

Este artículo es parte de nuestras revisiones de trabajos de investigación de IA, una serie de publicaciones que exploran los últimos hallazgos en inteligencia artificial.
Los modelos de aprendizaje profundo deben su éxito inicial a los grandes servidores con grandes cantidades de memoria y grupos de GPU. Las promesas del aprendizaje profundo dieron lugar a toda una industria de servicios de computación en la nube para redes neuronales profundas. En consecuencia, las redes neuronales muy grandes que se ejecutan en recursos de nube virtualmente ilimitados se volvieron muy populares, especialmente entre las empresas tecnológicas ricas que pueden pagar la factura.
Pero al mismo tiempo, los últimos años también han visto una tendencia inversa, un esfuerzo concertado para crear modelos de aprendizaje automático para dispositivos de borde. Estos modelos, llamados tiny machine learning, o TinyML, son adecuados para dispositivos que tienen memoria y potencia de procesamiento limitadas, y en los que la conectividad a Internet no está presente o es limitada.
El último de estos esfuerzos, un trabajo conjunto de IBM y el Instituto de Tecnología de Massachusetts (MIT), aborda el cuello de botella de memoria máxima de las redes neuronales convolucionales (CNN), una arquitectura de aprendizaje profundo que es especialmente crítica para las aplicaciones de visión por computadora. Detallado en un documento presentado en la conferencia NeurIPS 2021, el modelo se llama MCUNetV2 y puede ejecutar CNN en microcontroladores de baja memoria y baja potencia.
¿Por qué TinyML?

Si bien el aprendizaje profundo en la nube ha tenido un gran éxito, no es aplicable en todas las situaciones. Muchas aplicaciones requieren inferencia en el dispositivo. Por ejemplo, en algunos entornos, como las misiones de rescate con drones, la conectividad a Internet no está garantizada. En otros dominios, como la atención médica, los requisitos y regulaciones de privacidad hacen que sea muy difícil enviar datos a la nube para su procesamiento. Y el retraso causado por el viaje de ida y vuelta a la nube es prohibitivo para las aplicaciones que requieren inferencia de ML en tiempo real.
Todas estas necesidades han hecho que el aprendizaje automático en el dispositivo sea atractivo tanto desde el punto de vista científico como comercial. Su iPhone ahora ejecuta el reconocimiento facial y el reconocimiento de voz en el dispositivo. Su teléfono Android puede ejecutar la traducción en el dispositivo. Su Apple Watch utiliza el aprendizaje automático para detectar movimientos y patrones de ECG.
Estos modelos ML en el dispositivo han sido posibles en parte gracias a los avances en las técnicas utilizadas para hacer que las redes neuronales sean compactas y más eficientes en términos de cómputo y memoria. Pero también han sido posibles gracias a los avances en hardware. Nuestros teléfonos inteligentes y dispositivos portátiles ahora tienen más poder de cómputo que un servidor hace 30 años. Algunos incluso tienen coprocesadores especializados para la inferencia de ML.
TinyML lleva la inteligencia artificial avanzada un paso más allá, lo que hace posible ejecutar modelos de aprendizaje profundo en microcontroladores (MCU), que tienen muchos más recursos limitados que las pequeñas computadoras que llevamos en nuestros bolsillos y en nuestras muñecas.
Los microcontroladores son baratos, con precios de venta promedio que alcanzan menos de $0,50, y están en todas partes, integrados en dispositivos industriales y de consumo. Al mismo tiempo, no tienen los recursos que se encuentran en los dispositivos informáticos genéricos. La mayoría de ellos no tienen un sistema operativo. Tienen una CPU pequeña, están limitados a unos pocos cientos de kilobytes de memoria de bajo consumo (SRAM) y unos pocos megabytes de almacenamiento, y no tienen ningún equipo de red. En su mayoría, no tienen una fuente de electricidad de la red y deben funcionar con pilas y baterías de monedas durante años. Por lo tanto, la instalación de modelos de aprendizaje profundo en MCU puede abrir el camino para muchas aplicaciones.
Cuellos de botella de memoria en redes neuronales convolucionales
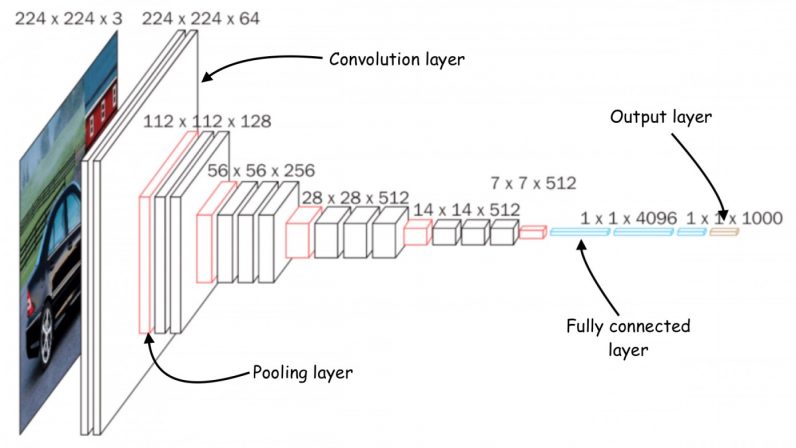
Ha habido múltiples esfuerzos para reducir las redes neuronales profundas a un tamaño que se ajuste a los dispositivos informáticos de memoria pequeña. Sin embargo, la mayoría de estos esfuerzos se centran en reducir la cantidad de parámetros en el modelo de aprendizaje profundo. Por ejemplo, la «poda», una clase popular de algoritmos de optimización, comprime las redes neuronales eliminando los parámetros que no son significativos en la salida del modelo.
El problema con los métodos de poda es que no abordan el cuello de botella de memoria de las redes neuronales. Las implementaciones estándar de bibliotecas de aprendizaje profundo requieren que se cargue en la memoria una capa de red completa y mapas de activación. Desafortunadamente, los métodos de optimización clásicos no realizan cambios significativos en las primeras capas de la red, especialmente en las redes neuronales convolucionales.
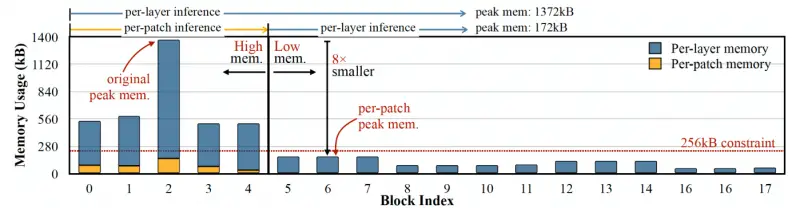
Esto provoca un desequilibrio en el tamaño de las diferentes capas de la red y da como resultado un problema de «pico de memoria»: aunque la red se vuelve más ligera después de la poda, el dispositivo que la ejecuta debe tener tanta memoria como la capa más grande. Por ejemplo, en MobileNetV2, un popular modelo de TinyML, los primeros bloques de capa tienen un pico de memoria que alcanza alrededor de 1,4 megabytes, mientras que las últimas capas tienen una huella de memoria muy pequeña. Para ejecutar el modelo, un dispositivo necesitará tanta memoria como el pico del modelo. Dado que la mayoría de los MCU no tienen más de unos pocos cientos de kilobytes de memoria, no pueden ejecutar la versión estándar de MobileNetV2.
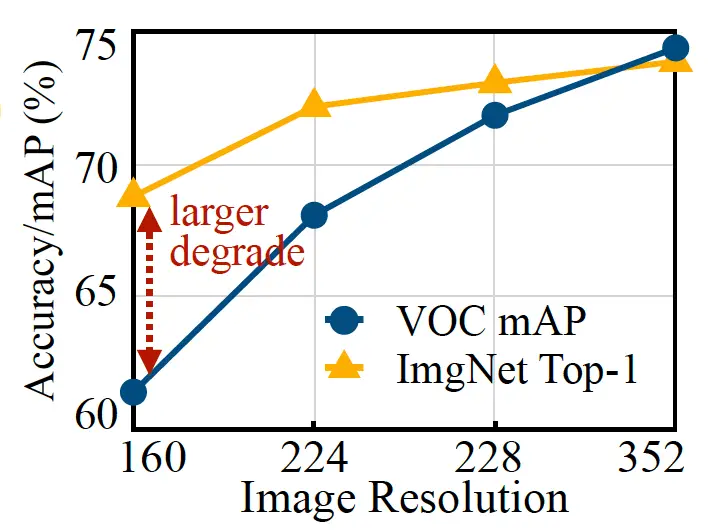
Otro enfoque para optimizar las redes neuronales es reducir el tamaño de entrada del modelo. Una imagen de entrada más pequeña requiere una CNN más pequeña para realizar tareas de predicción. Sin embargo, reducir el tamaño de entrada presenta sus propios desafíos y no es eficiente para todas las tareas de visión artificial. Por ejemplo, los modelos de aprendizaje profundo de detección de objetos son muy sensibles al tamaño de la imagen y su rendimiento cae rápidamente cuando se reduce la resolución de entrada.
Inferencia basada en parches con MCUNetV2
Para abordar el cuello de botella de memoria de las redes neuronales convolucionales, los investigadores crearon MCUNetV2, una arquitectura de aprendizaje profundo que puede ajustar su ancho de banda de memoria a los límites de los microcontroladores. MCUNetV2 se basa en el trabajo anterior del mismo grupo, que fue aceptado y presentado en la conferencia NeurIPS 2020.
La idea principal detrás de MCUNetV2 es la «inferencia basada en parches», una técnica que reduce la huella de memoria de las CNN sin degradar su precisión. En lugar de cargar una capa de red neuronal completa en la memoria, MCUNetV2 carga y calcula una región más pequeña, o un «parche», de la capa en un momento dado. Luego itera en toda la capa parche por parche y combina los valores hasta que calcula las activaciones para toda la capa.
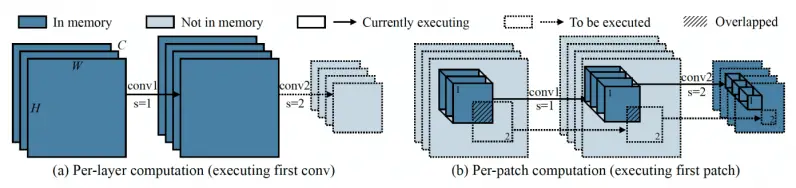
Dado que MCUNetV2 solo necesita almacenar un parche de neuronas a la vez, reduce considerablemente el pico de memoria sin reducir la resolución o los parámetros del modelo. Los experimentos de los investigadores muestran que MCUNetV2 puede reducir el pico de memoria en un factor de ocho.
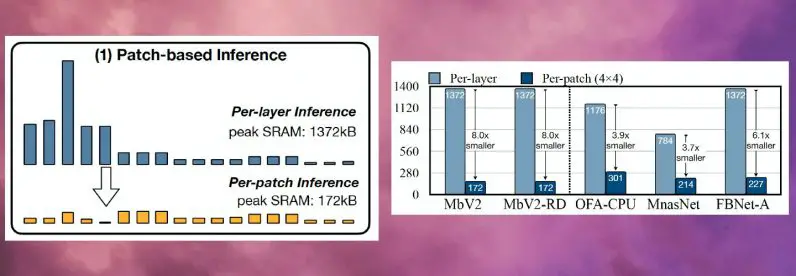
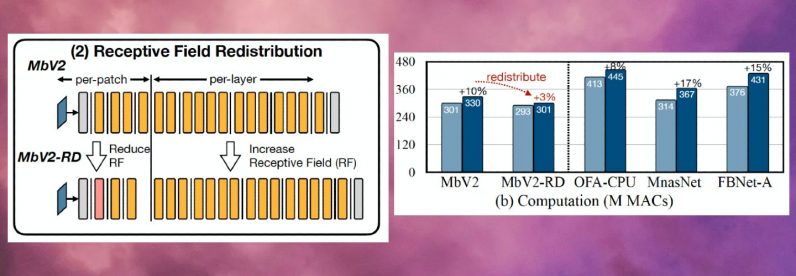
Los beneficios de ahorro de memoria de la inferencia basada en parches vienen con una compensación de gastos generales de cálculo. Los investigadores del MIT e IBM descubrieron que el cómputo general de la red podría aumentar entre un 10 y un 17 por ciento en diferentes arquitecturas, lo que no es adecuado para microcontroladores de baja potencia.
Para superar este límite, los investigadores redistribuyeron el “campo receptivo” de los diferentes bloques de la red. En las CNN, el campo receptivo es el área de la imagen que se procesa en un momento dado. Los campos receptivos más grandes requieren parches más grandes y superposiciones entre parches, lo que crea una sobrecarga de cómputo más alta. Al reducir los campos receptivos de los bloques iniciales de la red y ampliar los campos receptivos de las etapas posteriores, los investigadores pudieron reducir la sobrecarga de cómputo en más de dos tercios.
Finalmente, los investigadores observaron que los ajustes de MCUNetV2 dependen en gran medida de la arquitectura del modelo ML, la aplicación y la memoria y la capacidad de almacenamiento del dispositivo de destino. Para evitar ajustar manualmente el modelo de aprendizaje profundo para cada dispositivo y aplicación, los investigadores utilizaron la «búsqueda algorítmica neuronal», un proceso que utiliza el aprendizaje automático para optimizar automáticamente la arquitectura de la red neuronal y la programación de inferencias.
Los investigadores probaron la arquitectura de aprendizaje profundo en diferentes aplicaciones en varios modelos de microcontroladores con poca capacidad de memoria. Los resultados muestran que MCUNetV2 supera a otras técnicas de TinyML, alcanzando una mayor precisión en la clasificación de imágenes y detección de objetos con menores requisitos de memoria y latencias más bajas.
Los investigadores muestran MCUNetV2 en acción mediante detección de personas en tiempo real, palabras de activación visuales y detección de rostro/máscara.
Aplicaciones de TinyML
En un ensayo de 2018 titulado «Por qué el futuro del aprendizaje automático es diminuto», el ingeniero de software Pete Warden argumentó que el aprendizaje automático en MCU es extremadamente importante. “Estoy convencido de que el aprendizaje automático puede ejecutarse en chips diminutos de bajo consumo y que esta combinación resolverá una gran cantidad de problemas para los que no tenemos soluciones en este momento”, escribió Warden.
Nuestra capacidad para capturar datos del mundo ha aumentado enormemente gracias a los avances en sensores y CPU. Pero nuestra capacidad para procesar y usar esos datos a través de modelos de aprendizaje automático se ha visto limitada por la conectividad de la red y el acceso a los servidores en la nube. Como argumentó Warden, los procesadores y sensores son mucho más eficientes energéticamente que los transmisores de radio como Bluetooth y wifi.
“La física de mover datos parece requerir mucha energía. Parece haber una regla de que la energía que consume una operación es proporcional a la distancia a la que debe enviar los bits. Las CPU y los sensores envían bits de unos pocos milímetros, y es barato, la radio los envía metros o más y es caro”, escribió Warden. “[It’s] Obviamente, hay un mercado masivo sin explotar que espera ser desbloqueado con la tecnología adecuada. Necesitamos algo que funcione con microcontroladores baratos, que use muy poca energía, que dependa de la computación y no de la radio, y que pueda convertir todos los datos de sensores desperdiciados en algo útil. Este es el vacío que llena el aprendizaje automático, y específicamente el aprendizaje profundo”.
Gracias a MCUNetV2 y otros avances en TinyML, el pronóstico de Warden se está convirtiendo rápidamente en realidad. En los próximos años, podemos esperar que TinyML llegue a miles de millones de microcontroladores en hogares, oficinas, hospitales, fábricas, granjas, carreteras, puentes, etc. para habilitar aplicaciones que antes eran imposibles.
Este artículo fue publicado originalmente por Ben Dickson el TechTalks, una publicación que examina las tendencias en tecnología, cómo afectan la forma en que vivimos y hacemos negocios, y los problemas que resuelven. Pero también discutimos el lado malo de la tecnología, las implicaciones más oscuras de la nueva tecnología y lo que debemos tener en cuenta. Puede leer el artículo original aquí.