

Un nuevo chip acelerador llamado «Hiddenite» que puede lograr tecnología de punta exactitud en el cálculo de «redes neuronales ocultas» dispersas con cargas computacionales más bajas ahora ha sido desarrollado por investigadores de Tokyo Tech. Al emplear la construcción del modelo en chip propuesto, que es la combinación de generación de peso y expansión de «supermáscara», el chip Hiddenite reduce drásticamente el acceso a la memoria externa para mejorar la eficiencia computacional.
Las redes neuronales profundas (DNN) son una pieza compleja de arquitectura de aprendizaje automático para IA (aprendizaje artificial) que requiere numerosos parámetros para aprender a predecir resultados. Sin embargo, los DNN se pueden «recortar», lo que reduce la carga computacional y el tamaño del modelo. Hace unos años, la «hipótesis del billete de lotería» tomó por asalto el mundo del aprendizaje automático. La hipótesis establecía que un DNN inicializado aleatoriamente contiene subredes que logran una precisión equivalente al DNN original después del entrenamiento. Cuanto más grande sea la red, más «boletos de lotería» para una optimización exitosa. Estos boletos de lotería permiten que las redes neuronales dispersas «recortadas» logren precisiones equivalentes a las redes «densas» más complejas, lo que reduce las cargas computacionales generales y los consumos de energía.
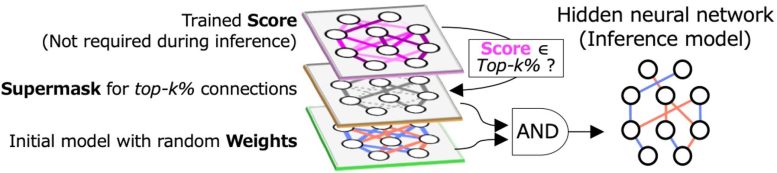
Figura 1. Los HNN encuentran subredes dispersas que logran una precisión equivalente al modelo de entrenamiento denso original. Crédito: Masato Motomura de Tokyo Tech
Una técnica para encontrar tales subredes es el algoritmo de la red neuronal oculta (HNN), que usa la lógica AND (donde la salida solo es alta cuando todas las entradas son altas) en los pesos aleatorios inicializados y una «máscara binaria» llamada «supermáscara». (Figura 1). La supermáscara, definida por las puntuaciones más altas de top-k%, denota las conexiones no seleccionadas y seleccionadas como 0 y 1, respectivamente. El HNN ayuda a reducir la eficiencia computacional desde el lado del software. Sin embargo, la computación de redes neuronales también requiere mejoras en los componentes de hardware.
Los aceleradores DNN tradicionales ofrecen un alto rendimiento, pero no tienen en cuenta el consumo de energía causado por el acceso a la memoria externa. Ahora, investigadores del Instituto de Tecnología de Tokio (Tokyo Tech), dirigidos por los profesores Jaehoon Yu y Masato Motomura, han desarrollado un nuevo chip acelerador llamado «Hiddenite», que puede calcular redes neuronales ocultas con un consumo de energía drásticamente mejorado. “Reducir el acceso a la memoria externa es la clave para reducir el consumo de energía. Actualmente, lograr una alta precisión de inferencia requiere modelos grandes. Pero esto aumenta el acceso a la memoria externa para cargar los parámetros del modelo. Nuestra principal motivación detrás del desarrollo de Hiddenite fue reducir este acceso a la memoria externa”, explica el Prof. Motomura. Su estudio se presentará en la próxima Conferencia Internacional de Circuitos de Estado Sólido (ISSCC) 2022, una prestigiosa conferencia internacional que muestra los pináculos de los logros en circuitos integrados.
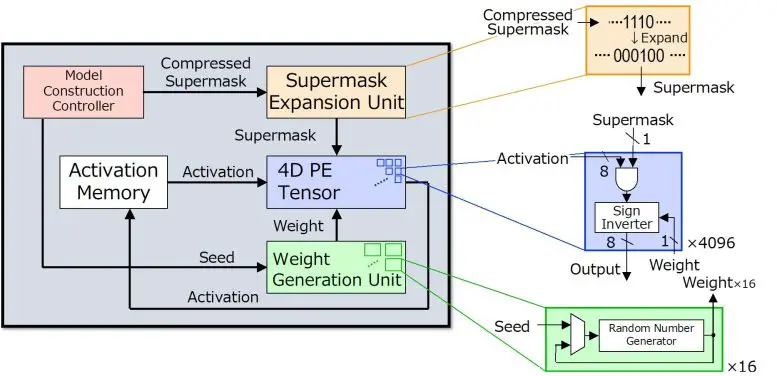
Figura 2. El nuevo chip Hiddenite ofrece generación de peso en el chip y «expansión de supermáscara» en el chip para reducir el acceso a la memoria externa para cargar los parámetros del modelo. Crédito: Masato Motomura de Tokyo Tech
«Hiddenite» significa Motor Tensor de Inferencia de Red Neural Oculta y es el primer chip de inferencia HNN. La arquitectura Hiddenite (Fig. 2) ofrece tres beneficios para reducir el acceso a la memoria externa y lograr una alta eficiencia energética. La primera es que ofrece la generación de pesos en el chip para regenerar pesos mediante el uso de un generador de números aleatorios. Esto elimina la necesidad de acceder a la memoria externa y almacenar los pesos. El segundo beneficio es la provisión de la «expansión de supermáscara en chip», que reduce la cantidad de supermáscaras que el acelerador debe cargar. La tercera mejora que ofrece el chip Hiddenite es el procesador paralelo de cuatro dimensiones (4D) de alta densidad que maximiza la reutilización de datos durante el proceso computacional, mejorando así la eficiencia.

Figura 3. Fabricado con tecnología de 40 nm, el núcleo del área del chip mide solo 4,36 milímetros cuadrados. Crédito: Masato Motomura de Tokyo Tech
“Los dos primeros factores son los que distinguen al chip Hiddenite de los aceleradores de inferencia DNN existentes”, revela el profesor Motomura. “Además, también introdujimos un nuevo método de entrenamiento para redes neuronales ocultas, llamado ‘destilación de puntajes’, en el que los pesos de destilación de conocimiento convencional se destilan en los puntajes porque las redes neuronales ocultas nunca actualizan los pesos. La precisión con la destilación de puntajes es comparable al modelo binario y tiene la mitad del tamaño del modelo binario”.
Basado en la arquitectura hiddenita, el equipo diseñó, fabricó y midió un prototipo de chip con el proceso de 40nm de Taiwan Semiconductor Manufacturing Company (TSMC) (Fig. 3). El chip mide solo 3 mm x 3 mm y maneja 4096 operaciones MAC (multiplicar y acumular) a la vez. Logra un nivel avanzado de eficiencia computacional, hasta 34,8 billones o tera de operaciones por segundo (TOPS) por vatio de potencia, al tiempo que reduce la cantidad de transferencia de modelo a la mitad que las redes binarizadas.
Estos hallazgos y su exitosa exhibición en un chip de silicio real seguramente provocarán otro cambio de paradigma en el mundo del aprendizaje automático, allanando el camino para una computación más rápida, más eficiente y, en última instancia, más respetuosa con el medio ambiente.