
Las siguientes subsecciones brindan un extenso estudio de ablación al variar tanto la composición del conjunto de datos como la columna vertebral de CNN utilizada en nuestro modelo.
Imágenes por instancia
Es importante distinguir la precisión de clasificación de instancias del modelo para objetos con muchos imágenes de aquellos con menos imágenes, porque a medida que aumenta el número de imágenes diferentes por instancia, también aumenta la información visual potencial para que el modelo aprenda a reconocer. Dadas las ventajas que pueden ofrecer más imágenes por instancia, además de experimentar con el conjunto de datos completo de 24,502 imágenes (obtenido al mantener solo instancias con 3 imágenes o más como se describe en la sección «Conjunto de datos»), también experimentamos restringiendo aún más el mínimo número de imágenes por instancia en el conjunto de datos a 4, 5 y 6. Como se muestra en el aumento general de precisión en cada subconjunto de imagen por instancia en la Fig. 4, encontramos que las instancias con un mayor número de imágenes son más precisas. clasificados, como se esperaba intuitivamente. Encontramos que excluir instancias con menos imágenes por instancia no no mejorar sustancialmente la precisión de los subconjuntos de conteo de imágenes más alto, demostrado por las puntuaciones relativamente cercanas de cada subconjunto (la configuración de entrenamiento más inclusiva incluso obtuvo la puntuación más alta en el subconjunto de 9 imágenes por instancia). Esto indica que hay poco riesgo para el rendimiento general de un detector de objetos al incluir objetos con un recuento de imágenes más bajo, ya que la precisión general más baja se deriva del rendimiento de clasificación naturalmente más bajo de los objetos menos representados, y no una degradación en el rendimiento en subconjuntos de conteo más alto. Aunque generalmente el rendimiento aumenta a medida que el conjunto de datos se vuelve más pequeño (y, por lo tanto, se resuelve más fácilmente), el rendimiento similar entre las cuatro configuraciones de entrenamiento en la Fig. 4 implica que nuestra limitación de conjunto de datos más estricta de 6 imágenes por instancia tiene no tamaño del conjunto de datos suficientemente reducido para que este problema se manifieste. Además, verificamos que las altas precisiones de nuestros modelos no provienen de un pequeño número de instancias fáciles o ‘resueltas’ que llevan de manera desproporcionada la precisión general, como lo demuestra la diferencia relativamente pequeña en la precisión entre los subconjuntos de recuentos de imágenes por instancia. 8, 9 y 10+.
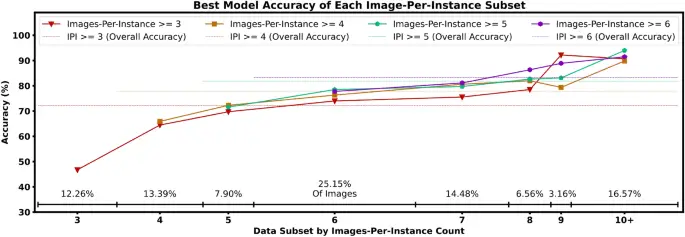
La precisión de las imágenes de cada subconjunto por imagen por instancia cuenta para nuestro mejor modelo (de la Fig. 5) bajo cada composición de conjunto de datos. Por ejemplo, las gráficas rojas triangulares indican la precisión de predicción de objetos de nuestro modelo de mayor rendimiento entrenado en el conjunto de datos con un corte mínimo de imagen por instancia de tres, dividido aún más por subconjuntos de objetos con exactamente 3/4/5… imágenes por instancia. La línea roja discontinua representa la general precisión, es decir, un promedio ponderado de las precisiones de cada subconjunto.
modelo CNN
Dado que la red troncal de CNN es la parte más importante del diseño del modelo, experimentamos con EfficientNet de última generación.5 y ResNet reescalado6 modelos con mayor ablación en Inception-v37/v48 modelos Encontramos que todos los modelos EfficientNet funcionan significativamente mejor que los otros modelos en cada configuración de entrenamiento (Fig. 5), y que los modelos EfficientNet más grandes logran consistentemente una mayor precisión que los más pequeños. Aunque un umbral más alto de imagen por instancia produce un mayor rendimiento, como se mencionó anteriormente, también vemos que el tamaño del modelo no cambia significativamente el rendimiento en diferentes umbrales de imagen por instancia. Esto se representa mediante el espaciado consistente entre cada polígono en la Fig. 5 a través de cada tipo diferente de modelo. En cambio, el cambio en la precisión en los umbrales de imagen por instancia es notablemente diferente para los tres modelos diferentes. arquitecturases decir, el aumento en el rendimiento de imágenes por instancia ≥ 3 y ≥ 6 es (sim) 19%, (sim) 11%, y (sim) 8% para las arquitecturas ResNet-RS, EfficientNet e Inception respectivamente.
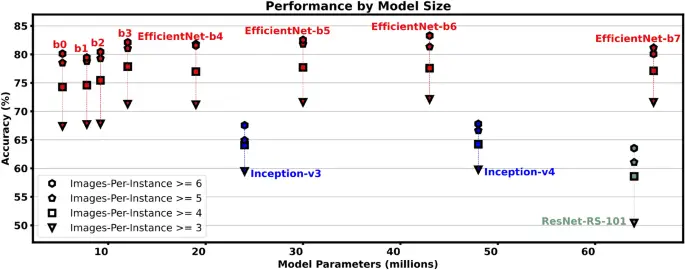
Rendimiento de los modelos con respecto a su tamaño, es decir, el número de parámetros. Los cuatro escenarios de imagen por instancia del conjunto de datos aquí son los mismos cuatro escenarios que en la Fig. 4.
Compensaciones de alto rendimiento
El desempeño más fuerte único el modelo es EfficientNet-b4/3/4/6 para umbrales de conjunto de datos de imagen por instancia ≥ 3/4/5/6 respectivamente. Sin embargo, para mantener un tamaño de lote suficientemente grande para un entrenamiento estable, las variaciones más grandes de EfficientNet requieren recursos computacionales significativamente mayores durante capacitación (detalles completos en la Tabla complementaria 1). Además, en línea con la práctica estándar para modelos de clasificación de imágenes basados en CNN24, encontramos que un conjunto colaborativo de modelos aumenta aún más la precisión. La Tabla 3 muestra que un conjunto de los 5 mejores modelos de EfficientNet brinda un aumento de ~ 1 a 2 % en la precisión del top 1, que puede aprovecharse siempre que uno esté dispuesto a comprarlo con aumentos en los recursos computacionales (~ 2,5 GB de VRAM para inferencia de una sola imagen). Incluso en escenarios donde el objeto predicho es incorrecto, encontramos que la respuesta correcta a menudo todavía se encuentra en las próximas conjeturas, es decir, las precisiones de los 3 primeros, los 5 primeros y los 10 primeros de nuestros modelos son en realidad significativamente más altas que nuestras habituales. puntuaciones de precisión. Vemos en la Tabla 3 que (para el mejor desempeño único modelo) los escenarios de conjuntos de datos de ‘imagen por instancia ≥ 3/4’ más relajados producen mejoras de ~ 10 %, ~ 13 % y ~ 17 % para las precisiones de los 3 primeros, los 5 primeros y los 10 primeros, respectivamente. Las precisiones de los 3 primeros, los 5 primeros y los 10 primeros muestran una mejora relativa menor para los escenarios menos relajados de imagen por instancia ≥ 5/6 (+ ~ 8 %, + ~ 10 %, + ~ 12 %) como el las precisiones top-1 de referencia ya son más altas que las de imagen por instancia ≥ 3/4.
Subcategorías de objetos
Aunque la pregunta central de este artículo es sobre las instancias, exploramos cómo la precisión de la clasificación de instancias difiere para las instancias en cada subcategoría del conjunto de datos. Vemos en la Tabla 4 que las subcategorías oriental y egipcia obtienen puntajes consistentemente por encima del promedio general. Los objetos del castillo obtienen una puntuación significativamente inferior al promedio (-8 % a -32 %) y los objetos de Fulling Mill tienen una puntuación entre (-8 % a + 0,33 %). Las mayores variaciones en la precisión de la subcategoría ocurren en los escenarios más relajados de imagen por instancia ≥ 3/4 (+ 6% a − 29.%), mientras que el escenario de imagen por instancia ≥ 6 más restrictivo y generalmente de mayor rendimiento tiene mucha menos variación en general (+ 1% a − 8%). Observamos que las subcategorías más pequeñas experimentan la caída más sustancial en la precisión y que esto coincide además con el promedio de imágenes por instancia para cada subsección (calculado a partir de la Tabla 2b): Oriental (aprox.) 5.84, egipcio (aprox.) 5.67, Batán (aprox.) 4.71, Castillo (aprox.) 4.43. Sin embargo, no podemos concluir que el tamaño más grande de una subcategoría sea la causa del aumento del rendimiento, ya que la subcategoría egipcia (~ 18,93 % de las instancias) obtiene una puntuación más alta que el subconjunto oriental mucho más grande (~ 69,09 % de las instancias). Por el contrario, tampoco podemos concluir que el tamaño relativamente pequeño del Batán ((sim) 5,94%) y Castillo ((sim) 3,80 %) de las subcategorías provocan su reducción relativa en el rendimiento en comparación con la precisión general, porque la precisión de estas dos subcategorías más pequeñas se acerca a la precisión general en los escenarios de conjuntos de datos de imagen por instancia más altos. Suponemos que las instancias de estas subcategorías, en cambio, no se representan tan fácilmente con menos imágenes por instancia. Para medir las diferencias en la información de la imagen entre las subsecciones, aplicamos la reducción de dimensión t-SNE25 en vectores de características extraídos de la penúltima capa de la CNN en nuestros mejores modelos para cada imagen en el conjunto de prueba. Esto genera un punto 2D para cada imagen que podemos trazar para observar cualquier grupo que pueda haber generado la reducción t-SNE. Vemos en la Fig. 6 que la gráfica que genera la reducción t-SNE bidimensional no no fuertemente agrupar las imágenes por subconjuntos, ya que los cuatro colores (que representan cada subcategoría diferente) están distribuidos de manera relativamente uniforme. Sin embargo, los puntos parecen agruparse en una gran cantidad de vecindarios muy pequeños. desconsiderado de su subcategoría. Esto no nos sorprende, ya que la CNN ha sido entrenada para distinguir imágenes por instancia en lugar de su subcategoría. Esto es evidencia de que nuestro modelo es no confiando en características únicas para cada subcategoría por ejemplo, orientaly en su lugar utiliza principalmente las características distintivas de cada instancia de objeto Como era la intención. Véanse las figuras complementarias. 2 y 3 en la Sección D de los materiales complementarios para reducción de dimensionalidad PCA y UMAP respectivamente.
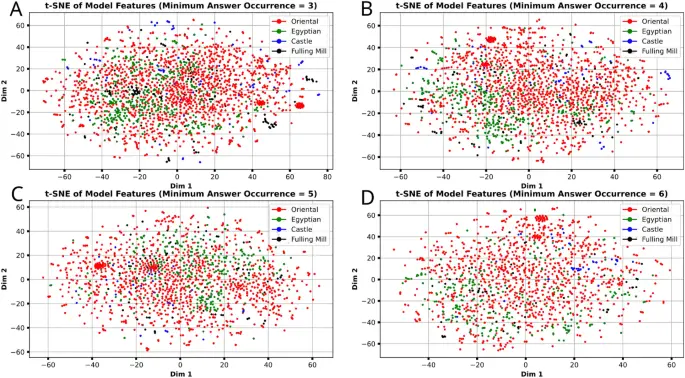
Reducción de la dimensión t-SNE25 en las características generadas a partir de cada imagen del conjunto de datos, extraídas de la penúltima capa de las CNN utilizadas en nuestros experimentos.
Visualización de predicciones con mapas de prominencia
Usamos mapas de prominencia26 para ver qué regiones de la imagen de entrada fueron más influyentes en la decisión que toma la red y, por lo tanto, nos permite estimar cómo nuestra red neuronal hace predicciones para qué instancia cree que pertenece la imagen. Dada una imagen y la clase que un modelo ha predicho para ella, podemos rastrear el origen de las señales que se propagan a través de la red que condujo a la clasificación dada, es decir, podemos resaltar las regiones de la imagen que más influyeron en la elección de clasificación de instancias del modelo. La Figura 7 muestra mapas de prominencia generados por nuestro mejor modelo único (EfficientNet-b6 en imágenes por instancia ≥ 6) superpuestos en la imagen original para mayor claridad. Una prominencia de mayor intensidad (rojo más oscuro) indica que los píxeles fueron muy influyentes en la decisión del modelo. Nuestros modelos no demuestran una confianza excesiva en ninguna característica en sus predicciones: la Fig. 7a muestra ejemplos en los que el límite del objeto, es decir, su forma, condujo a una clasificación correcta. En cambio, la Figura 7b muestra ejemplos en los que los detalles más finos en la superficie de los objetos son los más destacados para la clasificación correcta. No encontramos ninguna característica en la prominencia que se correlacione con incorrecto clasificaciones. Sin embargo, a menudo ocurre que incorrectamente los objetos clasificados exhiben una prominencia más dispersa como en la Fig. 7c. Dichos mapas de prominencia incorrectos todavía parecen prestar cierta atención a la forma/detalles de los objetos, aunque en un grado mucho menor que las contrapartes clasificadas correctamente en la Fig. 7a, b. Por ejemplo, los objetos en la Fig. 7c muestran regiones de prominencia dispersas por el fondo. Aún alguno de la prominencia todavía se superpone alrededor de la forma de los objetos (objetos del medio y de la derecha), o los detalles (visto en la base del objeto más a la izquierda en la Fig. 7c). Este comportamiento es típico de una predicción menos segura, donde el modelo aún conoce las características del objeto, pero no puede explotarlas con confianza en la clasificación.

Mapas de prominencia26 generado a partir de nuestro mejor modelo en imágenes por instancia ≥ 6 (EfficientNet-b6) para visualizar qué regiones de la imagen son más influyentes en la elección de la instancia. El mapa de prominencia se superpone a la imagen original para mayor claridad. Las regiones rojas más oscuras indican una puntuación de mayor intensidad.