

El Aprendizaje Automático de Máquinas (AutoML) se refiere a las técnicas para descubrir automáticamente modelos de buen rendimiento para tareas de modelado predictivo con muy poca participación del usuario.
TPOT es una biblioteca de código abierto para realizar AutoML en Python. Hace uso de la popular biblioteca de aprendizaje de máquinas Scikit-Learn para transformaciones de datos y algoritmos de aprendizaje de máquinas y utiliza un procedimiento de búsqueda global estocástica de Programación Genética para descubrir eficientemente un modelo de tubería de alto rendimiento para un determinado conjunto de datos.
En este tutorial, descubrirás cómo utilizar TPOT para AutoML con algoritmos de aprendizaje automático Scikit-Learn en Python.
Después de completar este tutorial, lo sabrás:
- TPOT es una biblioteca de código abierto para AutoML con preparación de datos de aprendizaje científico y modelos de aprendizaje automático.
- Cómo utilizar el TPOT para descubrir automáticamente modelos de alto rendimiento para las tareas de clasificación.
- Cómo usar TPOT para descubrir automáticamente modelos de alto rendimiento para tareas de regresión.
Empecemos.
TPOT para el aprendizaje automático de la máquina en Python
Foto de Gwen, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en cuatro partes; son:
- TPOT para el aprendizaje automático de la máquina
- Instalar y utilizar el TPOT
- TPOT para la clasificación
- TPOT para la regresión
TPOT para el aprendizaje automático de la máquina
La herramienta de optimización de tuberías basada en árboles, o TPOT para abreviar, es una biblioteca de Python para el aprendizaje automatizado de las máquinas.
TPOT utiliza una estructura basada en árboles para representar un modelo pipeline para un problema de modelación predictiva, incluyendo la preparación de datos y algoritmos de modelación e hiperparámetros de modelos.
… un algoritmo evolutivo llamado Herramienta de Optimización de Tuberías Basada en Árboles (TPOT) que diseña y optimiza automáticamente las tuberías de aprendizaje de las máquinas.
– Evaluación de una herramienta de optimización de oleoductos basada en árboles para automatizar la ciencia de los datos, 2016.
A continuación se realiza un procedimiento de optimización para encontrar una estructura de árbol que funcione mejor para un determinado conjunto de datos. Específicamente, un algoritmo de programación genética, diseñado para realizar una optimización global estocástica en programas representados como árboles.
TPOT utiliza una versión de la programación genética para diseñar y optimizar automáticamente una serie de transformaciones de datos y modelos de aprendizaje automático que intentan maximizar la precisión de la clasificación para un determinado conjunto de datos de aprendizaje supervisado.
– Evaluación de una herramienta de optimización de oleoductos basada en árboles para automatizar la ciencia de los datos, 2016.
La siguiente figura, tomada del documento TPOT, muestra los elementos que intervienen en la búsqueda de oleoductos, incluida la limpieza de datos, la selección de características, el procesamiento de características, la construcción de características, la selección de modelos y la optimización de hiperparámetros.
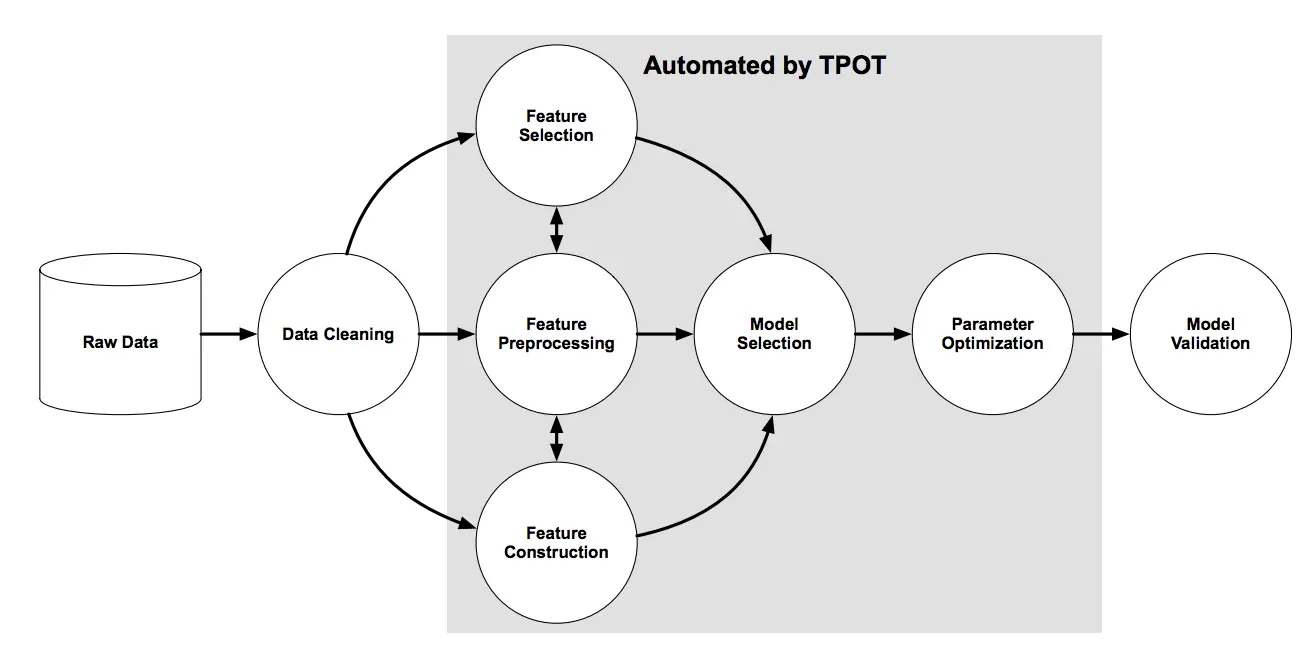
Resumen de la búsqueda de la tubería de TPOT
Tomado de: Evaluation of a Tree-based Pipeline Optimization Tool for Automaating Data Science, 2016.
Ahora que estamos familiarizados con lo que es TPOT, veamos cómo podemos instalar y usar TPOT para encontrar un modelo efectivo de tubería.
Instalar y utilizar el TPOT
El primer paso es instalar la biblioteca de TPOT, que se puede lograr usando pip, de la siguiente manera:
Una vez instalado, podemos importar la biblioteca e imprimir el número de versión para confirmar que se instaló con éxito:
|
# Verificar la versión del tpot importación tpot imprimir(‘tpot: %s’ % tpot.La versión…) |
Ejecutando el ejemplo se imprime el número de versión.
Su número de versión debería ser el mismo o más alto.
Usar el TPOT es sencillo.
Implica crear una instancia de la clase TPOTRegressor o TPOTClassifier, configurarla para la búsqueda, y luego exportar el modelo de tubería que se encontró para lograr el mejor rendimiento en su conjunto de datos.
La configuración de la clase implica dos elementos principales.
El primero es cómo se evaluarán los modelos, por ejemplo, el esquema de validación cruzada y la métrica de rendimiento. Recomiendo que se especifique explícitamente una clase de validación cruzada con la configuración elegida y la métrica de rendimiento a utilizar.
Por ejemplo, RepeatedKFold para la regresión con ‘error_absoluto_negativo…métrica para la regresión:
|
... # Definir el procedimiento de evaluación cv = RepetidoKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Definir la búsqueda modelo = TPOTRegressor(... puntuación=‘neg_mean_absolute_error’, cv=cv) |
O un RepetidoEstratificadoKFold para la regresión con ‘exactitud…métrica para la clasificación:
|
... # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Definir la búsqueda modelo = TPOTClassifier(... puntuación=«exactitud, cv=cv) |
El otro elemento es la naturaleza del procedimiento de búsqueda global estocástica.
Como algoritmo evolutivo, esto implica la configuración de los parámetros, como el tamaño de la población, el número de generaciones a ejecutar y, potencialmente, las tasas de cruce y mutación. Los primeros controlan de manera importante la extensión de la búsqueda; los segundos pueden dejarse en valores por defecto si la búsqueda evolutiva es nueva para usted.
Por ejemplo, un tamaño de población modesto de 100 y 5 o 10 generaciones es un buen punto de partida.
|
... # Definir la búsqueda modelo = TPOTClassifier(generaciones=5, tamaño_de_la_población=50, ...) |
Al final de la búsqueda, se encuentra un Pipeline que funciona mejor.
Este Pipeline puede ser exportado como código en un archivo Python que luego puede copiar y pegar en su propio proyecto.
|
... # Exportar el mejor modelo modelo.exportación(‘tpot_model.py’) |
Ahora que estamos familiarizados con el uso de TPOT, veamos algunos ejemplos trabajados con datos reales.
TPOT para la clasificación
En esta sección, usaremos TPOT para descubrir un modelo para el conjunto de datos del sonar.
El conjunto de datos del sonar es un conjunto de datos estándar para el aprendizaje de la máquina, compuesto por 208 filas de datos con 60 variables de entrada numéricas y una variable objetivo con dos valores de clase, por ejemplo, la clasificación binaria.
Utilizando un arnés de prueba de validación cruzada estratificada 10 veces con tres repeticiones, un modelo ingenuo puede lograr una precisión de alrededor del 53 por ciento. Un modelo de alto rendimiento puede lograr una precisión en este mismo arnés de prueba de alrededor del 88 por ciento. Esto proporciona los límites del rendimiento esperado en este conjunto de datos.
El conjunto de datos implica la predicción de si los retornos del sonar indican una roca o una mina simulada.
No es necesario descargar el conjunto de datos; lo descargaremos automáticamente como parte de nuestros ejemplos de trabajo.
El siguiente ejemplo descarga el conjunto de datos y resume su forma.
|
# Resumir el conjunto de datos del sonar de pandas importación lea_csv # Cargar conjunto de datos url = «https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv dataframe = read_csv(url, encabezado=Ninguno) # Dividido en elementos de entrada y salida datos = dataframe.valores X, y = datos[[:, :–1], datos[[:, –1] imprimir(X.forma, y.forma) |
Ejecutando el ejemplo se descarga el conjunto de datos y se divide en elementos de entrada y salida. Como era de esperar, podemos ver que hay 208 filas de datos con 60 variables de entrada.
A continuación, usemos TPOT para encontrar un buen modelo para el conjunto de datos del sonar.
Primero, podemos definir el método para evaluar los modelos. Utilizaremos una buena práctica de validación cruzada estratificada k-pliegue repetida con tres repeticiones y 10 pliegues.
|
... # Definir la evaluación del modelo cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) |
Usaremos un tamaño de población de 50 por cinco generaciones para la búsqueda y usaremos todos los núcleos en el sistema estableciendo «n_jobs» a -1.
|
... # Definir la búsqueda modelo = TPOTClassifier(generaciones=5, tamaño_de_la_población=50, cv=cv, puntuación=«exactitud, verbosidad=2, estado_aleatorio=1, n_jobs=–1) |
Finalmente, podemos iniciar la búsqueda y asegurarnos de que el modelo de mejor rendimiento se guarda al final de la carrera.
|
... # realizar la búsqueda modelo.encajar(X, y) # Exportar el mejor modelo modelo.exportación(‘tpot_sonar_best_model.py’) |
A continuación se muestra el ejemplo completo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# Ejemplo de tpot para el conjunto de datos de clasificación del sonar de pandas importación read_csv de sklearn.preprocesamiento importación LabelEncoder de sklearn.model_selection importación RepeatedStratifiedKFold de tpot importación TPOTClassifier # Cargar conjunto de datos url = «https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv dataframe = read_csv(url, encabezado=Ninguno) # Dividido en elementos de entrada y salida datos = dataframe.valores X, y = datos[[:, :–1], datos[[:, –1] # Preparar mínimamente el conjunto de datos X = X.astype(«Float32) y = LabelEncoder().fit_transform(y.astype(«str)) # Definir la evaluación del modelo cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Definir la búsqueda modelo = TPOTClassifier(generaciones=5, tamaño_de_la_población=50, cv=cv, puntuación=«exactitud, verbosidad=2, estado_aleatorio=1, n_jobs=–1) # realizar la búsqueda modelo.encajar(X, y) # Exportar el mejor modelo modelo.exportación(‘tpot_sonar_best_model.py’) |
Ejecutar el ejemplo puede llevar unos minutos, y verás una barra de progreso en la línea de comandos.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
La precisión de los modelos de alto rendimiento se informará a lo largo del camino.
|
Generación 1 – Mejor puntaje actual de CV interno: 0.8650793650793651 Generación 2 – Mejor puntaje actual de CV interno: 0.8650793650793651 Generación 3 – La mejor puntuación actual de CV interno: 0,8650793650793651 Generación 4 – Mejor puntaje actual de CV interno: 0.8650793650793651 Generación 5 – Mejor puntaje actual de CV interno: 0.8667460317460318 El mejor oleoducto: GradientBoostingClassifier(GaussianNB(input_matrix), learning_rate=0.1, max_depth=7, max_features=0.7000000000000001, min_samples_leaf=15, min_samples_split=10, n_estimators=100, subsample=0.9000000000000001) |
En este caso, podemos ver que el oleoducto de mayor rendimiento alcanzó una precisión media de alrededor del 86,6 por ciento. Este es un modelo hábil, y cercano a un modelo de alto rendimiento en este conjunto de datos.
El oleoducto de mayor rendimiento se guarda en un archivo llamado «tpot_sonar_best_model.py“.
Al abrir este archivo, se puede ver que hay un código genérico para cargar un conjunto de datos y ajustar la tubería. A continuación se muestra un ejemplo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
importación numpy como np importación pandas como pd de sklearn.conjunto importación GradientBoostingClassifier de sklearn.model_selection importación prueba_de_trenes_split de sklearn.naive_bayes importación GaussianNB de sklearn.tubería importación make_pipeline, make_union de tpot.builtins importación StackingEstimator de tpot.export_utils importación set_param_recursivo # NOTA: Asegúrate de que la columna de resultados esté etiquetada como «objetivo» en el archivo de datos tpot_data = pd.read_csv(«RUTA/AL/ARCHIVO DE DATOS, sep=‘COLUMN_SEPARATOR’, dtype=np.float64) características = tpot_data.dejar caer(«objetivo, eje=1) funciones_de_entrenamiento, características_de_pruebas, training_target, testing_target = prueba_de_trenes_split(características, tpot_data[[«objetivo], estado_aleatorio=1) # La puntuación media del CV en el conjunto de entrenamiento fue: 0,8667460317460318 export_pipeline = make_pipeline( StackingEstimator(estimador=GaussianNB()), GradientBoostingClassifier(tasa_de_aprendizaje=0.1, max_depth=7, max_features=0.7000000000000001, min_samples_leaf=15, min_samples_split=10, n_estimadores=100, submuestra=0.9000000000000001) ) # Fijar el estado aleatorio para todos los pasos de la tubería exportada set_param_recursive(export_pipeline.pasos, ‘estado_aleatorio’…, 1) export_pipeline.encajar(funciones_de_entrenamiento, training_target) resultados = export_pipeline.predecir(características_de_pruebas) |
NotaTal como está, este código no se ejecuta, por diseño. Es una plantilla que puedes copiar y pegar en tu proyecto.
En este caso, podemos ver que el modelo de mejor rendimiento es un pipeline compuesto por un modelo de Bayes ingenuo y un modelo de Gradient Boosting.
Podemos adaptar este código para que se ajuste a un modelo final con todos los datos disponibles y hacer una predicción para los nuevos datos.
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# Ejemplo de ajustar un modelo final y hacer una predicción en el conjunto de datos del sonar # de pandas importación read_csv de sklearn.preprocesamiento importación LabelEncoder de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.conjunto importación GradientBoostingClassifier de sklearn.naive_bayes importación GaussianNB de sklearn.tubería importación make_pipeline de tpot.builtins importación StackingEstimator de tpot.export_utils importación set_param_recursivo # Cargar conjunto de datos url = «https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv dataframe = read_csv(url, encabezado=Ninguno) # Dividido en elementos de entrada y salida datos = dataframe.valores X, y = datos[[:, :–1], datos[[:, –1] # Preparar mínimamente el conjunto de datos X = X.astype(«Float32) y = LabelEncoder().fit_transform(y.astype(«str)) # La puntuación media del CV en el conjunto de entrenamiento fue: 0,8667460317460318 export_pipeline = make_pipeline( StackingEstimator(estimador=GaussianNB()), GradientBoostingClassifier(tasa_de_aprendizaje=0.1, max_depth=7, max_features=0.7000000000000001, min_samples_leaf=15, min_samples_split=10, n_estimadores=100, submuestra=0.9000000000000001) ) # Fijar el estado aleatorio para todos los pasos de la tubería exportada set_param_recursive(export_pipeline.pasos, ‘estado_aleatorio’…, 1) # Encaja con el modelo export_pipeline.encajar(X, y) # hacer una predicción en una nueva fila de datos fila = [[0.0200,0.0371,0.0428,0.0207,0.0954,0.0986,0.1539,0.1601,0.3109,0.2111,0.1609,0.1582,0.2238,0.0645,0.0660,0.2273,0.3100,0.2999,0.5078,0.4797,0.5783,0.5071,0.4328,0.5550,0.6711,0.6415,0.7104,0.8080,0.6791,0.3857,0.1307,0.2604,0.5121,0.7547,0.8537,0.8507,0.6692,0.6097,0.4943,0.2744,0.0510,0.2834,0.2825,0.4256,0.2641,0.1386,0.1051,0.1343,0.0383,0.0324,0.0232,0.0027,0.0065,0.0159,0.0072,0.0167,0.0180,0.0084,0.0090,0.0032] yhat = export_pipeline.predecir([[fila]) imprimir(«Predicho: %.3f % yhat[[0]) |
La ejecución del ejemplo se ajusta al modelo de mejor rendimiento del conjunto de datos y hace una predicción para una sola fila de nuevos datos.
TPOT para la regresión
En esta sección, usaremos TPOT para descubrir un modelo para el conjunto de datos del seguro de automóviles.
El conjunto de datos de seguro de automóviles es un conjunto de datos estándar de aprendizaje por máquina que consta de 63 filas de datos con una variable de entrada numérica y una variable de destino numérica.
Utilizando un arnés de pruebas de validación cruzada estratificada 10 veces con tres repeticiones, un modelo ingenuo puede lograr un error absoluto medio (MAE) de alrededor de 66. Un modelo de alto rendimiento puede lograr un MAE en este mismo arnés de prueba de alrededor de 28. Esto proporciona los límites del rendimiento esperado en este conjunto de datos.
El conjunto de datos implica la predicción de la cantidad total en reclamaciones (miles de coronas suecas) dado el número de reclamaciones para las diferentes regiones geográficas.
No es necesario descargar el conjunto de datos; lo descargaremos automáticamente como parte de nuestros ejemplos de trabajo.
El siguiente ejemplo descarga el conjunto de datos y resume su forma.
|
# Resumir el conjunto de datos del seguro de auto de pandas importación lea_csv # Cargar conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/auto-insurance.csv’ dataframe = read_csv(url, encabezado=Ninguno) # Dividido en elementos de entrada y salida datos = dataframe.valores X, y = datos[[:, :–1], datos[[:, –1] imprimir(X.forma, y.forma) |
Ejecutando el ejemplo se descarga el conjunto de datos y se divide en elementos de entrada y salida. Como era de esperar, podemos ver que hay 63 filas de datos con una variable de entrada.
A continuación, podemos usar TPOT para encontrar un buen modelo para el conjunto de datos del seguro de automóviles.
Primero, podemos definir el método para evaluar los modelos. Usaremos una buena práctica de validación cruzada repetida k-pliegue con tres repeticiones y 10 pliegues.
|
... # Definir el procedimiento de evaluación cv = RepetidoKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) |
Usaremos un tamaño de población de 50 por 5 generaciones para la búsqueda y usaremos todos los núcleos en el sistema estableciendo «n_jobs» a -1.
|
... # Definir la búsqueda modelo = TPOTRegressor(generaciones=5, tamaño_de_la_población=50, puntuación=‘neg_mean_absolute_error’, cv=cv, verbosidad=2, estado_aleatorio=1, n_jobs=–1) |
Finalmente, podemos iniciar la búsqueda y asegurarnos de que el modelo de mejor rendimiento se guarda al final de la carrera.
|
... # realizar la búsqueda modelo.encajar(X, y) # Exportar el mejor modelo modelo.exportación(‘tpot_insurance_best_model.py’) |
A continuación se muestra el ejemplo completo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# Ejemplo de tpot para el conjunto de datos de regresión del seguro de pandas importación read_csv de sklearn.model_selection importación RepetidoKFold de tpot importación TPOTRegressor # Cargar conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/auto-insurance.csv’ dataframe = read_csv(url, encabezado=Ninguno) # Dividido en elementos de entrada y salida datos = dataframe.valores datos = datos.astype(«Float32) X, y = datos[[:, :–1], datos[[:, –1] # Definir el procedimiento de evaluación cv = RepetidoKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Definir la búsqueda modelo = TPOTRegressor(generaciones=5, tamaño_de_la_población=50, puntuación=‘neg_mean_absolute_error’, cv=cv, verbosidad=2, estado_aleatorio=1, n_jobs=–1) # realizar la búsqueda modelo.encajar(X, y) # Exportar el mejor modelo modelo.exportación(‘tpot_insurance_best_model.py’) |
Ejecutar el ejemplo puede llevar unos minutos, y verás una barra de progreso en la línea de comandos.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
El MAE de los modelos de mayor rendimiento será informado a lo largo del camino.
|
Generación 1 – Mejor puntaje actual de CV interno: -29.147625969129034 Generación 2 – Mejor puntaje actual de CV interno: -29.147625969129034 Generación 3 – Mejor puntaje actual de CV interno: -29.147625969129034 Generación 4 – Mejor puntaje actual de CV interno: -29.147625969129034 Generación 5 – Mejor puntaje actual de CV interno: -29.147625969129034 El mejor oleoducto: LinearSVR(matriz_de_entrada, C=1.0, dual=Falso, epsilon=0.0001, pérdida=cuadrada_epsilon_insensible, tol=0.001) |
En este caso, podemos ver que el oleoducto de mayor rendimiento alcanzó el MAE medio de alrededor de 29,14. Este es un modelo hábil, y cercano a un modelo de alto rendimiento en este conjunto de datos.
El oleoducto de mayor rendimiento se guarda en un archivo llamado «tpot_insurance_best_model.py“.
Al abrir este archivo, se puede ver que hay un código genérico para cargar un conjunto de datos y ajustar la tubería. A continuación se muestra un ejemplo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
importación numpy como np importación pandas como pd de sklearn.model_selection importación prueba_de_trenes_split de sklearn.svm importación LinearSVR # NOTA: Asegúrate de que la columna de resultados esté etiquetada como «objetivo» en el archivo de datos tpot_data = pd.read_csv(«RUTA/AL/ARCHIVO DE DATOS, sep=‘COLUMN_SEPARATOR’, dtype=np.float64) características = tpot_data.dejar caer(«objetivo, eje=1) funciones_de_entrenamiento, características_de_pruebas, training_target, testing_target = prueba_de_trenes_split(características, tpot_data[[«objetivo], estado_aleatorio=1) # La puntuación media del CV en el conjunto de entrenamiento fue: -29.147625969129034 export_pipeline = LinearSVR(C=1.0, doble=Falso, epsilon=0.0001, pérdida=«squared_epsilon_insensitive», tol=0.001) # Fijar el estado aleatorio en el estimador exportado si hasattr(export_pipeline, ‘estado_aleatorio’…): setattr(export_pipeline, ‘estado_aleatorio’…, 1) export_pipeline.encajar(funciones_de_entrenamiento, training_target) resultados = export_pipeline.predecir(características_de_pruebas) |
NotaTal como está, este código no se ejecuta, por diseño. Es una plantilla que puedes copiar y pegar en tu proyecto.
En este caso, podemos ver que el modelo de mejor rendimiento es una tubería compuesta por un modelo de máquina de vector de soporte lineal.
Podemos adaptar este código para que se ajuste a un modelo final con todos los datos disponibles y hacer una predicción para los nuevos datos.
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# Ejemplo de ajustar un modelo final y hacer una predicción en el conjunto de datos del seguro de pandas importación read_csv de sklearn.model_selection importación prueba_de_trenes_split de sklearn.svm importación LinearSVR # Cargar conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/auto-insurance.csv’ dataframe = read_csv(url, encabezado=Ninguno) # Dividido en elementos de entrada y salida datos = dataframe.valores datos = datos.astype(«Float32) X, y = datos[[:, :–1], datos[[:, –1] # La puntuación media del CV en el conjunto de entrenamiento fue: -29.147625969129034 export_pipeline = LinearSVR(C=1.0, doble=Falso, epsilon=0.0001, pérdida=«squared_epsilon_insensitive», tol=0.001) # Fijar el estado aleatorio en el estimador exportado si hasattr(export_pipeline, ‘estado_aleatorio’…): setattr(export_pipeline, ‘estado_aleatorio’…, 1) # Encaja con el modelo export_pipeline.encajar(X, y) # hacer una predicción en una nueva fila de datos fila = [[108] yhat = export_pipeline.predecir([[fila]) imprimir(«Predicho: %.3f % yhat[[0]) |
La ejecución del ejemplo se ajusta al modelo de mejor rendimiento del conjunto de datos y hace una predicción para una sola fila de nuevos datos.
Más lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar en él.
Resumen
En este tutorial, descubriste cómo usar TPOT para AutoML con algoritmos de aprendizaje automático Scikit-Learn en Python.
Específicamente, aprendiste:
- TPOT es una biblioteca de código abierto para AutoML con preparación de datos de aprendizaje científico y modelos de aprendizaje automático.
- Cómo utilizar el TPOT para descubrir automáticamente modelos de alto rendimiento para las tareas de clasificación.
- Cómo usar TPOT para descubrir automáticamente modelos de alto rendimiento para tareas de regresión.
¿Tiene alguna pregunta?
Haga sus preguntas en los comentarios de abajo y haré lo posible por responder.
Descubre el aprendizaje rápido de la máquina en Python!

Desarrolle sus propios modelos en minutos
…con sólo unas pocas líneas de código de aprendizaje científico…
Aprende cómo en mi nuevo Ebook:
Dominio de la máquina de aprendizaje con la pitón
Cubre Tutoriales de auto-estudio y proyectos integrales como:
Cargando datos, visualización, modelado, tuningy mucho más…
Finalmente traer el aprendizaje automático a
Sus propios proyectos
Sáltese los académicos. Sólo los resultados.
Ver lo que hay dentro