

Última actualización el 19 de octubre de 2022
Anteriormente hemos visto cómo entrenar el modelo Transformer para la traducción automática neuronal. Antes de pasar a la inferencia del modelo entrenado, primero exploremos cómo modificar ligeramente el código de entrenamiento para poder trazar las curvas de pérdida de entrenamiento y validación que se pueden generar durante el proceso de aprendizaje.
Los valores de pérdida de entrenamiento y validación brindan información importante, porque nos permiten tener una mejor idea de cómo está cambiando el rendimiento del aprendizaje a lo largo de la cantidad de épocas, y nos ayudan a diagnosticar cualquier problema con el aprendizaje que pueda conducir a un ajuste insuficiente o un error. modelo sobreajustado. También nos informarán sobre la época en la que usar los pesos del modelo entrenado en la etapa de inferencia.
En este tutorial, descubrirá cómo trazar las curvas de pérdida de entrenamiento y validación para el modelo Transformer.
Después de completar este tutorial, sabrás:
- Cómo modificar el código de entrenamiento para incluir divisiones de validación y prueba, además de una división de entrenamiento del conjunto de datos.
- Cómo modificar el código de entrenamiento para almacenar los valores de pérdida de validación y entrenamiento calculados, así como los pesos del modelo entrenado.
- Cómo trazar las curvas de pérdida de entrenamiento y validación guardadas.
Empecemos.
Trazado de las curvas de pérdida de entrenamiento y validación para el modelo de transformador
Foto de Jack Anstey, algunos derechos reservados.
Descripción general del tutorial
Este tutorial se divide en cuatro partes; están:
- Resumen de la arquitectura del transformador
- Preparación de las divisiones de entrenamiento, validación y prueba del conjunto de datos
- Entrenamiento del modelo de transformador
- Trazado de las curvas de pérdida de entrenamiento y validación
requisitos previos
Para este tutorial, asumimos que ya está familiarizado con:
- La teoría detrás del modelo Transformer
- Una implementación del modelo Transformer
- Entrenando el modelo de Transformador
Resumen de la arquitectura del transformador
Recuerde haber visto que la arquitectura de Transformer sigue una estructura de codificador-decodificador: el codificador, en el lado izquierdo, tiene la tarea de mapear una secuencia de entrada a una secuencia de representaciones continuas; el decodificador, en el lado derecho, recibe la salida del codificador junto con la salida del decodificador en el paso de tiempo anterior, para generar una secuencia de salida.
La estructura del codificador-decodificador de la arquitectura del transformador
Tomado de “La atención es todo lo que necesitas“
Al generar una secuencia de salida, el Transformador no se basa en recurrencias ni circunvoluciones.
Hemos visto cómo entrenar el modelo completo de Transformer y ahora veremos cómo generar y graficar los valores de pérdida de entrenamiento y validación que nos ayudarán a diagnosticar el rendimiento de aprendizaje del modelo.
Preparación de las divisiones de entrenamiento, validación y prueba del conjunto de datos
Para poder incluir divisiones de validación y prueba de los datos, modificaremos el código que prepara el conjunto de datos introduciendo las siguientes líneas de código, que:
- Especifique el tamaño de la división de datos de validación. Esto, a su vez, determina el tamaño de las divisiones de entrenamiento y prueba de los datos, que dividiremos en una proporción de 80:10:10 para los conjuntos de entrenamiento, validación y prueba, respectivamente:
self.val_split = 0.1 # Ratio of the validation data split
- Divida el conjunto de datos en conjuntos de validación y prueba, además del conjunto de entrenamiento:
val = dataset[int(self.n_sentences * self.train_split):int(self.n_sentences * (1-self.val_split))] test = dataset[int(self.n_sentences * (1 – self.val_split)):]
- Prepare los datos de validación tokenizando, rellenando y convirtiendo a un tensor. Para este propósito, recopilaremos estas operaciones en una función llamada,
encode_pad, como se muestra en la lista completa de códigos a continuación. Esto también evitará la repetición excesiva de código cuando lleguemos a realizar estas operaciones en los datos de entrenamiento:
valX = self.encode_pad(val[:, 0], enc_tokenizer, enc_seq_length)
valY = self.encode_pad(val[:, 1], dec_tokenizer, dec_seq_length)
- Guarde los tokenizadores del codificador y del decodificador en archivos pickle, y el conjunto de datos de prueba en un archivo de texto, para usarlos más tarde durante la etapa de inferencia:
self.save_tokenizer(enc_tokenizer, ‘enc’)
self.save_tokenizer(dec_tokenizer, ‘dec’)
savetxt(‘test_dataset.txt’, test, fmt=»%s»)
La lista completa de códigos ahora se actualiza de la siguiente manera:
from pickle import load, dump, HIGHEST_PROTOCOL
from numpy.random import shuffle
from numpy import savetxt
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from tensorflow import convert_to_tensor, int64
class PrepareDataset:
def __init__(self, **kwargs):
super(PrepareDataset, self).__init__(**kwargs)
self.n_sentences = 15000 # Number of sentences to include in the dataset
self.train_split = 0.8 # Ratio of the training data split
self.val_split = 0.1 # Ratio of the validation data split
# Fit a tokenizer
def create_tokenizer(self, dataset):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(dataset)
return tokenizer
def find_seq_length(self, dataset):
return max(len(seq.split()) for seq in dataset)
def find_vocab_size(self, tokenizer, dataset):
tokenizer.fit_on_texts(dataset)
return len(tokenizer.word_index) + 1
# Encode and pad the input sequences
def encode_pad(self, dataset, tokenizer, seq_length):
x = tokenizer.texts_to_sequences(dataset)
x = pad_sequences(x, maxlen=seq_length, padding=’post’)
x = convert_to_tensor(x, dtype=int64)
return x
def save_tokenizer(self, tokenizer, name):
with open(name + ‘_tokenizer.pkl’, ‘wb’) as handle:
dump(tokenizer, handle, protocol=HIGHEST_PROTOCOL)
def __call__(self, filename, **kwargs):
# Load a clean dataset
clean_dataset = load(open(filename, ‘rb’))
# Reduce dataset size
dataset = clean_dataset[:self.n_sentences, :]
# Include start and end of string tokens
for i in range(dataset[:, 0].size):
dataset[i, 0] = «<START> » + dataset[i, 0] + » <EOS>»
dataset[i, 1] = «<START> » + dataset[i, 1] + » <EOS>»
# Random shuffle the dataset
shuffle(dataset)
# Split the dataset in training, validation and test sets
train = dataset[:int(self.n_sentences * self.train_split)]
val = dataset[int(self.n_sentences * self.train_split):int(self.n_sentences * (1-self.val_split))]
test = dataset[int(self.n_sentences * (1 – self.val_split)):]
# Prepare tokenizer for the encoder input
enc_tokenizer = self.create_tokenizer(dataset[:, 0])
enc_seq_length = self.find_seq_length(dataset[:, 0])
enc_vocab_size = self.find_vocab_size(enc_tokenizer, train[:, 0])
# Prepare tokenizer for the decoder input
dec_tokenizer = self.create_tokenizer(dataset[:, 1])
dec_seq_length = self.find_seq_length(dataset[:, 1])
dec_vocab_size = self.find_vocab_size(dec_tokenizer, train[:, 1])
# Encode and pad the training input
trainX = self.encode_pad(train[:, 0], enc_tokenizer, enc_seq_length)
trainY = self.encode_pad(train[:, 1], dec_tokenizer, dec_seq_length)
# Encode and pad the validation input
valX = self.encode_pad(val[:, 0], enc_tokenizer, enc_seq_length)
valY = self.encode_pad(val[:, 1], dec_tokenizer, dec_seq_length)
# Save the encoder tokenizer
self.save_tokenizer(enc_tokenizer, ‘enc’)
# Save the decoder tokenizer
self.save_tokenizer(dec_tokenizer, ‘dec’)
# Save the testing dataset into a text file
savetxt(‘test_dataset.txt’, test, fmt=»%s»)
return trainX, trainY, valX, valY, train, val, enc_seq_length, dec_seq_length, enc_vocab_size, dec_vocab_size
Entrenamiento del modelo de transformador
Introduciremos modificaciones similares al código que entrena el modelo Transformer, para:
- Prepare los lotes de conjuntos de datos de validación:
val_dataset = data.Dataset.from_tensor_slices((valX, valY))
val_dataset = val_dataset.batch(batch_size)
- Supervise la métrica de pérdida de validación:
val_loss = Mean(name=»val_loss»)
- Inicialice los diccionarios para almacenar las pérdidas de capacitación y validación y, finalmente, almacene los valores de pérdida en los diccionarios respectivos:
train_loss_dict = {}
val_loss_dict = {}
train_loss_dict[epoch] = train_loss.result()
val_loss_dict[epoch] = val_loss.result()
- Calcule la pérdida de validación:
loss = loss_fcn(decoder_output, prediction)
val_loss(loss)
- Guarde los pesos del modelo entrenado en cada época. Los usaremos en la etapa de inferencia, para poder investigar las diferencias en los resultados que produce el modelo en diferentes épocas. En la práctica, sería más eficiente incluir un método de devolución de llamada que detuviera el proceso de entrenamiento en función de las métricas que se monitorean durante el entrenamiento y solo luego guardar los pesos del modelo:
# Save the trained model weights
training_model.save_weights(«weights/wghts» + str(epoch + 1) + «.ckpt»)
- Finalmente, guarde los valores de pérdida de entrenamiento y validación en archivos pickle:
with open(‘./train_loss.pkl’, ‘wb’) as file:
dump(train_loss_dict, file)
with open(‘./val_loss.pkl’, ‘wb’) as file:
dump(val_loss_dict, file)
El listado de código modificado ahora se convierte en:
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.optimizers.schedules import LearningRateSchedule
from tensorflow.keras.metrics import Mean
from tensorflow import data, train, math, reduce_sum, cast, equal, argmax, float32, GradientTape, function
from keras.losses import sparse_categorical_crossentropy
from model import TransformerModel
from prepare_dataset import PrepareDataset
from time import time
from pickle import dump
# Define the model parameters
h = 8 # Number of self-attention heads
d_k = 64 # Dimensionality of the linearly projected queries and keys
d_v = 64 # Dimensionality of the linearly projected values
d_model = 512 # Dimensionality of model layers’ outputs
d_ff = 2048 # Dimensionality of the inner fully connected layer
n = 6 # Number of layers in the encoder stack
# Define the training parameters
epochs = 20
batch_size = 64
beta_1 = 0.9
beta_2 = 0.98
epsilon = 1e-9
dropout_rate = 0.1
# Implementing a learning rate scheduler
class LRScheduler(LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000, **kwargs):
super(LRScheduler, self).__init__(**kwargs)
self.d_model = cast(d_model, float32)
self.warmup_steps = warmup_steps
def __call__(self, step_num):
# Linearly increasing the learning rate for the first warmup_steps, and decreasing it thereafter
arg1 = step_num ** -0.5
arg2 = step_num * (self.warmup_steps ** -1.5)
return (self.d_model ** -0.5) * math.minimum(arg1, arg2)
# Instantiate an Adam optimizer
optimizer = Adam(LRScheduler(d_model), beta_1, beta_2, epsilon)
# Prepare the training dataset
dataset = PrepareDataset()
trainX, trainY, valX, valY, train_orig, val_orig, enc_seq_length, dec_seq_length, enc_vocab_size, dec_vocab_size = dataset(‘english-german.pkl’)
print(enc_seq_length, dec_seq_length, enc_vocab_size, dec_vocab_size)
# Prepare the training dataset batches
train_dataset = data.Dataset.from_tensor_slices((trainX, trainY))
train_dataset = train_dataset.batch(batch_size)
# Prepare the validation dataset batches
val_dataset = data.Dataset.from_tensor_slices((valX, valY))
val_dataset = val_dataset.batch(batch_size)
# Create model
training_model = TransformerModel(enc_vocab_size, dec_vocab_size, enc_seq_length, dec_seq_length, h, d_k, d_v, d_model, d_ff, n, dropout_rate)
# Defining the loss function
def loss_fcn(target, prediction):
# Create mask so that the zero padding values are not included in the computation of loss
padding_mask = math.logical_not(equal(target, 0))
padding_mask = cast(padding_mask, float32)
# Compute a sparse categorical cross-entropy loss on the unmasked values
loss = sparse_categorical_crossentropy(target, prediction, from_logits=True) * padding_mask
# Compute the mean loss over the unmasked values
return reduce_sum(loss) / reduce_sum(padding_mask)
# Defining the accuracy function
def accuracy_fcn(target, prediction):
# Create mask so that the zero padding values are not included in the computation of accuracy
padding_mask = math.logical_not(equal(target, 0))
# Find equal prediction and target values, and apply the padding mask
accuracy = equal(target, argmax(prediction, axis=2))
accuracy = math.logical_and(padding_mask, accuracy)
# Cast the True/False values to 32-bit-precision floating-point numbers
padding_mask = cast(padding_mask, float32)
accuracy = cast(accuracy, float32)
# Compute the mean accuracy over the unmasked values
return reduce_sum(accuracy) / reduce_sum(padding_mask)
# Include metrics monitoring
train_loss = Mean(name=»train_loss»)
train_accuracy = Mean(name=»train_accuracy»)
val_loss = Mean(name=»val_loss»)
# Create a checkpoint object and manager to manage multiple checkpoints
ckpt = train.Checkpoint(model=training_model, optimizer=optimizer)
ckpt_manager = train.CheckpointManager(ckpt, «./checkpoints», max_to_keep=None)
# Initialise dictionaries to store the training and validation losses
train_loss_dict = {}
val_loss_dict = {}
# Speeding up the training process
@function
def train_step(encoder_input, decoder_input, decoder_output):
with GradientTape() as tape:
# Run the forward pass of the model to generate a prediction
prediction = training_model(encoder_input, decoder_input, training=True)
# Compute the training loss
loss = loss_fcn(decoder_output, prediction)
# Compute the training accuracy
accuracy = accuracy_fcn(decoder_output, prediction)
# Retrieve gradients of the trainable variables with respect to the training loss
gradients = tape.gradient(loss, training_model.trainable_weights)
# Update the values of the trainable variables by gradient descent
optimizer.apply_gradients(zip(gradients, training_model.trainable_weights))
train_loss(loss)
train_accuracy(accuracy)
for epoch in range(epochs):
train_loss.reset_states()
train_accuracy.reset_states()
val_loss.reset_states()
print(«nStart of epoch %d» % (epoch + 1))
start_time = time()
# Iterate over the dataset batches
for step, (train_batchX, train_batchY) in enumerate(train_dataset):
# Define the encoder and decoder inputs, and the decoder output
encoder_input = train_batchX[:, 1:]
decoder_input = train_batchY[:, :-1]
decoder_output = train_batchY[:, 1:]
train_step(encoder_input, decoder_input, decoder_output)
if step % 50 == 0:
print(f’Epoch {epoch + 1} Step {step} Loss {train_loss.result():.4f} Accuracy {train_accuracy.result():.4f}’)
# Run a validation step after every epoch of training
for val_batchX, val_batchY in val_dataset:
# Define the encoder and decoder inputs, and the decoder output
encoder_input = val_batchX[:, 1:]
decoder_input = val_batchY[:, :-1]
decoder_output = val_batchY[:, 1:]
# Generate a prediction
prediction = training_model(encoder_input, decoder_input, training=False)
# Compute the validation loss
loss = loss_fcn(decoder_output, prediction)
val_loss(loss)
# Print epoch number and accuracy and loss values at the end of every epoch
print(«Epoch %d: Training Loss %.4f, Training Accuracy %.4f, Validation Loss %.4f» % (epoch + 1, train_loss.result(), train_accuracy.result(), val_loss.result()))
# Save a checkpoint after every epoch
if (epoch + 1) % 1 == 0:
save_path = ckpt_manager.save()
print(«Saved checkpoint at epoch %d» % (epoch + 1))
# Save the trained model weights
training_model.save_weights(«weights/wghts» + str(epoch + 1) + «.ckpt»)
train_loss_dict[epoch] = train_loss.result()
val_loss_dict[epoch] = val_loss.result()
# Save the training loss values
with open(‘./train_loss.pkl’, ‘wb’) as file:
dump(train_loss_dict, file)
# Save the validation loss values
with open(‘./val_loss.pkl’, ‘wb’) as file:
dump(val_loss_dict, file)
print(«Total time taken: %.2fs» % (time() – start_time))
Trazado de las curvas de pérdida de entrenamiento y validación
Para poder trazar las curvas de pérdida de entrenamiento y validación, primero cargaremos los archivos pickle que contienen los diccionarios de pérdida de entrenamiento y validación, que habríamos guardado al entrenar el modelo Transformer anteriormente.
Luego, recuperaremos los valores de pérdida de entrenamiento y validación de los diccionarios respectivos y los graficaremos en el mismo gráfico.
La lista de códigos es la siguiente, que estoy guardando en un script de Python separado:
from pickle import load
from matplotlib.pylab import plt
from numpy import arange
# Load the training and validation loss dictionaries
train_loss = load(open(‘train_loss.pkl’, ‘rb’))
val_loss = load(open(‘val_loss.pkl’, ‘rb’))
# Retrieve each dictionary’s values
train_values = train_loss.values()
val_values = val_loss.values()
# Generate a sequence of integers to represent the epoch numbers
epochs = range(1, 21)
# Plot and label the training and validation loss values
plt.plot(epochs, train_values, label=»Training Loss»)
plt.plot(epochs, val_values, label=»Validation Loss»)
# Add in a title and axes labels
plt.title(‘Training and Validation Loss’)
plt.xlabel(‘Epochs’)
plt.ylabel(‘Loss’)
# Set the tick locations
plt.xticks(arange(0, 21, 2))
# Display the plot
plt.legend(loc=»best»)
plt.show()
Ejecutar el código anterior genera una gráfica similar de las curvas de pérdida de entrenamiento y validación a la siguiente:
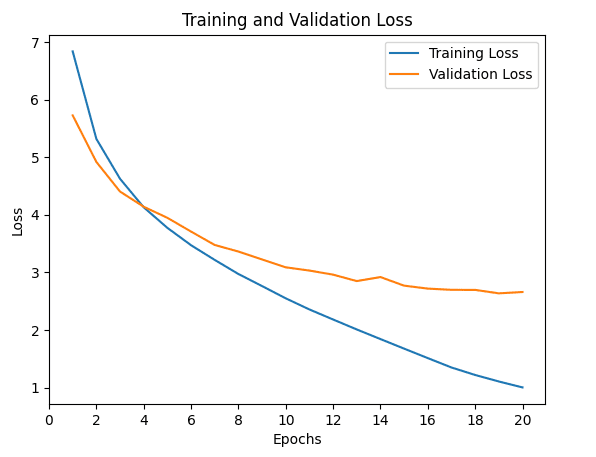
Gráficos de líneas de los valores de pérdida de entrenamiento y validación durante varias épocas de entrenamiento
Tenga en cuenta que, aunque es posible que vea curvas de pérdida similares, es posible que no sean necesariamente idénticas a las anteriores. Esto se debe a que estamos entrenando el modelo de Transformer desde cero, y los valores de pérdida de entrenamiento y validación resultantes dependen de la inicialización aleatoria de los pesos del modelo.
No obstante, estas curvas de pérdida sirven para darnos una mejor idea de cómo está cambiando el rendimiento del aprendizaje a lo largo de la cantidad de épocas y nos ayudan a diagnosticar cualquier problema con el aprendizaje que pueda conducir a un modelo inadecuado o excesivo.
Para obtener más detalles sobre el tema del uso de las curvas de pérdida de entrenamiento y validación para diagnosticar el rendimiento de aprendizaje de un modelo, puede consultar este tutorial de Jason Brownlee.
Otras lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar más.
Libros
- Aprendizaje profundo avanzado con Python, 2019.
- Transformadores para el procesamiento del lenguaje natural, 2021.
Documentos
- La atención es todo lo que necesitas, 2017.
sitios web
- Cómo utilizar las curvas de aprendizaje para diagnosticar el rendimiento del modelo de aprendizaje automático, https://machinelearningmastery.com/learning-curves-for-diagnosing-machine-learning-model-performance/
Resumen
En este tutorial, descubrió cómo trazar las curvas de pérdida de entrenamiento y validación para el modelo Transformer.
Específicamente, aprendiste:
- Cómo modificar el código de entrenamiento para incluir divisiones de validación y prueba, además de una división de entrenamiento del conjunto de datos.
- Cómo modificar el código de entrenamiento para almacenar los valores de pérdida de validación y entrenamiento calculados, así como los pesos del modelo entrenado.
- Cómo trazar las curvas de pérdida de entrenamiento y validación guardadas.
¿Tiene usted alguna pregunta?
Haga sus preguntas en los comentarios a continuación y haré todo lo posible para responder.
La publicación Trazado de las curvas de pérdida de entrenamiento y validación para el modelo de transformador apareció primero en Machine Learning Mastery.