud de características’ para predecir los valores de cualquier punto de datos nuevo. Esto significa que al nuevo punto se le asigna un valor en función de su similitud con los puntos del conjunto de entrenamiento.26. SVM cae en la categoría de aprendizaje supervisado que es útil para resolver problemas de clasificación. Este método crea el mejor límite de decisión para dividir el próximo espacio n en diferentes clases para colocar los nuevos puntos de datos en la categoría de clase adecuada. SVM siempre selecciona vectores fuertes para crear hiperplanos. Estos extremos se denominan vectores de respaldo. Las dimensiones del hiperplano están determinadas por el número de características del conjunto de datos.27. GB combina las predicciones de múltiples árboles de decisión para generar las predicciones finales. El algoritmo ET funciona mediante la creación de una gran cantidad de árboles de decisión no podados a partir del conjunto de datos de entrenamiento. Las predicciones se realizan promediando la predicción de los árboles de decisión en el caso de la clasificación. AB funciona al poner más peso en las instancias difíciles de clasificar y menos en las que ya se manejaron bien28. Un perceptrón multicapa (MLP) es una clase de red neuronal artificial (ANN) totalmente conectada. El término MLP se usa de manera ambigua, a veces vagamente para referirse a cualquier ANN de realimentación, a veces estrictamente para referirse a redes compuestas de múltiples capas de perceptrones. MLP es una red neuronal artificial feedforward que genera un conjunto de salidas a partir de un conjunto de entradas. Un MLP se caracteriza por varias capas de nodos de entrada conectados como un gráfico dirigido entre las capas de entrada y salida.29. El proceso y los hiperparámetros seleccionados finales para cada modelo se presentan en la Tabla 2.
Se investigaron varias combinaciones del número de capas (1 o 40 capas ocultas) y la tasa de aprendizaje (de 0,01 a 0,0001) en el modelo ANN para el ajuste de hiperparámetros. Para el modelo DT, los parámetros de profundidad y hoja y SVM, el tipo de kernel (función de base lineal, polinomial o radial), el parámetro de regularización C (de 2–2 a 29) y para el modelo RF, se examinaron la profundidad máxima (de 3 a 13), el estado aleatorio (de 3 a 17); para el modelo KNN se probó el número de vecinos (de 1 a 10). Todos los modelos fueron creados con un peso de clase equilibrado. La aleatorización para la división del conjunto de datos de validación y el proceso de entrenamiento se repitieron varias veces para cada conjunto de hiperparámetros. Se estimó el área bajo la curva característica operativa del receptor (AUROC) para el conjunto de datos de prueba en cada proceso de entrenamiento y se compararon los valores medios de AUROC. El área bajo la curva (AUC) es una medida de la capacidad de un clasificador para distinguir entre clases y se utiliza como resumen de la curva ROC. Cuanto mayor sea el AUC, mejor será el rendimiento del modelo para discernir las clases positivas y negativas. Se calcularon otros valores en el rendimiento de los algoritmos para el conjunto de datos en cada proceso de entrenamiento, incluida la exactitud, la precisión, la sensibilidad, la especificidad y la puntuación F. La precisión es un criterio de evaluación de los modelos de clasificación y es una fracción de las predicciones que el modelo ha hecho con precisión (Ec. 1). La precisión es una métrica que calcula el porcentaje de predicciones correctas para la clase positiva. Maximizar la precisión minimizará los errores de falsos positivos, mientras que maximizar la recuperación minimizará los errores de falsos negativos (Ec. 2). La sensibilidad (también conocida como recuerdo) estima el porcentaje de predicciones correctas para la clase positiva de todas las predicciones positivas posibles realizadas (Ec. 3). La especificidad calcula la proporción de verdaderos negativos identificados correctamente por el modelo (Ec. 4). La medida F, también denominada puntuación F, se utiliza para verificar la precisión de un modelo en un conjunto de datos. El puntaje F se usa ampliamente en la evaluación de sistemas de recuperación de información, como motores de búsqueda y muchos tipos de modelos de aprendizaje automático. Además, la medida F es una métrica de puntuación única configurable para evaluar un modelo de clasificación binaria basado en las predicciones hechas para la clase positiva (Ec. 5). La medida F se estima usando sensibilidad y precisión.30. Se calcularon los siguientes criterios para evaluar el rendimiento de los modelos predichos.
$${text{Exactitud}} = left( {{text{verdaderos positivos}} + {text{verdaderos negativos}}} right)/left( {text{ejemplos totales}} right) $$
(1)
$${text{Precisión}} = left( {text{verdaderos positivos}} right)/left( {{text{verdaderos positivos}} + {text{falsos positivos}}} right) $$
(2)
$${text{Sensibilidad}} = left( {text{verdaderos positivos}} right)/left( {{text{verdaderos positivos}} + {text{falsos negativos}}} right) $$
(3)
$${text{Especificidad}} = left( {text{negativo verdadero}} right)/left( {{text{negativo verdadero}} + {text{positivo falso}}} right) $$
(4)
$${text{puntuación F}} = ({2} times {text{precisión}} times {text{recordar}})/left( {{text{precisión}} + { texto{recordar}}} right)$$
(5)
Aprobación ética y consentimiento para participar
Este estudio fue aprobado por el Comité de Ética de la Universidad Allameh Tabataba’i con código de identificación de investigación: IR.ATU.REC.1399.038. Los sujetos dieron su consentimiento informado por escrito para participar en este estudio y toda la investigación se llevó a cabo de acuerdo con las instrucciones pertinentes.